指令微调(Instruction Tuning),是指使用自然语言形式的数据对预训练后的大语言模型进行参数微调,在一些文章中也称为有监督微调(Supervised Fine-tuning,SFT)或多任务提示训练(Multitask Prompted Training)。指令微调的第一步就是收集或构建指令化的实例,然后通过有监督的方式对LLM的参数进行微调,经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习(zero-shot)的方式解决多种下游任务。
一般来说,一个经过指令格式化的数据实例包括任务描述(也称为指令)、任务输入-任务输出以及可选的示例。下面,我们将主要介绍三种构建格式化指令数据的方法。
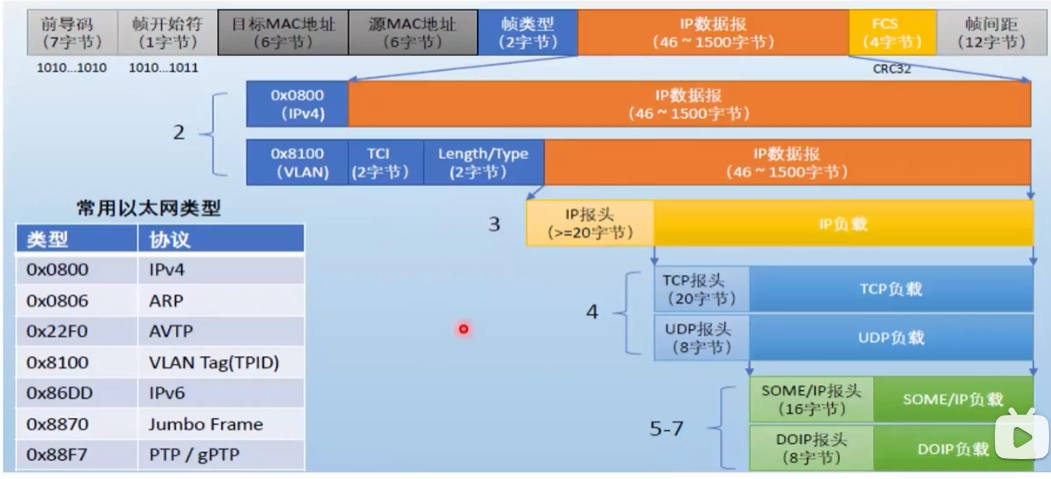
1、基于现有的NLP任务数据集构建
学术界围绕传统NLP任务(如机器翻译、文本摘要和文本分类等)发布了大量的开源数据集合,这些数据是非常重要的监督学习数据资源,可以用于指令数据集的构造。

通常来说,这些NLP数据集都包括输入和输出两个主要部分。例如,在中英翻译任务中,输入是“大语言模型已经成为机器学习的一个重要研究方向”,而相应的输出则是“Large language models have become one important research direction for machine learning”。
为了生成指令化的训练数据,一个非常关键的步骤就是为上述的“输入-输出”对数据添加任务描述信息,用于指导模型去理解任务目标以及相关信息。在上述的例子中,可以向中译英的翻译数据集中添加指令,例如“请把这个中文句子翻译成英文”。通过上述操作,就可以将一个NLP任务的数据实例全部通过自然语言形式进行表达,进而数据实例可以被用于大语言模型的指令微调。

经过NLP指令数据微调后,大语言模型可以学习到指令遵循(Instruction Following)的能力,进而能够解决其他未见过的NLP任务。相关研究表明在现有NLP数据集的输入-输出数据中添加合适的任务描述是提升大模型指令跟随能力的关键因素,如果去除了这些任务描述,仅使用输入-输出数据对模型进行微调,模型的性能会出现显著下降。
此外,为了进一步丰富训练实例,还可以设计特定的任务描述来翻转现有实例的输入-输出对,从而得到新的任务数据用于指令微调。例如,给定一个问题-答案对,传统的训练方式是基于问题预测答案;同时也可以基于答案生成问题,以此方式来创建一个新的“问题生成”实例,比如可以使用任务描述“请基于以下答案生成一个问题”。
2、基于日常对话数据构建
尽管通过指令格式化已有的NLP数据集能够获得大量的指令数据实例,但是这些数据的多样性比较局限,与人类的真实需求也不能很好匹配。为此,可以使用用户在日常对话中的实际需求作为任务描述。例如,InstructGPT将用户提交给OpenAIAPI的查询作为任务描述。由于这些用户查询源自于真实应用场景,均采用自然语言形式进行表达,因此特别适合大模型学习指令跟随能力。
为了进一步增加任务的多样性,OpenAI还雇佣标注者创作更多的真实生活任务,包括开放式生成、开放式问答、头脑风暴等任务,然后由另一组标注者来回答这些问题作为输出。OpenAI最终将指令(用户真实查询或者人工标注的任务)和期望的输出(人工编写的答案)配对作为一个训练实例。
用户第一轮输入:激活函数有什么作用?
模型第一轮输出:激活函数是神经网络中的一种非线性函数,通常应用于神经元的输出上。它的作用是为神经网络引入非线性特性,使得神经网络可以更好地逼近复杂的非线性函数。如果不使用激活函数,神经网络将只能实现线性变换,无法学习复杂的非线性关系。……
用户第二轮输入:什么是复杂的非线性关系?
模型第二轮输出:复杂的非线性关系指的是输入与输出之间存在着非常复杂的非线性映射关系,无法用简单的线性函数来描述。这样的关系可能是高维度、非平稳、非对称等。例如,在图像识别任务中,一张图片中的不同物体之间的关系非常复杂,无法用简单的线性函数来描述。……
……(省略后续多轮对话)
为了推动指令微调数据集的开放共享,最近研究人员创建并且开源了一些常见的日常对话任务指令集,例如Dolly和OpenAssistant,这些数据均由人工精心标注,因此具有较高的质量。此外,研究人员还尝试通过自行构建的开放平台收集大量的用户对话请求作为输入数据,并使用ChatGPT或GPT-4生成回复作为输出数据。其中,一个代表性的数据集是来自于ShareGPT的多轮对话数据。
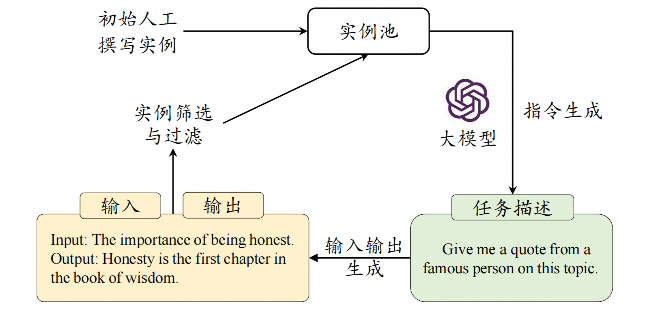
3、基于合成数据构建
为了减轻人工收集与标注数据的负担,研究人员进一步提出半自动化的数据合成方法。他们借助已有的高质量指令数据作为上下文学习示例输入大语言模型,进而生成大量多样化的任务描述和输入-输出数据。
如上图所示,Self-Instruct方法仅需要使用100多个人工撰写的实例作为初始任务池,然后随机选择数据作为示例,就可以通过提示大语言模型生成新的指令微调数据。这种半自动化的合成方法具备高效生成大规模指令微调数据的能力,从而显著降低了人工标注所需的经济成本,在实践中得到了广泛应用。
考虑到Self-Instruct生成的实例可能过于简单或缺乏多样性,还有一种改进的指令数据合成方法Evol-Instruct,该方法通过基于深度和广度的演化来提高实例的复杂性和多样性。
Self-Instruct方法
Self-Instruct方法借助大语言模型(例如ChatGPT)所具备的数据合成能力,通过迭代的方法高效地生成大量的指令微调数据。作为初始任务池,该方法首先构建了175条高质量且多样的指令数据,之后经由两个主要步骤生成指令微调数据。
- 指令数据生成:从任务池中随机选取少量指令数据作为示例,并针对Chat-GPT设计精细指令来提示模型生成新的微调数据。具体地,ChatGPT模型将以下图中的指令和上下文示例,来仿照生成一些新的任务描述和对应的输出:
你被要求提供10个多样化的任务指令。这些任务指令将被提供给GPT模型。
以下是你提供指令需要满足的要求:
1.尽量不要在每个指令中重复动词,要最大化指令的多样性。
2.使用指令的语气也应该多样化。例如,将问题与祈使句结合起来。
……(省略后续要求)
下面是10个任务指令的列表:
###指令:将85华氏度转换为摄氏度。
###输出:85华氏度等于29.44摄氏度。
###指令:是否有科学无法解释的事情?
###输出:有很多科学无法解释的事情,比如生命的起源、意识的存在……
……(省略上下文示例)
- 过滤与后处理:该步骤的主要目的是剔除低质量或者重复的生成实例,从而保证指令数据的多样性与有效性。常见的过滤方法包括:去除与任务池中指令相似度过高的指令、语言模型难以生成回复的指令、过长或过短的指令以及输入或输出存在重复的实例。
Evol-Instruct方法
Evol-Instruct方法是一种基于大语言模型的指令数据复杂化技术。该方法基于初始指令数据集进行扩展,主要包含两个步骤:
- 指令演化:在该步骤中,大语言模型作为指令演化器,针对两个不同的方向进行指令的拓展,分别为深度演化和广度演化。深度演化通过五种特定类型的提示(添加约束、深化、具体化、增加推理步骤以及使输入复杂化)使得指令变得更加复杂与困难;而广度演化旨在扩充指令主题范围、指令涉及的能力范围以及整体数据集的多样性。
Evol-Instruct深度演化(添加约束)指令:
我希望您充当指令重写器。
您的目标是将给定的提示重写为更复杂的版本,使得著名的AI系统(例如Chat-GPT和GPT-4)更难处理。
但重写的提示必须是合理的,且必须是人类能够理解和响应的。
您的重写不能省略#给定提示#中表格和代码等非文本部分。
您应该使用以下方法使给定的提示复杂化:
请在#给定提示#中添加一项约束或要求。
你应该尽量不要让#重写提示#变得冗长,#重写提示#只能在#给定提示#中添加10到20个单词。
#重写提示#中不允许出现“#给定提示#”、“#重写提示#”字段。
#给定提示#:{需要重写的指令}
#重写提示#:
Evol-Instruct广度演化指令:
我希望你充当指令创造器。
您的目标是从#给定提示#中汲取灵感来创建全新的提示。
此新提示应与#给定提示#属于同一领域,但更为少见。
#创造提示#的长度和复杂性应与#给定提示#类似。
#创造提示#必须合理,并且必须能够被人类理解和响应。
#创造提示#中不允许出现“#给定提示#”、“#创造提示#”字段。
#给定提示#:{需要重写的指令}
#创造提示#:
上面是深度演化(添加约束)和广度演化的具体指令,我们将此提示和需要重写的指令输入到大语言模型中,模型便会根据这些指令生成演化后新的提示。然后再将这个指令输入给大模型来得到相应的答案,这样便构建了一条新的指令-输出数据实例。
- 数据后处理:该阶段将去除部分实例数据以保证数据集合的整体质量和多样性。主要使用了如下的规则进行处理:使用ChatGPT比较演化前后的指令,移除ChatGPT认为差异很小的指令;移除大模型难以响应的指令,如响应中包含“sorry”或响应长度过短;移除仅包含标点符号和连词的指令或回复。
以上是常见的三种构建格式化指令数据的方法,通过指令微调旨在使用人工构建的指令数据对于大语言模型进一步训练,从而增强或解锁大语言模型的能力。
【推荐时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台。





![[数据概念]一分钟弄懂数据治理](https://img-blog.csdnimg.cn/img_convert/2ef2a15ebfc232c59f94db3a4df1e7c9.jpeg)