选择题
-
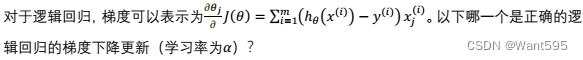
【 正确答案: A D】
A.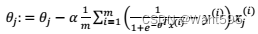
B.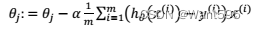
C.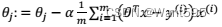
D.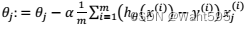
-
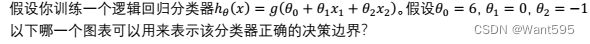
【 正确答案: B】
A.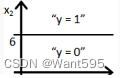
B.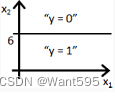
C.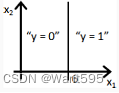
D.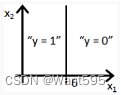
-

【 正确答案: C, D】
A.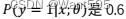
B.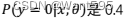
C.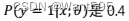
D.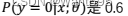
-
假设我们三个类别中心
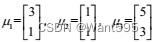 ,若某测试样本为
,若某测试样本为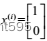 ,它的
c
(
i
)
c^{(i)}
c(i)是多少?
,它的
c
(
i
)
c^{(i)}
c(i)是多少?
【 正确答案: B】
A.1
B.2
C.3
D.不确定 -
假设你训练一个逻辑回归分类器,输入一个新的样本x,输出预测值 h θ ( x ) h_{\theta}(x) hθ(x)=0.35,这意味着 【 正确答案: A B】
A. P ( y = 1 ∣ x ; θ ) = 0.35 P(y=1|x;\theta)=0.35 P(y=1∣x;θ)=0.35
B. P ( y = 0 ∣ x ; θ ) = 0.65 P(y=0|x;\theta)=0.65 P(y=0∣x;θ)=0.65
C. P ( y = 1 ∣ x ; θ ) = 0.65 P(y=1|x;\theta)=0.65 P(y=1∣x;θ)=0.65
D. P ( y = 0 ∣ x ; θ ) = 0.35 P(y=0|x;\theta)=0.35 P(y=0∣x;θ)=0.35 -
以下哪个图你认为假设函数在训练集上存在过拟合?【 正确答案: B】
A.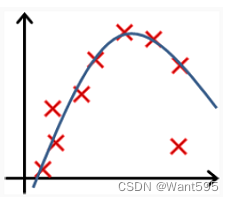
B.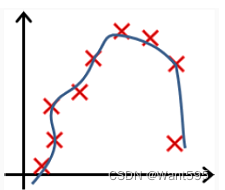
C.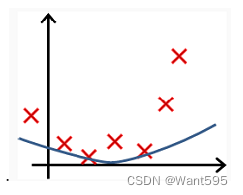
D.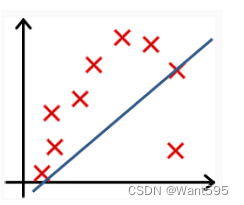
-
以下哪个图你认为假设函数在训练集上存在欠拟合?【正确答案: D】
A.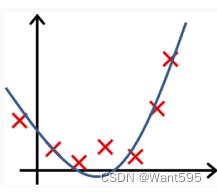
B.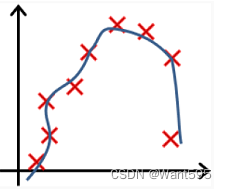
C.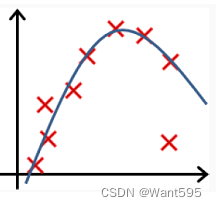
D.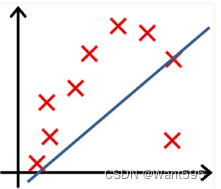
-

【 正确答案: A】
A.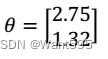
B.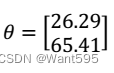
C. AB都是
D. AB都不是 -

【 正确答案: C】
A.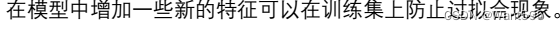
B.
C.
D.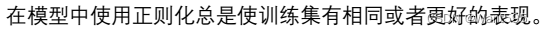
-
以下哪些说法是正确的?【 正确答案: D】
A.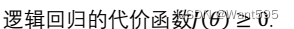
B.
C.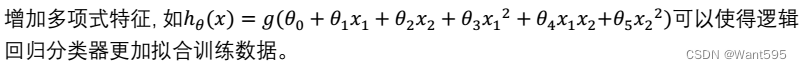
D.
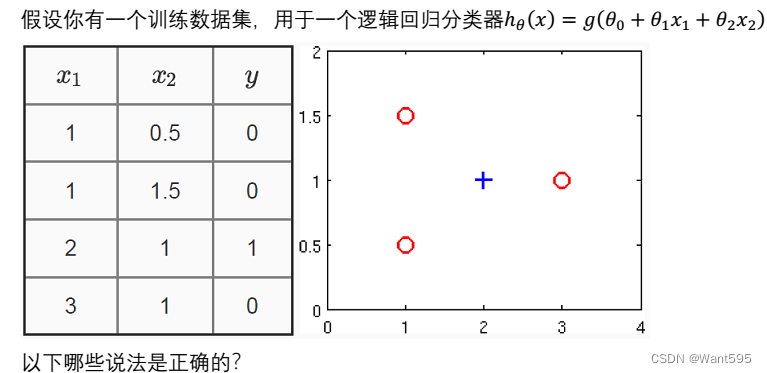
【 正确答案: D】
A.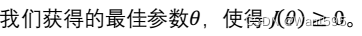
B.
C.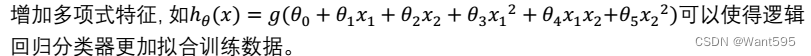
D.
-

【 正确答案: CD】
A. P ( y = 1 ∣ x ; θ ) = 0.6 P(y=1|x;\theta)=0.6 P(y=1∣x;θ)=0.6
B. P ( y = 0 ∣ x ; θ ) = 0.4 P(y=0|x;\theta)=0.4 P(y=0∣x;θ)=0.4
C. P ( y = 1 ∣ x ; θ ) = 0.4 P(y=1|x;\theta)=0.4 P(y=1∣x;θ)=0.4
D. P ( y = 0 ∣ x ; θ ) = 0.6 P(y=0|x;\theta)=0.6 P(y=0∣x;θ)=0.6 -
kNN算法称为K最近邻分类算法。就是需要预测a,就根据最接近a的K的数据的最大特征结果来表示a的类别, 下面关于K的选择正确的是 【 正确答案: A B D】
A.K值较小,则模型复杂度较高,容易发生过拟合,学习的估计误差会增大,预测结果对近邻的实例点非常敏感
B.K值较大可以减少学习的估计误差,但是学习的近似误差会增大
C.与输入实例较远的训练实例也会对预测起作用,使预测发生错误,k值增大模型的复杂度会增加
D.在应用中,k值一般取一个比较小的值,通常采用交叉验证法来来选取最优的K值 -
当发现机器学习模型过拟合时,以下操作正确的是 【 正确答案: A B C】
A.降低特征维度
B.增加样本数量
C.添加正则项
D.增加特征维度 -
不平衡是指:输入实例的K邻近点中,大数量类别的点会比较多,但其实可能都离实例较远,这样会影响最后的分类的精度,下面可以解决不平衡问题的是: 【 正确答案: A】
A. 对样本点根据距离及逆行加权,近处节点赋予较大权重,反之较小权重
B. 选择较大的K值
C. 采用KD树优化
D. 选择较小的K值 -
关于KNN的缺点正确的是【 正确答案: A】
A. 计算量大
B. 存在类别不平衡问题
C. 需要大量内存
D. 计算结果好坏依赖于K的选择 -
关于 KNN的优点正确的是【 正确答案: A】
A. KNN既可以做非线性分类又可以做回归
B. 准确率高
C. 原理简单,对数据没有假设
D. 对离群点不敏感 -
KNN的三要素是下面哪三项【 正确答案: BCD】
A. 判断数据是否有标签
B. 距离度量的方式
C. 分类和回归决策规则
D. k值的选取 -
KNN算法称为K最近邻分类算法,当需要预测样本a的类别时,就可以根据最接近a的K个数据来近似表示a,下面关于K的选择正确的是 【 正确答案: ABC】
A. K值较小,则模型复杂度较高,容易发生过拟合,学习的估计误差会增大,预测结果对近邻的实例点非常敏感
B. K值较大可以减少学习的估计误差,但是学习的近似误差会增大
C. 在应用中,k值一般取一个比较小的值,通常采用交叉验证法来来选取最优的K值
D. 与输入实例较远的训练实例也会对预测起作用,使预测发生错误,k值增大模型的复杂度会增加 -
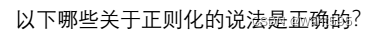
【 正确答案: A】
A.
B.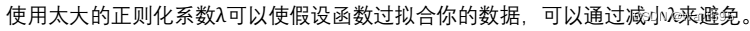
C.
D.
判断题
-
K近邻算法是一种无监督学习算法。
【正确答案:错误】 -
K近邻算法对数据集中特征的尺度不敏感。
【正确答案:错误】 -
K近邻算法中的K值表示特征空间的维度数。
【正确答案:错误】 -
K近邻算法可用于回归问题。
【正确答案:正确】 -
K近邻算法中,欧氏距离越小,表示样本越相似。
【正确答案:正确】 -
K近邻算法的计算开销主要受训练集大小影响。
【正确答案:正确】 -
逻辑回归是一种回归模型。
【正确答案:错误】 -
分类模型一般采用均方损失函数,回归模型通常采用交叉熵损失函数。
【正确答案:错误】 -
K-MEANS算法若选择了不合适的初始聚类中心,可能会导致算法陷入局部最优。
【正确答案:正确】 -
学习曲线可以用来判断模型是否存在过拟合或欠拟合。
【正确答案:正确】 -
K近邻算法的超参数K的选择不受训练集大小和数据维度的影响。
【正确答案:错误】 -
K近邻算法的决策边界是特征空间中两个类别的中间线。
【正确答案:错误】 -
K近邻算法在处理不平衡数据集时对多数类别更为敏感。
【正确答案:正确】
简答题
-
什么是k均值聚类算法,它是如何工作的?
- k均值聚类算法是一种常用的聚类分析方法。
- 通过将数据分配给最近的聚类中心将数据划分为k个类别,并且不断更新聚类的中心,直至聚类稳定。
-
KNN算法中的K值选择对结果有何影响?如何选择合适的K值?
- KNN算法中的K值是指选择多少个邻居来参与投票或平均。
- K值的选择直接影响算法的性能。
- 通过交叉验证等技术.
-
什么是K近邻算法(KNN)?它的工作原理是什么?
- K近邻算法(KNN)是一种基本的监督学习算法,用于分类和回归问题。
- KNN的工作原理可以概括为:“近朱者赤,近墨者黑”,即一个样本的类别或数值很可能与其周围的邻居相似。
-
什么是查准率(精确率)?什么是查全率(召回率)?如何权衡查准率(精确率)与查全率(召回率)?
- 查准率(Precision):查准率是指模型预测为正类别的样本中,真正为正类别的比例。
- 查全率(Recall):查全率是指所有正类别样本中,被模型正确预测为正类别的比例。