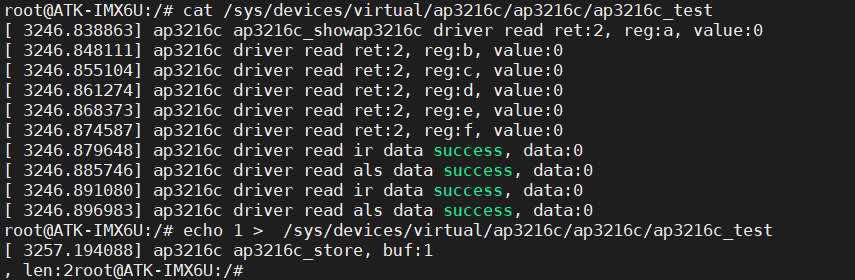
1.什么是Cache预取
众所周知,CPU访问Cache中的数据是比访问内存中的数据是要快的,而因为程序都有时间局部性和空间局部性,时间局部性简单来说就是某一条或几条指令在一段时间内会被CPU多次执行;空间局部性简单来说就是某一段数据块中的数据会被CPU多次访问。像这样的会被CPU多次执行和访问的指令和数据,将其放在Cache中,会提高CPU执行程序速度。Cache预取就是在这样的背景下诞生的。
而Cache预取又分为硬件预取和软件预取。
关于硬件预取,举一个例子:
// 程序1:
for (int i = 0; i < 1024; i++) {
for (int j = 0; j < 1024; j++) {
arr[i][j] = num++;
}
}
// 程序2:
for (int i = 0; i < 1024; i++) {
for (int j = 0; j < 1024; j++) {
arr[j][i] = num++;
}
}
程序1是按照数组在内存中的保存方式顺序访问,而程序2则是跳跃式访问。对于程序1,硬件预取单元能够自动预取接下来需要访问的数据到Cache,节省访问内存的时间,从而提高程序1的执行效率;对于程序2,硬件不能够识别数据访问的规律,因而不会预取,从而使程序2总是需要再内存中读取数据,降低了执行效率。
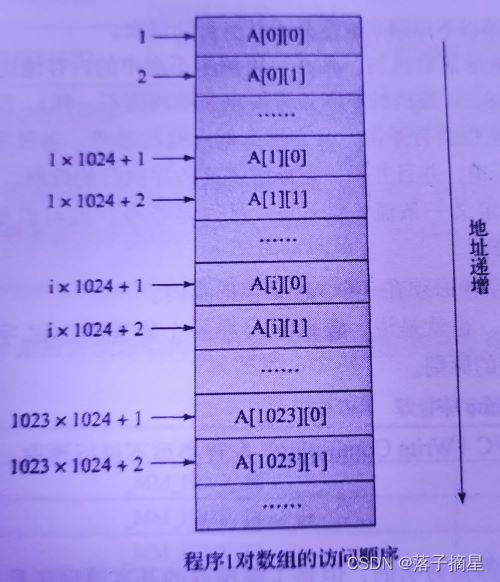
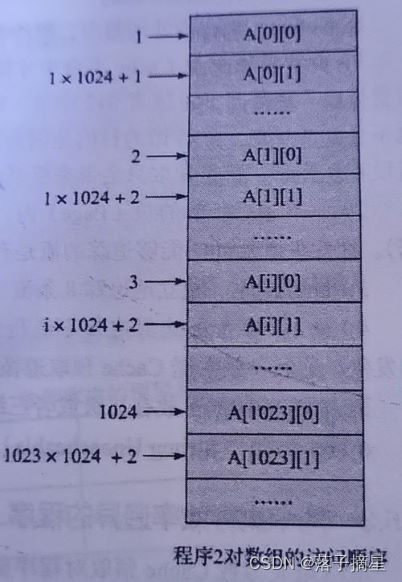
因此,硬件预取单元不一定能够提高程序执行的效率,所以一些体系架构的处理器增加了一些指令,作为软件预取指令。DPDK中也有相关预取函数,如:rte_ixgbe_prefetch(sw_ring[rx_id].mbuf); // 预取下一个控制结构体mbuf
rte_packet_prefetch((char*)rxm->buf_addr + rxm->data_off); // 预取报文
DPDK必须保证所有需要读取的数据都在Cache中,否则一旦出现Cache不命中,性能将会严重下降。为了保证这一点,DPDK采用了多种技术来进行优化,预取只是其中一种。
3.什么是Cache一致性
当我们定义了一个数据结构或者分配了一段数据缓冲区之后,在内存中就有一个地址和其相对应,然后程序就可以对它进行都写。对于读,首先是从内存加载到Cache,最后送到处理器内部的寄存器;对于写,则是从寄存器送到Cache,最后通过总线写回内存,这两个过程就引出了两个问题:
问题1:该数据结构或者数据缓冲区的起始地址是Cache Line对齐的吗?如果不是,即使该数据区域大小小于Cache Line,那么也需要占用两个Cache entry;并且,假设第一个Cache Line前半部分属于另外一个数据结构并且另外一个处理器正在处理它,那么当两个核都修改了该Cache Line从而写回各自一级的Cache,准备送回内存时,如何同步数据?毕竟每个核都只修改了该Cache Line的一部分。
对于这个问题,一个解决办法就是定义该数据结构或者数据缓冲区时就申明对齐,DPDK对很多结构体定义的时候就是如此操作的。例如:
struct rte_ring_debug_status {
uint64_t enq_success_bulk;
uint64_t enq_success_objs;
uint64_t enq_quota_bulk;
uint64_t enq_quota_objs;
uint64_t enq_fail_bulk;
uint64_t enq_fail_objs;
uint64_t deq_success_bulk;
uint64_t deq_success_objs;
uint64_t deq_fail_bulk;
uint64_t deq_fail_objs;
} __rte_cache_aligned;
__rte_cache_aligned的定义如下所示:
#define RTE_CACHE_LINE_SIZE 64
#define __rte_cache_aligned __attribute((__aligned(RTE_CACHE_LINE_SIZE)))
问题2:假设该数据结构或者数据缓冲区的起始地址是Cache Line对齐的,但是有多个核同时对该段内存进行读写,当同时对内存进行写回操作时,如何解决冲突?
对于这个问题,DPDK解决的方案是:避免多个核访问同一个内存地址或者数据结构。这样,每个核尽量都避免与其他核共享数据,从而减少因为错误的数据共享(cache line false sharing)导致的Cache一致性的开销。
以下是两个DPDK为了避免Cache一致性的例子。
例子1:数据结构定义。DPDK的应用程序很多情况下都需要多个核同时来处理事务,因而,对于某些数据结构,我们给每个核都单独定义一份,这样每个核都只访问属于自己核的备份。如下:
struct lcore_conf {
uint16_t n_rx_queue;
struct lcore_rx_queue rx_queue_list[MAX_RX_QUEUE_PER_LCORE];
uint16_t tx_queue_id[RTE_MAX_ETHPORTS];
struct mbuf_table tx_mbufs[RTE_MAX_ETHPORTS];
lookup_struct_t * ipv4_lookup_struct;
lookup_struct_t * ipv6_lookup_struct;
} __rte_cache_aligned; // Cache行对齐
struct lcore_conf lcore[RTE_MAX_LCORE] __rte_cache_aligned;
以上的数据结构“struct lcore_conf”总是以Cache行对齐,这样就不会出现该数据结构横跨两个Cache行的问题。而定义的数组“lcore[RTE_MAX_LCORE]”中RTE_MAX_LCORE指一个系统中最大核的数量。DPDK中对每个核都进行了编号,这样n就只需要访问lcore[n],核m只需要访问lcore[m],这样就避免了多个核访问同一个结构体。
例子2:对网络端口的访问。在网络平台中,少不了访问网络设备,比如网卡。多核情况下,有可能多个核访问同一个网卡的接收队列/发送队列,也就是在内存中的一段内存结构。这样,也会引起Cache一致性问题。那么DPDK是如何解决这个问题的呢?
网卡设备一般都具有多队列的能力,也就是说,一个网卡有多个接收队列和多个访问队列。在DPDK中,如果有多个核可能需要同时访问同一个网卡,那么DPDK就会为每个核都准备一个单独的接受队列/发送队列。这样,就避免了竞争,也避免了Cache一致性问题。
如下图:
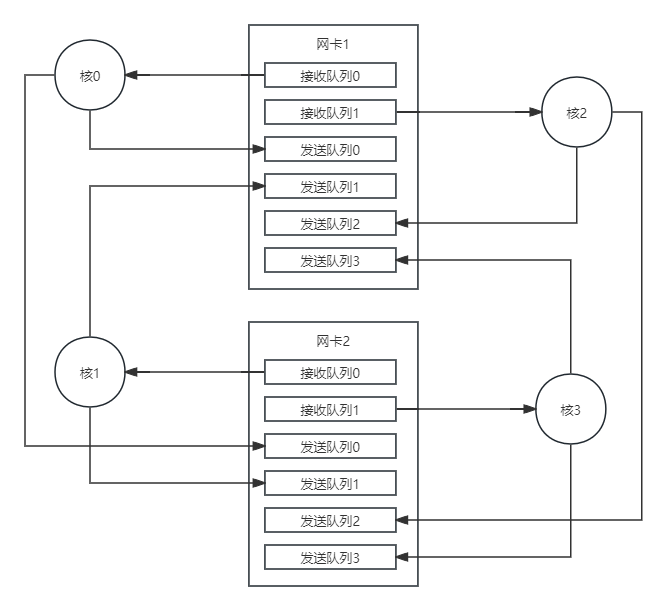
上图是四个核同时访问两个网络端口(即两个网卡)的图示。其中,网卡1和网卡2都有两个接收队列核四个发送队列;核0到核3每个都有自己的一个接收队列和一个发送队列。核0从网卡1的接收队列0接收数据,可以发送到网卡1的发送队列0或者网卡2的发送队列0;同理,核3从网卡2的接收队列1接收数据,可以发送到网卡1的发送队列3或者网卡2的发送队列3。
Cache一致性问题最根本的原因是处理器内部不只一个核,当两个或多个核访问内存中同一个Cache行的内容时,就会因为多个Cache同时缓存了该内容引起同步问题。
而上面DPDK对于问题2的解决办法很好的解决了这个问题。
文章参考《深入浅出DPDK》