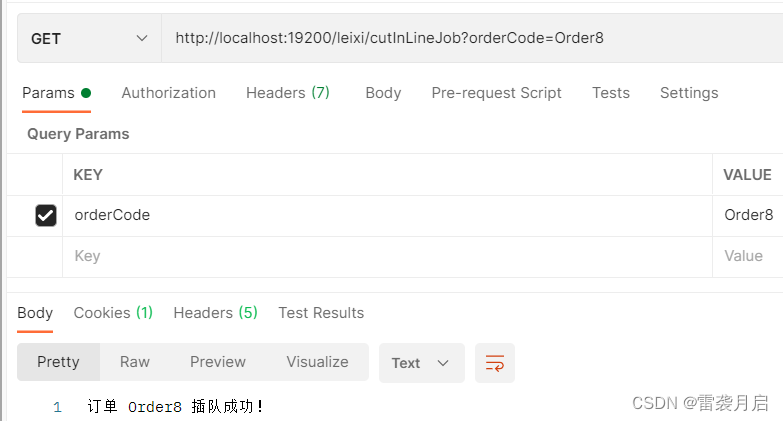
官方代码仓库:https://github.com/browserify/browserify
在github闲逛的时候,发现了一个很神奇的项目,这个项目的特点就是实用纯vue和js代码实现了直播间消息的获取,获取的方式就是建立websocket连接,然后接收消息,这没什么特别的,但是特别的地方是什么?要知道这些消息全都是protobuf传输的,需要使用proto解析的,这个仓库的神器之处竟然是将proto文件解析成了浏览器可以直接使用的js代码并引入到浏览器中使用: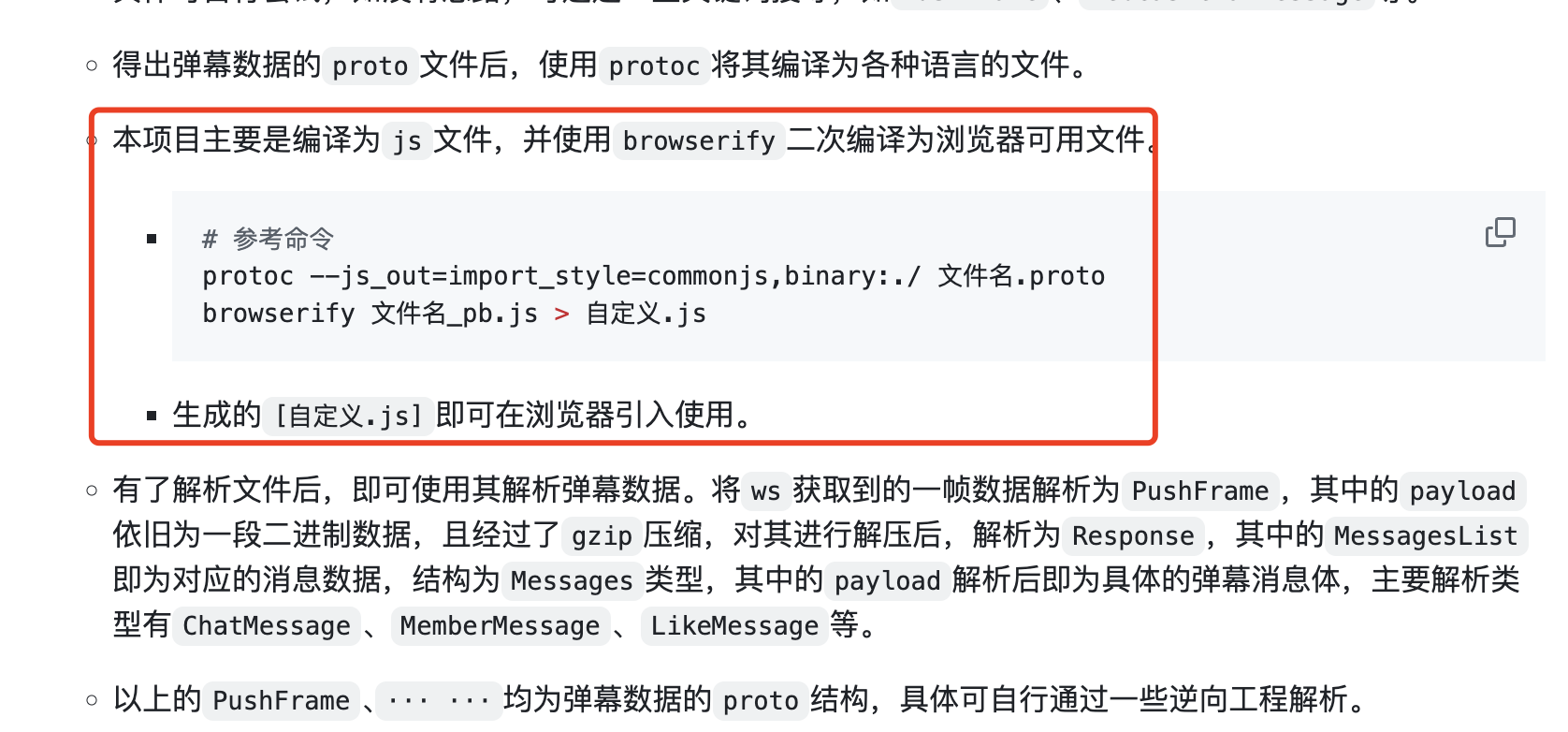
browerify妙用
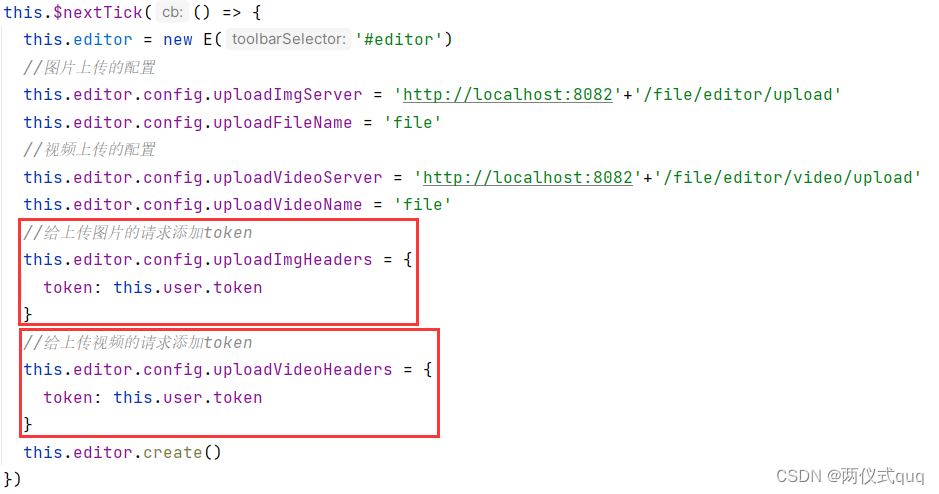
我看了一下它的代码,也是厉害的,因为某音的直播websocket连接需要用到axios/pako/webmssdk这几个依赖库,还有一个proto文件,他这里竟然直接将这些依赖包直接引入到index.html文件中了,然后最神奇的是,竟然直接在浏览器控制台可以用proto里面的协议了:
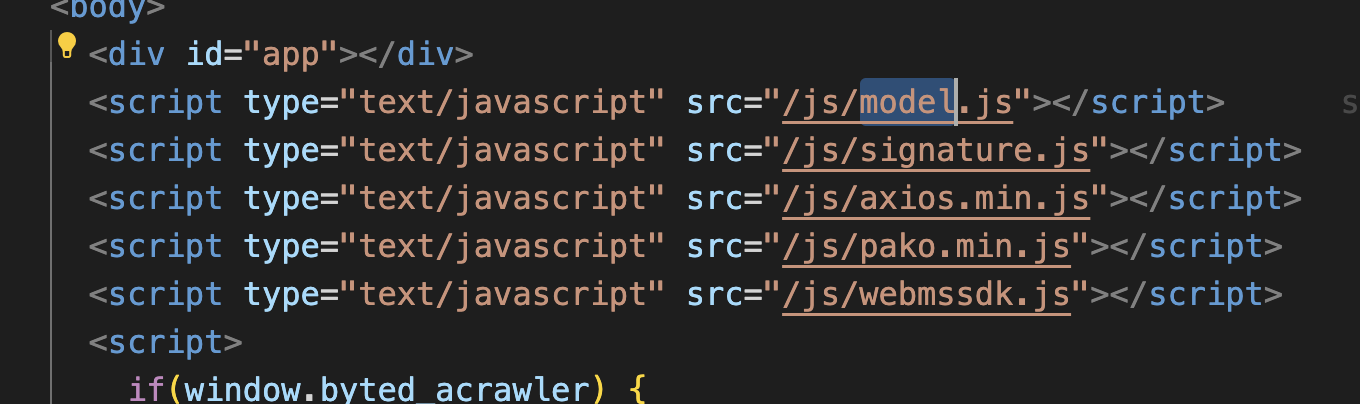
启动服务后,到浏览器控制台:

这样做的好处是什么呢?
直接在代码里面可以使用proto或者pako,就不需要引入了,是不是非常方便。这个时候你在项目中使用的时候,可能会遇到:找不到名称“proto” 的提示,这个提示是正常的,因为你确实没有引入或者声明proto啊
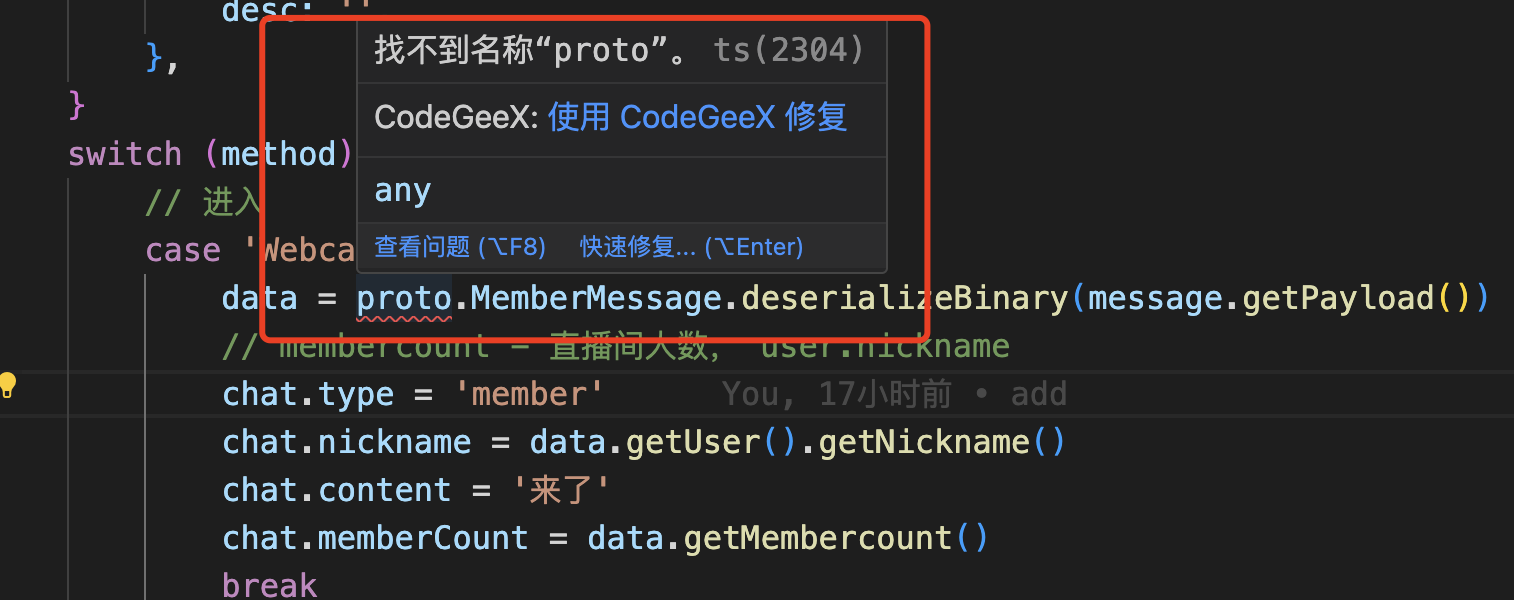
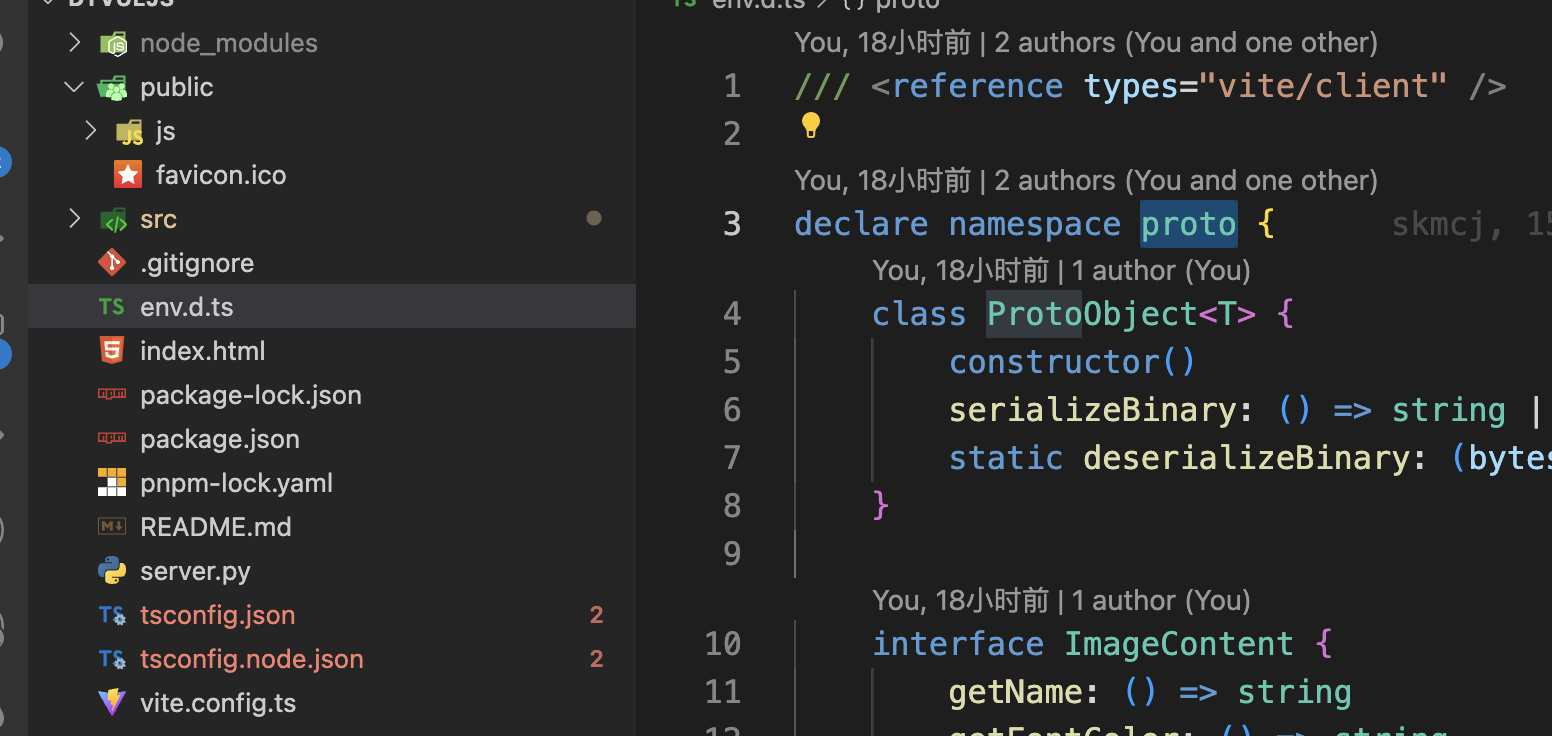
解决这个问题的办法,就是在env.d.ts里面声明一下:
Commonjs规范及Node模块
Node在实现中并非完全按照CommonJS规范实现,而是对模块规范进行了一定的取舍,同时也增加了少许自身需要的特性。nodejs是区别于javascript的,在javascript中的顶层对象是window,而在node中的顶层对象是global。
[注意]实际上,javascript也存在global对象,只是其并不对外访问,而使用window对象指向global对象而已。
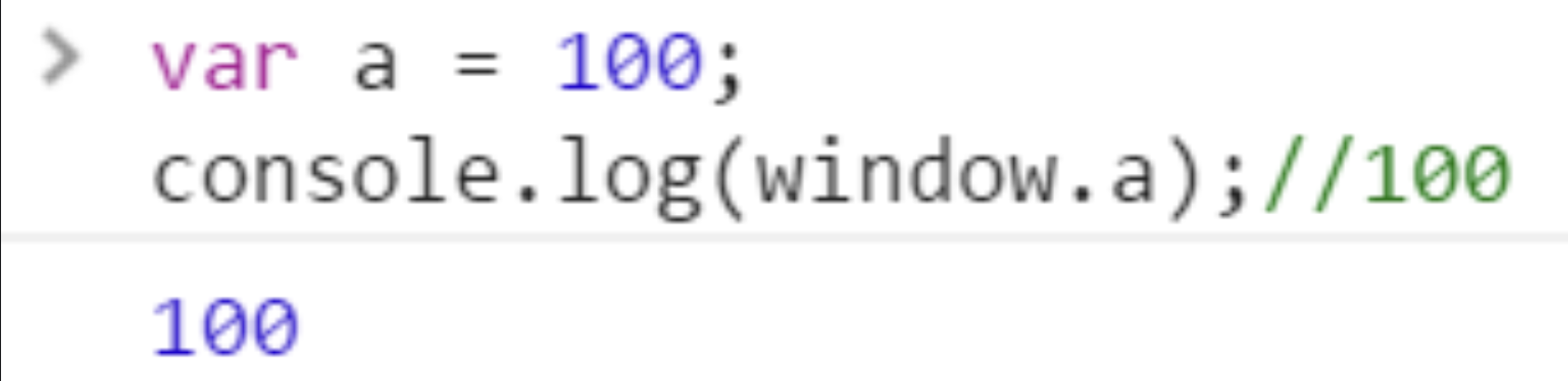
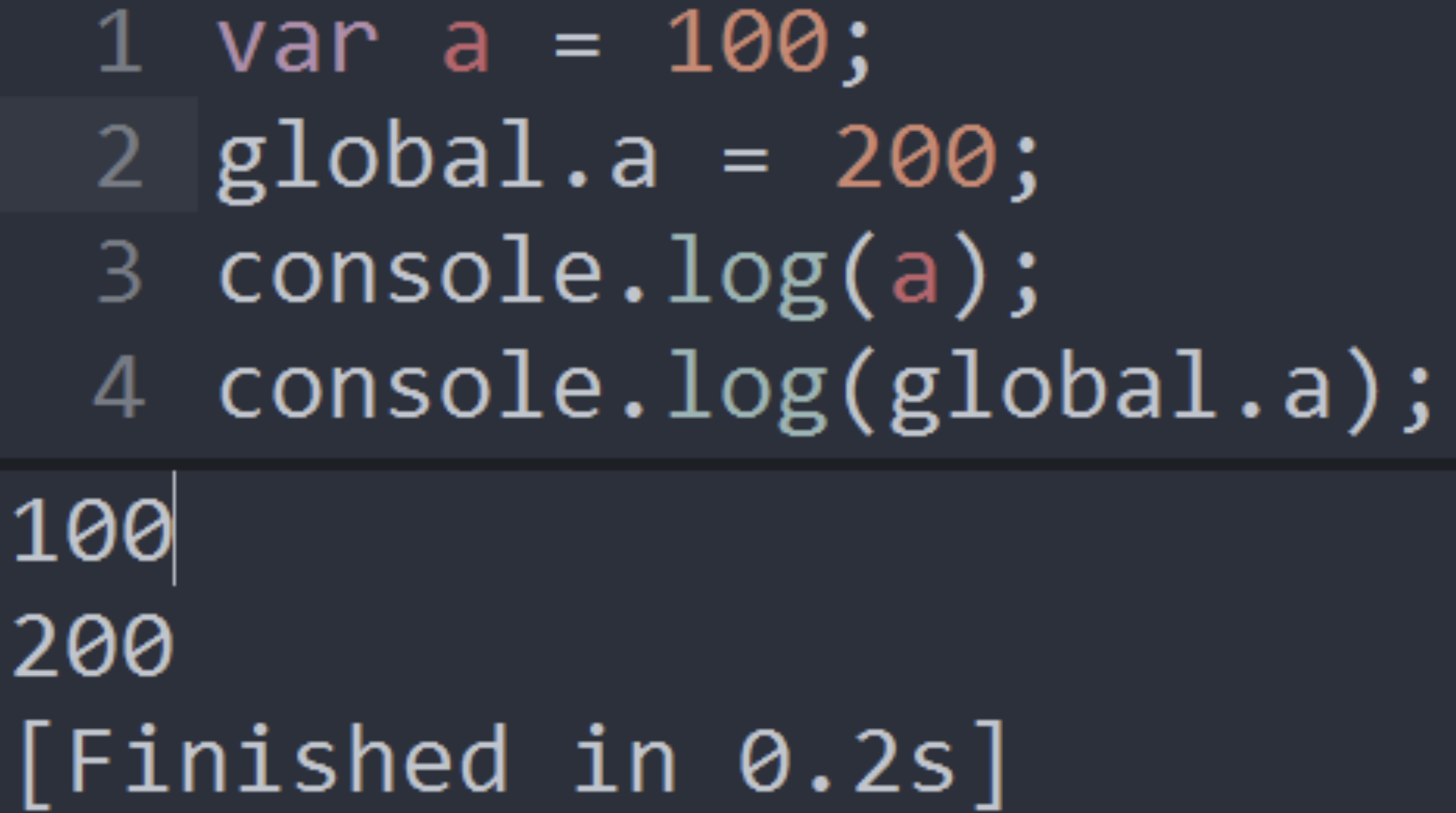
在javascript中,通过var a = 100;是可以通过window.a来得到100的:
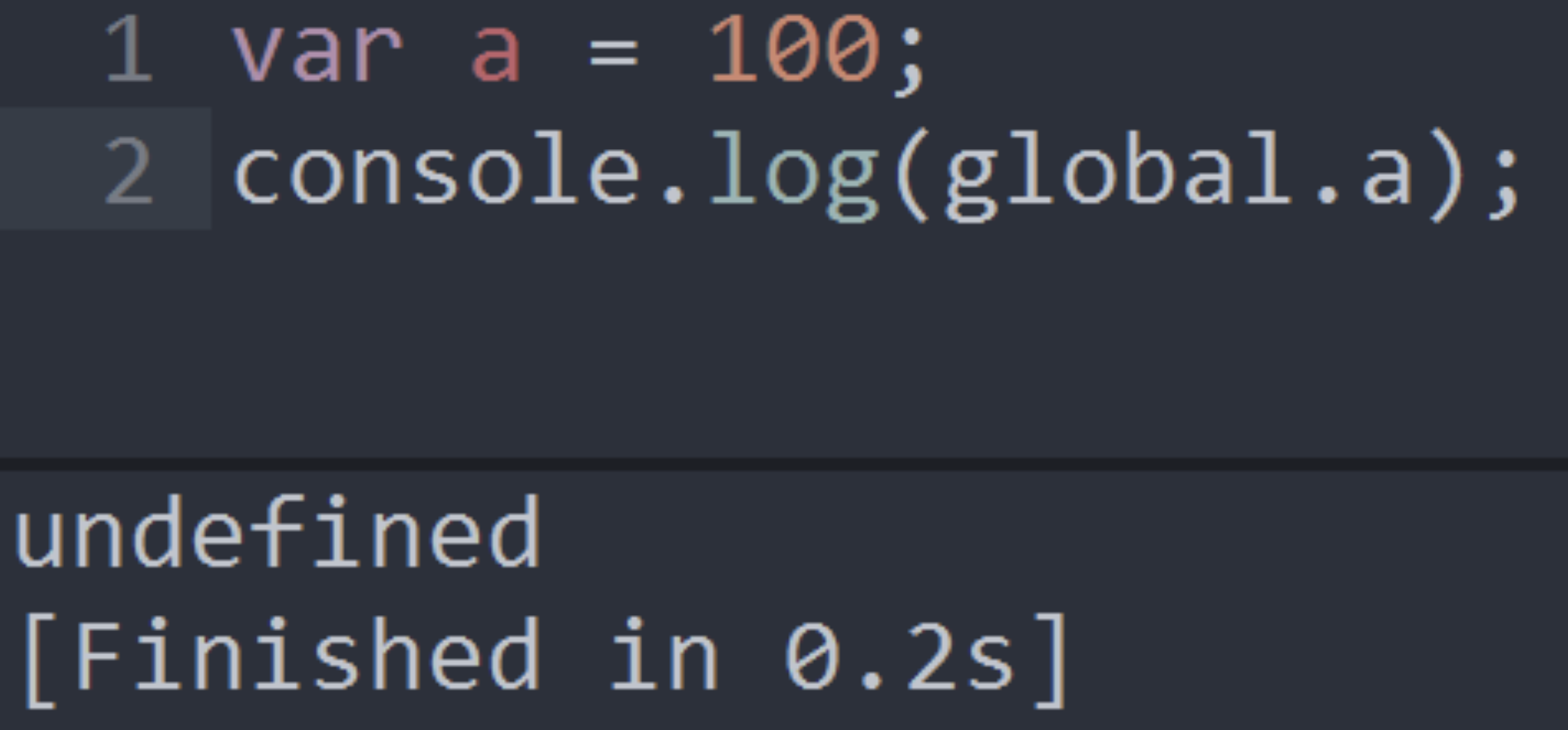
但在nodejs中,是不能通过global.a来访问,得到的是undefined
这是因为var a = 100;这个语句中的变量a,只是模块范围内的变量a,而不是global对象下的a。
在nodejs中,一个文件就是一个模块,每个模块都有自己的作用域。使用var来声明的一个变量,它并不是全局的,而是属于当前模块下。如果要在全局作用域下声明变量,则如下所示:
Node中模块分为两类:一类是Node提供的模块,称为核心模块;另一类是用户编写的模块,称为文件模块。核心模块部分在Node源代码的编译过程中,编译进了二进制执行文件。在Node进程启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块引入时,文件定位和编译执行这两个步骤可以省略掉,并且在路径分析中优先判断,所以它的加载速度是最快的。文件模块则是在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。
接下来,我们展开详细的模块加载过程,在javascript中,加载模块使用script标签即可,而在nodejs中,如何在一个模块中,加载另一个模块呢?使用require()方法来引入:
缓存加载
再展开介绍require()方法的标识符分析之前,需要知道,与前端浏览器会缓存静态脚本文件以提高性能一样,Node对引入过的模块都会进行缓存,以减少二次引入时的开销。不同的地方在于,浏览器仅仅缓存文件,而Node缓存的是编译和执行之后的对象。不论是核心模块还是文件模块,require()方法对相同模块的二次加载都一律采用缓存优先的方式,这是第一优先级的。不同之处在于核心模块的缓存检查先于文件模块的缓存检查。
标识符分析
require()方法接受一个标识符作为参数。在Node实现中,正是基于这样一个标识符进行模块查找的。模块标识符在Node中主要分为以下几类:[1]核心模块,如http、fs、path等;[2].或..开始的相对路径文件模块;[3]以/开始的绝对路径文件模块;[4]非路径形式的文件模块,如自定义的connect模块
根据参数的不同格式,require命令去不同路径寻找模块文件
1、如果参数字符串以“/”开头,则表示加载的是一个位于绝对路径的模块文件。比如,require('/home/marco/foo.js')将加载/home/marco/foo.js
2、如果参数字符串以“./”开头,则表示加载的是一个位于相对路径(跟当前执行脚本的位置相比)的模块文件。比如,require('./circle')将加载当前脚本同一目录的circle.js
3、如果参数字符串不以“./“或”/“开头,则表示加载的是一个默认提供的核心模块(位于Node的系统安装目录中),或者一个位于各级node_modules目录的已安装模块(全局安装或局部安装)
[注意]如果是当前路径下的文件模块,一定要以./开头,否则nodejs会试图去加载核心模块,或node_modules内的模块
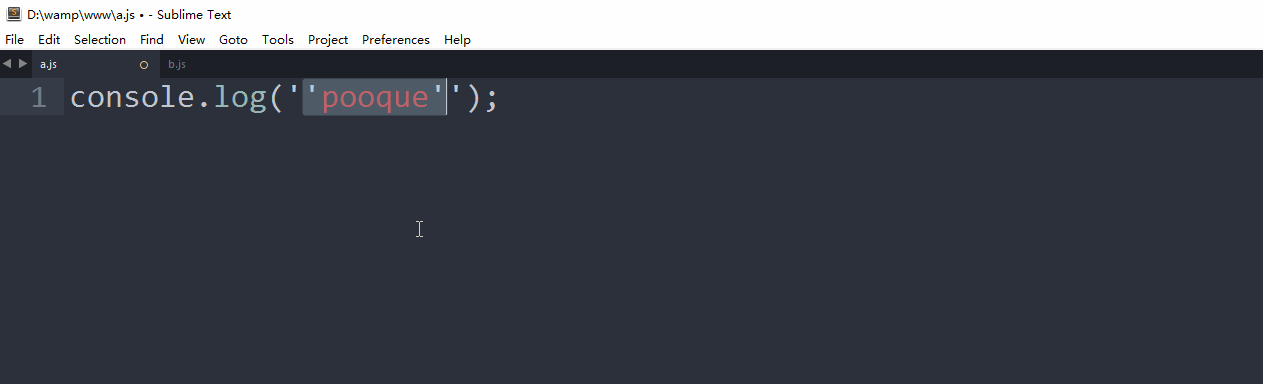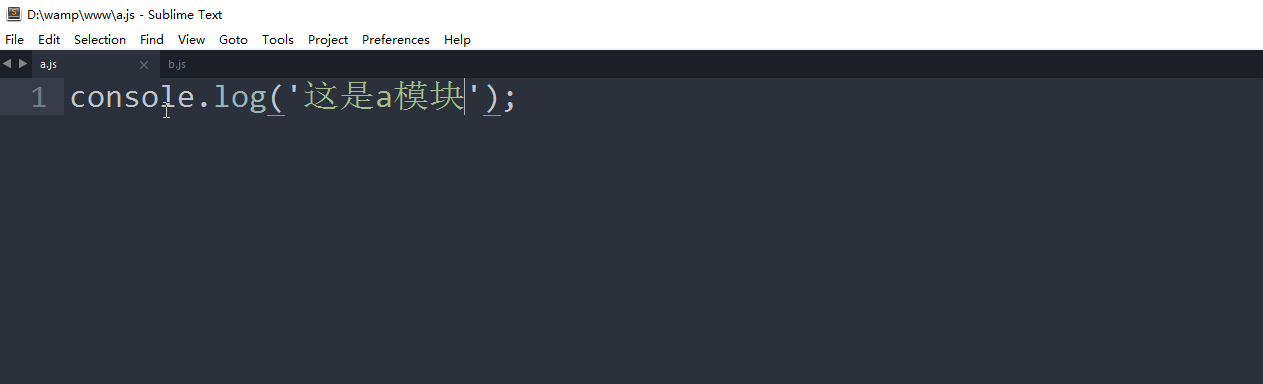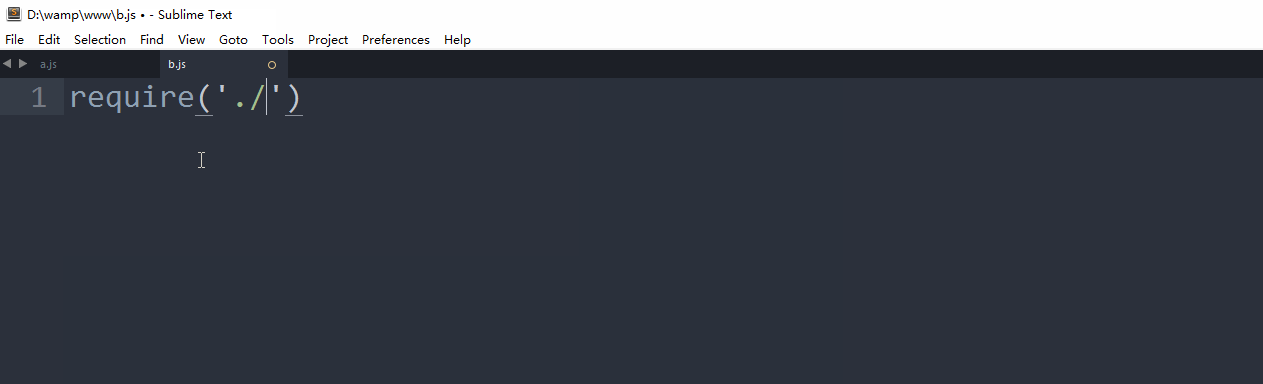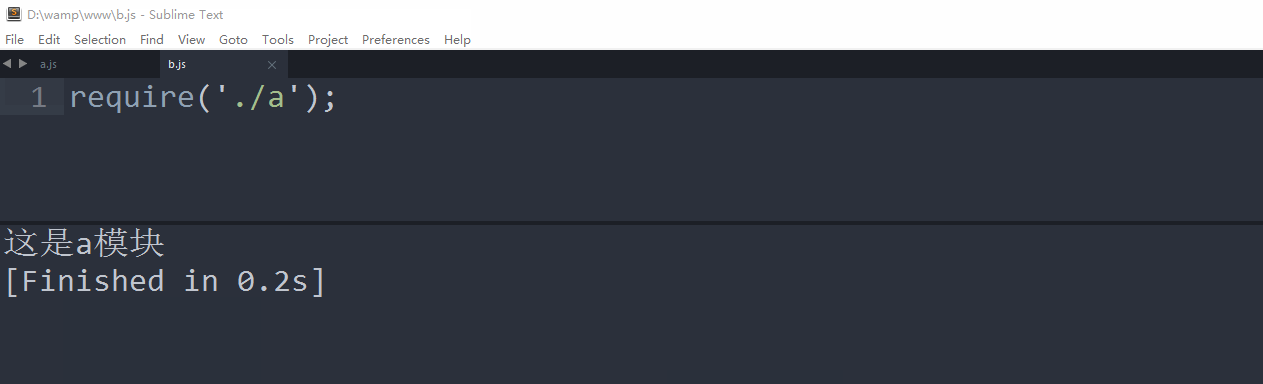
//a.js
console.log('aaa');
//b.js
require('./a');//'aaa'
require('a');//报错文件扩展名分析
require()在分析标识符的过程中,会出现标识符中不包含文件扩展名的情况。CommonJS模块规范也允许在标识符中不包含文件扩展名,这种情况下,Node会先查找是否存在没有后缀的该文件,如果没有,再按.js、.json、.node的次序补足扩展名,依次尝试,在尝试的过程中,需要调用fs模块同步阻塞式地判断文件是否存在。因为Node是单线程的,所以这里是一个会引起性能问题的地方。小诀窍是:如果是.node和.json文件,在传递给require()的标识符中带上扩展名,会加快一点速度。另一个诀窍是:同步配合缓存,可以大幅度缓解Node单线程中阻塞式调用的缺陷。
目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,这在引入自定义模块和逐个模块路径进行查找时经常会出现,此时Node会将目录当做一个包来处理,在这个过程中,Node对CommonJS包规范进行了一定程度的支持。首先,Node在当前目录下查找package.json(CommonJS包规范定义的包描述文件),通过JSON.parse()解析出包描述对象,从中取出main属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤,而如果main属性指定的文件名错误,或者压根没有package.json文件,Node会将index当做默认文件名,然后依次查找index.js、index.json、index.node。如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数组都被遍历完毕,依然没有查找到目标文件,则会抛出查找失败的异常。
访问变量
如何在一个模块中访问另外一个模块中定义的变量呢?
1.module是最容易想到的方法,把一个模块定义的变量复制到全局环境global中,然后另一个模块访问全局环境即可。这种方法虽然简单,但由于会污染全局环境,不推荐使用
//a.js
var a = 100;
global.a = a;
//b.js
require('./a');
console.log(global.a);//1002.module而常用的方法是使用nodejs提供的模块对象Module,该对象保存了当前模块相关的一些信息
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}module.id 模块的识别符,通常是带有绝对路径的模块文件名。
module.filename 模块的文件名,带有绝对路径。
module.loaded 返回一个布尔值,表示模块是否已经完成加载。
module.parent 返回一个对象,表示调用该模块的模块。
module.children 返回一个数组,表示该模块要用到的其他模块。
module.exports 表示模块对外输出的值。
3.exports:module.exports属性表示当前模块对外输出的接口,其他文件加载该模块,实际上就是读取module.exports变量:
//a.js
var a = 100;
module.exports.a = a;
//b.js
var result = require('./a');
console.log(result);//'{ a: 100 }'为了方便,Node为每个模块提供一个exports变量,指向module.exports。造成的结果是,在对外输出模块接口时,可以向exports对象添加方法
console.log(module.exports === exports);//true[注意]不能直接将exports变量指向一个值,因为这样等于切断了exports与module.exports的联系。
模块编译
编译和执行是模块实现的最后一个阶段。定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同,具体如下所示
js文件——通过fs模块同步读取文件后编译执行
node文件——这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件
json文件——通过fs模块同步读取文件后,用JSON.parse()解析返回结果
其余扩展名文件——它们都被当做.js文件载入
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能
根据不同的文件扩展名,Node会调用不同的读取方式,如.json文件的调用如下:
// Native extension for .json
Module._extensions['.json'] = function(module, filename) {
var content = NativeModule.require('fs').readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};其中,Module._extensions会被赋值给require()的extensions属性,所以通过在代码中访问require.extensions可以知道系统中已有的扩展加载方式。编写如下代码测试一下:
console.log(require.extensions);得到的执行结果如下:
{ '.js': [Function], '.json': [Function], '.node': [Function] }在确定文件的扩展名之后,Node将调用具体的编译方式来将文件执行后返回给调用者。
JavaScript模块的编译
回到CommonJS模块规范,我们知道每个模块文件中存在着require、exports、module这3个变量,但是它们在模块文件中并没有定义,那么从何而来呢?甚至在Node的API文档中,我们知道每个模块中还有filename、dirname这两个变量的存在,它们又是从何而来的呢?如果我们把直接定义模块的过程放诸在浏览器端,会存在污染全局变量的情况。
事实上,在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function(exports, require, module, filename, dirname) {\n,在尾部添加了\n});一个正常的JavaScript文件会被包装成如下的样子:
(function (exports, require, module, filename, dirname) {
var math = require('math');
exports.area = function (radius) {
return Math.PI * radius * radius;
};
});这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象。最后,将当前模块对象的exports属性、require()方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function()执行。这就是这些变量并没有定义在每个模块文件中却存在的原因。在执行之后,模块的exports属性被返回给了调用方。exports属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量或属性则不可直接被调用。至此,require、exports、module的流程已经完整,这就是Node对CommonJS模块规范的实现。
C/C++模块的编译
Node调用process.dlopen()方法进行加载和执行。在Node的架构下,dlopen()方法在Windows和*nix平台下分别有不同的实现,通过libuv兼容层进行了封装。
实际上,.node的模块文件并不需要编译,因为它是编写C/C++模块之后编译生成的,所以这里只有加载和执行的过程。在执行的过程中,模块的exports对象与.node模块产生联系,然后返回给调用者。C/C++模块给Node使用者带来的优势主要是执行效率方面的,劣势则是C/C++模块的编写门槛比JavaScript高。
JSON文件的编译
.json文件的编译是3种编译方式中最简单的。Node利用fs模块同步读取JSON文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋给模块对象的exports,以供外部调用。
JSON文件在用作项目的配置文件时比较有用。如果你定义了一个JSON文件作为配置,那就不必调用fs模块去异步读取和解析,直接调用require()引入即可。此外,你还可以享受到模块缓存的便利,并且二次引入时也没有性能影响。
CommonJS
在介绍完Node的模块实现之后,回过头来再学习下CommonJS规范,相对容易理解。
CommonJS规范的提出,主要是为了弥补当前javascript没有标准的缺陷,使其具备开发大型应用的基础能力,而不是停留在小脚本程序的阶段。
CommonJS对模块的定义十分简单,主要分为模块引用、模块定义和模块标识3个部分。
模块引用:
var math = require('math');在CommonJS规范中,存在require()方法,这个方法接受模块标识,以此引入一个模块的API到当前上下文中。
模块定义:
在模块中,上下文提供require()方法来引入外部模块。对应引入的功能,上下文提供了exports对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。在模块中,还存在一个module对象,它代表模块自身,而exports是module的属性。在Node中,一个文件就是一个模块,将方法挂载在exports对象上作为属性即可定义导出的方式:
// math.js
exports.add = function () {
var sum = 0, i = 0,args = arguments, l = args.length;
while (i < l) {
sum += args[i++];
}
return sum;
};在另一个文件中,我们通过require()方法引入模块后,就能调用定义的属性或方法了:
// program.js
var math = require('math');
exports.increment = function (val) {
return math.add(val, 1);
};模块标识
模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径,或者绝对路径。它可以没有文件名后缀.js
模块的定义十分简单,接口也十分简洁。它的意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出功能以顺畅地连接上下游依赖。每个模块具有独立的空间,它们互不干扰,在引用时也显得干净利落。
CommonJS格式转换
Browserify是目前最常用的CommonJS格式转换的工具,Nodejs的模块是基于CommonJS规范实现的,可不可以应用在浏览器环境中呢?
var math = require('math');
math.add(2, 3);第二行math.add(2, 3),在第一行require('math')之后运行,因此必须等math.js加载完成。也就是说,如果加载时间很长,整个应用就会停在那里等。这对服务器端不是一个问题,因为所有的模块都存放在本地硬盘,可以同步加载完成,等待时间就是硬盘的读取时间。但是,对于浏览器,这却是一个大问题,因为模块都放在服务器端,等待时间取决于网速的快慢,可能要等很长时间,浏览器处于"假死"状态。而browserify这样的一个工具,可以把nodejs的模块编译成浏览器可用的模块,解决上面提到的问题。
实现示例
Browserify是目前最常用的CommonJS格式转换的工具,请看一个例子,b.js模块加载a.js模块
// a.js
var a = 100;
module.exports.a = a;
// b.js
var result = require('./a');
console.log(result.a);index.html直接引用b.js会报错,提示require没有被定义
//index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<script src="b.js"></script>
</body>
</html>报错提示:这时,就要使用Browserify了

安装Browserify
npm install -g browserify转换b.js文件:
使用下面的命令,就能将b.js转为浏览器可用的格式bb.js
browserify b.js > bb.js查看bb.js,browserify将a.js和b.js这两个文件打包为bb.js,使其在浏览器端可以运行:
(function e(t,n,r){function s(o,u){if(!n[o]){if(!t[o]){var a=typeof require=="function"&&require;if(!u&&a)return a(o,!0);if(i)return i(o,!0);var f=new Error("Cannot find module '"+o+"'");throw f.code="MODULE_NOT_FOUND",f}var l=n[o]={exports:{}};t[o][0].call(l.exports,function(e){var n=t[o][1][e];return s(n?n:e)},l,l.exports,e,t,n,r)}return n[o].exports}var i=typeof require=="function"&&require;for(var o=0;o<r.length;o++)s(r[o]);return s})({1:[function(require,module,exports){
var a = 100;
module.exports.a = a;
},{}],2:[function(require,module,exports){
var result = require('./a');
console.log(result.a);
},{"./a":1}]},{},[2]);index.html引用bb.js,控制台显示100
//index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<script src="bb.js"></script>
</body>
</html>控制台显示:

Browserify原理
Browserify到底做了什么?安装一下browser-unpack,就能清楚原理了
npm install browser-unpack -g然后,使用下列命令,将前面生成的bb.js解包
browser-unpack < bb.js解包之后的内容:

可以看到,browerify将所有模块放入一个数组,id属性是模块的编号,source属性是模块的源码,deps属性是模块的依赖。
因为b.js里面加载了a.js,所以deps属性就指定./a对应1号模块。执行的时候,浏览器遇到require('./a')语句,就自动执行1号模块的source属性,并将执行后的module.exports属性值输出
browerify将a.js和b.js打包,并生成bb.js,browser-unpack将bb.js解包,是一个逆向的过程。但实际上,bb.js依然存在。