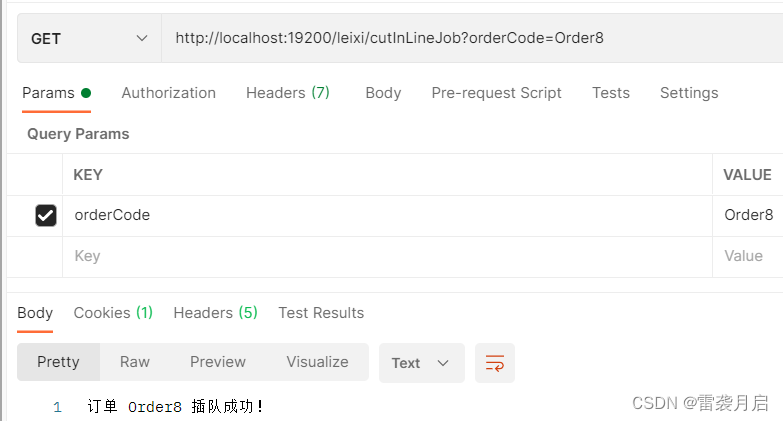
自2022年年末英伟达发布4090芯片以来,这款产品凭借着其优异的性能迅速在科技界占据了一席之地。现如今,不论是在游戏体验、内容创作能力方面还是模型精度提升方面,4090都是一个绕不过去的名字。而A100作为早些发布的产品,其优异的能力和适配性已经为它打下了良好的口碑。RTX 4090芯片和A100芯片虽然都是高性能的GPU,但它们在设计理念、目标市场和性能特点上有着明显的区别,而本篇文章将简单概述两者的区别同时介绍一下二者的特性。
GPU 训练性能和成本对比
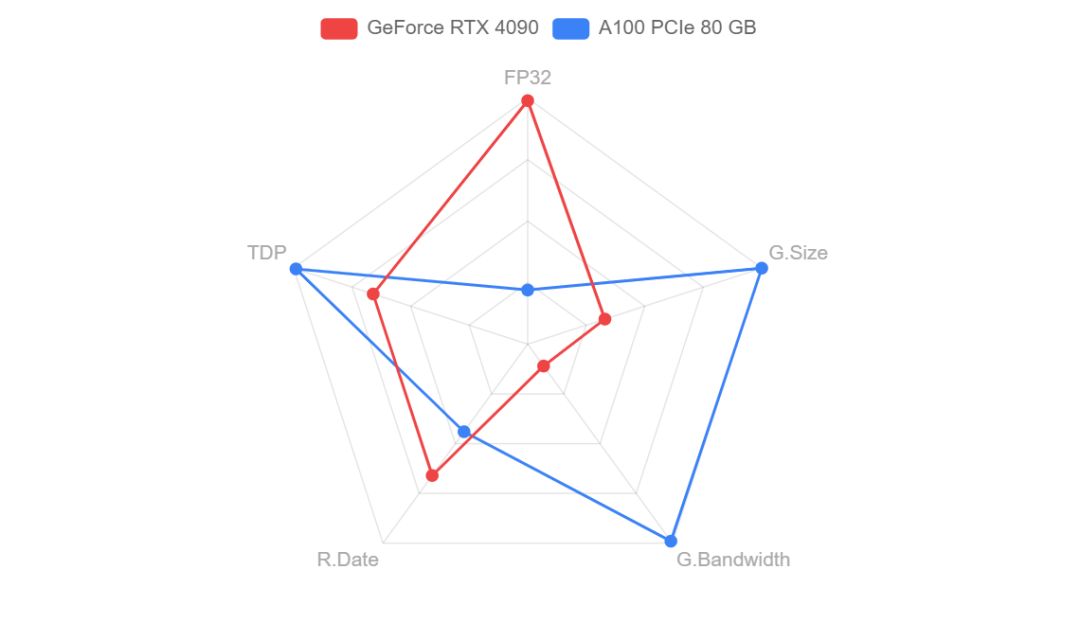
虽然A100被称为深度学习神器,但是不一定代表他的性能任何时候都超过其他显卡,A100对标的是RTX 3090,都是Ampere架构的,而RTX 4090作为RTX 3090的升级版,架构是Ada Lovelace,单卡性能至少提升60%以上,RTX 4090在理论上核心性能远强于A100,下面这2个参数对比图也可以很直观的看出2张卡的差距。
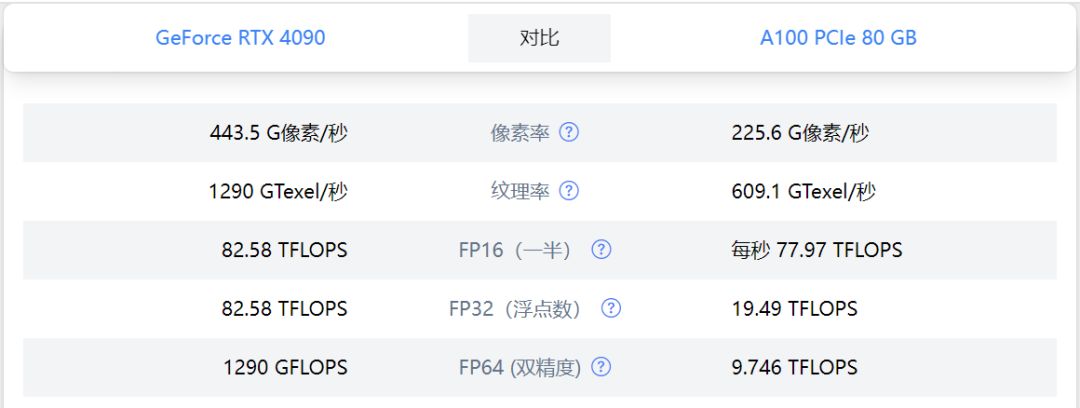
RTX 4090与A100的FP16性能比较
根据之前的讨论,RTX 4090的FP16性能约为82.58 Tflops,而A100的FP16性能可达约312 Tflops。不过,随后我们发现实际使用中4090的FP16性能接近于A100。这可能是因为不同的测试条件和使用场景会影响性能测量,或者由于不同的硬件版本和配置。
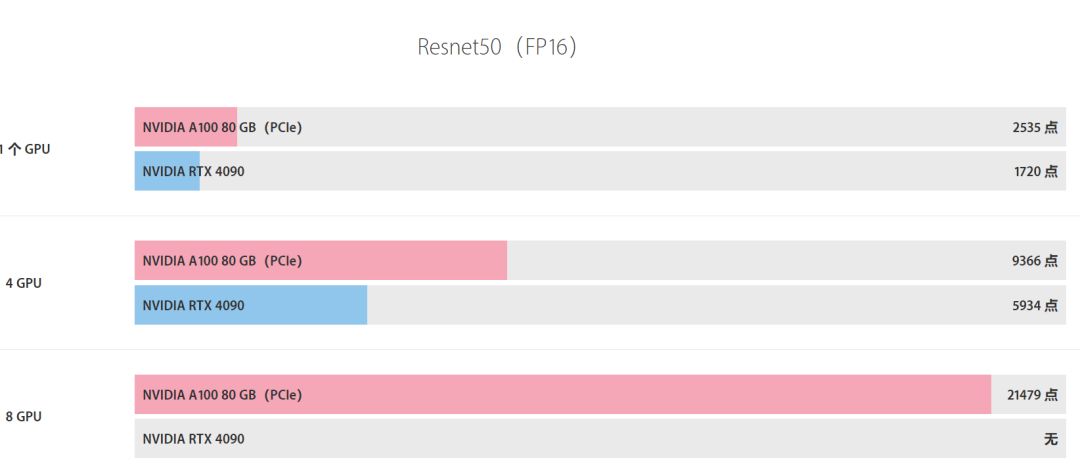
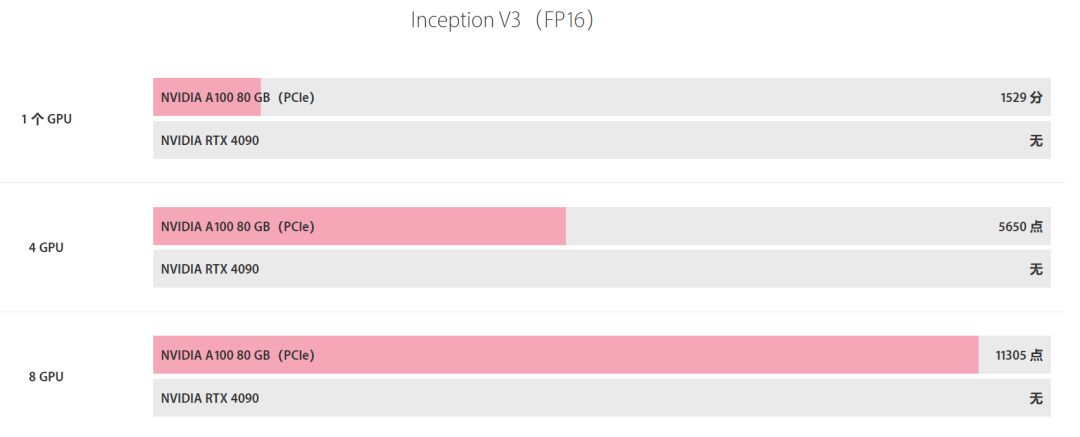
从理论规格上看,A100确实在FP16上显示出更高的性能,但实际应用性能可能会有所不同,取决于具体任务和软件优化。
结论
既然 4090 单卡训练的性价比这么高,为啥不能用来做大模型训练呢?抛开不允许游戏显卡用于数据中心这样的许可证约束不谈,从技术上讲,根本原因是大模型训练需要高性能的通信。在大模型训练方面,A100比4090表现的更加优秀,但是在推理(inference/serving)方面,选择用 4090 芯片不仅可行,在性价比上还能比H100 稍高。而如果4090芯片对其进行极致优化,其性价比甚至可以达到 H100芯片 的 2 倍。
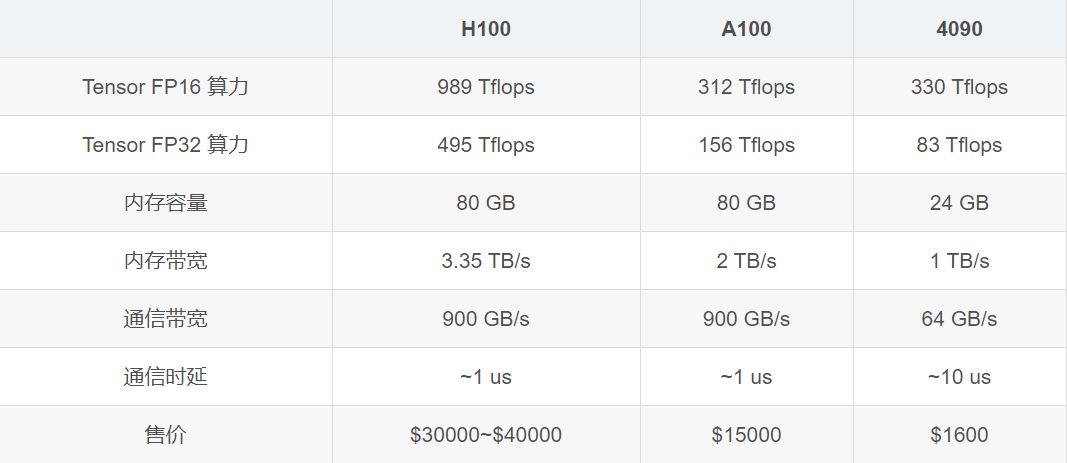
事实上,H100/A100 和 4090 最大的区别就在通信和内存上,算力差距不大。
在这小编向大家推荐一款来自UCloud优刻得的一款4090云服务器,相比较于市面上的一些GPU共享算力平台的资源,不仅价格实惠,性价比高,性能强劲 的同时还拥有独立IP、预装主流大模型及环境镜像,支持7X24的小时的售后服务。同时,UCloud还推出了9.9元/天的4090特惠,方便大家体验使用 价格非常香,可以放心上车!

高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0624_shemei