项目二 _____(电商日志数据分析项目)
- 引言
- 需求分析
- 详细思路
- 统计页面浏览量
- Map阶段
- Reduce阶段
- 日志的ETL操作
- Map阶段
- Reduce阶段
- 统计各个省份的浏览量
- Map阶段
- Reduce阶段
- 具体步骤
- 统计页面浏览量
- 日志的ETL操作
- 统计各个省份的浏览量
- 工具类(utils)
- 提取页面ID的工具类(GetPageId)
- IP地址解析工具类(IPParser)
- 日志解析工具类( LogParser)
- 运行结果截图
- 统计页面浏览量
- 日志的ETL操作
- 统计各个省份的浏览量
- 代码展示
- 遇到的问题及解决方案
引言
在电子商务领域,日志数据分析在了解客户行为、改善服务和优化业务策略方面发挥着至关重要的作用。本项目旨在深入研究由在线交易、用户互动和网站活动产生的庞大日志数据,提取有价值的见解。通过对这些数据的详细分析,我们希望发现能够增强决策过程和推动业务增长的模式、趋势和关联性。通过先进的分析技术和数据可视化,我们希望获得对客户偏好、市场动态和运营效率的全面了解。最终,本项目致力于为利益相关者提供可操作的智能,使其能够做出明智的决策并在竞争激烈的电子商务领域保持领先地位。
需求分析
-
统计页面浏览量:使用Hadoop的MapReduce来统计页面浏览量,实现对每个页面的浏览总量统计每一行记录代表一次浏览,统计出所有记录条数即可统计出页面浏览量。
-
统计各个省份的浏览量:需要解析日志文件中的IP地址,从中提取出省份信息。通过对IP地址进行解析,可以确定记录所在的省份,然后统计每个省份的浏览量。
-
日志的ETL操作:在ETL过程中,需要从日志文件中抽取数据,对数据进行转换以提取有价值的字段,最后加载转换后的数据至目的端。在本项目中,需要解析出IP地址、URL、PageID(对应的页面ID)、国家、省份和城市等字段,以便进行后续的分析和统计。
通过ETL操作,可以有效地处理大量的日志数据,提取出关键信息,减少数据存储和处理的复杂性,同时确保只有有价值的数据被提取和加载,从而实现对电商日志数据的高效分析和利用。
详细思路
统计页面浏览量
Map阶段
首先,在Map阶段,重写map方法,输入trackinfo_20130721.txt文件中的记录(将文件的偏移量作为输入键,文本行作为值),转换为键值对的形式输入如下:
<key,value>,<Text 对象,LongWritable 对象>,在map阶段输出的时候,我们可以把输出的键值对做成一个固定值<Text("key"), LongWritable(1)>,将键设置为一个名为key的Text类型,输出的值设为1,代表一条记录。将输出的结果写入到上下文中context.write(KEY,ONE);
Reduce阶段
在Reduce阶段,重写reduce方法,reduce方法用于对具有相同键的一组值进行处理,如<key, <value1,value2,...,valuen>>,所以reduce方法会接收到一个键(key)以及一组值(values),初始化一个变量count用来记录统计的value值,对values进行迭代,每迭代一次就将count加1,计算具有相同键的记录的数量,实际上就是在统计记录的总条数,因为在map阶段所有记录都已经设置了相同的KEY值,我们也可以对value进行求和,因为value里面所代表的就是每一条的记录数,value求和得到的值所代表的也是记录的总条数,与通过迭代统计得到的值一样。假如value的值不为1,那我们就不能去通过求和的方式,只能通过遍历value的长度来计算记录的总条数,将输出的结果写入上下文中context.write(NullWritable.get(),new LongWritable(count)),这里的NullWritable.get()代表KEY,我们不希望输出就可以设置为NullWritable类型,值就是迭代出的count值,设置为 LongWritable类型。
日志的ETL操作
Map阶段
首先,在Map阶段,重写map方法,输入trackinfo_20130721.txt文件中的记录(将文件的偏移量作为输入键,文本行作为值),转换为键值对的形式输入如下:
<key,value>,<Text 对象,LongWritable 对象>,将输入的value: Text 类型数据转换为字符串,然后使用 LogParser 解析日志信息得到各字段信息,parse方法是将传入的日志字符串解析成一个包含各个字段信息的 Map,解析后的日志信息中提取各个字段的数值,并构建一个新的字符串(StringBuilder类型,包含多个字段值),将日志信息追加builder,然后拼接成一个字符串,并将这个字符串写入到 MapReduce 的上下文中。
Reduce阶段
因为ETL操作只是用来提取信息,所以并不需要Reduce阶段。
统计各个省份的浏览量
Map阶段
首先,在Map阶段,重写map方法,在map方法中重写parse2方法将日志字符串 log 解析成包含各个字段信息的 Map 对象 info中。
将解析得到的省份信息(province)作为键,ONE 作为值写入上下文中。
Reduce阶段
在Reduce阶段,重写reduce方法,reduce方法用于对具有相同键的一组值进行处理,如<key, <value1,value2,...,valuen>>,所以reduce方法会接收到一个键(key)以及一组值(values),初始化一个变量count用来记录统计的value值,对values进行迭代,每迭代一次就将count加1,计算具有相同键的记录的数量,实际上就是在统计记录的总条数,因为在map阶段所有记录都已经设置了相同的KEY值,我们也可以对value进行求和,因为value里面所代表的就是每一条的记录数,value求和得到的值所代表的也是记录的总条数,与通过迭代统计得到的值一样。假如value的值不为1,那我们就不能去通过求和的方式,只能通过遍历value的长度来计算记录的总条数,将输出的结果写入上下文中context.write(NullWritable.get(),new LongWritable(count)),这里的NullWritable.get()代表KEY,我们不希望输出就可以设置为NullWritable类型,值就是迭代出的count值,设置为 LongWritable类型,与上述统计页面浏览量一致。
具体步骤
统计页面浏览量
首先需要创建一个名为PageCount的类,其中包含了 main 方法,用于设置作业的配置信息,包括输入路径、输出路径,以及 Mapper 和 Reducer 类。
设置输入输出路径
FileInputFormat.setInputPaths(job,newPath(“trackinfo_20130721.txt”));
FileOutputFormat.setOutputPath(job,new Path(“output/PageCountOut”));
接下来,PageCountMapper 类是 Mapper 类,负责将输入数据中的每一行转换成键值对,其中键为固定的文本 “key”,值为固定的整数 1。
设置键值对的值(KEY为固定文本,VALUE为1)
private Text KEY=new Text(“key”);
private LongWritable ONE=new LongWritable(1);
然后,PageCountReducer 类是 Reducer 类,负责对 Mapper 输出的键值对进行聚合操作,统计相同键的值的个数,即对访问次数进行累加。
通过循环的方式进行计数,即统计浏览量
long count =0;
for(LongWritable value :values){
count++;
日志的ETL操作
首先需要创建一个名为ETL的类,其中包含了 main 方法,用于设置作业的配置信息,包括输入路径、输出路径,以及 Mapper 和 Reducer 类。
设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(“pageFlum/trackinfo_20130721.txt”));
FileOutputFormat.setOutputPath(job, new Path(“ETL/etl”));
接下来,ETLMapper 类是 Mapper 类,首先初始化一个setup 方法:在 Mapper 开始执行之前调用,用于初始化操作。在这里,创建了一个 LogParser 的实例,用于解析日志。之后在map 方法:是一个实际的映射逻辑,将输入的每一行日志转换为需要的格式,并输出。
创建一个新的 LogParser 实例,并将其赋值给 logParser 成员变量
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
解析后的日志信息中提取各个字段的数值
String ip = info.get(“ip”);
String url = info.get(“url”);
String time = info.get(“time”);
String country = info.get(“country”);
String province = info.get(“province”);
String city = info.get(“city”);
通过调用 GetPageId 类的 getPageId 方法,从 URL 中提取页面 ID
String pageId=GetPageId.getPageId(url);
构建新的字符串 builder,将解析后的字段按照制表符分隔拼接
StringBuilder builder = new StringBuilder();
builder.append(ip).append(“\t”);
builder.append(url).append(“\t”);
builder.append(pageId).append(“\t”);
builder.append(time).append(“\t”);
builder.append(country).append(“\t”);
builder.append(province).append(“\t”);
builder.append(city).append(“\t”);
context.write(NullWritable.get(), new Text(builder.toString()));
统计各个省份的浏览量
首先需要创建一个名为PageCount的类,其中包含了 main 方法,用于设置作业的配置信息,包括输入路径、输出路径,以及 Mapper 和 Reducer 类。
设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(“ETL/etl/part-r-00000”));
FileOutputFormat.setOutputPath(job, new Path(“output/PageProvinceOut/”));
接下来,PageProvinceMapper类是 Mapper 类,初始化一个setup 方法:在 Mapper 开始执行之前调用,用于初始化操作。在这里,创建了一个 LogParser 的实例,用于解析日志,在map 方法中:也是一个实际的映射逻辑,将输入的每一行日志解析出省份信息,并输出。
调用parse2方法解析日志文件
Map<String,String> info = logParser.parse2(log);
context.write(new Text(info.get(“province”)),ONE);
然后,PageProvinceReducer 类是 Reducer 类,对 Mapper 输出的键值对进行聚合操作,统计相同省份的访问次数。
通过循环的方式进行计数,即统计浏览量
long count =0;
for(LongWritable value :values){
count++;
工具类(utils)
提取页面ID的工具类(GetPageId)
使用正则表达式创建一个模式,用于匹配形如 topicId=数字 的字符串。
Pattern pat = Pattern.compile(“topicId=[0-9]+”);
使用模式匹配器 matcher 对象在输入的 URL 上进行匹配。
Matcher matcher = pat.matcher(url);
IP地址解析工具类(IPParser)
定义了一个受保护的构造函数,接受 IP 地址数据库文件路径
protected IPParser(String ipFilePath) { super(ipFilePath); }
定义了一个静态方法 getInstance(),用于获取 IPParser 的实例对象
public static IPParser getInstance() { return obj; }
日志解析工具类( LogParser)
Map<String, String> logInfo = new HashMap<String,String>();
创建了一个 HashMap 对象 logInfo,用于存储键值对,其中键和值都是字符串类型
这个 HashMap 的作用是用来保存日志信息的各个字段
IPParser ipParse = IPParser.getInstance();
整个开发过程还需要编写Driver类来配置和启动MapReduce作业,设置输入输出路径、指定Mapper和Reducer类等。通过这些步骤,可以完成对页面浏览量的统计并输出到对应的文件中。这种方式可以有效地对数据进行处理和分析,来满足需求。
运行结果截图
统计页面浏览量
日志的ETL操作
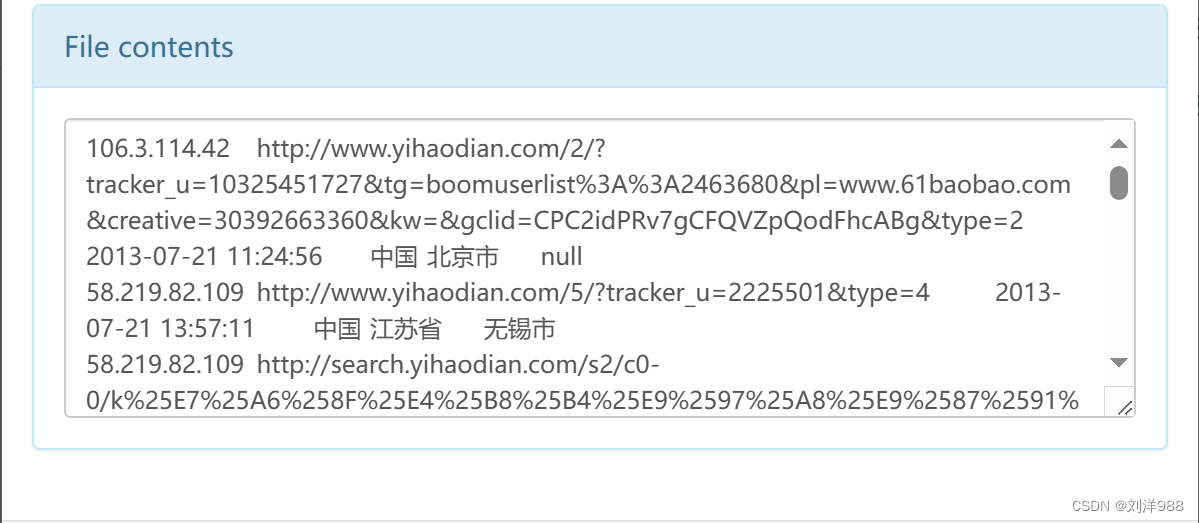
统计各个省份的浏览量
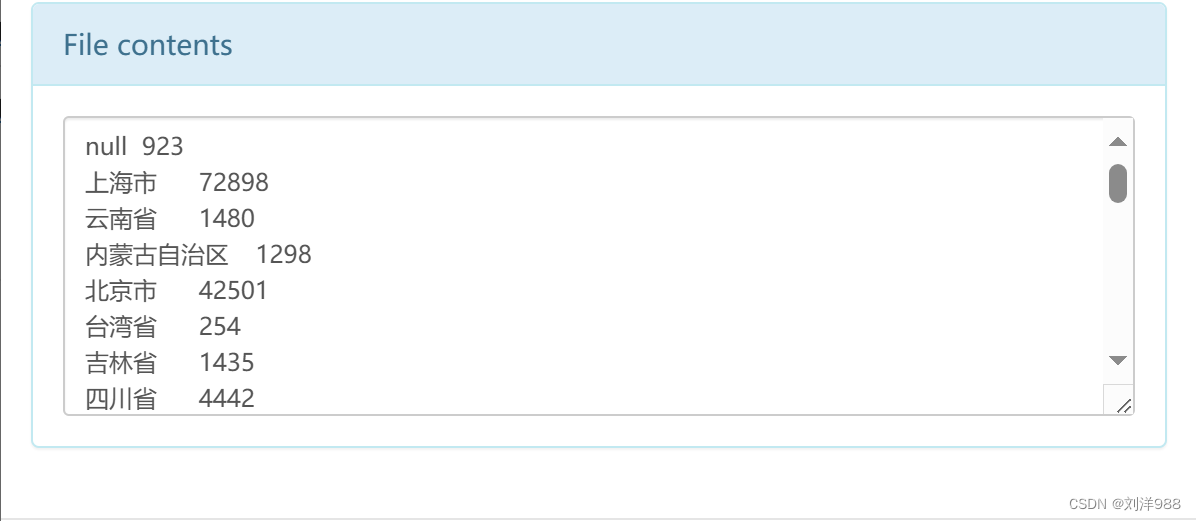
代码展示
PageCount
public class PageCount {
public static void main(String[] args) throws Exception{
// driver类 八股文
Configuration configuration =new Configuration();
FileSystem fileSystem=FileSystem.get(configuration);
Path outputPath=new Path("output/PageCountOut/");
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
Job job =Job.getInstance(configuration);
job.setJarByClass(PageCount.class);
job.setMapperClass(PageCountmapper.class);
job.setReducerClass(PageCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path("pageFlum/trackinfo_20130721.txt"));
FileOutputFormat.setOutputPath(job,new Path("output/PageCountOut/"));
job.waitForCompletion(true);
}
//Map
//文件的偏移量作为输入键,文本行作为值
static class PageCountmapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text KEY=new Text("key");
private LongWritable ONE=new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(KEY,ONE);
}
}
//Reduce
static class PageCountReducer extends Reducer<Text,LongWritable, NullWritable,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count =0;
for(LongWritable value :values){
count++;
}
context.write(NullWritable.get(),new LongWritable(count));
}
}
}
ETL
public class ETL {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("ETL/etl");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(ETL.class);
job.setMapperClass(ETLMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("pageFlum/trackinfo_20130721.txt"));
FileOutputFormat.setOutputPath(job, new Path("ETL/etl"));
job.waitForCompletion(true);
}
static class ETLMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
private LogParser logParser;
//定义了一个私有的成员变量 logParser,类型为 LogParser(类名)
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
// 用于在任务执行之前进行一些初始化操作。在这个方法中,
// 会创建一个新的 LogParser 实例,并将其赋值给 logParser 成员变量
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String, String> info = logParser.parse(log);
//解析后的日志信息中提取各个字段的数值
String ip = info.get("ip");
String url = info.get("url");
//通过调用 GetPageId 类的 getPageId 方法,从 URL 中提取页面 ID
String pageId=GetPageId.getPageId(url);
String time = info.get("time");
String country = info.get("country");
String province = info.get("province");
String city = info.get("city");
StringBuilder builder = new StringBuilder();
builder.append(ip).append("\t");
builder.append(url).append("\t");
builder.append(pageId).append("\t");
builder.append(time).append("\t");
builder.append(country).append("\t");
builder.append(province).append("\t");
builder.append(city).append("\t");
context.write(NullWritable.get(), new Text(builder.toString()));
}
}
}
PageProvince
public class PageProvince {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("output/PageProvinceOut/");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(PageProvince.class);
job.setMapperClass(PageProvinceMapper.class);
job.setReducerClass(PageProvinceReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("ETL/etl/part-r-00000"));
FileOutputFormat.setOutputPath(job, new Path("output/PageProvinceOut/"));
job.waitForCompletion(true);
}
static class PageProvinceMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String,String> info = logParser.parse2(log);
context.write(new Text(info.get("province")),ONE);
}
}
static class PageProvinceReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count++;
}
context.write(key, new LongWritable(count));
}
}
}
GetPageId
public class GetPageId {
public static String getPageId(String url) {
//初始化一个空字符串 pageId,用于存储提取的页面 ID
String pageId = "";
//检查输入的 URL 是否为空或者只包含空格,如果是,则直接返回空的 pageId
if (StringUtils.isBlank(url)) {
return pageId;
}
//使用正则表达式创建一个模式,用于匹配形如 topicId=数字 的字符串。
Pattern pat = Pattern.compile("topicId=[0-9]+");
//使用模式匹配器 matcher 对象在输入的 URL 上进行匹配。
Matcher matcher = pat.matcher(url);
//如果找到匹配的字符串,则从匹配的字符串中提取页面 ID,并将其赋值给 pageId
//在输入的 URL 中查找与模式匹配的子序列
if (matcher.find()) {
pageId = matcher.group().split("topicId=")[1];
//返回与前一次匹配操作(find())相匹配的输入子序列
//根据 "topicId=" 进行分割,取分割后的第二部分,即数字部分作为页面 ID。
}
return pageId;
//返回提取的页面 ID
}
}
IPParser
public class IPParser extends IPSeeker {
// 地址 仅仅只是在idea环境中使用,部署在服务器上,
// 需要先将qqwry.dat放在集群的各个节点某个有读取权限目录,
// 然后在这里指定全路径
private static final String ipFilePath = "/home/liuyang/qqwry.dat";
// 部署在服务器上
// 定义了一个静态常量 ipFilePath,表示 IP 地址数据库文件的路径
// 类加载时创建了一个静态 IPParser 对象 obj,并传入 IP 地址数据库文件路径进行初始化
private static IPParser obj = new IPParser(ipFilePath);
//定义了一个受保护的构造函数,接受 IP 地址数据库文件路径,并调用父类 IPSeeker 的构造函数进行初始化
protected IPParser(String ipFilePath) {
super(ipFilePath);
}
//定义了一个静态方法 getInstance(),用于获取 IPParser 的实例对象
public static IPParser getInstance() {
return obj;
}
/**
* 解析ip地址
*
* @param ip
* @return
*/
//定义了一个公共方法 analyseIp,接受一个 IP 地址作为参数,用于解析该 IP 地址的地理位置信息并返回一个 RegionInfo 对象
public RegionInfo analyseIp(String ip) {
if (ip == null || "".equals(ip.trim())) {
return null;
}
//检查传入的 IP 地址是否为空,如果为空则返回 null
RegionInfo info = new RegionInfo();
try {
String country = super.getCountry(ip); //调用父类方法获取 IP 地址对应的国家信息
if ("局域网".equals(country) || country == null || country.isEmpty() || country.trim().startsWith("CZ88")) {
// 设置默认值
info.setCountry("中国");
info.setProvince("上海市");
} else {
//根据国家信息的不同情况,设置对应的国家、省份和城市信息到 RegionInfo 对象中
int length = country.length();
int index = country.indexOf('省');
if (index > 0) { // 表示是国内的某个省
info.setCountry("中国");
info.setProvince(country.substring(0, Math.min(index + 1, length)));
int index2 = country.indexOf('市', index);
if (index2 > 0) {
// 设置市
info.setCity(country.substring(index + 1, Math.min(index2 + 1, length)));
}
} else {
String flag = country.substring(0, 2);
switch (flag) {
case "内蒙":
info.setCountry("中国");
info.setProvince("内蒙古自治区");
country = country.substring(3);
if (country != null && !country.isEmpty()) {
index = country.indexOf('市');
if (index > 0) {
// 设置市
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
// TODO:针对其他旗或者盟没有进行处理
}
break;
case "广西":
case "西藏":
case "宁夏":
case "新疆":
info.setCountry("中国");
info.setProvince(flag);
country = country.substring(2);
if (country != null && !country.isEmpty()) {
index = country.indexOf('市');
if (index > 0) {
// 设置市
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
}
break;
case "上海":
case "北京":
case "重庆":
case "天津":
info.setCountry("中国");
info.setProvince(flag + "市");
country = country.substring(3);
if (country != null && !country.isEmpty()) {
index = country.indexOf('区');
if (index > 0) {
// 设置市
char ch = country.charAt(index - 1);
if (ch != '小' || ch != '校') {
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
}
if ("unknown".equals(info.getCity())) {
// 现在city还没有设置,考虑县
index = country.indexOf('县');
if (index > 0) {
// 设置市
info.setCity(country.substring(0, Math.min(index + 1, length)));
}
}
}
break;
case "香港":
case "澳门":
info.setCountry("中国");
info.setProvince(flag + "特别行政区");
break;
default:
info.setCountry(country); // 针对其他国外的ip
}
}
}
} catch (Exception e) {
// nothing
}
return info;
}
/**
* ip地址对应的info类
*
*/
// 定义了一个静态内部类 RegionInfo,用于存储 IP 地址解析后的地理位置信息,包括国家、省份和城市信息,
// 并提供了相应的 getter 和 setter 方法以及 toString() 方法。
public static class RegionInfo {
// 通过 getter 方法获取对象的属性值,
// 通过 setter 方法设置对象的属性值,
// 通过 toString() 方法返回对象的字符串表示形式
private String country ;
private String province ;
private String city ;
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "RegionInfo [country=" + country + ", province=" + province + ", city=" + city + "]";
}
}
}
IPSeeker
public class IPSeeker {
//首先定义了一些常量和类成员变量,包括一些固定常量、用作缓存的 Hashtable、文件访问相关的变量
public static final String ERROR_RESULT = "错误的IP数据库文件";
// 一些固定常量,比如记录长度等等
private static final int IP_RECORD_LENGTH = 7;
private static final byte AREA_FOLLOWED = 0x01;
private static final byte NO_AREA = 0x2;
// 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找
private Hashtable ipCache;
// 随机文件访问类
private RandomAccessFile ipFile;
// 内存映射文件
private MappedByteBuffer mbb;
// 单一模式实例
private static IPSeeker instance = null;
// 起始地区的开始和结束的绝对偏移
private long ipBegin, ipEnd;
// 为提高效率而采用的临时变量
private IPLocation loc;
private byte[] buf;
private byte[] b4;
private byte[] b3;
/** */
/**
* 私有构造函数
*/
protected IPSeeker(String ipFilePath) {
//用于初始化 IP 地址信息文件,并读取文件头信息
ipCache = new Hashtable();
loc = new IPLocation();
buf = new byte[100];
b4 = new byte[4];
b3 = new byte[3];
try {
ipFile = new RandomAccessFile(ipFilePath, "r");
} catch (FileNotFoundException e) {
System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用");
ipFile = null;
}
// 如果打开文件成功,读取文件头信息
if (ipFile != null) {
try {
ipBegin = readLong4(0);
ipEnd = readLong4(4);
if (ipBegin == -1 || ipEnd == -1) {
ipFile.close();
ipFile = null;
}
} catch (IOException e) {
System.out.println("IP地址信息文件格式有错误,IP显示功能将无法使用");
ipFile = null;
}
}
}
/** */
/**
* @return 单一实例
*/
//用于获取单例实例
public static IPSeeker getInstance(String ipFilePath) {
if (instance == null) {
instance = new IPSeeker(ipFilePath);
}
return instance;
}
/** */
/**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/
public List getIPEntriesDebug(String s) {
List ret = new ArrayList();
long endOffset = ipEnd + 4;
for (long offset = ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
// 读取结束IP偏移
long temp = readLong3(offset);
// 如果temp不等于-1,读取IP的地点信息
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
return ret;
}
/** */
/**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/
public List getIPEntries(String s) {
List ret = new ArrayList();
try {
// 映射IP信息文件到内存中
if (mbb == null) {
FileChannel fc = ipFile.getChannel();
mbb = fc.map(FileChannel.MapMode.READ_ONLY, 0, ipFile.length());
mbb.order(ByteOrder.LITTLE_ENDIAN);
}
int endOffset = (int) ipEnd;
for (int offset = (int) ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
int temp = readInt3(offset);
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
} catch (IOException e) {
System.out.println(e.getMessage());
}
return ret;
}
/** */
/**
* 从内存映射文件的offset位置开始的3个字节读取一个int
*
* @param offset
* @return
*/
private int readInt3(int offset) {
mbb.position(offset);
return mbb.getInt() & 0x00FFFFFF;
}
/** */
/**
* 从内存映射文件的当前位置开始的3个字节读取一个int
*
* @return
*/
private int readInt3() {
return mbb.getInt() & 0x00FFFFFF;
}
/** */
/**
* 根据IP得到国家名
*
* @param ip
* ip的字节数组形式
* @return 国家名字符串
*/
//用于根据 IP 地址获取地理位置信息,包括 getCountry、getArea、getIPLocation
public String getCountry(byte[] ip) {
// 检查ip地址文件是否正常
if (ipFile == null)
return ERROR_RESULT;
// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);
// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件
if (ipCache.containsKey(ipStr)) {
IPLocation loc = (IPLocation) ipCache.get(ipStr);
return loc.country;
} else {
IPLocation loc = getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());
return loc.country;
}
}
/** */
/**
* 根据IP得到国家名
*
* @param ip
* IP的字符串形式
* @return 国家名字符串
*/
public String getCountry(String ip) {
return getCountry(IPSeekerUtils.getIpByteArrayFromString(ip));
}
/** */
/**
* 根据IP得到地区名
*
* @param ip
* ip的字节数组形式
* @return 地区名字符串
*/
public String getArea(byte[] ip) {
// 检查ip地址文件是否正常
if (ipFile == null)
return ERROR_RESULT;
// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);
// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件
if (ipCache.containsKey(ipStr)) {
IPLocation loc = (IPLocation) ipCache.get(ipStr);
return loc.area;
} else {
IPLocation loc = getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());
return loc.area;
}
}
/**
* 根据IP得到地区名
*
* @param ip
* IP的字符串形式
* @return 地区名字符串
*/
public String getArea(String ip) {
return getArea(IPSeekerUtils.getIpByteArrayFromString(ip));
}
/** */
/**
* 根据ip搜索ip信息文件,得到IPLocation结构,所搜索的ip参数从类成员ip中得到
*
* @param ip
* 要查询的IP
* @return IPLocation结构
*/
public IPLocation getIPLocation(byte[] ip) {
IPLocation info = null;
long offset = locateIP(ip);
if (offset != -1)
info = getIPLocation(offset);
if (info == null) {
info = new IPLocation();
info.country = "未知国家";
info.area = "未知地区";
}
return info;
}
/**
* 从offset位置读取4个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/
//提供了一些辅助方法,如 readString、readIP、compareIP 等,用于读取文件中的字符串、读取 IP 地址、比较 IP 地址等操作
private long readLong4(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ret |= (ipFile.readByte() & 0xFF);
ret |= ((ipFile.readByte() << 8) & 0xFF00);
ret |= ((ipFile.readByte() << 16) & 0xFF0000);
ret |= ((ipFile.readByte() << 24) & 0xFF000000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从当前位置读取3个字节转换成long
*
* @return
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/
private void readIP(long offset, byte[] ip) {
try {
ipFile.seek(offset);
ipFile.readFully(ip);
byte temp = ip[0];
ip[0] = ip[3];
ip[3] = temp;
temp = ip[1];
ip[1] = ip[2];
ip[2] = temp;
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/
private void readIP(int offset, byte[] ip) {
mbb.position(offset);
mbb.get(ip);
byte temp = ip[0];
ip[0] = ip[3];
ip[3] = temp;
temp = ip[1];
ip[1] = ip[2];
ip[2] = temp;
}
/**
* 把类成员ip和beginIp比较,注意这个beginIp是big-endian的
*
* @param ip
* 要查询的IP
* @param beginIp
* 和被查询IP相比较的IP
* @return 相等返回0,ip大于beginIp则返回1,小于返回-1。
*/
private int compareIP(byte[] ip, byte[] beginIp) {
for (int i = 0; i < 4; i++) {
int r = compareByte(ip[i], beginIp[i]);
if (r != 0)
return r;
}
return 0;
}
/**
* 把两个byte当作无符号数进行比较
*
* @param b1
* @param b2
* @return 若b1大于b2则返回1,相等返回0,小于返回-1
*/
private int compareByte(byte b1, byte b2) {
if ((b1 & 0xFF) > (b2 & 0xFF)) // 比较是否大于
return 1;
else if ((b1 ^ b2) == 0)// 判断是否相等
return 0;
else
return -1;
}
/**
* 这个方法将根据ip的内容,定位到包含这个ip国家地区的记录处,返回一个绝对偏移 方法使用二分法查找。
*
* @param ip
* 要查询的IP
* @return 如果找到了,返回结束IP的偏移,如果没有找到,返回-1
*/
private long locateIP(byte[] ip) {
long m = 0;
int r;
// 比较第一个ip项
readIP(ipBegin, b4);
r = compareIP(ip, b4);
if (r == 0)
return ipBegin;
else if (r < 0)
return -1;
// 开始二分搜索
for (long i = ipBegin, j = ipEnd; i < j;) {
m = getMiddleOffset(i, j);
readIP(m, b4);
r = compareIP(ip, b4);
// log.debug(Utils.getIpStringFromBytes(b));
if (r > 0)
i = m;
else if (r < 0) {
if (m == j) {
j -= IP_RECORD_LENGTH;
m = j;
} else
j = m;
} else
return readLong3(m + 4);
}
// 如果循环结束了,那么i和j必定是相等的,这个记录为最可能的记录,但是并非
// 肯定就是,还要检查一下,如果是,就返回结束地址区的绝对偏移
m = readLong3(m + 4);
readIP(m, b4);
r = compareIP(ip, b4);
if (r <= 0)
return m;
else
return -1;
}
/**
* 得到begin偏移和end偏移中间位置记录的偏移
*
* @param begin
* @param end
* @return
*/
private long getMiddleOffset(long begin, long end) {
long records = (end - begin) / IP_RECORD_LENGTH;
records >>= 1;
if (records == 0)
records = 1;
return begin + records * IP_RECORD_LENGTH;
}
/**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
*
* @param offset
* @return
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if (b == AREA_FOLLOWED) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if (b == NO_AREA) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if (b == NO_AREA) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/**
* @param offset
* @return
*/
private IPLocation getIPLocation(int offset) {
// 跳过4字节ip
mbb.position(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = mbb.get();
if (b == AREA_FOLLOWED) {
// 读取国家偏移
int countryOffset = readInt3();
// 跳转至偏移处
mbb.position(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = mbb.get();
if (b == NO_AREA) {
loc.country = readString(readInt3());
mbb.position(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(mbb.position());
} else if (b == NO_AREA) {
loc.country = readString(readInt3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(mbb.position() - 1);
loc.area = readArea(mbb.position());
}
return loc;
}
/**
* 从offset偏移开始解析后面的字节,读出一个地区名
*
* @param offset
* @return 地区名字符串
* @throws IOException
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if (b == 0x01 || b == 0x02) {
long areaOffset = readLong3(offset + 1);
if (areaOffset == 0)
return "未知地区";
else
return readString(areaOffset);
} else
return readString(offset);
}
/**
* @param offset
* @return
*/
private String readArea(int offset) {
mbb.position(offset);
byte b = mbb.get();
if (b == 0x01 || b == 0x02) {
int areaOffset = readInt3();
if (areaOffset == 0)
return "未知地区";
else
return readString(areaOffset);
} else
return readString(offset);
}
/**
* 从offset偏移处读取一个以0结束的字符串
*
* @param offset
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for (i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte())
;
if (i != 0)
return IPSeekerUtils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
System.out.println(e.getMessage());
}
return "";
}
/**
* 从内存映射文件的offset位置得到一个0结尾字符串
*
* @param offset
* @return
*/
private String readString(int offset) {
try {
mbb.position(offset);
int i;
for (i = 0, buf[i] = mbb.get(); buf[i] != 0; buf[++i] = mbb.get())
;
if (i != 0)
return IPSeekerUtils.getString(buf, 0, i, "GBK");
} catch (IllegalArgumentException e) {
System.out.println(e.getMessage());
}
return "";
}
public String getAddress(String ip) {
String country = getCountry(ip).equals(" CZ88.NET") ? "" : getCountry(ip);
String area = getArea(ip).equals(" CZ88.NET") ? "" : getArea(ip);
String address = country + " " + area;
return address.trim();
}
/**
* * 用来封装ip相关信息,目前只有两个字段,ip所在的国家和地区
*
*
* @author swallow
*/
//定义了一个内部类 IPLocation,用于封装 IP 相关信息,包括国家和地区
public class IPLocation {
public String country;
public String area;
public IPLocation() {
country = area = "";
}
public IPLocation getCopy() {
IPLocation ret = new IPLocation();
ret.country = country;
ret.area = area;
return ret;
}
}
/**
* 一条IP范围记录,不仅包括国家和区域,也包括起始IP和结束IP *
*
*
* @author gerry liu
*/
//定义了内部类 IPEntry,用于表示一条 IP 范围记录,包括起始 IP、结束 IP、国家和地区。
public class IPEntry {
public String beginIp;
public String endIp;
public String country;
public String area;
public IPEntry() {
beginIp = endIp = country = area = "";
}
public String toString() {
return this.area + " " + this.country + "IP Χ:" + this.beginIp + "-" + this.endIp;
}
}
/**
* 操作工具类
*
* @author gerryliu
*
*/
//定义了一个静态内部类 IPSeekerUtils,包含一些 IP 地址处理的工具方法,如将 IP 地址转换为字节数组、根据编码方式转换字符串
public static class IPSeekerUtils {
/**
* 从ip的字符串形式得到字节数组形式
*
* @param ip
* 字符串形式的ip
* @return 字节数组形式的ip
*/
public static byte[] getIpByteArrayFromString(String ip) {
byte[] ret = new byte[4];
java.util.StringTokenizer st = new java.util.StringTokenizer(ip, ".");
try {
ret[0] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[1] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[2] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[3] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
} catch (Exception e) {
System.out.println(e.getMessage());
}
return ret;
}
/**
* 对原始字符串进行编码转换,如果失败,返回原始的字符串
*
* @param s
* 原始字符串
* @param srcEncoding
* 源编码方式
* @param destEncoding
* 目标编码方式
* @return 转换编码后的字符串,失败返回原始字符串
*/
public static String getString(String s, String srcEncoding, String destEncoding) {
try {
return new String(s.getBytes(srcEncoding), destEncoding);
} catch (UnsupportedEncodingException e) {
return s;
}
}
/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/
public static String getString(byte[] b, String encoding) {
try {
return new String(b, encoding);
} catch (UnsupportedEncodingException e) {
return new String(b);
}
}
/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param offset
* 要转换的起始位置
* @param len
* 要转换的长度
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/
public static String getString(byte[] b, int offset, int len, String encoding) {
try {
return new String(b, offset, len, encoding);
} catch (UnsupportedEncodingException e) {
return new String(b, offset, len);
}
}
/**
* @param ip
* ip的字节数组形式
* @return 字符串形式的ip
*/
public static String getIpStringFromBytes(byte[] ip) {
StringBuffer sb = new StringBuffer();
sb.append(ip[0] & 0xFF);
sb.append('.');
sb.append(ip[1] & 0xFF);
sb.append('.');
sb.append(ip[2] & 0xFF);
sb.append('.');
sb.append(ip[3] & 0xFF);
return sb.toString();
}
}
/**
* 获取全部ip地址集合列表
*
* @return
*/
public List<String> getAllIp() {
List<String> list = new ArrayList<String>();
byte[] buf = new byte[4];
for (long i = ipBegin; i < ipEnd; i += IP_RECORD_LENGTH) {
try {
this.readIP(this.readLong3(i + 4), buf); // 读取ip,最终ip放到buf中
String ip = IPSeekerUtils.getIpStringFromBytes(buf);
list.add(ip);
} catch (Exception e) {
// nothing
}
}
return list;
}
}
LogParser
public class LogParser {
//定义一个 Logger 对象用于记录日志
private Logger logger = LoggerFactory.getLogger(LogParser.class);
//定义两个解析方法 parse 和 parse2,用于解析日志信息并返回一个包含字段信息的 Map 对象。
public Map<String, String> parse2(String log) {
//提取了 IP 地址、URL、页面 ID、时间、国家、省份和城市等信息,并将这些信息存入 logInfo 中返回
Map<String, String> logInfo = new HashMap<String,String>();
IPParser ipParse = IPParser.getInstance();
if(StringUtils.isNotBlank(log)) {
String[] splits = log.split("\t");
String ip = splits[0];
String url = splits[1];
String pageId = splits[2];
String time = splits[3];
String country = splits[4];
String province = splits[5];
String city = splits[6];
logInfo.put("ip",ip);
logInfo.put("url",url);
logInfo.put("pageId",pageId);
logInfo.put("time",time);
logInfo.put("country",country);
logInfo.put("province",province);
logInfo.put("city",city);
} else{
logger.error("日志记录的格式不正确:" + log);
}
return logInfo;
}
public Map<String, String> parse(String log) {
// 提取了 IP 地址、URL、页面 ID、时间等信息,
// 并调用 IPParser 的方法获取 IP 地址的地理位置信息,最后将这些信息存入 logInfo 中返回。
Map<String, String> logInfo = new HashMap<String,String>();
// 创建了一个 HashMap 对象 logInfo,用于存储键值对,其中键和值都是字符串类型
// 这个 HashMap 的作用是用来保存日志信息的各个字段
IPParser ipParse = IPParser.getInstance();
if(StringUtils.isNotBlank(log)) {
String[] splits = log.split("\001");
String ip = splits[13];
//从 splits 数组中获取第 14 个元素(索引为 13)作为 IP 地址,
String url = splits[1];
String pageId = splits[10];
String time = splits[17];
logInfo.put("ip",ip);
// 然后将其存储在 logInfo 中,键名为 "ip"
logInfo.put("url",url);
logInfo.put("pageId",pageId);
logInfo.put("time",time);
IPParser.RegionInfo regionInfo = ipParse.analyseIp(ip);
//调用 IPParser.analyseIp(ip) 方法获取了 IP 地址的地理位置信息,包括国家、省份和城市
logInfo.put("country",regionInfo.getCountry());
logInfo.put("province",regionInfo.getProvince());
logInfo.put("city",regionInfo.getCity());
} else{
logger.error("日志记录的格式不正确:" + log);
} //日志信息为空或格式不正确,会记录错误日志并返回空的 logInfo
return logInfo;
}
}
遇到的问题及解决方案
遇到的问题及解决方案:
| 遇到的问题 | 解决方案 |
|---|---|
| 在pom.xml文件中导入坐标超时报错 | 通过使用国内的阿里云镜像解决 |
| Java 运行版本低于编译类文件用的版本 | 使用支持当前 Java 版本编译器来编译代码 |





![[数据集][目标检测]斑马线人行横道检测数据集VOC+YOLO格式793张1类别](https://img-blog.csdnimg.cn/direct/3d76c978ccc64a9c8894c4045aad70bb.png)