本次分享论文:Towards Translating Real-World Code with LLMs: A Study of Translating to Rust
基本信息
原文作者:Hasan Ferit Eniser, Hanliang Zhang, Cristina David, Meng Wang, Maria Christakis, Brandon Paulsen, Joey Dodds, Daniel Kroening
作者单位:MPI-SWS, University of Bristol, TU Wien, Amazon Web Services, Inc.
关键词:代码翻译,Rust语言,大语言模型(LLMs),差分模糊测试,自动化反馈
原文链接:https://arxiv.org/pdf/2405.11514
开源代码:暂无
论文要点
论文简介:本论文探讨了利用大语言模型(LLMs)进行代码翻译的能力,特别是从其他编程语言翻译到Rust语言。研究主要评估了五种先进的LLMs,包括GPT-4、Claude 3等,在处理实际开源项目代码时的表现。为此,作者开发了一种名为FLOURINE的端到端代码翻译工具,通过差分模糊测试验证Rust翻译的输入/输出等效性,从而消除了对预先存在的测试用例的需求。研究显示,最成功的LLM可以翻译47%的基准代码,并提供了改进的见解。
研究目的:随着对Rust等安全编程语言的兴趣增加,将潜在的有缺陷的旧代码翻译成现代语言的需求也在增加。论文旨在回答大语言模型是否能有效地翻译真实世界的代码。为此,作者开发了一种新的工具FLOURINE,通过实际开源项目的代码进行测试和评估,研究大语言模型在生成初始翻译和修复错误翻译方面的能力。
研究贡献:
1. 开发了FLOURINE工具,能够在无需手写测试用例的情况下生成验证过的Rust翻译。
2. 构建了跨语言模糊测试器,能够在不同语言之间传递输入和输出。
3. 利用FLOURINE进行了首次大规模研究,评估了大语言模型在翻译真实世界代码方面的能力。
4. 证明了大语言模型能够翻译部分真实世界项目,并且直接向大语言模型提供反例反馈的效果不如重复原始提示。
5. 开源了所有代码、基准和结果,以便复现实验。
引言
代码翻译任务在编程语言之间变得越来越重要,尤其是在将可能有缺陷的旧代码翻译成Rust等现代安全语言的背景下。传统的“规则基础”翻译工具针对特定的源语言和目标语言,而大语言模型则有望胜任任意源语言和目标语言的翻译任务。过去的工作主要集中在竞赛编程网站、教育网站或手工设计的编码问题上,这些基准不具代表性。而本研究则着眼于真实世界的代码,利用大语言模型进行Rust翻译。
相关工作
相关工作主要分为代码翻译、跨语言差分模糊测试和大语言模型的反馈策略。多数代码翻译工作集中在竞赛编程风格的代码上,而本研究则评估了大语言模型在真实世界代码翻译中的表现。现有的跨语言差分模糊测试工作中,很少考虑不同语言实现的比较。
本研究开发的跨语言模糊测试工具是目前唯一一个尝试将不同语言编译成共享IR进行测试的工具。关于大语言模型的反馈策略,虽然有一些工作展示了使用反例反馈的成功,但我们的结果显示这种策略在大语言模型的代码翻译任务中效果并不好。
研究概述
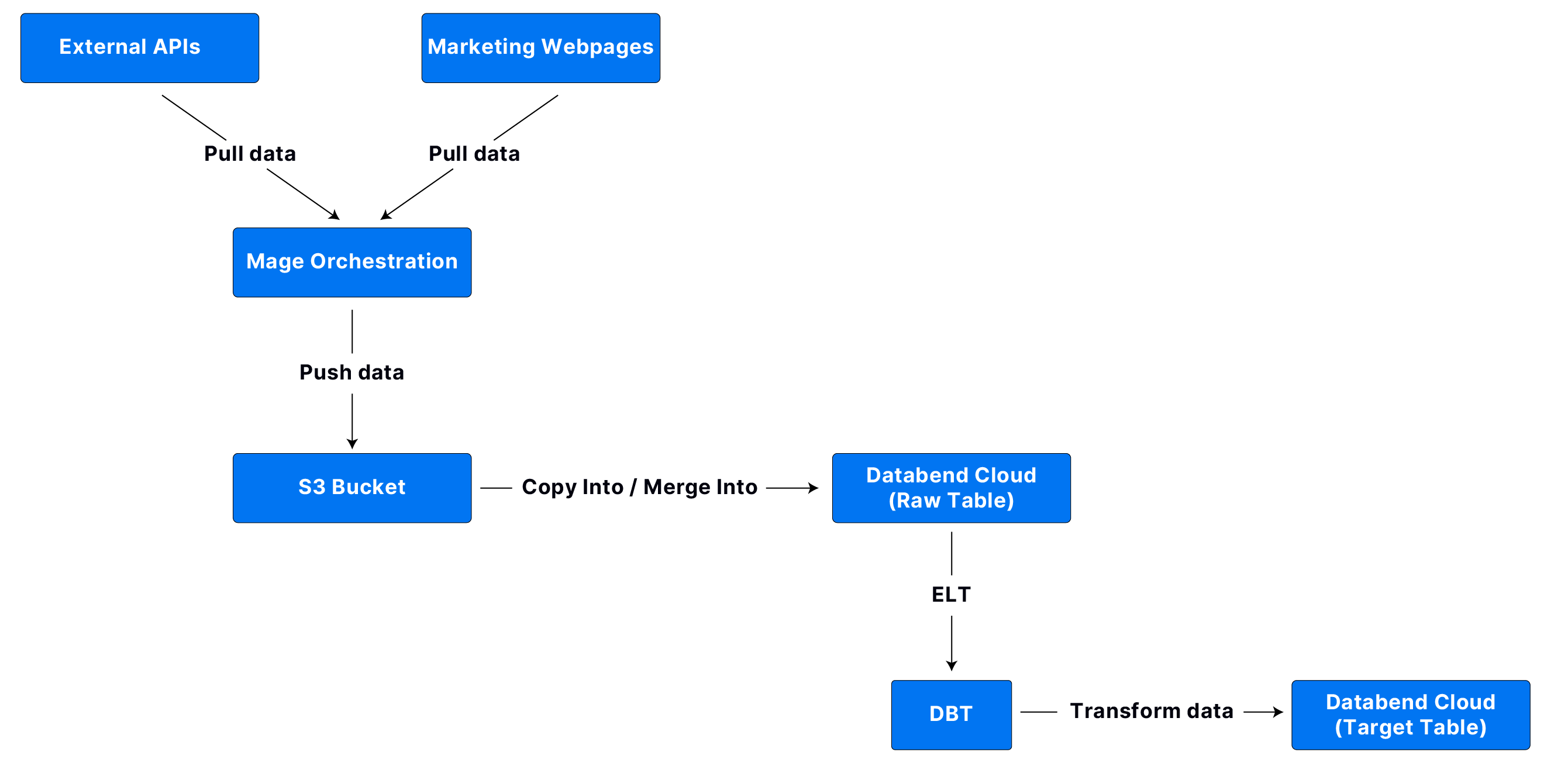
本研究开发了一个名为FLOURINE的端到端代码翻译工具,旨在评估和改进大语言模型(LLM)在翻译真实世界代码时的表现。FLOURINE首先使用LLM生成候选翻译代码,然后应用编译驱动的修复,利用Rust编译器的错误信息进行逐步修复。一旦代码通过编译,FLOURINE使用跨语言差分模糊测试来验证翻译的输入/输出等效性,这种方法无需预先存在的测试用例。如果发现翻译不等效,工具将执行反馈策略,向LLM提供反例以修复错误翻译。数据集由七个开源项目的代码样本组成,这些项目涉及音频处理、文本处理、几何学、银行、二维三角测量、图算法和声卡仿真,确保翻译任务的多样性和复杂性。实验结果展示了LLM在生成和修复翻译代码方面的潜力,为未来的改进方向提供了宝贵的见解。
基于LLM代码翻译
本研究的代码翻译算法采用了迭代方法,首先通过大语言模型(LLM)生成候选翻译,然后通过编译驱动的修复阶段确保代码可以编译。编译驱动修复利用Rust编译器的错误信息进行逐步修复,以获得可编译的翻译代码。接着,使用跨语言差分模糊测试验证翻译代码与原始代码的输入/输出等效性。如果发现反例,则将这些反例反馈给LLM,以生成新的候选翻译。整个过程重复进行,直到找到通过所有测试的翻译代码或达到设定的迭代次数。
反馈策略
本研究评估了四种反馈策略,以提高代码翻译的成功率。简单重启策略在每次失败后重新生成翻译,不提供任何额外信息。提示重启策略在原始提示中加入模糊测试的正反例,帮助LLM识别正确行为和避免错误。基于反例的修复策略则将发现的反例反馈给LLM,要求其修正特定错误路径上的问题。对话式修复策略保留所有历史对话,每次在原提示基础上添加新的反例反馈,形成连续对话。结果显示,简单重启和提示重启效果最佳,而直接提供反例的策略效果不如预期。
研究评估
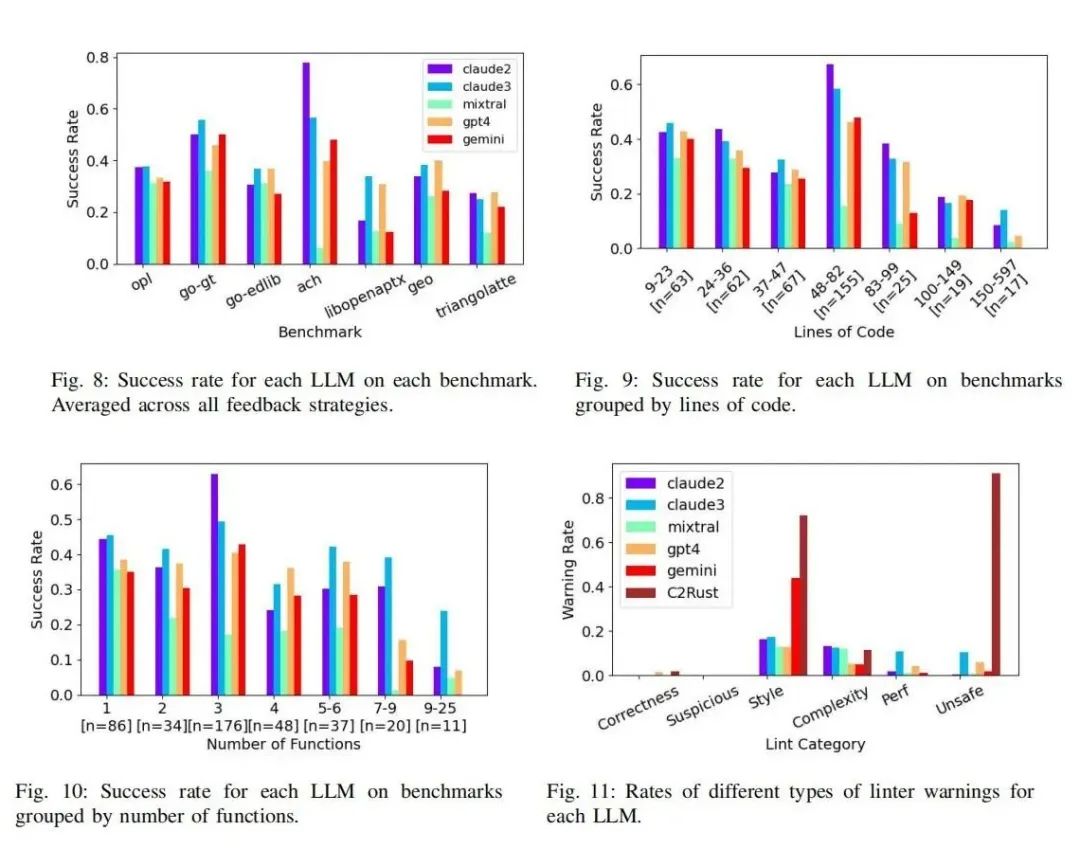
在研究评估中,我们对五种先进的LLM(包括GPT-4、Claude 3等)进行了8160次代码翻译实验,评估了它们在处理408个真实世界代码样本时的表现。结果显示,这些LLM的成功翻译率在21%至47%之间,且代码复杂度越高,翻译成功率越低。实验还揭示了反馈策略的有效性,尽管基于反例的修复策略效果不如预期,但简单重启和提示重启策略显著提高了成功率。研究还发现,LLM生成的Rust代码通常更简洁、语法更规范,但在某些情况下仍会产生非惯用或性能欠佳的代码。
论文结论
本研究展示了大语言模型在翻译真实世界代码方面的能力,并提出了FLOURINE工具作为验证Rust翻译的有效方法。尽管反例反馈在本研究中的效果不佳,但LLM在代码翻译任务中展示了显著的潜力。未来的研究可以进一步优化反馈策略和模糊测试器,以提高翻译的成功率和代码质量。
原作者:论文解读智能体
校对:小椰风