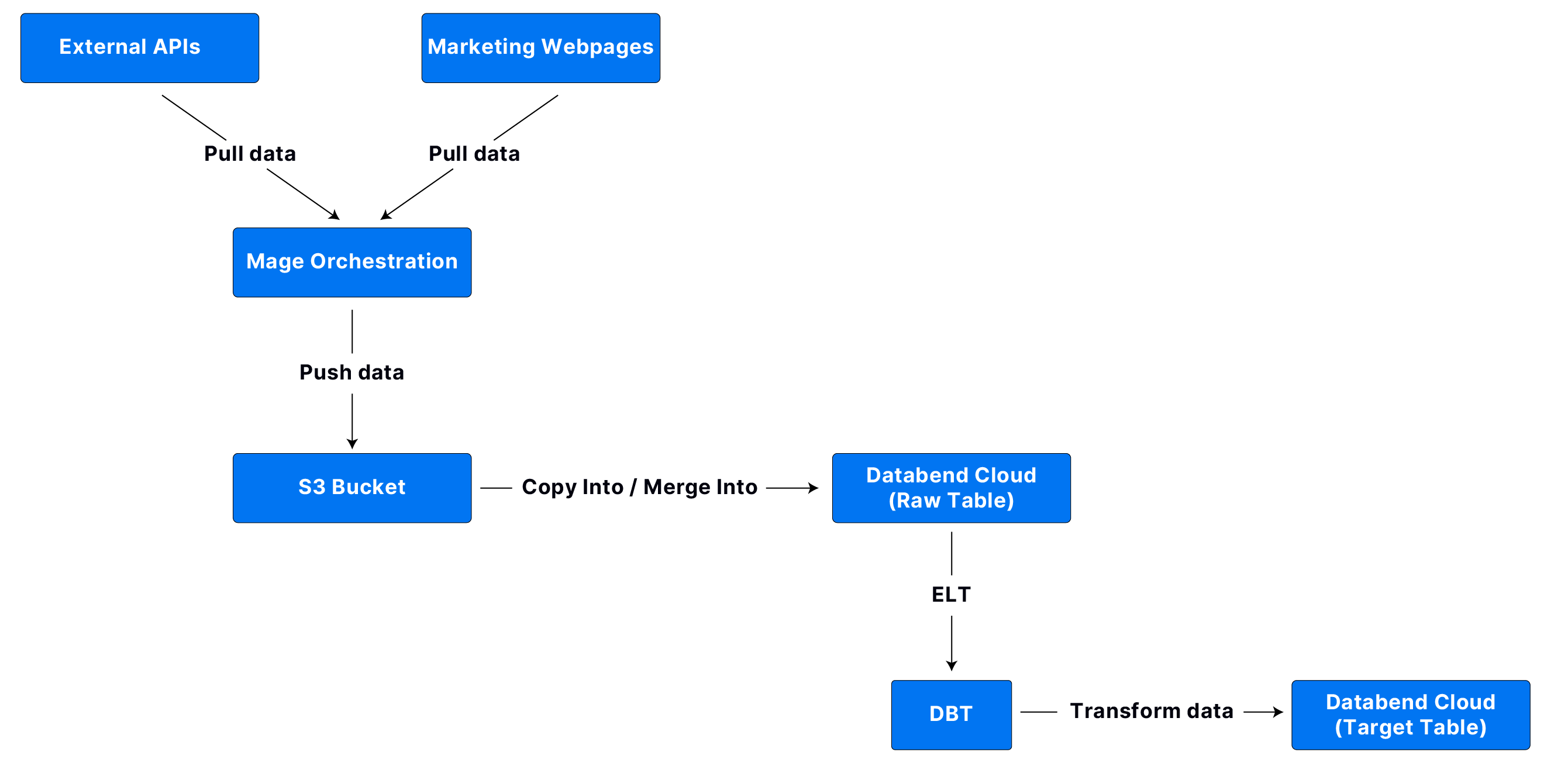
第1关:手写数字体生成
任务描述
本关任务:编写一个程序,实现手写数字体的生成。
相关知识
为了完成本关任务,你需要掌握:1.生成器,2.判别器,3.GAN网络训练,4.手写数字体生成。
GAN的网络结构
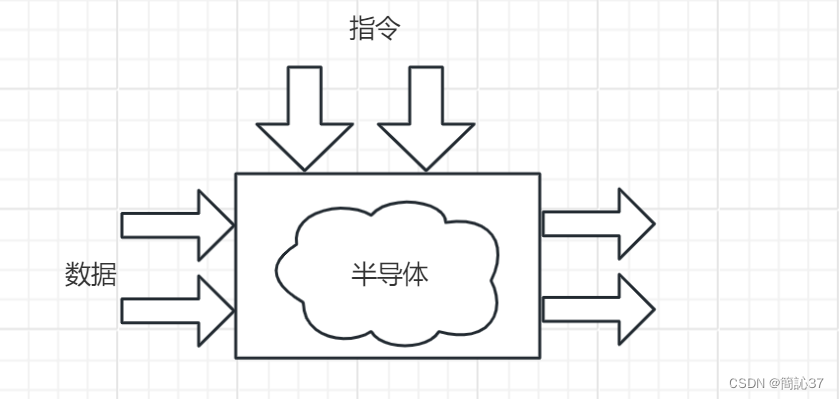
GAN(生成对抗网络)包含两个部分,第一部分是生成网络(G),第二部分是对抗网络,或者说是判别网络(D);这两个部分都可以看成是黑匣子,即接受输入然后有一个输出。
GAN的思想在于很好地利用这两个部分,使他们产生零和博弈,是一种相互成就的关系。简单来说,就是让两个网络相互竞争,生成网络来生成假的数据试图达到真实的标准,对抗网络通过判别器去判别真伪,认出哪些是真实数据,就是通过这样不断地 迭代最后希望生成器生成的数据能够以假乱真。
我们使用下图来简单的看一看这两个过程:
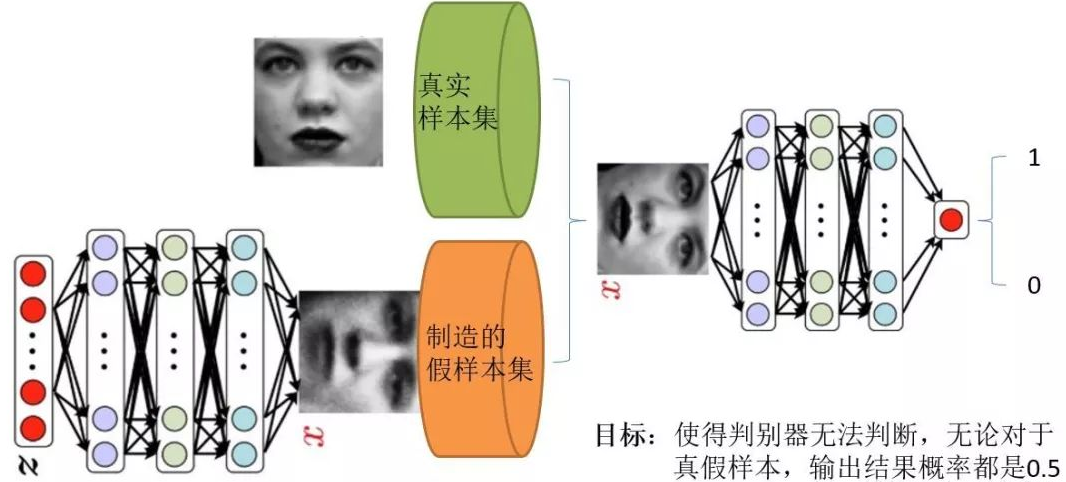
图1-1-1 生成对抗网络图示
上图中,z是随机噪声(随机生成的一些数,也是GAN生成图像的源头)。D通过真图和假图的数据,进行一个二分类神经网络训练。G根据一串随机数就可以捏造出一个"假图像"出来,用这些假图去欺骗D,D负责辨别这是真图还是假图,会给出一个score。比如,G生成了一张图,在D这里评分很高,说明G生成能力是很成功的;若D给出的评分不高,可以有效区分真假图,则G的效果还不太好,需要调整参数。
判别器
我们首先来看判别模型,就是图中右半部分的网络,直观来看就是一个简单的神经网络结构,输入就是一副图像,输出就是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假)。它的目的就是能判别出来属于的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
判别器的网络代码如下(代码使用pytorch框架书写,下同):
class DNet(nn.Module):
def __init__(self):
super(DNet, self).__init__()
self.l1 = nn.Linear(28*28, 256)
self.a = nn.ReLU()
self.l2 = nn.Linear(256, 128)
self.l3 = nn.Linear(128, 1)
self.s = nn.Sigmoid()
def forward(self, x):
x = self.l1(x)
x = self.a(x)
x = self.l2(x)
x = self.a(x)
x = self.l3(x)
x = self.s(x)
return x
生成器
我们再来看生成模型,它同样也可以看成是一个神经网络模型,输入是一组随机数Z,输出是一个图像,不再是一个数值而已。从图中可以看到,会存在两个数据集,一个是真实数据集,这个是真实存在的,另一个是假的数据集,那么这个数据集就是由生成网络造出来的数据。那么我们就可以把生成网络理解成是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到判别网络没法判断是真样本还是假样本。
生成器的代码如下:
class GNet(nn.Module):
def __init__(self):
super(GNet, self).__init__()
self.l1 = nn.Linear(10, 128)
self.a = nn.ReLU()
self.l2 = nn.Linear(128, 256)
self.l3 = nn.Linear(256, 28*28)
self.tanh = nn.Tanh()
def forward(self, x):
x = self.l1(x)
x = self.a(x)
x = self.l2(x)
x = self.a(x)
x = self.l3(x)
x = self.tanh(x)
return x
GAN的网络训练
上面认识了生成器和判别器之后,我们还需要一种手段来进行两者的训练,将他们联系起来。总体来说GAN的训练在同一轮梯度更新的过程中可以细分为2步:(1)先训练D;(2)再训练G。 当训练D的时候,固定G的参数:上一轮G产生的图片和真实图片,直接拼接在一起作为x。然后按顺序摆放成0和1,假图对应0,真图对应1。然后就可以通过D,x输入生成一个score(从0到1之间的数),通过score和y组成的损失函数,从而进行梯度反传。 当训练G的时候,固定D的参数:需要把G和D当作一个整体。这个整体(简称DG系统)的输出仍然是score。输入一组随机向量z,就可以在G生成一张图,通过D对生成的这张图进行打分得到score,这就是DG系统的前向过程。score=1就是DG系统需要优化的目标,score和y=1之间的差异可以组成损失函数,然后可以采用反向传播梯度。
两者共用的损失函数如下:
![]()
其中的参数与上述一一对应。 我们可以使用下面的代码对网络进行训练:
# !/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as func
import torchvision
import numpy as np
batch_size = 160
# 将读取的图片转换为tensor 并标准化
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.5], std=[0.5])
])
dataset = torchvision.datasets.MNIST("./mnist/", train=True, transform=transform, download=True )
data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size = batch_size, shuffle=True) # shuffle乱序
device = torch.device("cuda")
# 构建模型并送入GPU
D = DNet().to(device)
G = GNet().to(device)
# 设置优化器
D_optimizer = torch.optim.Adam(D.parameters(), lr=0.001)
G_optimizer = torch.optim.Adam(G.parameters(), lr=0.001)
for epoch in range(250):
cerrent = 0.0 # 正确识别
for step, data in enumerate(data_loader):
# 获取真实图集 并拉直
real_images = data[0].reshape(batch_size, -1).to(device)
# 构造真假标签
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# 训练辨别器 分别将真图片和真标签喂入判别器、生成图和假标签喂入判别器
# 判别器的损失为真假训练的损失和
# print(real_images.size())
real_outputs = D(real_images)
real_loss = func.binary_cross_entropy(real_outputs, real_labels)
z = torch.randn(batch_size, 10).to(device) # 用生成器产生fake图喂入判别器网络
fake_images = G(z)
d_fake_outputs = D(fake_images)
fake_loss = func.binary_cross_entropy(d_fake_outputs, fake_labels)
d_loss = real_loss + fake_loss
G_optimizer.zero_grad()
D_optimizer.zero_grad()
d_loss.backward()
D_optimizer.step()
# 训练生成器
z = torch.randn(batch_size, 10).to(device)
fake_images = G(z)
fake_outputs = D(fake_images)
g_loss = func.binary_cross_entropy(fake_outputs, real_labels) # 将fake图和真标签喂入判别器, 当g_loss越小生成越真实
G_optimizer.zero_grad()
D_optimizer.zero_grad()
g_loss.backward()
G_optimizer.step()
if step % 20 == 19:
print("epoch: " , epoch+1, " step: ", step+1, " d_loss: %.4f" % d_loss.mean().item(),
" g_loss: %.4f" % g_loss.mean().item(), " d_acc: %.4f" % real_outputs.mean().item(),
" d(g)_acc: %.4f" % d_fake_outputs.mean().item())
# 保存模型
torch.save(D.state_dict(), "./D.pth")
torch.save(G.state_dict(), "./G.pth")
手写数字体生成
在完成训练后,我们可以加载训练好的生成器,生成手写数字。代码如下:
# !/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as func
import torchvision
import matplotlib.pylab as plt
import numpy as np
def denomalize(x):
"""还原被标准化后的图像"""
out = (x+1) / 2
out = out.view(32, 28, 28).unsqueeze(1) # 添加channel
return out.clamp(0,1)
def imshow(img,epoch):
"""打印生成器产生的图片"""
# torchvision.utils.make_grid用来连接一组图, img为一个tensor(batch, channel, height, weight)
# .detach()消除梯度
im = torchvision.utils.make_grid(img, nrow=8).detach().numpy()
# print(np.shape(im))
plt.title("Generated IMG {}".format(epoch))
plt.imshow(im.transpose(1, 2, 0)) # 调整图形标签, plt的图片格式为(height, weight, channel)
plt.savefig('./img_out/generate{}.jpg'.format(str(epoch)))
plt.show()
device = torch.device("cpu")
# 构建模型并送入运算
D = DNet().to(device)
G = GNet().to(device)
z = torch.randn(32, 10).to(device)
# 数字代表训练的程度,即为第10代,第50代...
for epoch in [10,50,100,200,400]:
G.load_state_dict(torch.load("./G{}.pth".format(epoch),map_location=device))
G.to(device)
img = G(z)
img = denomalize(img.to("cpu"))
imshow(img,epoch)

图5-1-1 训练150个epoch时生成的数据

图5-1-2 训练200个epoch时生成的数据
第1关任务——代码题
# !/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as func
import torchvision
import matplotlib.pylab as plt
import numpy as np
# 转换
def denomalize(x):
##########Begin##########
out = (x+1) / 2
out = out.view(32, 28, 28).unsqueeze(1) # 添加channel
return out.clamp(0,1)
###########End###########
# 生成图片显示
def imshow(img,epoch):
##########Begin##########
im = torchvision.utils.make_grid(img, nrow=8).detach().numpy()
plt.title("Generated IMG {}".format(epoch))
plt.imshow(im.transpose(1, 2, 0))
plt.savefig('./img_out/generate{}.jpg'.format(str(epoch)))
plt.show()
###########End###########
# 判别器模型
class DNet(nn.Module):
##########Begin##########
def __init__(self):
super(DNet, self).__init__()
self.l1 = nn.Linear(28*28, 256)
self.a = nn.ReLU()
self.l2 = nn.Linear(256, 128)
self.l3 = nn.Linear(128, 1)
self.s = nn.Sigmoid()
def forward(self, x):
x = self.l1(x)
x = self.a(x)
x = self.l2(x)
x = self.a(x)
x = self.l3(x)
x = self.s(x)
return x
###########End###########
# 生成器模型
class GNet(nn.Module):
##########Begin##########
def __init__(self):
super(GNet, self).__init__()
self.l1 = nn.Linear(10, 128)
self.a = nn.ReLU()
self.l2 = nn.Linear(128, 256)
self.l3 = nn.Linear(256, 28*28)
self.tanh = nn.Tanh()
def forward(self, x):
x = self.l1(x)
x = self.a(x)
x = self.l2(x)
x = self.a(x)
x = self.l3(x)
x = self.tanh(x)
return x
###########End###########
device = torch.device("cpu")
# 构建模型并送入GPU
D = DNet().to(device)
G = GNet().to(device)
print(D)
print(G)
z = torch.tensor([[ 1.1489e+00, 7.1681e-01, 5.8007e-02, -1.2308e-01, -8.6097e-01,
1.2392e+00, -1.1096e+00, 2.4585e-01, -7.0626e-01, -2.8230e-01],
[-2.1945e-01, 4.6672e-01, 7.7213e-01, -9.8824e-01, 1.3838e+00,
2.2511e-01, -1.1168e+00, 2.2530e+00, 7.3158e-01, 1.7082e-01],
[-2.6517e+00, 1.3954e+00, 1.5612e+00, -3.5644e-01, 1.3853e+00,
-3.6608e-01, 2.3234e-03, -4.7733e-01, -1.7758e-01, 3.4617e-01],
[ 4.7174e-01, -7.3149e-01, 1.1419e-01, -2.6241e-01, -1.1660e-01,
-1.3477e-01, 1.1245e+00, -1.6306e+00, 6.1722e-01, -1.3473e-01],
[ 1.0552e+00, -1.4014e-01, -5.8463e-01, 1.2349e+00, -6.5313e-01,
-2.3425e-01, 1.0186e-01, -6.0410e-01, -7.4244e-01, -8.8516e-01],
[-5.3014e-01, 6.2547e-01, -1.5977e-01, -2.3066e-01, 9.8950e-02,
-4.8964e-01, -1.0218e+00, -5.9025e-01, -1.0131e+00, -6.5106e-01],
[-1.5537e+00, -6.9103e-01, -7.3599e-01, -4.3914e-01, -2.0448e-01,
-1.4190e+00, -1.2123e+00, -1.6747e-01, -1.1395e+00, 5.5171e-01],
[-1.6244e+00, -7.4496e-01, -1.2768e+00, -4.2177e-01, -6.1283e-01,
-8.8188e-01, 4.1788e-01, 9.2558e-01, -1.5659e+00, -1.5211e-01],
[ 9.3092e-02, -1.5520e-01, 1.6417e+00, 6.8507e-01, 2.4547e+00,
-8.3659e-02, 3.2725e+00, 4.3044e-01, 1.3569e-01, 1.4817e+00],
[-1.4958e+00, -5.2917e-02, -3.6961e-01, -2.2025e+00, -1.6436e-01,
1.2136e+00, -1.3152e-02, -1.2154e+00, 2.0911e-03, 2.9080e-01],
[-1.0469e+00, 2.8222e+00, -3.9115e-01, 2.2041e-01, -7.8101e-01,
1.2563e+00, 1.1753e+00, -1.3332e+00, 2.4884e+00, -4.4259e-01],
[-7.0369e-01, -1.4290e+00, 6.3865e-01, -5.8341e-01, -1.3592e+00,
-5.8469e-01, 1.8228e+00, 1.0016e+00, 5.4477e-01, -2.2182e+00],
[-3.4230e-01, 9.9979e-01, 1.2068e-01, -2.5346e-01, -1.1366e+00,
-1.3778e+00, -1.3563e+00, 9.4610e-01, -9.4018e-01, -9.2094e-01],
[ 8.2746e-01, -6.2931e-01, -3.8875e-01, 2.1943e-01, 6.4780e-01,
-1.0844e+00, -8.8125e-01, 2.8869e-01, -1.0784e-01, -6.1752e-01],
[ 7.3338e-01, -8.2371e-01, 8.7851e-01, 9.9646e-01, -1.7378e+00,
4.4679e-01, -4.5057e-01, 8.8582e-01, 1.0759e+00, 7.1904e-01],
[ 1.3013e+00, 2.7334e-01, 4.3593e-01, -1.2887e+00, -1.2346e+00,
1.5697e+00, 3.1392e-01, -1.8793e+00, 7.4765e-01, -1.5952e+00],
[-1.7635e-01, -5.8611e-02, -3.1754e-01, 5.3886e-01, 4.2619e-01,
9.4467e-01, 2.0849e-01, -3.3167e-01, -4.1872e-01, -7.3638e-02],
[ 6.3905e-01, 6.8031e-02, 1.8931e+00, 6.8102e-01, 6.8116e-01,
-6.4648e-02, 4.3161e-01, 1.8226e+00, 2.1950e+00, -4.8745e-01],
[-1.6209e+00, 7.3165e-01, 1.1026e-01, 1.1185e+00, 2.7662e+00,
-5.5616e-01, 3.9975e-01, -5.4667e-01, 8.1839e-01, 2.9950e-01],
[-4.0914e-01, 5.0958e-01, 5.3542e-01, -6.3667e-01, -5.9792e-01,
-1.3693e+00, 7.9520e-02, 1.9240e-01, -7.1213e-01, -3.1667e-01],
[ 2.8481e-01, -1.1645e+00, 1.0669e-01, 8.8317e-01, -1.1061e+00,
1.1247e+00, -1.8601e-01, 3.4027e+00, 1.1318e+00, -2.4114e+00],
[ 2.7305e-01, -3.0332e-01, -4.0622e-01, 2.2628e-01, 1.8857e+00,
-3.0286e-01, -6.2789e-01, -2.3954e-01, -7.5774e-01, -6.8736e-01],
[ 3.8802e-01, 1.6416e+00, 5.8121e-01, 1.9790e+00, -3.7603e-02,
-3.2679e-01, -4.7280e-01, -1.4476e-01, 1.0581e+00, -9.8440e-01],
[-3.9233e-01, 3.2649e-02, 7.7994e-01, -1.3475e+00, -2.7656e-01,
1.8111e+00, -1.3303e-01, 1.8950e+00, 1.2445e+00, 8.5697e-01],
[-1.0138e+00, -3.4321e-01, 9.0624e-01, -1.5395e+00, -3.9321e-01,
-4.8072e-01, -9.0556e-01, 1.5222e+00, -8.9406e-01, -8.8321e-01],
[ 5.2679e-02, 4.2842e-01, 1.1687e+00, 3.4735e-01, -2.9261e-01,
-3.1606e-01, -5.9302e-01, -3.0689e-01, 1.0589e+00, -7.3568e-01],
[ 5.9457e-01, -5.2930e-01, 6.7054e-01, 1.0220e+00, -1.4623e-02,
-1.7065e-01, -1.6068e+00, 8.9959e-01, -1.1968e+00, 2.4110e-01],
[ 8.9343e-02, 1.4014e+00, 6.8921e-01, 4.5150e-01, -2.6966e+00,
1.8082e+00, 7.1977e-01, -1.2223e+00, 1.3240e-01, -3.1817e-03],
[-6.7737e-01, 1.1342e+00, -3.7651e-01, 9.1442e-01, 3.4748e-01,
-1.2479e+00, -6.5175e-01, 2.9314e-01, 1.0561e-01, 4.2260e-01],
[ 1.2196e+00, 1.5686e-01, 3.7240e-01, 1.3012e+00, 2.5194e-01,
-6.7221e-01, 1.3126e+00, 8.6740e-01, -2.5076e-01, 7.7630e-01],
[ 5.8054e-01, 1.6174e+00, -3.9814e-01, -5.9296e-01, -6.1294e-01,
1.0387e+00, -2.5145e+00, 7.9484e-01, -7.6897e-01, -1.1325e+00],
[ 3.6981e-01, 3.0270e-01, 1.7068e-01, 8.7460e-01, 2.0930e-01,
-3.2083e-01, 6.9222e-01, -1.2070e-01, -1.2727e+00, 6.8880e-01]]).to(device)
# 加载不同训练程度的预训练模型,生成图片并显示
##########Begin##########
for epoch in [10,50,100,200,400]:
G.load_state_dict(torch.load("./G{}.pth".format(epoch),map_location=device))
G.to(device)
img = G(z)
img = denomalize(img.to("cpu"))
imshow(img,epoch)
###########End###########
if epoch ==200:
print(img)