- MyCat简介
- MyCat是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
- MyCAT主要解决的是数据库的分库分表,以及对数据的读写分离。来达到提高数据存储量,以及提升数据查询效率等
- MyCat架构
- 用户可以把MyCAT看作是一个数据库代理,用mysql客户端工具(如Navicat)和命令访问,其核心功能就是分库分表,即将一个大表水平分割为N个小表,实际的存储还是在后端Mysql服务器中或其它数据库中。

- MyCat拦截了用户发送过来的SQL语句,⾸先对SQL语句做了特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给客户。
- MyCat安装
- 下载http://dl.mycat.io/
- 把MyCat的压缩包上传到linux服务器
- 解压缩 tar zxf 压缩包名称
- 目录结构:
- bin:mycat命令,启动、重启、停止等
- catlet:catlet为Mycat的一个扩展功能
- conf:Mycat 配置信息,重点关注
- lib:Mycat引用的jar包,Mycat是java开发的
- logs:日志文件,包括Mycat启动的日志和运行的日志。
| conf目录下service.xml,rule.xml,schema.xml三个文件 service.xml主要配置Mycat服务的参数,比如端口号,myact用户名和密码使用的逻辑数据库等 role.xml主要配置路由策略,主要有分片的片键,拆分的策略(取模还是按区间划分等) schema.xml文件主要配置数据库的信息,例如逻辑数据库名称,物理上真实的数据源以及表和数据源之间的对应关系和路由策略等。 |
- 进入mycat/bin目录
- 启动命令:./mycat start
- 停止命令:./mycat stop
- 重启命令:./mycat restart
- 分片原理
- 数据库分片指:通过某种特定的条件,将我们存放在一个数据库中的数据分散存放在不同的多个数据库(主机)中,这样来达到分散单台设备的负载,根据切片规则,可分为以下两种切片模式:
- 水平分片:对数据量很大的表进行拆分,把这些表按照某种规则将数据存放到不同的数据库中。
垂直切分:根据业务的不同,将不同业务的表存储在不同的数据库中。比如将一个数据库中的A,B,C三张表垂直切分;A表存储在节点1上,B表存储在节点2上,C表存储在节点3上。
- 分库分表
- 环境搭建
mysql节点1环境;
| 操作系统版本 : centos7 数据库版本 : mysql-5.6 |
mysql节点2环境
| 操作系统版本 : centos7 数据库版本 : mysql-5.6 |
- MyCat安装到节点1上(需要安装jdk)
- 相关概念
- schema:逻辑库,与MySQL中的database(数据库)对应,在逻辑库中定义所包含的Table。所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
- table:逻辑表,表中的数据根据不同的分片规则存储在不同的节点上。
- dataNode:是MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上,一般来说,为了高可用性,每个DataNode都设置两个DataSource,一主一从,当主节点宕机,系统自动切换到从节点。
- dataHost:节点主机,定义某个物理库的访问地址,用于捆绑到dataNode上。
- 配置schema.xml
- Schema.xml用于配置逻辑库表及数据节点,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。
- schema 标签用于定义MyCat实例中的逻辑库
- Table 标签定义了MyCat中的逻辑表
- dataNode 标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。
- dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句
- 注意:若是LINUX版本的MYSQL,则需要设置为Mysql大小写不敏感,否则可能会发生表找不到的问题。
在MySQL的配置文件中my.ini [mysqld] 中增加一行
lower_case_table_names = 1
- Schema.xml用于配置逻辑库表及数据节点,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。
-
- Schema.xml配置
| <?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!--TESTDB逻辑数据库名称--> <!--checkSQLschema 拦截SQL语句, true表示不使用schema:例如select * from goods false使用schema:例如select * from TESTDB.goods --> <!-- sqlMaxLimit:限制查询语句返回最多数据的条数。 --> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <!-- auto sharding by id (long) --> <!--TB_GOODS逻辑表名--> <!--dataNode数据节点--> <!--rule分片规则--> <!--数据节点及分片规则的设置;将TB_GOODS表安照auto-sharding-loing 规则进行分片存储;三个节点综合起来组成TB_GOODS一个完整的表 --> <table name="TB_GOODS" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema> <!--分片节点;目前分成三个节点,每个节点对应的就是物理库的名字--> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost2" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" /> <!--节点主机的地址;分片后会将数据存储在不同的两个主机节点上--> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <!--心跳检查语句--> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <!--设置主机的地址和连接信息--> <writeHost host="hostM1" url="192.168.254.128:3306" user="root" password="root"> <!-- can have multi read hosts --> </writeHost> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.25.166:3306" user="root" password="root"> <!-- can have multi read hosts --> </writeHost> </dataHost> </mycat:schema> |
- Server.xml用于配置服务器权限
| <user name="test"> <property name="password">test</property> <property name="schemas">TESTDB</property> <property name="readOnly">true</property> </user> |
- 配置rule.xml
rule.xml用于配置表的分片规则,里面定义了对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。这个文件里面主要有tableRule和function这两个标签。在具体使用过程中可以按照需求添加tableRule和function。此配置文件可以不用修改,使用默认即可。
- 分片测试
由于配置的分片规则为“auto-sharding-long”,所以mycat会根据此规则自动分片。
每个datanode中保存一定数量的数据。根据id进行分片。
测试id范围为:
Datanode1:1~5000000
Datanode2:5000000~10000000
Datanode3:10000001~15000000
- 分片规则
| 规则 | 示例 | 描述 |
| 枚举法: 通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则,配置如下 | <tableRule name="sharding-by-intfile"> <rule> <columns>user_id</columns> <algorithm>hash-int</algorithm> </rule> </tableRule> <function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> <property name="type">0</property> <property name="defaultNode">0</property> </function> | 【columns】标识将要分片的表字段 【algorithm】分片函数 【mapFile 】标识配置文件名称 【type】默认值为 0,0 表示 Integer,非零表示 String 【defaultNode】 默认节点:小于 0 表示不设置默认节点,大于等于 0 设置默认节点。 |
| 注意:默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点 | ||
| partition-hash-int.txt 配置: 10000=0 10010=1 DEFAULT_NODE=1 //默认节点 | ||
| 规则 | 示例 | 描述 |
| 按日期(天)分片 此规则为按天分片。 | <tableRule name="sharding-by-date"> <rule> <columns>create_time</columns> <algorithm>sharding-by-date</algorithm> </rule> </tableRule> <function name="sharding-by-date" class="org.opencloudb.route.function.PartitionByDate"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2010-01-01</property>
<property name="sPartionDay">10</property> </function> | 【columns】标识将要分片的表字段 【algorithm】分片函数 【dateForma 】日期格式 【sBeginDate 】开始日期 【sPartionDay 】分区天数,即默认从开始日期算起,分隔 10 天一个分区。 |
| 注意 需要提前将分片规划好,建好,否则有可能日期超出实际配置分片数 | ||
- MyCat读写分离
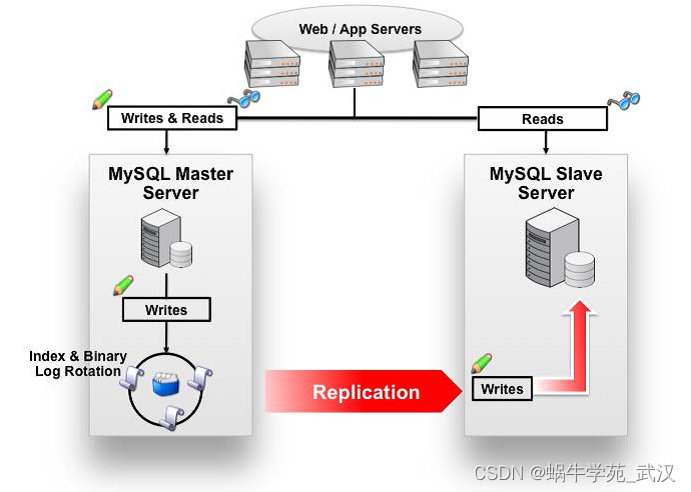
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。高峰时段的一些复杂SQL查询就导致数据库服务器CPU爆表,系统瘫痪,严重情况下可能导致数据库崩溃。
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个读节点的配置
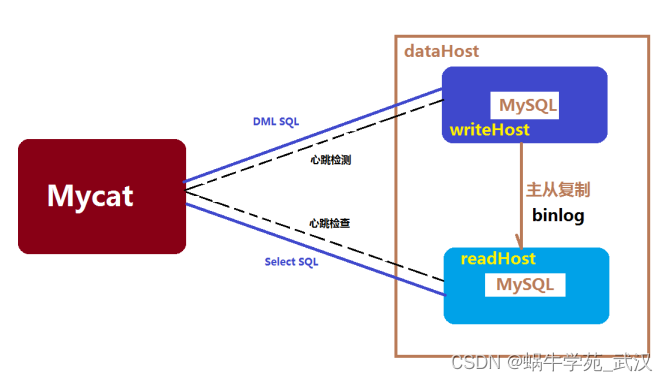
Mycat读写分离和自动切换机制,需要mysql的主从复制机制配合。
七、Mysql的主从复制
- 主服务器配置
修改etc\my.conf文件:
在[mysqld]段下添加:
| #启用二进制日志 log-bin=mysql-bin #服务器唯一ID,一般取IP最后一段 server-id=1000 |
第二步:重启mysql服务
| service mysqld restart |
第三步:建立帐户并授权,给用户授予主从复制的权限。
| mysql>GRANT FILE ON *.* TO 'backup'@'%' IDENTIFIED BY '123456'; mysql>GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'backup'@'%' identified by '123456'; |
#一般不用root帐号,“%”表示所有客户端都可能连,只要帐号,密码正确,此处可用具体客户端IP代替,如192.168.145.226,加强安全。
刷新权限
| mysql> FLUSH PRIVILEGES; |
查看mysql现在有哪些用户
| mysql>select user,host from mysql.user; |
第四步:查询master的状态
| mysql> show master status; mysql> show BINLOG EVENTS in 'mysql-bin.*****' |
- 从服务器配置
第一步:修改my.conf文件
| [mysqld] server-id=1001 |
第二步:配置从服务器
| mysql>change master to master_host='192.168.25.134',master_port=3306,master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=120 |
注意语句中间不要断开,master_port为mysql服务器端口号(无引号),master_user为执行同步操作的数据库账户,“120”无单引号(此处的120就是show master status 中看到的position的值,这里的mysql-bin.000001就是file对应的值)。
第二步:启动从服务器复制功能
| Mysql>start slave; |
第三步:检查从服务器复制功能状态:
| mysql> show slave status |
……………………(省略部分)
Slave_IO_Running: Yes //此状态必须YES
Slave_SQL_Running: Yes //此状态必须YES
……………………(省略部分)
注:Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
| 错误处理: 如果出现此错误: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. 因为是mysql是克隆的系统所以mysql的uuid是一样的,所以需要修改。 |
| 解决方法: 删除/var/lib/mysql/auto.cnf文件,重新启动服务。 |
- MyCat配置
Mycat 支持MySQL主从复制状态绑定的读写分离机制,让读更加安全可靠,配置如下:
| <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost1" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100"> <heartbeat>show slave status</heartbeat> <writeHost host="hostM" url="192.168.25.34:3306" user="root" password="root"> <readHost host="hostS" url="192.168.25.166:3306" user="root" password="root" /> </writeHost> </dataHost> |
- 设置 balance="1"与writeType="0"
Balance参数设置:
1. balance=“0”, 所有读操作都发送到当前可用的writeHost上。
2. balance=“1”,所有读操作都随机的发送到readHost。
3. balance=“2”,所有读操作都随机的在writeHost、readhost上分发
WriteType参数设置:
1. writeType=“0”, 所有写操作都发送到可用的writeHost上。
2. writeType=“1”,所有写操作都随机的发送到readHost。
3. writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
“readHost是从属于writeHost的,即意味着它从那个writeHost获取同步数据,因此,当它所属的writeHost宕机了,则它也不会再参与到读写分离中来,即“不工作了”,这是因为此时,它的数据已经“不可靠”了。基于这个考虑,目前mycat 1.3和1.4版本中,若想支持MySQL一主一从的标准配置,并且在主节点宕机的情况下,从节点还能读取数据,则需要在Mycat里配置为两个writeHost并设置banlance=1。”
- 设置 switchType="2" 与slaveThreshold="100"
switchType 目前有三种选择:
-1:表示不自动切换
1 :默认值,自动切换
2 :基于MySQL主从同步的状态决定是否切换
“Mycat心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType="2" 与slaveThreshold="100",此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制。Mycat心跳机制通过检测 show slave status 中的 "Seconds_Behind_Master", "Slave_IO_Running", "Slave_SQL_Running" 三个字段来确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延。“