Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi
华盛顿大学,IBM人工智能研究院
摘要
尽管大语言模型(LLMs)具有非凡的能力,但是它们经常产生不符合事实的响应,因为它们只依赖于它们封装的参数化知识。检索增强生成(retrieve - augmented Generation, RAG)是一种通过检索相关知识来增强LMs的特殊方法,减少了此类问题。然而,不加选择地检索和合并固定数量的检索段落,无论检索是否必要,或者段落是否相关,都会降低LM的通用性,或者可能导致无益的响应生成。
我们引入了一个新的框架,称为自我反思检索-增强生成(SELF-RAG),它通过检索和自我反思来提高LM的质量和真实性。我们的框架训练了一个任意的LM,它可以自适应地按需检索段落,并使用特殊的令牌(称为反射令牌)生成和反映检索到的段落及其自己的生成。生成反射令牌使LM在推理阶段可以控制,使其能够根据不同的任务需求调整其行为。
实验表明,SELF-RAG (7B和13B参数)在各种任务上明显优于最先进的llm和检索增强模型。具体来说,SELF-RAG在开放域QA、推理和事实验证任务上优于ChatGPT和检索增强的Llama2-chat,并且相对于这些模型,它在提高长格式代的事实性和引用准确性方面显示出显著的进步。
1 引言
最先进的大语言模型继续与事实错误作斗争(Mallen et al., 2023; Min et al., 2023),尽管他们增加了模型和数据规模(Ouyang et al., 2022)。检索-增强生成(RAG)方法(图一左边; Lewis et al. 2020; Guu et al. 2020) 通过相关检索段落增加大语言模型的输入,减少知识密集型任务中的事实错误 (Ram et al.,2023; Asai et al., 2023a).。然而,这些方法可能会阻碍大语言模型的通用性,或者引入不必要的或偏离主题的段落,从而导致低质量的生成 (Shi et al., 2023),因为它们不加区分地检索段落,而不管事实基础是否有用。此外,输出不能保证与检索到的相关段落一致(Gao et al., 2023) ,因为模型没有明确地训练以利用和遵循所提供的段落中的事实。
这项工作引入了自我反思检索增强生成(SELF-RAG),通过按需检索和自我反思来提高大语言模型的生成质量,包括其事实准确性,同时又不损害其通用性。我们以端到端方式训练任意LM,通过生成任务输出和间歇特殊令牌(即反射令牌)来学习在给定任务输入的情况下反思自己的生成过程。反射令牌分为检索令牌和批判令牌,分别表示检索的需要及其生成质量(图1右)。
特别是,在给定输入提示和前几代的情况下,SELF-RAG首先确定用检索到的段落增加连续生成是否有帮助。如果是,它输出一个检索令牌,按需调用检索器模型(步骤1)。随后,SELF-RAG并发地处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤2)。然后,它生成批评令牌来评估自己的输出,并根据事实性和整体质量选择最好的一个(步骤3)。这个过程不同于传统的RAG(图1左)始终如一地检索固定数量的文档以生成,而不考虑检索的必要性(例如,底部的图示例不需要事实知识),并且从不第二次评估生成质量。此外,SELF-RAG为每个片段提供了引用,并对输出是否得到文章的支持进行了自我评估,从而更容易进行事实验证。
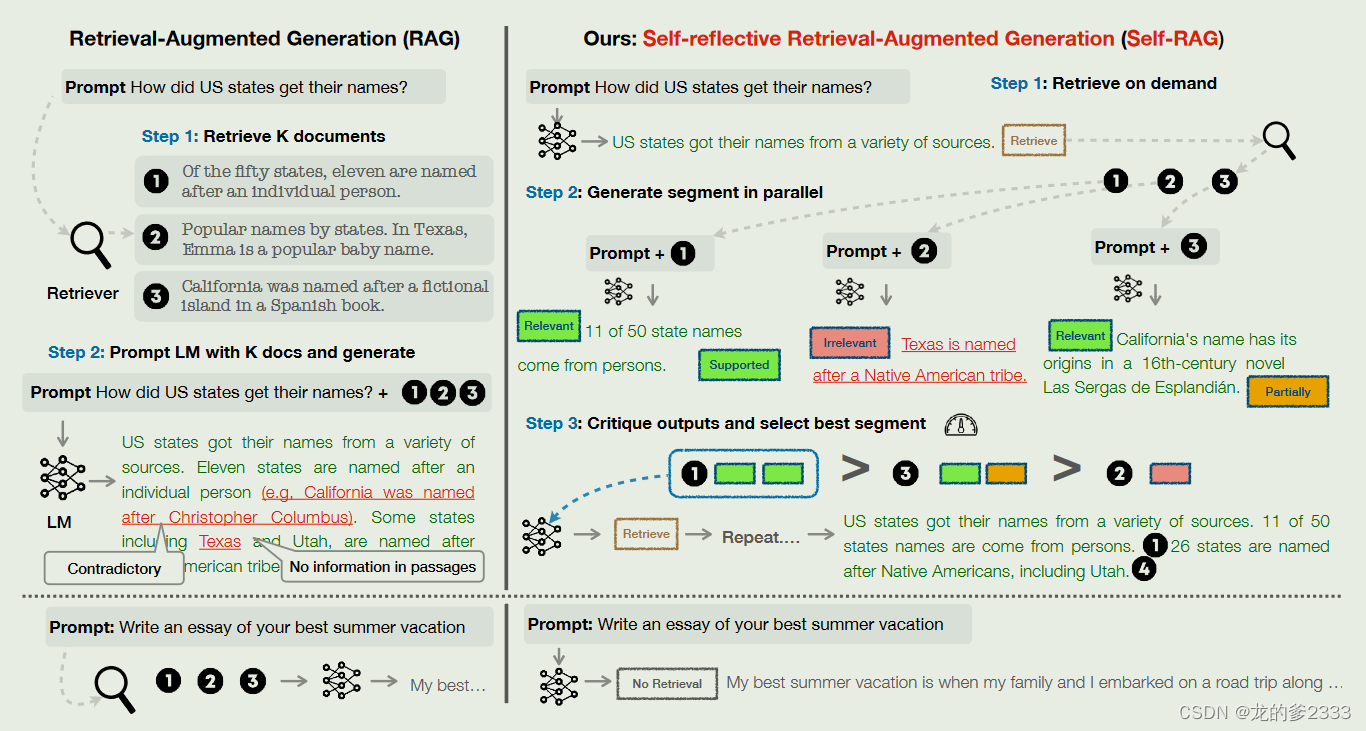
图1:SELF-RAG的概述。SELF-RAG学习检索、批评和生成文本段落,以提高整体生成质量、真实性和可验证性。
SELF-RAG训练任意LM来生成带有反射标记的文本,方法是将它们统一为扩展模型词汇表中的下一个标记预测。我们在不同的文本集合上训练我们的生成器LM,这些文本集合与反射令牌和检索的段落交织在一起。反射令牌,灵感来自强化学习中使用的奖励模型 (Ziegler et al., 2019; Ouyang et al., 2022),通过训练有素的评估模型离线插入原始语料库。这消除了在训练期间托管评估模型的需要,减少了开销。在某种程度上,评估模型是在输入、输出和相应的反射令牌的数据集上进行监督的,这些令牌是通过提示一个适当的LM (i.e.,GPT-4; OpenAI 2023)。虽然我们从使用控制令牌来启动和指导文本生成的研究中获得灵感(Lu et al., 2022; Keskar et al., 2019),,我们训练过的LM使用评估令牌在每个生成的片段之后评估自己的预测,作为生成输出的一个组成部分。
SELF-RAG进一步支持可定制的解码算法,以满足由反射令牌预测定义的硬约束或软约束。特别是,我们的推理时间算法使我们能够(1)灵活地调整不同下游应用程序的检索频率;(2)通过使用反射令牌概率加权线性和作为段分数的段级波束搜索,利用反射令牌来根据用户偏好定制模型的行为。
包括推理和长格式生成在内的六个任务的实证结果表明,SELF-RAG显著优于具有更多参数和广泛采用RAG方法的预训练和指令调整的llm,并且具有更高的引用准确性。特别是,SELF-RAG在四个任务上优于检索增强ChatGPT,在所有任务上优于Llama2-chat (Touvron et al., 2023) 和Alpaca (Dubois et al., 2023)。我们的分析证明了使用反射令牌进行训练和推理对于整体性能改进以及测试时模型定制的有效性(例如,平衡引用前提和完整性之间的权衡)。
2 相关工作
Retrieval-Augmented Generation。检索增强生成(RAG)用检索到的文本段落增强LMs的输入空间 (Guu et al., 2020; Lewis et al., 2020),在微调或与现成的lm一起使用后,导致知识密集型任务的大幅改进 (Ram et al., 2023)。最近的一项工作 (Luo et al., 2023)使用固定数字对LM进行指令调谐预先输入检索到的段落,或者预先训练检索器和LM联合,然后对任务数据集进行少量微调(Izacard et al., 2022b)。之前的工作通常在开始时只检索一次,Jiang等人(2023)建议在专有的LLM之上自适应检索生成的段落,或者Schick等人(2023)训练LM为命名实体生成API调用。然而,这些方法的任务性能的提高往往是以牺牲运行时效率(Mallen et al., 2023)、对不相关上下文的鲁棒性 (Shi et al., 2023)和缺乏归因 (Liu et al., 2023a; Gao et al., 2023)。我们引入了一种方法来训练任意LM学习对各种指令跟随查询使用按需检索,并引入了由反射标记引导的受控生成,以进一步提高生成质量和属性。
Concurrent RAG work。一些关于RAG的并行工作提出了新的培训或提示策略,以改进广泛采用的RAG方法。Lin等人(2023)分两步对检索器和LM在指令调优数据集上进行微调。虽然我们也在不同的指令遵循数据集上训练我们的模型,但SELF-RAG可以根据需要进行检索,并通过细粒度的自我反射选择最佳的模型输出,使其广泛适用,更加鲁棒和可控。Yoran等人(2023)使用自然语言推理模型,Xu等人(2023)使用摘要模型过滤或压缩检索到的段落,然后使用它们提示LM生成输出。SELF-RAG并行处理段落,并通过自我反思过滤掉不相关的段落,而不依赖外部模型进行推理。此外,我们的自我反思机制还评估模型输出质量的其他方面,包括真实性。LATS(Zhou et al., 2023)提示现成的lm为问答任务搜索相关信息,并在lm生成值分数的指导下进行树搜索生成。虽然它们的值函数只是简单地表示每一代的总体得分,但SELF-RAG训练到任意LM来学习生成细粒度的自我反思和可定制的推理。
Training and generating with critics。用强化学习训练llm(例如,近端策略优化或PPO;来自人类反馈(RLHF)的Schulman et al . 2017)已被证明可以有效地将llm与人类偏好结合起来(Ouyang et al, 2022)。Wu等(2023)引入了带有多个奖励模型的细粒度RLHF。虽然我们的工作也研究了检索和生成的细粒度批评,但我们在任务示例上训练目标LM,并从离线的评估模型中添加反射令牌,与RLHF相比,训练成本要低得多。此外,SELF-RAG中的反射令牌在推理时实现了可控制的生成,而RLHF则在训练时关注人类偏好对齐。其他作品使用通用控制令牌来指导LM生成(Lu et al, 2022;Korbak等人,2023),而SELF-RAG使用反射令牌来决定是否需要检索并自评估生成质量。Xie等人(2023)提出了一个自我评价导向的解码框架,但他们只关注一个评价维度(推理路径一致性)的推理任务,没有检索。LLM细化研究进展(Dhuliawala et al ., 2023;Madaan等,2023;Paul et al ., 2023)提示模型迭代生成任务输出、自然语言反馈和精细任务输出,但以牺牲推理效率为代价。
3 SELF-RAG:学会检索,生成和自我评估
我们引入自反射检索增强生成(SELF-RAG),如图1所示。
SELF-RAG是一个框架,通过检索和自我反思来提高大语言模型的质量和真实性,而不会牺牲大语言模型的原始创造力和多功能性。我们的端到端训练允许LM根据检索到的段落生成文本(如果需要),并通过学习生成特殊令牌来批评输出。这些反射令牌(表1)表示需要检索或确认输出的相关性、支持或完整性。相比之下,常见的RAG方法不加选择地检索段落,而不确保引用来源的完全支持。
3.1 问题形式化和概述
形式上,给定输入x,我们训练M以顺序生成由多个片段y = [,…,
]组成的文本输出y。其中
表示第t段的令牌序列在
中生成的标记包括来自原始词汇表的文本以及反射标记(表1)。

表1:SELF-RAG中使用的四种类型的反射令牌。每种类型使用几个令牌来表示其输出值。底部的三行是三种类型的评论标记,粗体文本表示最理想的评论标记。x,y,d分别表示输入、输出和相关通道

Inference overview。图1和算法1给出了SELF-RAG在推理中的概述。对于每一个输入x,以及先前的输出y<t,该模型对检索令牌进行解码以评估检索的效用。如果不需要检索,则模型预测下一个输出段,就像它在标准LM中所做的那样。如果需要检索,则模型生成:一个评估令牌,用于评估检索到的通道的相关性,下一个响应段,以及一个评估令牌,用于评估响应段中的信息是否被该通道支持。最后,一个新的评估令牌评估响应的整体效用为了生成每个片段,SELF-RAG并行处理多个通道,并使用自己生成的反射令牌对生成的任务输出强制执行软约束(第3.3节)或硬控制(算法1)。例如,在图1(右)中,检索到的段落d1在第一个时间步被选择,因为d2没有提供直接证据(ISREL是不相关的),d3输出只是部分支持,而d1是完全支持的。
Training overview。SELF-RAG允许任意LM生成带有反射标记的文本,方法是将它们统一为来自扩展模型词汇表(即原始词汇表加上反射标记)的下一个标记预测。具体来说,我们在检索器R检索的交错段落和评估模型C预测的反射令牌(总结在附录算法2中)的精选语料库上训练生成器模型M。我们训练C生成反射令牌,以评估检索到的段落和给定任务输出的质量(第3.2.1节)。使用评估模型,我们通过在任务输出中插入反射令牌来更新训练语料库。随后,我们使用传统LM目标(第3.2.2节)训练最终的生成器模型(M),使M能够在推理时自行生成反射令牌,而不依赖于评估模型。
3.2 训练SELF-RAG
在这里,我们描述了两个模型的监督数据收集和训练,评估模型C(第3.2.1节)和生成器M(第3.2.2节)。
3.2.1 训练评估模型C
Data collection for critic model。手动标注每个段的反射令牌是昂贵的(Wu et al, 2023)。像GPT-4 (OpenAI, 2023)这样的最先进的LLM可以有效地实现来产生这种反馈(Liu et al ., 2023b)。然而,依赖这种专有的LMs会增加API成本并降低可重复性(Chen et al, 2023)。我们通过提示GPT-4生成反射令牌来创建监督数据,然后将其知识提取到C内部中。对于每一组反射令牌,我们从原始训练数据中随机抽取实例:{,
} ~ {X, Y}。
由于不同的反射令牌组有自己的定义和输入,如表1所示,我们对它们使用不同的指令提示符。这里,我们以Retrieve为例。我们用特定类型的指令提示GPT-4(“给定指令,判断从网络中找到一些外部文档是否有助于生成更好的响应。”),然后在原始任务输入x和输出y中进行几次演示,以预测适当的反射令牌作为文本:p(r|I, x, y)。手动评估显示GPT-4反射令牌预测与人类评估高度一致。我们收集了每种类型的4k-20k监督训练数据,并将它们组合成c的训练数据。附录D部分给出了完整的指令列表,A.1包含了更多的细节和我们的分析。
Critic learning。在我们收集训练数据后,我们用预训练的LM初始化C,并使用标准条件语言建模目标在
上训练它,最大化似然:
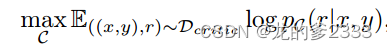
r代表反射令牌。
虽然初始模型可以是任何预训练的LM,但我们使用与生成器LM相同的模型(即Llama 2-7B;Touvron等2023)用于C初始化。评论家在大多数反射令牌类别上与基于gpt -4的预测达成了90%以上的一致性(附录表5)。
3.2.2 训练生成模型
Data collection for generator。给定一个输入输出对(x, y),我们使用检索和评估模型来增加原始输出y,以创建精确模仿SELF-RAG推理时间过程的监督数据(第3.1节)。对于每个片段∈y,我们运行C来评估额外的传代是否有助于增强生成。如果需要检索,则添加检索特殊令牌Retrieve =Yes, R检索前K个段落D。对于每个段落,C进一步评估该段落是否相关并预测ISREL。如果一篇文章是相关的,C进一步评估该文章是否支持模型生成并预测ISSUP。评论令牌ISREL和ISSUP被附加在检索到的段落或代之后。在输出y(或
)的末尾,C预测整个实用程序令牌ISUSE,并将带有反射令牌和原始输入对的增强输出添加到
中。请参见图2中的示例训练数据。
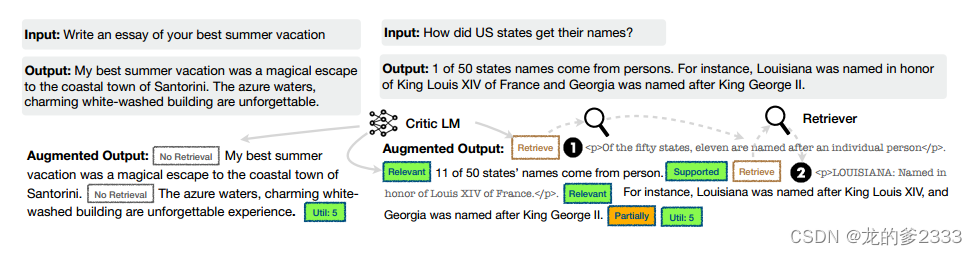
图2:SELF-RAG训练示例。左边的例子不需要检索,右边的例子需要检索;因此,插入了段落。更多的例子见附录表4。
Connections to prior work on learning with critique。最近的工作在训练期间纳入了额外的评估(反馈),例如,通过PPO进行的RLHF (Ouyang et al. 2022)。而PPO依赖于在训练期间分离奖励模型,我们离线计算评论并直接将它们插入训练语料库,其中生成器LM使用标准LM目标进行训练。与PPO相比,这大大降低了培训成本。我们的工作还与之前的工作有关,这些工作将特殊令牌纳入控制生成(Keskar等人,2019;Lu et al ., 2022;Korbak et al, 2023)。我们的SELF-RAG学习生成特殊的令牌,以便在每个生成的片段之后评估自己的预测,从而在推理中使用软重新排序机制或硬约束(下面讨论)。
3.3 SELF-RAG推理
生成反射令牌来对自己的输出进行自我评估,使SELF-RAG在推理阶段可以控制,从而使其能够根据不同的任务需求调整自己的行为。对于要求事实准确性的任务(Min et al., 2023),我们的目标是让模型更频繁地检索段落,以确保输出与现有证据密切一致。相反,在更开放的任务中,比如写一篇个人经历的文章,重点转向更少的检索,优先考虑整体的创造力或实用性得分。在本节中,我们将描述在推理过程中实施控制以满足这些不同目标的方法。
Adaptive retrieval with threshold(阈值自适应检索)。SELF-RAG通过预测检索动态地决定何时检索文本段落。或者,我们的框架允许设置阈值。具体来说,如果在Retrieve中的所有输出令牌上生成Retrieve =Yes令牌的概率超过指定的阈值,我们将触发检索(详情见附录a .3节)。
Tree-decoding with critique tokens(使用批判令牌进行树解码)。在每个片段步骤t,当需要检索时,基于硬条件或软条件,R检索K个通道,生成器M并行处理每个通道并输出K个不同的延续候选。我们进行段级波束搜索(波束大小=B),获得每个时间戳t的top-B段延续,并在生成结束时返回最佳序列。每个片段yt相对于通道d的分数被更新为一个批评家分数s,它是每个批判标记类型的归一化概率的线性加权和。对于每个批判令牌组G(例如,ISREL),我们将其在时间戳t的分数表示为,并计算分段分数如下:

其中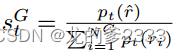 表示最理想的反射令牌的生成概率
表示最理想的反射令牌的生成概率(例如,ISREL =Relevant)对于具有N个不同令牌(代表G的不同可能值)的批判令牌类型G。Eq. 4中的权重
是超参数,可以在推理时调整,以在测试时启用自定义行为。例如,为了确保结果y主要得到证据的支持,我们可以为ISSUP得分设置较高的权重项,而相对降低其他方面的权重项。或者,我们可以在解码过程中使用Critique进一步执行硬约束。代替在Eq. 4中使用软奖励函数,我们可以在模型产生不令牌(例如,ISSUP =No support)时显式地过滤掉段延续。RLHF研究了多种偏好之间的权衡平衡(Touvron等人,2023;Wu等人,2023),这通常需要训练来改变模型的行为。SELF-RAG在没有额外培训的情况下定制LM。
4 实验
4.1 任务和数据集
我们对SELF-RAG和一系列下游任务的不同基线进行评估,用旨在评估整体正确性、真实性和流畅性的指标对产出进行整体评估。在这些实验中,我们进行了零样本评估,在没有少量样本演示的情况下提供描述任务的说明(Wei等人,2022;Sanh et al, 2022)。我们的实验设置的详细信息,包括测试时间说明,可在附录B.1节中获得。
Closed-set tasks(闭集任务)。包括两个数据集,即关于公共卫生的事实验证数据集(PubHealth;Zhang et al . 2023)和从科学考试中创建的多项选择推理数据集(ARC-Challenge;Clark et al 2018)。我们使用准确性作为评估指标,并对测试集进行报告。我们汇总了这两个数据集的目标类别的答案概率(附录B.2节)。
Short-form generations tasks(短格式生成任务)。包括两个开放域问答(QA)数据集,PopQA (malen等人,2023)和triviqa -unfiltered (Joshi等人,2017),其中系统需要回答关于事实知识的任意问题。对于PopQA,我们使用长尾子集,由1,399个罕见的实体查询组成,这些实体查询的维基百科月页面浏览量小于100。由于triviaqa未过滤(开放)测试集不可公开获取,我们遵循先前工作的验证和测试分割(Min et al, 2019;Guu et al, 2020),使用11,313个测试查询进行评估。根据malallen等人(2023),我们根据黄金答案是否包含在模型代中来评估性能,而不是严格要求精确匹配;Schick et al(2023)。
Long-form generation tasks(长格式生成任务)。包括一个传记生成任务(Min等人,2023)和一个长篇QA任务ALCE-ASQA Gao等人(2023);Stelmakh et al .(2022)。我们使用FactScore (Min等人,2023)来评估传记,我们使用官方的正确性指标(str-em),基于MAUVE的流畅性指标(Pillutla等人,2021),以及ASQA的引用准确性和召回率指标(Gao等人,2023)。
4.2 基线
Baselines without retrievals。我们评估了强大的公开可用的预训练llm, Llama27B,13B (Touvron等人,2023),指令调整模型,Alpaca7B,13B (Dubois等人,2023)(我们基于Llama2的复制);以及使用私人数据、ChatGPT (Ouyang等,2022)和Llama2-chat13B训练和强化的模型。对于指令调优的lm,我们使用官方系统提示或培训期间使用的指令格式(如果公开可用)。我们还将我们的方法与并行工作CoVE65B (Dhuliawala等人,2023)进行了比较,后者引入了迭代提示工程来提高LLM世代的事实性。
Baselines with retrievals。我们在测试时或训练时评估增强检索的模型。第一类包括标准的RAG基线,其中LM (Llama2、Alpaca)使用与我们系统中相同的检索器,在给定的查询前加上检索到的顶部文档,生成输出。
它还包括Llama2- FT,其中Llama2对我们使用的所有训练数据进行微调,而不需要反射令牌或检索通道。我们还报告了使用私有数据训练的lm的检索增强基线的结果:Ret-ChatGPT和Ret-Llama2-chat,它们部署了上述相同的增强技术,以及困惑。ai,一个基于instructgpt的生产搜索系统。第二类包括使用检索到的文本段落进行训练的并行方法,即SAIL (Luo等人,2023)在Alpaca指令调优数据上对LM进行指令调优,在指令之前插入检索到的顶部文档,以及Toolformer (Schick等人,2023)使用API调用(例如,维基百科API)预训练LM。
4.3 实验设置
Training data and settings。我们的训练数据由不同的指令跟随输入输出对组成。特别是,我们从open - directive处理过的数据(Wang et al ., 2023)和知识密集型数据集(Petroni et al ., 2021;Stelmakh et al ., 2022;Mihaylov et al, 2018)。我们总共使用了150k个指令输出对。我们使用Llama2 7B和13B (Touvron等人,2023)作为我们的发电机基础LM,我们使用Llama2-7B作为我们的基础批评LM。对于检索器模型R,我们默认使用现成的Contriever-MS MARCO (Izacard等人,2022a),每次输入检索最多10个文档。更多培训细节见附录B.1节。
Inference settings。作为默认配置,我们将权重项ISREL、ISSUP、ISUSE分别赋值为1.0、1.0和0.5。为了鼓励频繁检索,由于引文要求,我们将大多数任务的检索阈值设置为0.2,将ALCE的检索阈值设置为0 (Gao et al ., 2023)。我们使用vllm加速推理(Kwon et al, 2023)。在每个分段级别,我们采用2的波束宽度。
对于令牌级生成,我们使用贪婪解码。默认情况下,我们使用来自Contriever-MS MARCO的前5个文档(Izacard等人,2022a);对于传记和开放域QA,我们使用了web搜索引擎检索到的前5个文档,如下Luo等人(2023);对于ASQA,我们使用作者提供的GTR-XXL (Ni et al, 2022)在所有基线上的前5个文件进行公平比较。

表2:六个任务的总体实验结果。粗体数字表示非专有模型中性能最好的模型,灰色粗体文本表示性能优于所有非专有模型的最佳专有模型。*表示同时工作所报告的同时的或最近的结果。-表示原始论文未报道或不适用的数字。
模型是根据比例排序的。FS, em, rg, mau, prec, rec表示FactScore(事实);Str-em, rouge(正确);淡紫色(流利);分别引用精度和召回率。
5 结果与分析
5.1 主要结果
Comparison against baselines without retrieval。表2(顶部)显示了没有检索的基线。我们的SELF-RAG(底部两行)在所有任务中都比有监督的微调llm具有显著的性能优势,甚至在PubHealth、PopQA、传记代和ASQA (Rouge和MAUVE)中优于ChatGPT。我们的方法也明显优于采用复杂提示工程的并发方法;具体来说,在生物生成任务上,我们的7B和13B模型优于并行CoVE (duliawala等人,2023),后者迭代地提示Llama265B优化输出。
Comparison against baselines with retrieval。如表2(下)所示,我们的SELF-RAG在许多任务中也优于现有的RAG,在所有任务中获得了非专有的基于lm的模型中的最佳性能。虽然我们的方法优于其他基线,但在PopQA或Bio上,具有检索功能的强大指令调优的lm(例如,LLama2-chat, Alpaca)从它们的非检索基线中获得了很大的收益。然而,我们发现这些基线为我们不能简单地复制或提取检索段落的子字符串的任务提供了有限的解决方案。在PubHealth和ARC-Challenge上,与没有检索的基线相比,有检索的基线并没有显著提高性能。我们还观察到,大多数检索基线都难以提高引文准确性。在ASQA上,我们的模型比除ChatGPT之外的所有模型都显示出更高的引用精度和召回率。Gao等人(2023)发现,ChatGPT在这一特定任务中始终表现出优越的疗效,超过了较小的lm。我们的SELF-RAG弥补了这一性能差距,甚至在引用精度方面优于ChatGPT,该精度衡量模型生成的声明是否完全得到引用证据的支持。我们还发现,在事实精度的度量上,SELF-RAG 7B偶尔优于我们的13B,这是由于经常生成较小的SELF-RAG的趋势精确接地但短输出。Llama2-FT7B是在与SELF-RAG相同的指令输出对上训练的基线LM,没有检索或自我反思,仅在测试时进行检索增强,滞后于SELF-RAG。这一结果表明SELF-RAG的收益不仅仅来自于训练数据,也证明了SELF-RAG框架的有效性。
5.2 分析
消融实验。我们对我们的框架进行了一系列的精简,以确定哪些因素发挥了关键作用。我们评估了与我们的模型训练不同的两个模型变体:没有检索器使用给定指令输出对的标准指令跟随方法训练LM,没有检索到的段落;没有评论家用输入输出对训练LM,这些输入输出对总是在没有反射令牌的情况下用检索到的最上面的文档进行扩充。这类似于SAIL (Luo等人,2023),我们使用我们的指令输出数据,而不是像SAIL那样使用Alpaca数据集(Dubois等人,2023)。我们还对我们的推理时间算法进行了消融,包括不检索在推理期间禁用检索;硬约束表示在Retrieve =Yes而不是使用自适应阈值时检索的模型性能;Retrieve top 1总是只检索和使用top 1文档,类似于标准RAG方法;Remove ISSUP表示仅在式4中critical -guided beam search期间移除ISSUP分数的模型性能。在这个消融实验中,我们使用50k的训练实例大小来更有效地探索训练变化。在本节的后面,我们将对训练数据大小的影响进行分析。我们在PopQA、PubHealth和ASQA三个数据集上进行消融研究。在ASQA上,我们在抽样的150个实例上评估模型,并排除了涉及自适应或无检索过程的消融。
表3a显示了消融结果。表的上半部分为训练消融的结果,下半部分为推理消融的结果。我们看到所有组件都发挥着重要作用。我们还观察到SELF-RAG和No Retriever或Critic基线之间的性能差距很大,这表明使用这些模型训练LM在很大程度上有助于SELF-RAG的性能提高。在传统的RAG方法中,使用顶部段落而不考虑其相关性(检索顶部1)会导致PopQA和ASQA的大幅下降,并且在光束搜索结果中删除ISSUP会损害ASQA的性能。这证明了SELF-RAG基于细粒度多标准仔细选择生成的能力的有效性,而不是天真地使用检索模型中的所有顶级段落或仅仅依赖于相关性分数。
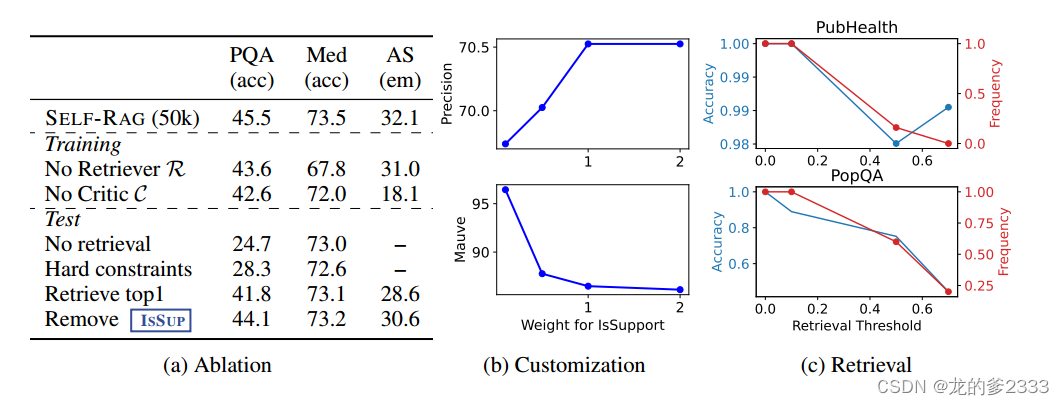
图3:SELF-RAG分析:(a)基于我们的7B模型对SELF-RAG训练和推理关键组件的消融研究。(b)软权重对ASQA引用精度和流利度的影响。(c) PubHealth和PopQA上的检索频率和归一化精度。
推理时间定制的影响。我们提出的框架的一个关键好处是,它使我们能够控制每个评估类型对最终生成抽样的影响程度。我们分析了不同的参数权重对我们的7B模型顶部在ASQA推理时间的影响,其中考虑了多个评估方面。图3b显示了更改ISSUP的权重项的效果,它评估文本段落对输出的支持程度。如图所示,增加权重会对模型的引用精度产生积极影响,因为这更强调模型生成是否得到证据的支持。
相反,权重越大,MAUVE得分越低:当生成越长、越流畅时,往往会有更多的主张没有得到引用的完全支持,这与Liu等人(2023a)的发现一致。我们的框架允许实践者在测试时通过调整这些参数来选择和定制模型的行为,而不需要额外的训练。
效率和准确性的权衡。使用我们的框架,从业者可以使用奖励令牌的令牌概率来调整检索发生的频率。我们评估了这个自适应阈值如何影响检索的总体准确性和频率,并在PubHealth和PopQA上评估了不同数量的阈值δ(较大的δ导致较少的检索)的性能。图3c显示了模型的检索频率在两个数据集上的显著变化。随着δ的变化。一方面,在PubHealth中,检索较少导致的性能下降较小,但在PopQA中则较大。
训练数据大小的影响。我们对数据规模如何影响模型的性能进行了分析。特别是,我们从原始的150k训练实例中随机抽取5k、10k、20k和50k实例,并在这些子集上微调四个SELF-RAG 7B变体。然后,我们将在PopQA、PubHealth和ASQA(引用精度)上的模型性能与在完整的150k个实例上训练的最终SELF-RAG进行比较。我们还对图4a、4b和4c进行了评估,图4a、4b和4c显示了模型在不同数据量上的性能。在所有数据集中,增加数据量通常会显示出上升的轨迹,并且在PopQA和ASQA中改进幅度更大,而当我们将训练数据从50k增加到150k时,我们在Llama2-FT7B上没有观察到如此显著的改进。这些结果也表明,进一步扩大SELF-RAG的训练数据可能会导致进一步的改进,尽管在本工作中我们将训练数据的大小限制在150k。
人类的评估。我们对SELF-RAG输出以及预测反射令牌的可靠性进行了小规模的人工评估。特别是,我们从PopQA和Bio结果中抽取了50个样本。在Menick等人(2022)之后,人类注释者评估标准普尔,这表明模型输出是否可信(即,输出是对问题的合理和主题响应,就像它发生在对话中一样)和支持(即,提供的证据足以验证答案的有效性)。对于标普,我们不考虑SELF-RAG预测不相关或没有支持的情况。然后,我们询问我们的注释者,关于ISREL和ISSUP的模型预测反射令牌是否与他们的检查相匹配(例如,完全支持的输出是否得到引用证据的支持)。人类注释者发现SELF-RAG的答案往往是可信的,并且有相关段落的支持,这些段落在短格式PopQA上的标准普尔得分较高,这与Menick等人(2022)的结果一致。人类注释者还发现,ISREL和ISSUP反射令牌预测大多与他们的评估一致。附录表6显示了几个关于评估的注释示例和解释。
6 结论
本文介绍了SELF-RAG,这是一个新的框架,通过按需检索和自我反思来提高大语言模型的质量和真实性。SELF-RAG通过预测原始词汇表中的下一个标记以及新添加的特殊标记(称为反射标记)来训练LM学习检索、生成和评估文本段落和它自己的生成。SELF-RAG通过利用反射令牌进一步支持在测试时裁剪LM行为。我们使用多个指标对六个任务进行了整体评估,结果表明SELF-RAG明显优于具有更多参数或传统检索增强生成方法的llm。