本节课为「计算机视觉 CV 核心知识」第一节课正式课;
「AI秘籍」系列课程:
- 人工智能应用数学基础
- 人工智能Python基础
- 人工智能基础核心知识
- 人工智能BI核心知识
- 人工智能CV核心知识

Hi,大家好。我是茶桁。
老同学对我应该都很熟悉了,那新来的同学可能还不太认识我。不认识的有兴趣的话就自行找找相关简介吧,我也就不多介绍了,直接开始咱们的课程。
迄今为止,「茶桁的 AI 秘籍」系列已经写了有一年了,期间从最基础的 Python 编程基础,到相关的数学基础,再到一些神经网络的核心基础知识都已经讲的七七八八了。但是 CV 部分呢,也就是计算机视觉方面的核心知识课程,今天还是第一节课。
在这节课之前我们同学应该是学了前面的一些机器学习的内容,看了计算机视觉的一些介绍。那么从这节课开始我们就开始真正的去从一个比较底层,或者说从比较核心的来出发学习计算机视觉方面的知识。
课程内容详情
我们大概会这样去安排:
1. 计算机视觉基础:图像处理
这部分内容中,会先去学图像处理,也就是计算机视觉的基础图像处理这部分的内容。
核心知识点是图像相似变化、仿射变换;图像锐化、模糊、形态学运算;灰度直方图、直方图均衡化。
2. 认识计算机视觉
这部分内容就是认识计算机视觉,也就是说,图像处理到计算机视觉的过渡。学这个的时候我们就要思考一个问题:图像处理和计算机视觉到底是什么样的关系,有什么相同点,有什么不同点。
核心知识点:方向梯度直方图(Histogram of Oriented Gradient,HOG),图像局部纹理特征(Local Binary Pattern, LBP)、Haar-Like 特征提取。
3. GPU 如何在 LeNet 提升中发挥作用
这部分我们讨论一个问题:GPU 在 LeNet 的提升中发挥的作用。这部分和前面看似衔接不是那么紧,这部分内容是比较多,就是标题上我们好像没有衔接那么紧,但是内容上我们是有衔接的。内容是稍微有点跨度,这些内容还包含一个 LeNet 网络,LeNet 就是计算机视觉,或者CNN、深度神经网络、深度卷积网络中第一个比较有代表性的网络。我们把 LeNet 讲了之后再讨论一下 GPU 如何在 LeNet 提升中发挥作用,为什么要用 GPU 提升,那 LeNet 提升到底有哪些思考,有哪些思路,GPU到底是发挥了怎样的作用。
核心知识点:GPU/CPU 架构、GPU 线程的操作与调度、认识 PyCuda 库、用 PyCuda 实现矩乘法
4. 计算机视觉中的图像分类
接下来这部分内容中,我们就开始真正的去做一些事。计算机视觉中,前面三部分课程就把基础打完了,这部分我们真正的开始做一个事情,就是图像的分类。图像的分类在计算机视觉的三大问题中它是最重要、最核心的一类问题,计算机就是分类这个问题。
核心知识点为:AlexNet、VGG、RestNet、DenseNet、MobileNet、EfficientNet
5. 深度学习之两阶段目标检测
接着我们会讲深度学习之两阶段的目标检测。
核心知识点就包括 RCNN,NMS, Fast RCNN,Rol Pooling, Faster RCNN, RPN, Anchor
6. 深度学习之单阶段目标检测
这部分内容是单阶段的目标检测。核心知识点就是 YOLO。
这部分和之前的部分中我们主要是讲目标检测,会把目标检测单阶段和两阶段的主要的模型、主要的思路给讲一下。那么这两个模型,这两个主要的思路可以说是所有我们看到的计算机视觉的项目中几乎都含有的两种思路,要么就是其中之一。这两个思路是非常重要。
这两个思路也是学习后面一些比较好的检测模型的一个基础。这两个思路如果掌握了,你基本上接触最新的目标检测,这个思路是没有什么问题了。
7. 计算机视觉中的图像分割
接着就是计算机视觉中的图像分割。
可以看到第四部分是分类,第五、第六部分是目标检测,第七部分是图像分割。这四个部分的内容就涵盖了计算机视觉的三大问题:分类、检测和分割。其中分类是基础,就分类掌握了,其实你可以不用再去看那个目标检测都可以做目标检测的事情了。
所以说目标检测是在以分类为思路的基础上发展来的,分割也是。所以,我说分类是计算机视觉的一个基础。
这部分核心知识点:反卷积与上采样、全卷积网络(FCN)、UNet、ENet、Mask RCNN、TensorMask
所以第四部分是开始一个具体的应用,一直到第七部分。
8. 计算机视觉中的目标跟踪
这一部分是计算机视觉中的目标跟踪。
目标跟踪又是一个应用,但是我们没有把它归类为计算机视觉的三大问题,它是计算机视觉若干小问题中的一种,它是另外一个扩展,也是我们前面学习到一个知识的综合的应用。
解决目标跟踪的思路有非常多,我们到时候去一一去介绍一下。
核心知识点:TLD、KCF、卡尔曼滤波、mean-shift、粒子滤波
计算机视觉的三大问题,分类检测和分割,只有目标检测花了两个章节的时间,分割只花一节的时间。所以说从这方面你能看到,目标检测在我们计算机视觉任务中的重要性,以及我们在当前发表的论文也好、研究机构也好,或者研究的大部分从业者,是要掌握目标检测模型的,是要用到的,非常重要。是计算机视觉中的一个核心的点。
OK,这是我们这个课的主要内容了,就是从第一部分到第八部分,一共这么多些内容,一、二、三是打基础,四就开始做计算机视觉中的三大问题了,第八部分就是计算机视觉中的一个扩展性的问题——目标跟踪。大概就这么样的一个安排。
那么这节课呢,是咱们第一部分的第一节课。这节课的内容是基本的图像处理。
好,接下来呢,咱们从一个视频开始,先初步的认识一下这个计算机视觉。
How Computer vision works「中文字幕」
这个视频虽然全是英文,但是我补上了中文字幕。所以也不存在听不懂的情况了,这个视频大概介绍了一下计算机视觉的内容。
接下来,咱们就来讨论一下计算机视觉的由来,讨论一个比较基础的问题:我们为什么要用矩阵来表示图像。
我们知道,现在我们表示图像、视频都是要用矩阵,为什么?那么你可以想一下,看看你自己的答案和等一下我讲的答案是否一样。
 计算机视觉解决什么问题?
计算机视觉解决什么问题?
首先我们回答这样的一个问题:计算机视觉解决什么问题?
我们现在学习了计算机视觉了,那有人会问你,计算机视觉解决什么问题?或者计算机视觉是到底是啥?你怎么回答他?
你的父母会问你做什么工作,你说计算机视觉,有的时候可能我们就说人工智能,高大上对吧?那么说到底是啥呢?怎么回答呢?
我记得之前的公司有个同事,他是做人脸关键点检测的,反正也是一种算法。他爸是老师,他爸就问他:你们现在做什么事情呢?我现在家里的老照片坏了你能不能帮我修复一下?你们不是做图像处理吗?你帮我修复一下。
然后他就笑了,他说我不是做这个的,我是做关键点检测的。然后他爸又听不懂,他说反正你是做计算机视觉,都读到硕士了,我这老照片你给我修复一下。他就跟他爸解释了半天,那时他解释的时候用的是专业术语他爸也听不懂。
我们讨论这个事情,如何跟别人直白的讲出来我们到底是做什么的。这个问题说不清楚,说明自己其实没有对自己从事的或者学习到的内容有很好的一个概括和总结,一句话、两句话说不出来,或者说一大堆还解释不清楚。
那基本上,你要是能用简单的话把它解释出来,你就对它有个很深刻的认识。或者说就掌握的比较好了。所以说,我们就尝试去把它说明白,好吧?
那么计算机视觉要解决什么问题呢?我们看几个例子,我们来看下图:

我不是用一句话去回答它,而是用一张图片去回答它,为什么?因为图片信息量太大了,省去我太多话了。这就是我们计算机视觉的一个优势,我们是处理图片的,图片上信息量非常大,我们处理的载体就非常大,不像 NLP 只有一句话,这句话要非常精准的把一个东西描出来是需要大量的处理的,我们计算机视觉,这个图片上有很多很多信息。
OK,那么从这个图片上我们能看到计算机视觉要解决问题,我们这个图片讲的是一个 face detection,face detection 翻译过来就是人脸检测。
就这个图片上有一个人脸,我们希望把这个人脸给检测出来。那么我们就用个黄色的框把这个人脸给标出来了,这就是人脸检测的任务,人脸检测任务就是计算机视觉中的任务之一。
这个应该我们很多人应该都听说过,或者是没有听说过就第一次看到也能理解,毕竟现在很多手机、相机都包含了这项功能。看这个图片上有人的话立马就知道他的人脸在哪里,就是人脸检测。
那么人脸检测我们再扩展一下,其实后面还有很多例子,我们来扩展一下就是还有人脸识别。
这样一个图片上我把人脸的位置给它框出来了,那这张图片到底是定义为人脸检测还是人脸识别呢?其实从语言上来理解这两个都行:这个图片上有人脸,我把这个人脸给检测出来了,我把这人脸给识别出来了。这里的识别、检测实际上一个意思。什么意思呢?用在这里都是一个定位的意思,要把人脸定位,识别定位、检测定位。这是我们常用的语言,常用的语言体系都是这么理解的。
当你是一个算法工程师的时候,你的产品经理或者是你的业务跟你说「我要做一个人脸检测」,或者说「我要做一个人脸识别」的时候,其实「识别」就是更加口语化。
这时候你脑子要想,「我要做一个人脸识别」,这个人脸识别是什么,到底是定位还是另外一种人脸识别,我们知道人脸识别还有一种是要识别出这个人是谁。
比如说我们考勤机,要识别出这个人的名字、要识别出这个人和身份证、这个人是不是一个人。所以说你要清楚业务问你的问题,它到底是指的是人脸的定位,从图片上把图片上的人脸给定位出来还是说要把这个人脸具体识别出来,这个人是谁。
因为这种情况造成的误解,我们专业上学计算机视觉的人会把人脸方面的这两个问题区分开。就是对人脸的定位和对人脸的身份识别。我们需要把它的称呼给固定下来,人脸的定位统称为「人脸检测」,我们业内不叫他人脸识别,我们把人脸识别就统称为「身份识别」。
身份识别,这就是人脸检测这方面的一个容易造成歧义的地方。就是跟别人交流沟通的时候,通常不知道这个事情,不知道有人脸定位和人脸身份识别这两个事情,它会把人脸识别搞混淆了。
那这时候你要反应快一点,到底是说把图片上的人脸的位置给出来,或者是只要检测到图片上有人脸就行,还是说要把这个人的身份给识别出来。他到底是谁,工号是多少,你要把它搞清楚。
OK,这是人脸识别任务,这是计算机视觉要解决的问题之一。就图片上有人脸的话,要把它识别出来。识别出来就两方面内容,一个就是把位置识别出来,一个就是把他的身份识别出来,这是计算机视觉。
所以有人问你说你现在到底做什么,计算机视觉到底做什么,那这个就很清楚很简短了,很有代表性。你也可以概括一下,是「让计算机代替我们人眼去做人脸识别」。
然后我们再看一下计算机视觉到底解决什么问题。

这是什么应用呢?我们看一下。第一步,upload your photo,上传你的照片;第二步,apply some makeup,化一些妆;第三步,choose a hairstyle,选择一个发型,所以它是一个美颜的功能,我们现在各种 APP 都有美颜的功能。
所以计算机视觉这方面的技术就可以用来做美颜,那我们需要做什么事情呢?上图第一步是一张原图,我们要对原图进行 makeup,要进行化妆,通常重点就是眼睛、嘴巴、鼻子,要对某些部位的颜色特征进行改变,那怎么改变呢?首先第一步,我们要把这些部位的位置给检测,这个图片上这些部位,眼睛在什么位置,鼻子、嘴巴在什么位置要检测出来。那么这里要用到一个技术,叫「人脸关键点检测」,叫 face Landmark。
就这个检测技术结果出来之后,我们去改变这个 Landmark 周围这些区域的一些颜色状况就可以了。如果是眼睛周围就把眼睛周围加一些眼影等等。然后这些 Landmark 我们还可以把相应的发型图片放到头部相应的位置,并且缩放一定的尺度,旋转一定的角度。所以说这种应用也是我们计算机视觉的应用之一。像这种应用就不只是解决我们人眼看到什么的一个问题,它就是对图像的直接处理了。这也是属于计算机视觉的一个应用。
所以说有人问你计算机视觉到底做什么,就做美颜,美颜也是一个很简单的回答。
我们再看一个应用:

这个应用是另外一个事情,叫 motion sensing,就是运动检测,and gesture recognition,这是一个姿态或者是动作的识别。这是一个客厅里的一个游戏,打排球的一个游戏。要通过摄像头来识别出来当前在摄像头前这个人的动作姿态。
那么这个识别的方式方法有非常多种,可以通过二维、三维,甚至通过别的方式。无论通过什么方式,它都属于计算机视觉部分的内容。它可能只是数据采集的方式不一样,但它归根到底都是矩阵,都是对矩阵的各种处理,方法又非常的像,都是我们的各种模型,各种 model。
然后我们看一下,这是一个综合的图。
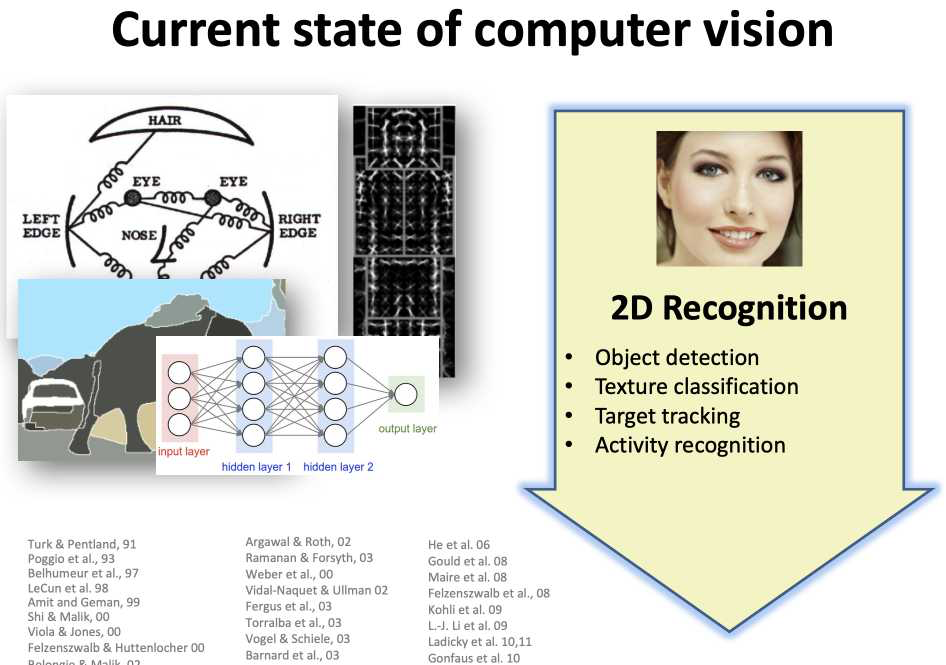
这是 current state of computer vision。图里有个总结是 2D 的 recognition,2D的识别。
2D的识别有些什么内容呢?
object detection,目标的检测;我们刚才说人脸 detection,face detection 是定位。目标检测也是定位,定位加分类。就定位到某个位置,这个位置有什么类别的内容。像人脸检测定位到某个位置有个人脸,目标检测就定位到某个位置有个飞机,定位到某个位置有个显示器。
然后第二个内容 texture,texture 是个纹理分类,或者可以理解为 OCR。就是文字的分类,文字的识别。
然后 target tracking 是目标跟踪,这是我们最后一个部分要讲解的内容。
然后是 activity recognition,这是一个 recognition 的内容,是个识别层的内容,大概就翻译为活动识别。
总之无论它换什么名字其实都是一个分类的任务,或者说是一个特殊要求的分类的任务。
这组图中的这个部分

这个图我们做图像处理或者做计算机视觉实验比较基础的内容可能就会了解,这个图实际上画的是一个特征图。这个图看样子画的是 hog 特征,这个 hog 特征是对我们图片进行处理提特征的时候常用的一个提特征的手段。那什么叫提特征呢?我们在之后的课程中认识计算机视觉会讲,并且会讲 hog 特征的提取方法,如果把提的特征显示出来,大概就是这种图。
有兴趣了解的可以去看看这篇论文:「Object Detection with Heuristic Coarse-to-Fine Search」:https://www.semanticscholar.org/paper/Object-Detection-with-Heuristic-Coarse-to-Fine-Girshick/c684d188a28f77483a7ca9ee0653bc5105f2106c
INFO: 要研究论文的话,ChatGPT 不一定是最好的方式了,可以试试 Google 的 NotebookLM,具体的可以看看这个短片:
这应该是你最强的学术论文研究工具
然后,网络结构我们应该就比较常见了,在之前的基础课上应该也看到过:
那被网络结构遮挡的那张图就是图像分割的结果了。虽然我们看不完整,但是也能看到一个大概,图中把牛、道路、汽车、山脉、天空分割出来了,这是图片分割的结果,是图片分割要输出的一个结果。输入是一张图片,然后输出分割之后的结果。
我们可以在这张图上看到不少的例子,那我们的计算机视觉这么多的例子要一下讲清楚并不容易。
然后还有什么呢?我们来看这张图:

这两个人看场景动作都非常相似,但是我们能看出来一个是朱茵,一个是杨幂。那实际上这两个人是换脸得到的,换脸的叫AI换脸,AI换脸曾经有人出过 APP 也非常火,并且还推动了《民法典人格权编(草案)》的出台。
因为这个有很多个人隐私方面的风险,或者说法律风险。所以这个现在都在抵制,讲到这里不得不感慨一下,技术应用到社会黑暗面的破坏力。就算已经有相关法律的出台,但是现在 AI 换脸诈骗依然层出不穷。一般人根本分不清对面通过换脸的到底是自己的亲戚朋友还是陌生的诈骗者,或者说不知道有这项技术的都认为这个图片是真的了对吧?
那 AI 换脸到底用到什么技术呢?其实用到也有个关键检测,当然除了关键的检测之外还会有别的更多的一些技术,比如说有图像的后处理,有衔接的部分,就植皮的时候,你植的皮和原来的皮肤或者原来的图像的一个衔接的部分,它过渡要平滑。
还有视频中的换脸,那个技术叫 face2face。也就是说一个视频,原来是某个人在说话,我想变成另外一个人去说话,我就把要换的脸贴到这个视频上,我的表情就随着那个人的表情去改变,张嘴,并且嘴里也是有牙齿的。
这种应用其实也是有的,不过这种应用其实那么开源的就稍微少一些。那前段时间我讲解了 SadTalker,是属于阿里的 EMO 的免费开源平替,就是一张图片和一段语音生成一个以假乱真的视频。
想要在自己的电脑上生成一个任意头像的口播吗?我教你啊....
下面一个技术就比较实用化了,我们看一下。

首先这有三张图片,第一张图片这个人脸是正对图片的,正中间的第二张图片人脸是转了个头的,第三张图人脸就回正了。这是什么?
这实际上是就是我们人脸识别之前的一个活体检测功能,检测摄像头前人是不是真人,是不是有人拿着你的手机,拿着别人的视频、照片来冒充这个人。所以会要求手机摄像头前这个人按照规定做一些动作。如果我让你转头你就转头了,我就认为你是活人,是真人。然后我再看看你的身份,是不是要登录这个账号的身份。这是人脸识别进行鉴权,是个活体检测的功能。
那这种活体检测叫动作活体,这种动作活体在我们生活中已经大量的广泛的使用了。你登录某个银行 APP 的时候,或者你在火车站进入检票口的时候,或者登录一些其他 APP 的时候,它会让你进行人脸识别。
人脸识别之前,它会让你去鉴权,就是活体检测,让你做一些动作。比如说很多人在一起你就没法做,你就找一个人少的地方,光线不错的地方做一下。这就是活体检测。
OK,到这里我们等于说是就把我们计算机是要解决什么问题说了一遍。大概就是解决这些问题:人脸检测、人脸识别、美颜、活动识别、手势检测等等。还有其他的,比如说AI换脸啊,比如活体检测等等,就类似于这些内容。
当然还有非常多其他的应用,那么所有的这些内容其实都可以用我们学到计算机视觉中的分类、检测、分割这三种方法把它覆盖掉。基本上这种技术都可以做这个事情,是个综合的应用。
行,那我们本节课就介绍到这里,介绍完了之后我希望大家脑子里对计算机视觉就有个基本的认识,并且稍微组织一下。当别人问你,你做计算机事业到底是做什么?组织一下你自己的语言回答一下。其实回答之后你要看看他到底理解到哪种层次,如果他没接触过你就说就像人脸识别那种技术,他大概知道你做什么事情。
行,那咱们下节课再见。
相关系列课程:
- 人工智能应用数学基础
- 人工智能Python基础
- 人工智能基础核心知识
- 人工智能BI核心知识
- 人工智能CV核心知识
#小程序://海豚知道/qwC6nIDbKMKYKmx
觉得课程对您有用,请点击下方「看一看」和「转发」,分享给更多人






![[数据概念]一分钟弄懂数据治理](https://img-blog.csdnimg.cn/img_convert/2ef2a15ebfc232c59f94db3a4df1e7c9.jpeg)