本章内容需有一定Python基础,如何不懂的,请先学习Python。
什么??没有好的学习资料,给你准备好了!!
Web自动化环境搭建
1、软件准备
- python64位安装包
- chrome64位浏览器&驱动
- 浏览器驱动下载
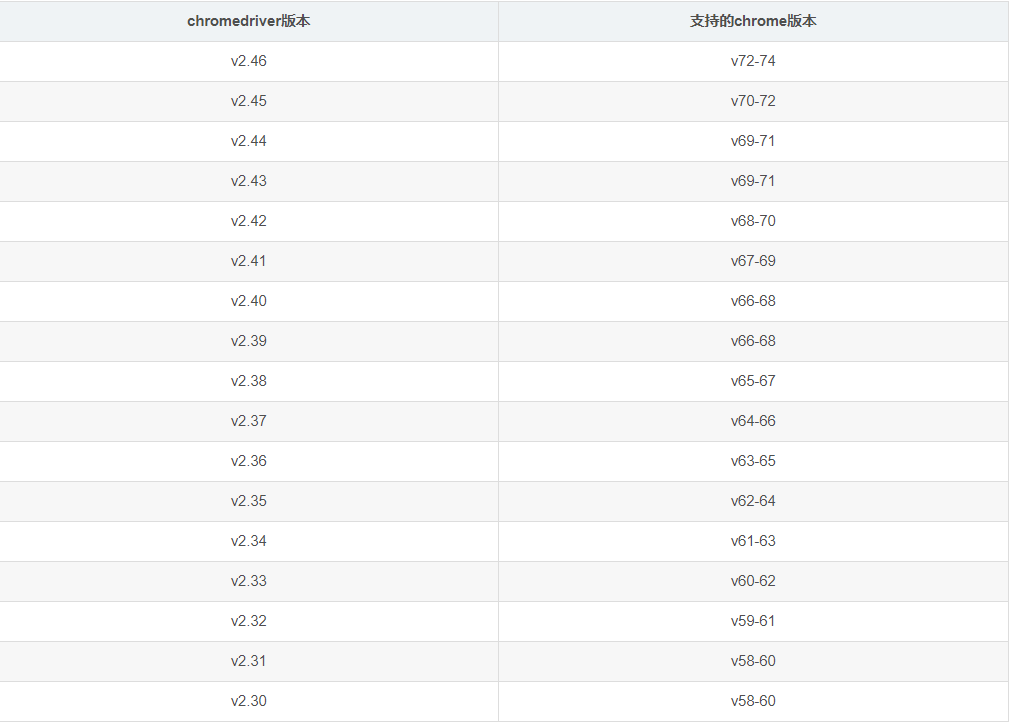
注意:chromedriver与chrome版本要对应。具体可查看该对应表
另外:本文主要以chromedirver为例
2、开始环境搭建
安装python:双击自定义安装 或者 在cmd中输入python-3.7.0-amd64.exe的路径,即在电脑中存放的位置,回车即可弹出安装页面,勾选Add Python 3.7 to PATH,即自动配置环境变量。
如图:
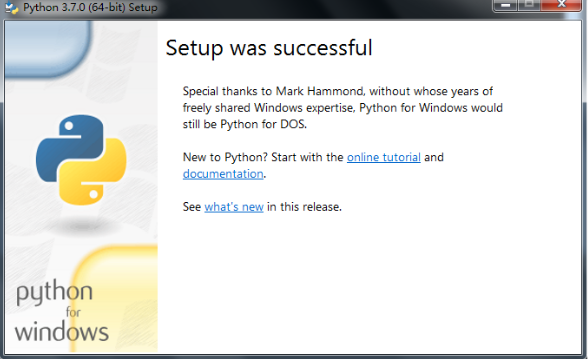
下图显示安装成功:

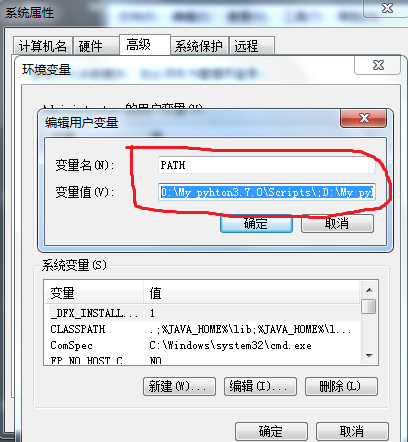
注:可以查看系统环境变量,发现D:\My pyhton3.7.0\Scripts;D:\My pyhton3.7.0;已经自动添加到了path中,这就是勾选Add Python 3.7 to PATH的效果.
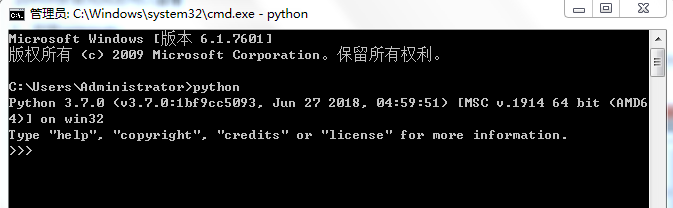
python安装完成后可以在cmd界面输入python,会出现下图内容,说明python安装成功
3、安装selenium:
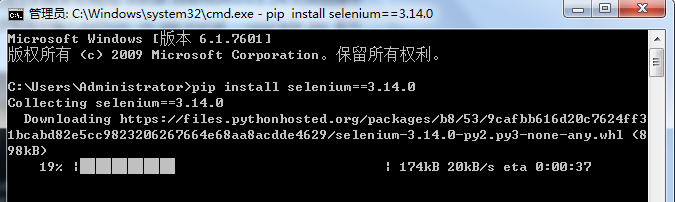
- 在cmd中运行pip install selenium 即可在线安装selenium,(ps:安装指定的版本可用pip install selenium==3.14.0)如图提示selenium安装成功。
- 使用pip show selenium 查看selenium版本信息
4、安装chrome浏览器
该处使用谷歌浏览器64位的版本号为70.0.3538.67
5、将chromedriver.exe放到python的安装目录下(或者目录下的scripts下)
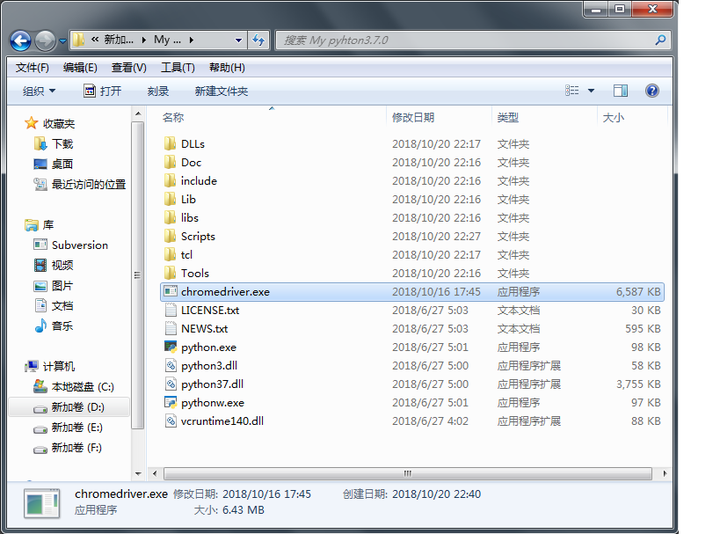
以上5步就搭建好python+selenium环境了
如果步骤还不够清楚的话,直接领取资料包,里面有步骤教学视频,按照视频一步步来操作,就很清晰了↓↓
浏览器和驱动下载
在我学习Ui自动化时,总会遇到浏览器驱动版本问题,小伙伴也是一头雾水也找不到下载的地方,今天给大家整理。

不同版本的下载地址,大家可以去查一下,我的资料包里面也会有,大家可以自己领取,自行下载就好了~
浏览器基本操作
开始自动化测试之前,需了解浏览器的一些基本操作,以方便后续的自动测试。码上开始吧!
导入Selenium模块

浏览器基本操作
- 打开网站

- 设置休眠
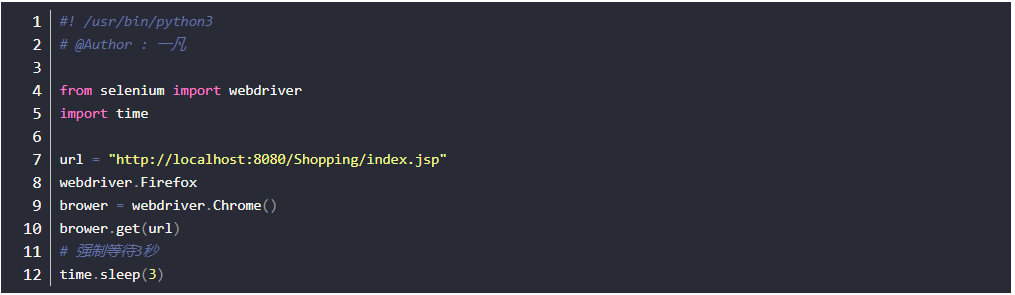
- 页面刷新
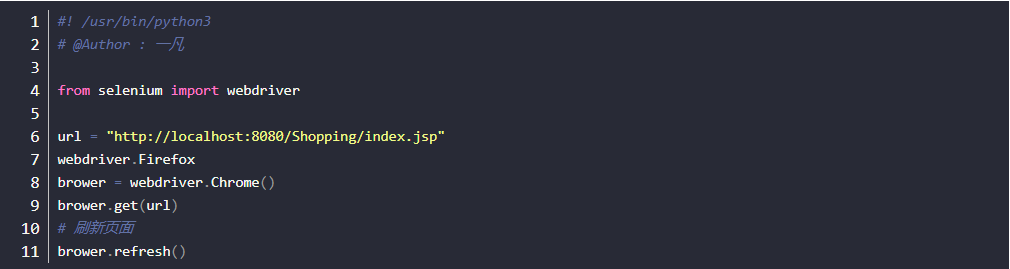
- 前进和后退
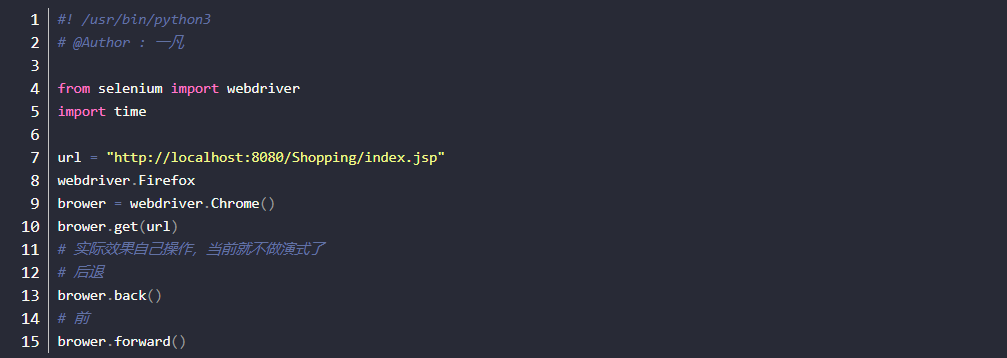
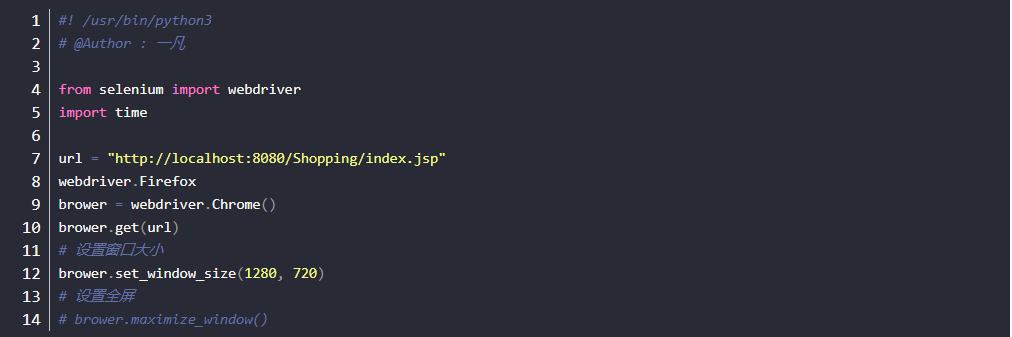
- 设置窗口大小
- 截屏

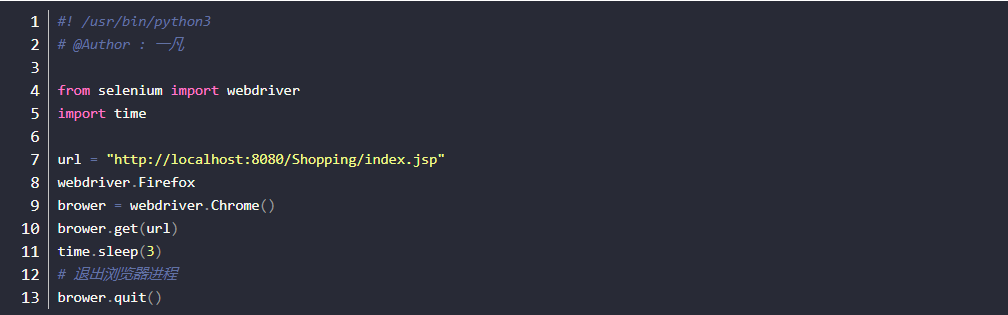
- 退出
为什么要学习定位
- 让程序操作指定元素,就必须先找到此元素;
- 程序不像人类用眼睛直接定位到元素;
- webDriver提供了八种定位元素的方式。
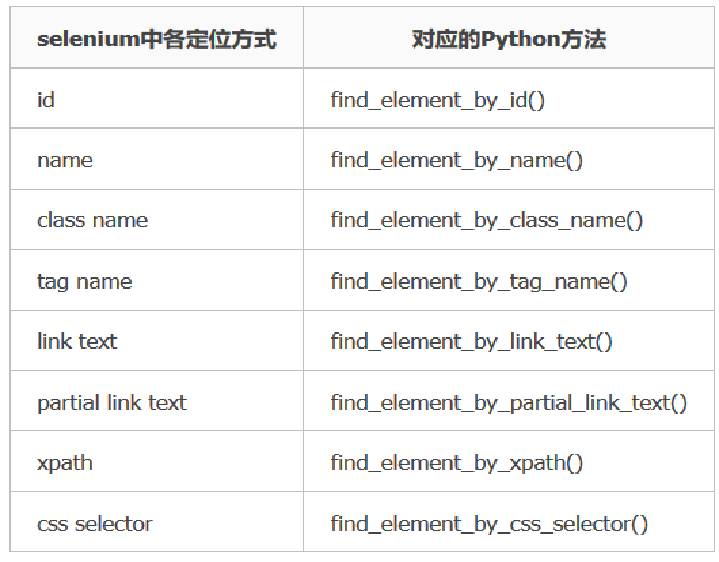
定位总结
- id、name、class_name、tag_name:根据元素的标签或元素的属性来进行定位
- link_text、partial_link_text:根据超链接的文本来进行定位(a标签)
- xpath:为元素路径定位–重点
- css:为css选择器定位(样式定位)
常见定位方式
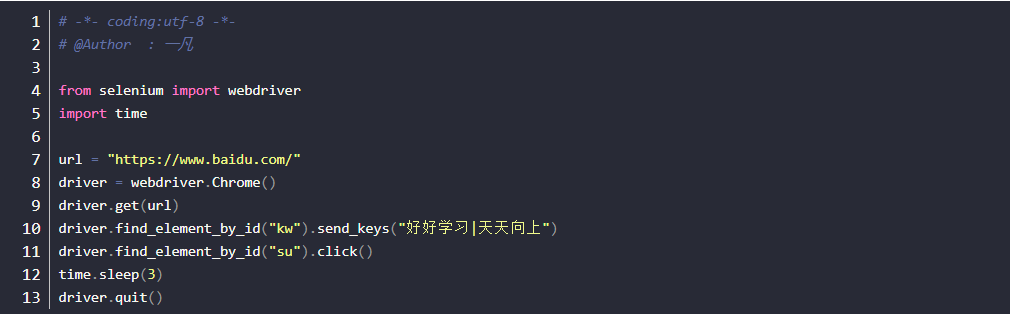
id
- 说明:HTML规定id属性在整个HTML文档中必须是唯一的,id定位就是通过元素的id属性来定位元素;
- 前提:元素有id属性
- id定位方法:find_element_by_id()
- 实现案例-1需求:打开百度界面(https://www.baidu.com/),通过id定位,输入信息,点击百度的钮
name
- 说明:HTML规定name属性来指定元素名称,name定位就是根据name属性来定位
- 前提:元素有name属性
- name定位方法:find_element_by_name()
- 实现案例-2需求:打开百度(https://www.baidu.com/),通过name定位

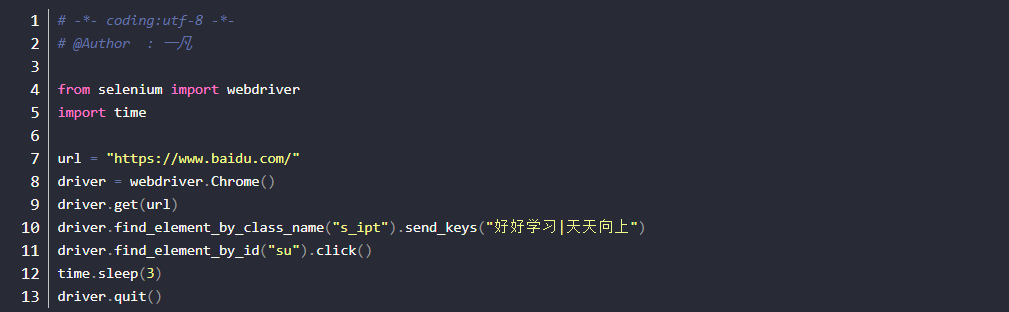
class_name
- 说明:HTML规定class来指定元素的类名,class定位就是根据class属性来定位,用法和name,id类似。
- 前提:元素有class属性
- class_name定位方法:find_element_by_class_name()
- 实现案例-3需求:打开百度界面(https://www.baidu.com/),通过class定位
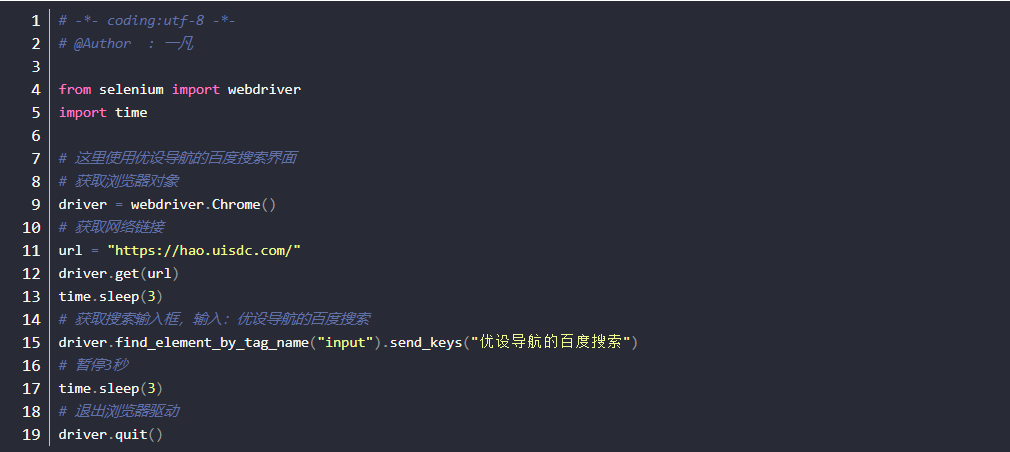
tag_name
tag_name是通过标签名称来定位的,如:a标签
注:由于HTML源码中,经常会出现很多相同的的标签名,所以一般不使用该定位方式
link_text
- 说明:link_text定位于前面4个定位有所不同,它专门用来定位超链接文本(文本值)
- 前提:定位的元素是链接标签(a标签)
- link_text定位方法:find_element_by_link_text()
- 实现案例-5需求:打开百度首页,通过link_text(链接文本)定位到【新闻】按钮,并进行点击操作

partial_link_text
- 说明:partial_link_text定位是对link_text定位的补充,partial_link_text为模糊匹配;link_text为全部匹配。
- 前提:定位的元素是链接标签(a标签)
- partial_link_text定位方法:find_element_by_partial_link_text()
- 通过传入a标签局部文本或全部文本来定位元素,要求输入的文本能够唯一找到这个元素
- 实现案例-6需求:打开百度新闻(http://news.baidu.com/),通过partial_link_text定位任何一条新闻,并进行点击操作
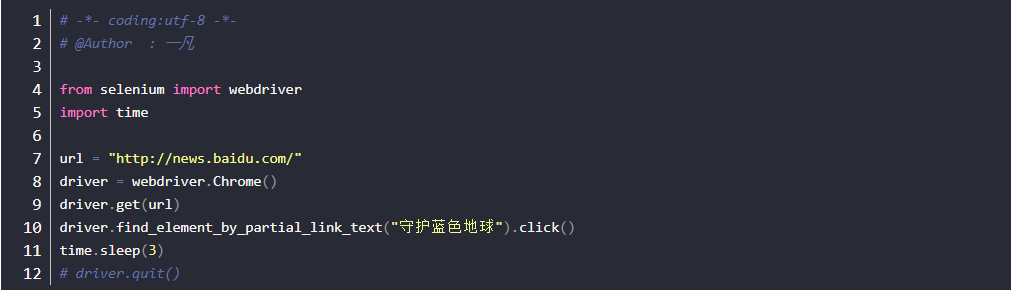
元素组
元素组定位方式:find_elements_by_xxx
作用:
查找返还定位所有符合条件的元素
返还的定位元素格式为列表格式
说明:
- 列表数据格式的读取需要指定下标(下标从0开始)
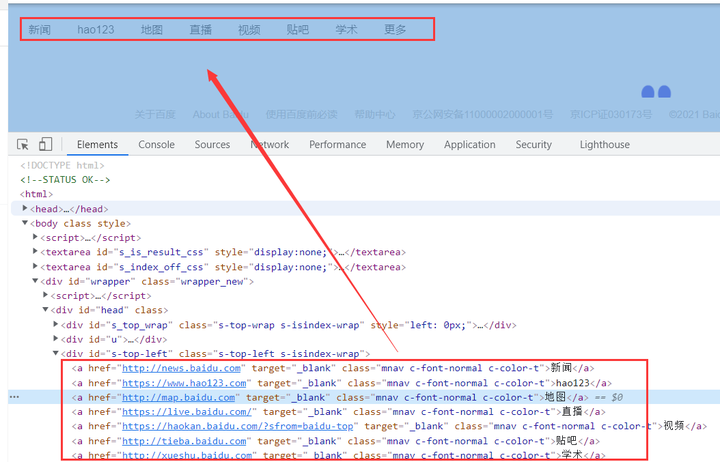
- 案例要求:打开百度页面https://www.baidu.com/,通过元素组定位

定位:"//*[@id=‘s-top-left’]/a"

xpath定位详解
通过常见属性定位
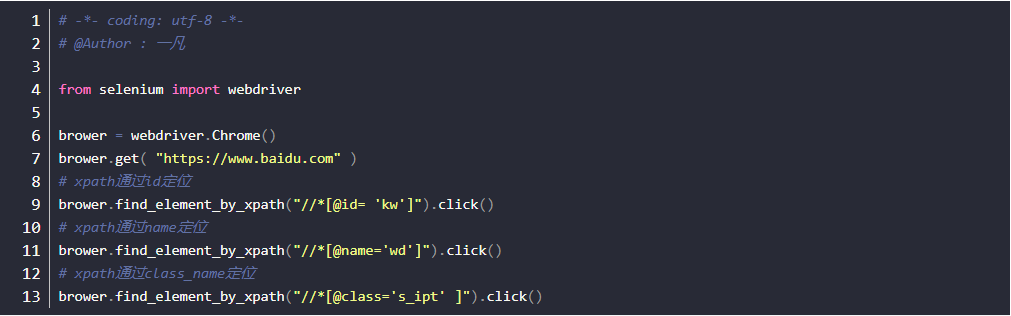
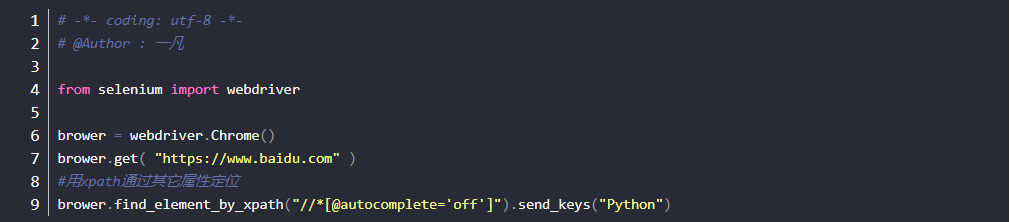
通过其它属性
- 如果一个元素id、name、class属性都没有,这时候也可以通过其它属性定位到
标签
有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
如果不想制定标签名称,可以用*号表示任意标签
如果想制定具体某个标签,就可以直接写标签名称
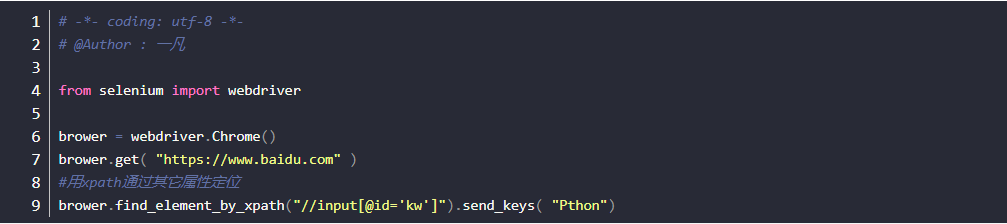
层级定位
- 如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(图中数字1)
- 找到它老爸后,再找下个层级就能定位到了
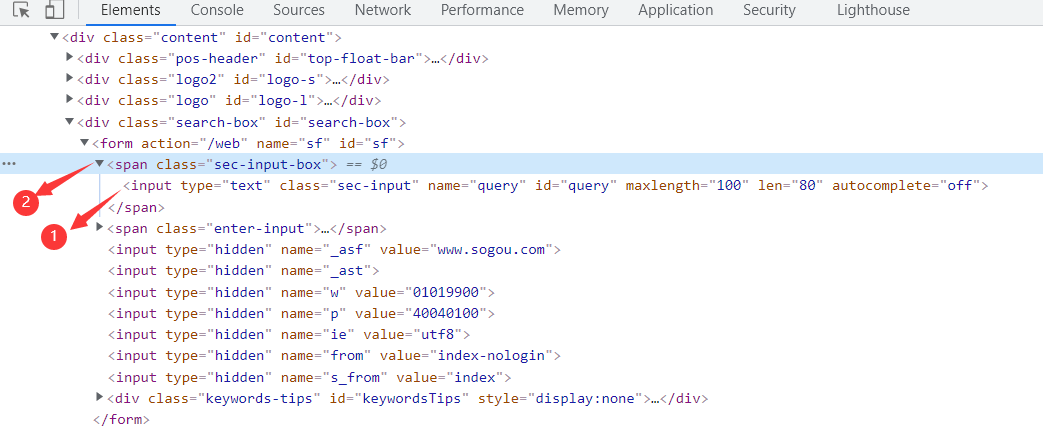
- 如上图所示,要定位的是input这个标签,它的老爸的 class=“sec-input-box yuyin-cur”
- 要是它老爸的属性也不是很明显,就找它爷爷id=form(图中数字2)
- 于是就可以通过层级关系定位到

索引
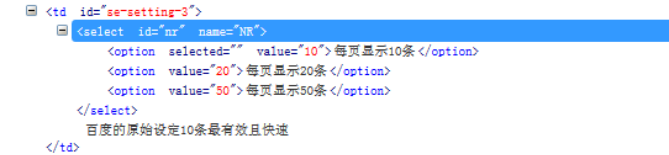
- 百度主页–设置–搜索设置
1.如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
3.如下图三胞胎兄弟
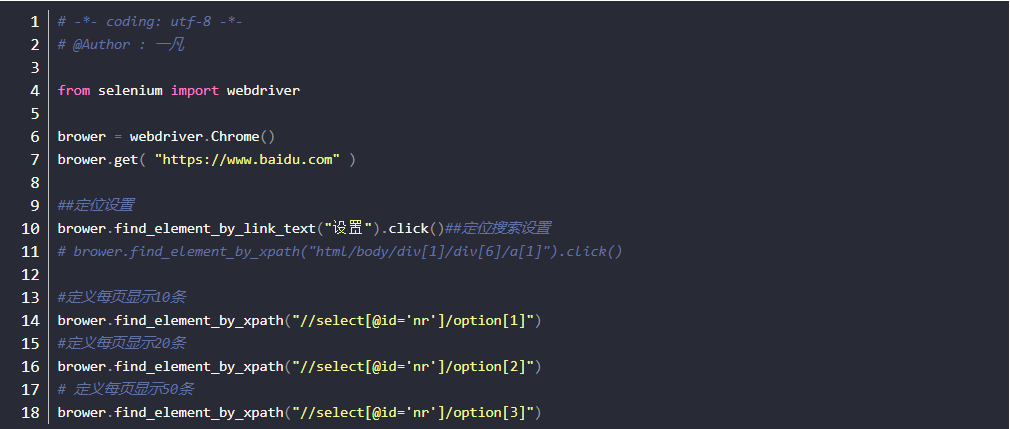
4.用xpath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)
逻辑
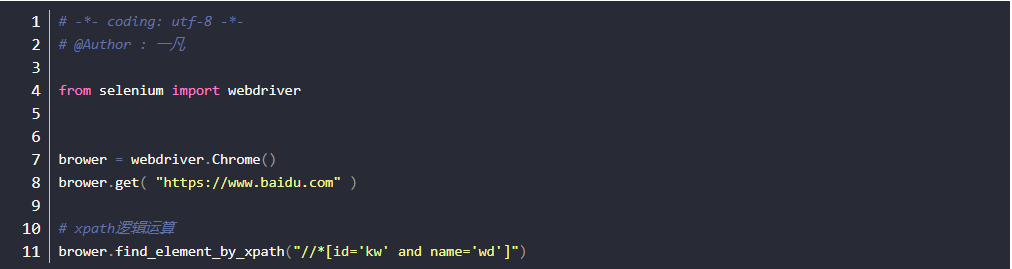
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
2.一般用的比较多的是and运算,同时满足两个属性
定位总结
定位单个元素
1.id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
下面两种要重点掌握其中一种,两者都会是更好的。现在我比较喜欢用xpath定位
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
定位一组元素
1.id复数定位find_elements_by_id(self, id_)
2.name复数定位find_elements_by_name(self, name)
3.class复数定位find_elements_by_class_name(self, name)
4.tag复数定位find_elements_by_tag_name(self, name)
5.link复数定位find_elements_by_link_text(self, text)
6.partial_link复数定位find_elements_by_partial_link_text(self, link_text)
7.xpath复数定位find_elements_by_xpath(self, xpath)
8.css复数定位find_elements_by_css_selector(self, css_selector)
如何定位多个元素呢?

操作元素

数据驱动
- 我个人的理解就是说,把自动化测试中需要用到的数据和代码分开。
- 当我们需要用到这个数据时,直接读取里边的数据就可以。
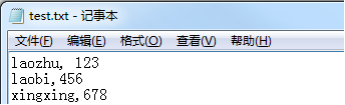
- 工作中常用到的文本格式有:txt、csv。假设我要搜索一组数据,进行一个简单的登录操作
txt文件

excel
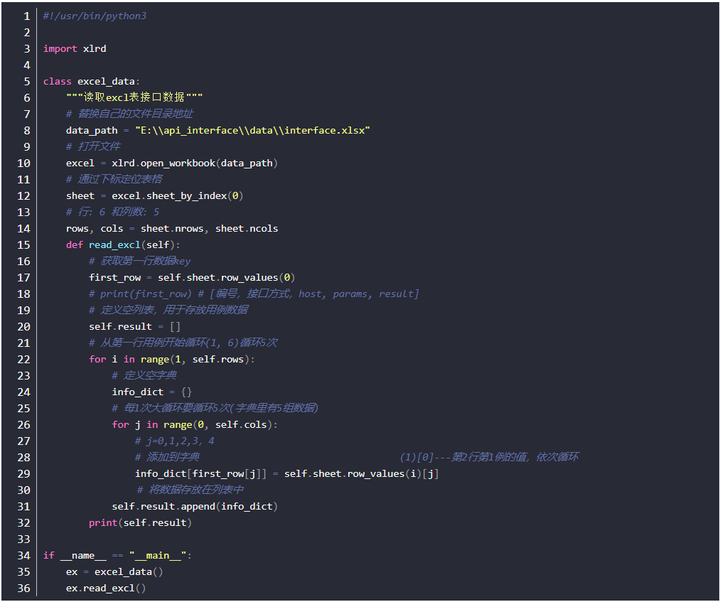
- 小伙伴都知道,测试用例是写在Excel里的,如果是少量的用例很容易处理,如果用例成百上千条呢?
- 自动化测试的话,需要对用例数据进行读取,那必须循环读取才可以实现自动化。那么问题来了,怎么做呢?

问题解析:
1、用列表存放这些用例数据,所以要用到列表
2、每一行用例要存放在字典内,所以需要用到字典
3、循环写入到字典,然后存放到列表内
运行结果

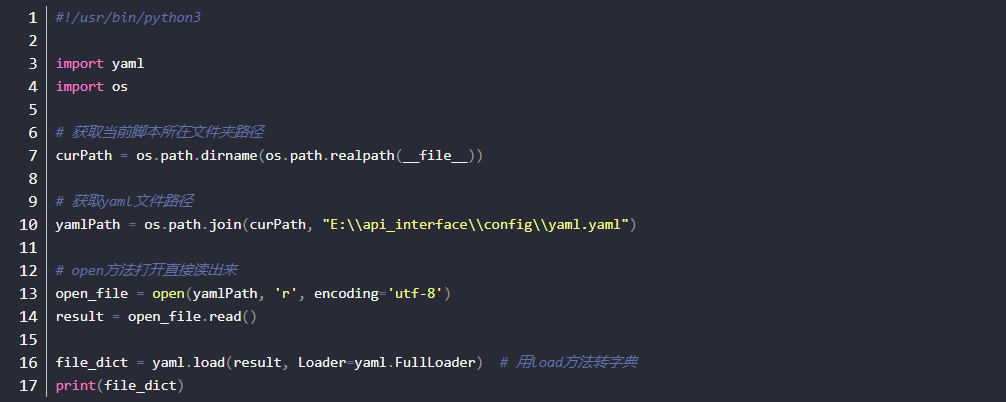
yaml
- yaml文件后缀名为yaml,如文名件.yaml
- yaml为第3方模块,需另行安装pip install pyyaml
问题解析:
1.定义文件地址
2.打开yaml文件
3.读取文件后转成字典以方便读取
运行结果

键盘操作
什么是键盘事件
- 在web产品测试中我们经常还会用到其它键盘操作,如删除,空格,回车,Ctrl+C等
- 这些操作都包含在Keys类中,所以要模拟键盘操作是首先要导入keys包。
- 所有的键盘操作都是在最后的 send_keys()里面通过改变参数实现的。

键盘常见操作

案例操作
鼠标操作
- 前面我们已经学习到可以用 click()来模拟鼠标的单击操作
- 在实际的 web 产品测试中发现,有关鼠标的操作,不仅只有单击,有时候还要用到右击,双击,拖动等操作
- 这些操作都包含在ActionChains 类中,所以要模拟鼠标操作是首先要导入ActionChains

鼠标常见操作

左击操作
- 对ActionChains类进行实例化对象操作
- 调用click(元素)方法
- 执行操作perform方法
- 案例1: 对百度的搜索输入hello,左击百度一下按钮

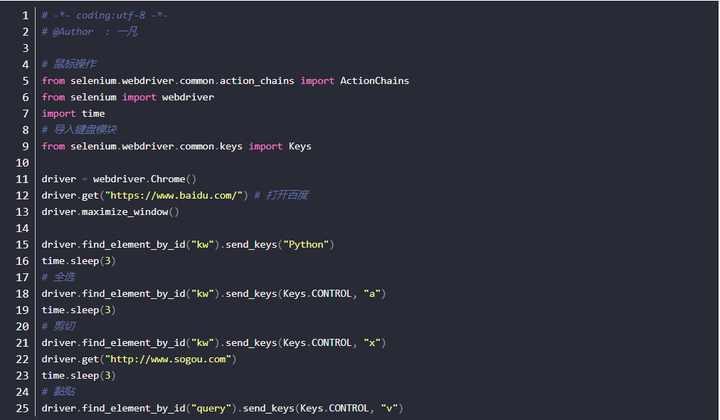
右击操作
操作思路:
- 对ActionChains类进行实例化对象操作
- 调用context_click(元素)方法
- 执行操作perform()方法
- 案例2: 对百度的搜索框进行右击操作
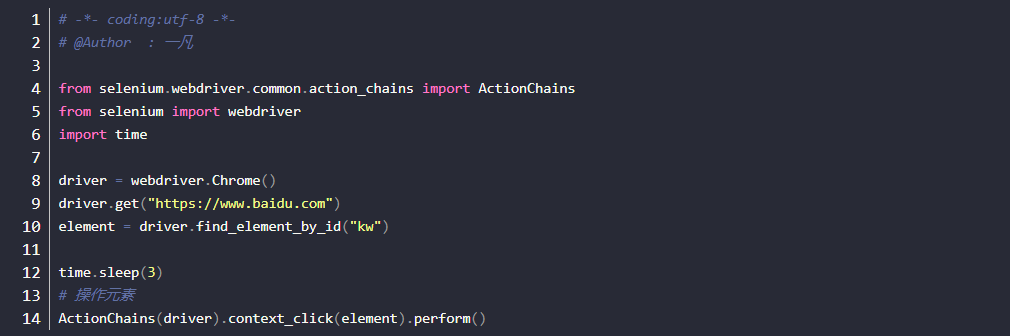
双击操作
操作思路:
- 对ActionChains类进行实例化对象操作
- 调用double_click(元素)方法
- 执行操作perform()方法
- 案例3: 对百度的搜索框输入:好好学习,双击鼠标选中文本
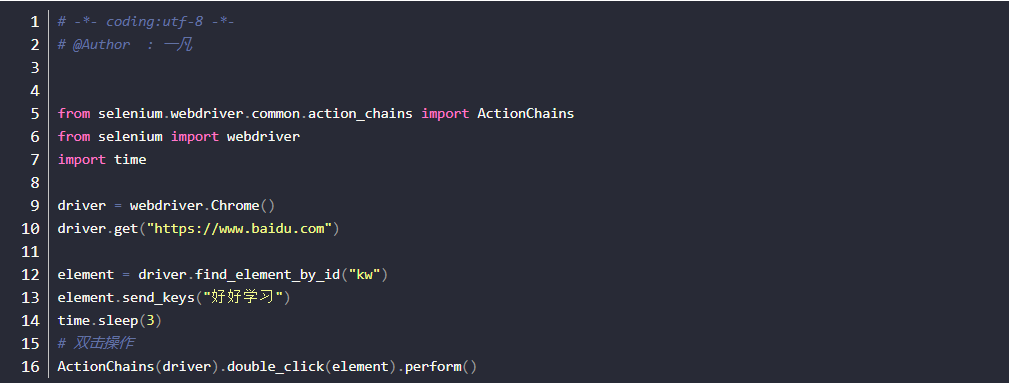
拖动操作
操作思路:
- 对ActionChains类进行实例化对象操作
- 调用drag_and_drop(元素1,元素2)方法
- 执行操作perform()方法
- http://127.0.0.1:5000/signin,点击练习鼠标拖拽,再将drag me元素分别拖动到item1,item2等元素位置
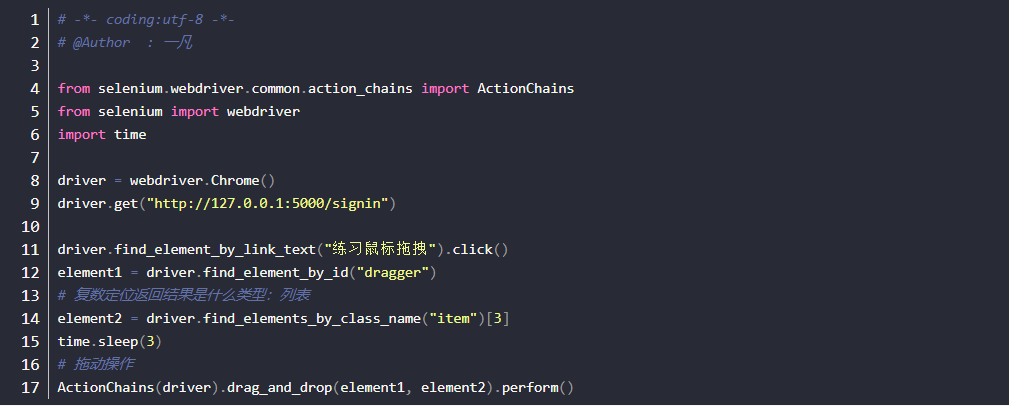
悬停操作
操作思路:
- 对ActionChains类进行实例化对象操作
- 调用move_to_element(元素)方法
- 执行操作perform()方法
-案例5: 进入百度,悬停到设置元素上
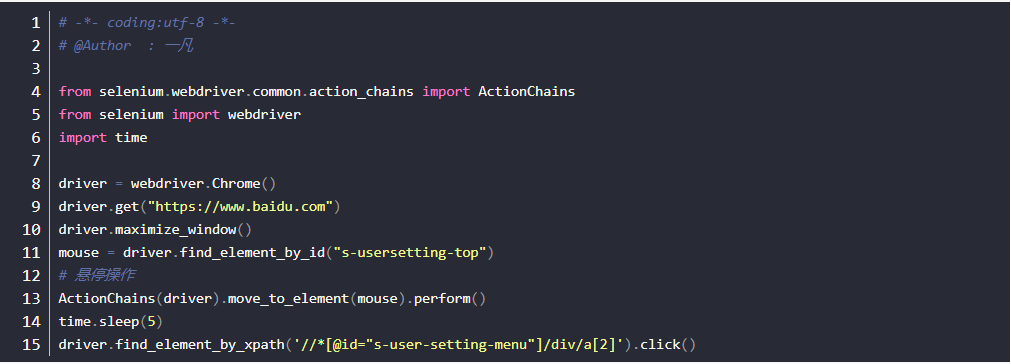
按下左键操作
操作思路:
- 对ActionChains类进行实例化对象操作
- 调用click_and_hold(元素)方法
- 执行操作perform方法
- 案例6: 进入百度,在贴吧元素上按着不松

鼠标其它操作

获取元素属性
- 我们要设计功能测试用例时,一般会有预期结果,有些预期结果测试人员无法通过肉眼进行判断的。
- 自动化测试运行过程是无人值守,一般情况下,脚本运行成功,没有异样信息就标识用户执行成功。
- 那怎么才能知道我打开这个网页,是不是我想要打开的这个网页呢?
-通常我们可以通过获得页面的 title 、URL 地址,页面上的标识性信息(如,登录成功的“欢迎,xxx”信息)来判断用例执行成功。
获取title

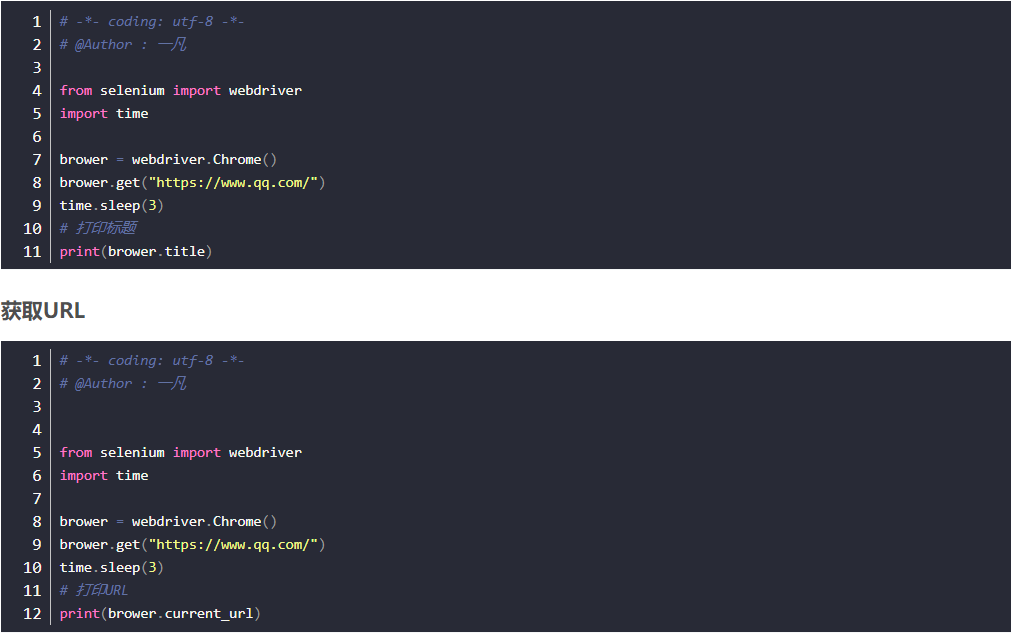
获取URL
获取元素标签
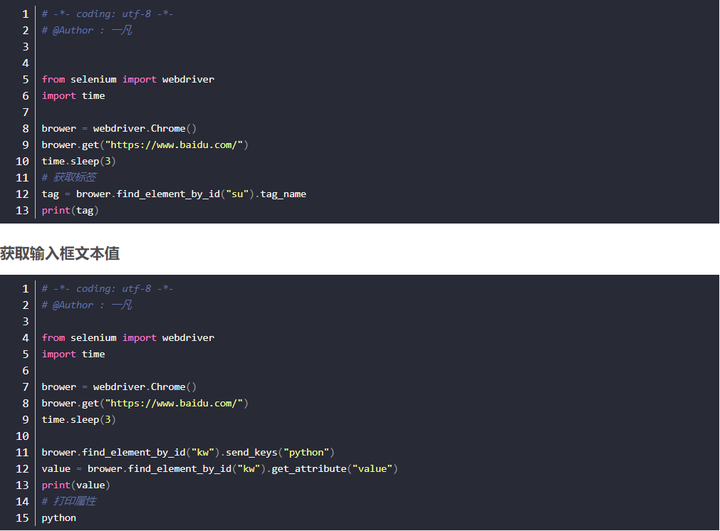
获取输入框文本值
获取元素其它属性
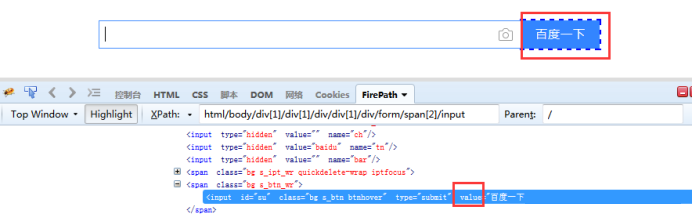
1.获取其它属性方法:get_attribute(“属性”),这里的参数可以是class、name,value等任意属性
2.如获取百度一下按钮的value属性
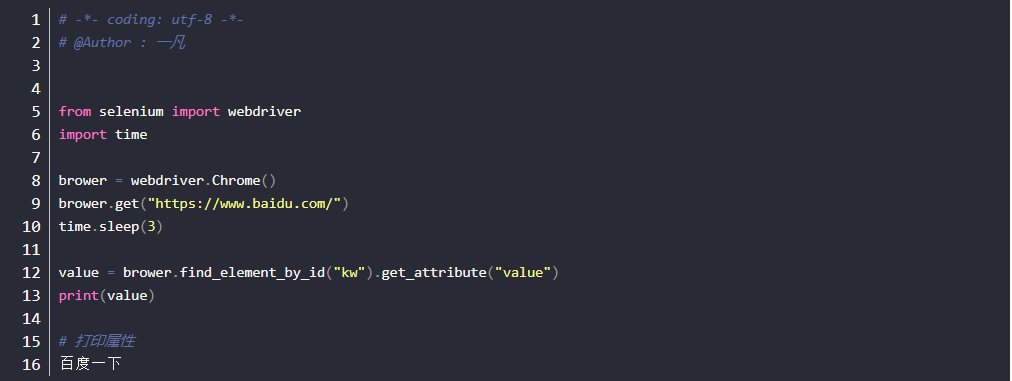
文本超链接text
如下图这种显示在页面上的文本信息,可以直接获取到
查看元素属性:

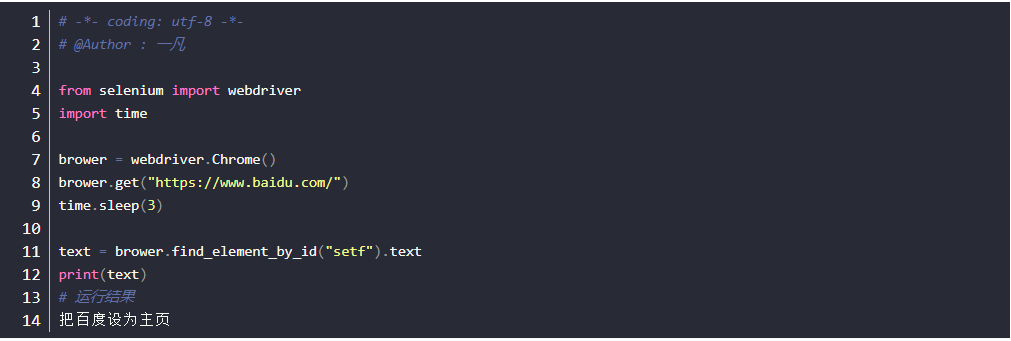
获取浏览器名字

判断是否存在
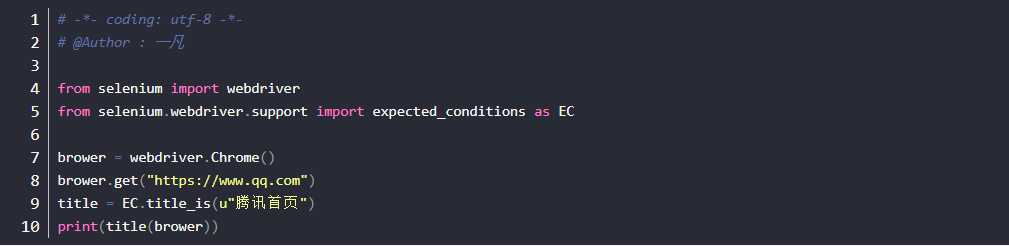
title(title_is)
- 获取页面title的方法可以直接用driver.title获取到,然后也可以把获取到的结果用做断言。
1.首先导入expected_conditions模块:from selenium.webdriver.support import expected_conditions
2.由于这个模块名称比较长,所以为了后续的调用方便,重新命名为EC了(有点像数据库里面多表查询时候重命名)
3.打开博客首页后判断title,返回结果是True或False
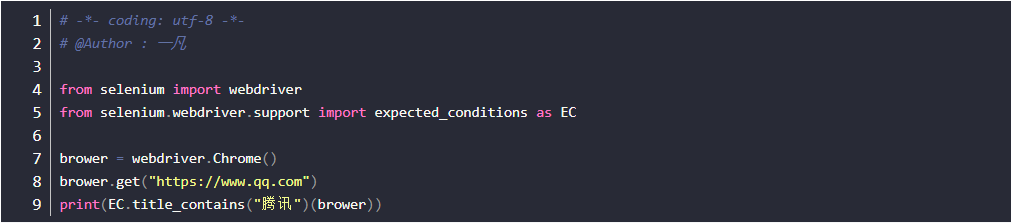
判断title包含:title(title_contains)
判断元素是否存在
- selenium是没有方法判断元素是否存的,所以需要自己写.元素不存在的话,操作元素会报错,或者元素有多个,不唯一的时候也会报错
find_elements方法判断
1.find_elements方法是查找页面上所有相同属性的方法,这个方法其实非常好用
2.由于元素定位的方法很多,所以判断的时候定位方法不统一也比较麻烦,我选择xpath定位
3.写一个函数判断,找到就返回Ture,没找到就返回False(或者不止一个)

判断元素文本
如果要判断按钮上的文本,就不能用上面那个方法
导入模块:
![]()
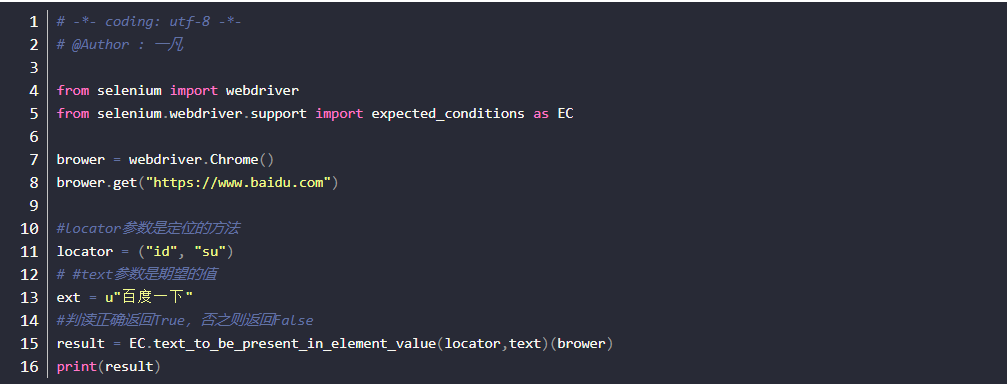
多窗口(句柄)
有些页面的链接打开后,会重新打开一个窗口,对于这种情况,想在新页面上操作,就得先切换窗口了。获取窗口的唯一标识用句柄表示,所以只需要切换句柄,我们就能在多个页面上灵活自如的操作了。
1.什么是多窗口
2.获取当前窗口句柄
- 元素有属性,浏览器的窗口其实也有属性的,只是你看不到,浏览器窗口的属性用句柄(handle)来识别。
- 人为操作的话,可以通过眼睛看,识别不同的窗口点击切换。但是脚本没长眼睛,它不知道你要操作哪个窗口,这时候只能句柄来判断了。
- 获取当前页面的句柄:driver.current_window_handle
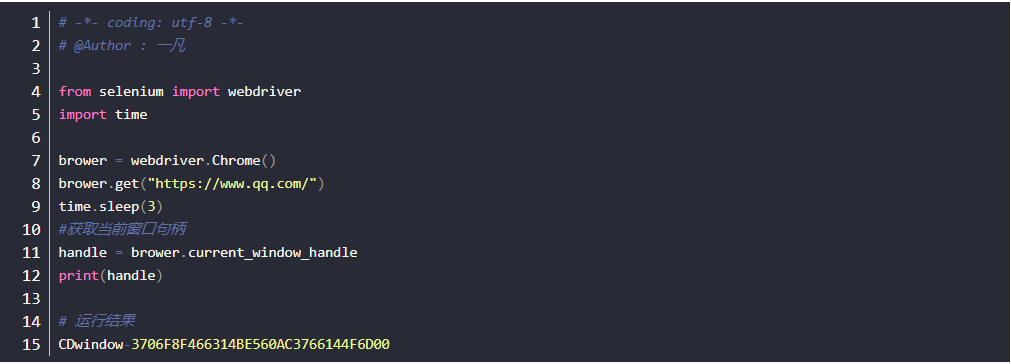
3.获取所有句柄
- 定位赶集网招聘求职按钮,并点击
- 点击后,获取当前所以的句柄:window_handles
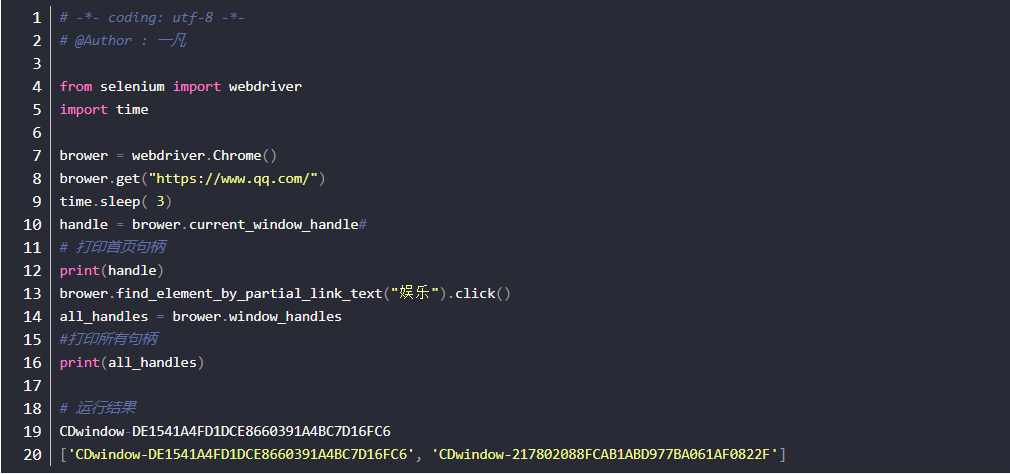
4.切换句柄
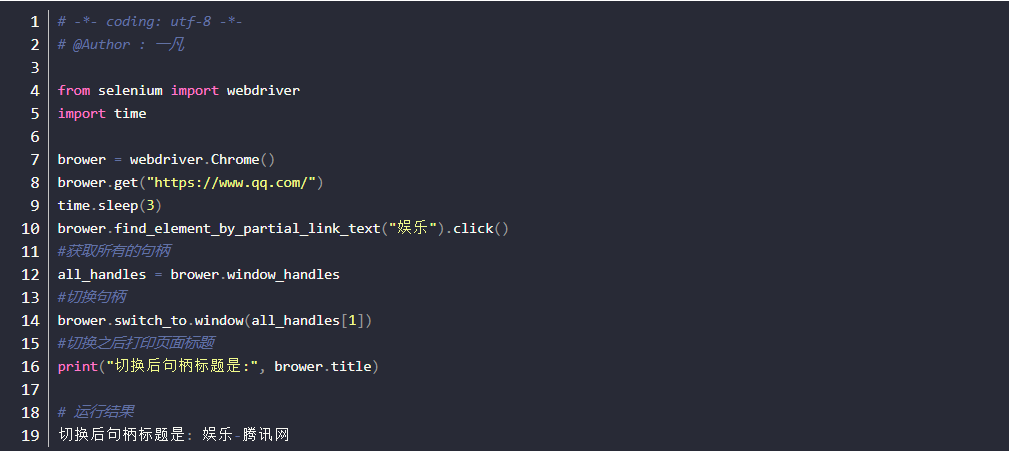
selenium三种等待方式详解
为什么要使用等待?
- 在自动化测试脚本的运行过程中,webdriver操作浏览器的时候,对于元素的定位是有一定的超时时间,大致在1-3秒
- 如果这个时间内仍然定位不到元素,就会抛出异常,中止脚本执行
- 我们可以通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败
常用的三种等待方式
- 强制等待
- 隐式等待
- 显示等待
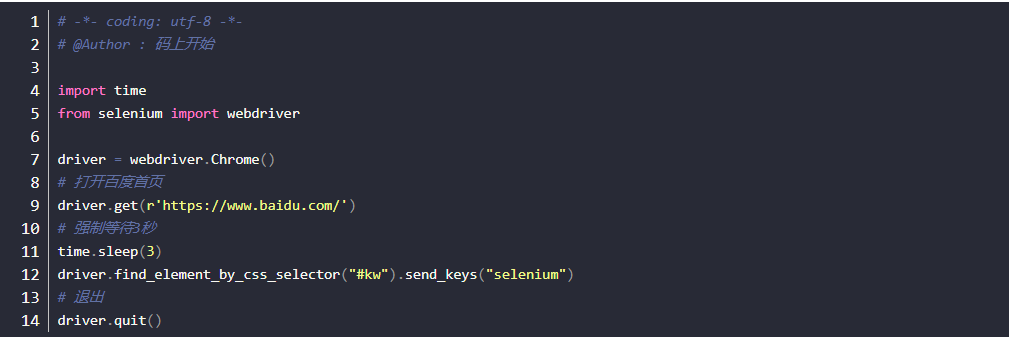
强制等待
- 利用time模块的sleep方法来实现,最简单粗暴的等待方法
- 强制等待,不管你浏览器是否加载完成,都得给我等待3秒,3秒一到,继续执行下面的代码,
弊端
- 不建议用这种等待方法,严重影响代码的执行速度
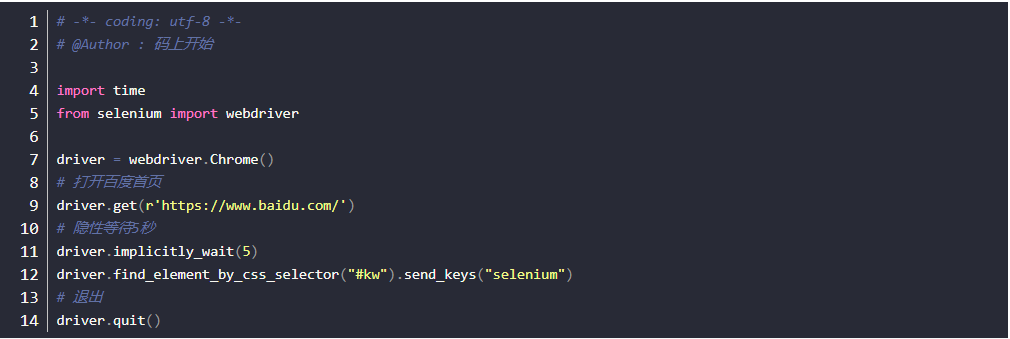
隐式等待
- implicitly_wait()方法用来等待页面加载完成(直观的就是浏览器tab页上的小圈圈转完)网页加载完成则执行下一步
- **隐式等待只需要声明一次,**一般在打开浏览器后进行声明
- 声明之后对整个drvier的生命周期都有效,后面不用重复声明
弊端
- 程序会一直等待整个页面加载完成,直到超时
- 有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页面全部加载完成才能执行下一步
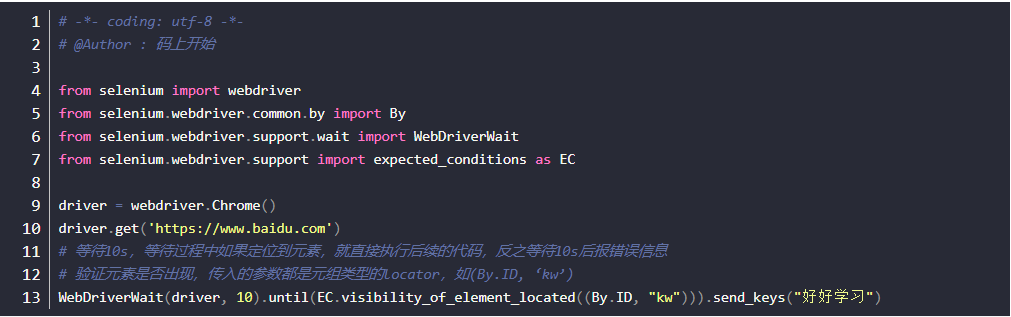
显示等待
- WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了
- 它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步
- 否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
- 显示等待必须在每个需要等待的元素前面进行声明

四个参数
- driver:浏览器驱动
- timeout:等待时间
- poll_frequency:检测的间隔时间,默认0.5s
- ignored_exceptions:超时后的异常信息,默认抛出NoSuchElementException
expected_conditions
- expected_conditions是selenium的一个模块
- 包含一系列可用于判断的条件
- 可以对网页上元素是否存在,可点击等等进行判断,一般用于断言或与WebDriverWait配合使用
![]()
模块用法汇总
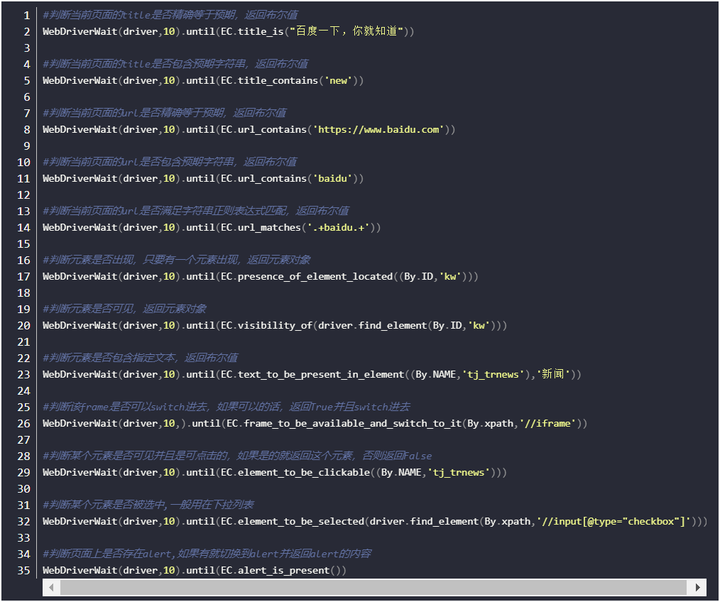
无头模式
- 在使用seleinum的时候经常会打开浏览器,如果电脑配置不在了的时候,会出现卡,有没有一种方式不弹出浏览器又把想要的操作执行完呢??
- 这时候firefox和chrome就有了无头模式,也就是没有界面的浏览器,在内存中执行。
Firefox

Chrome

logging模块
- 你可以控制消息的级别,过滤掉那些并不重要的消息。
- 你可决定输出到什么地方,以及怎么输出。有许多的重要性别级可供选择,debug、info、warning、error 以及 critical
- 通过赋予 logger 或者 handler 不同的级别,你就可以只输出错误消息到特定的记录文件中,或者在调试时只记录调试信息。
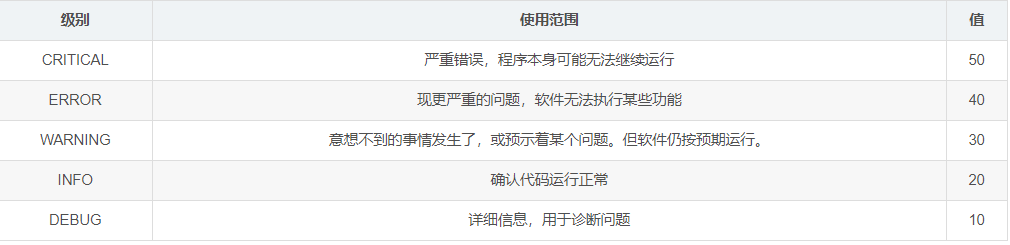
日志级别
- 级别从高到低

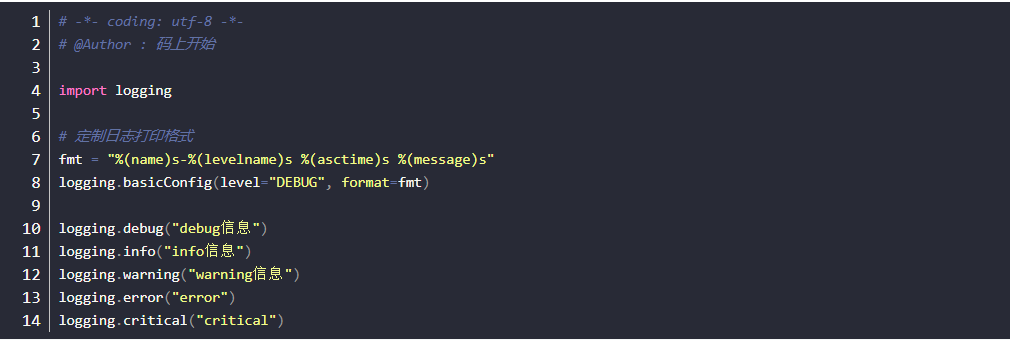
运行结果
- 默认打印WARNING及以上的日志信息
- level=“DEBUG” 设置级别名必须都是大写
- 如果我想打印日志的时间、在哪一行等格式?可以实现吗??

实现日志格式
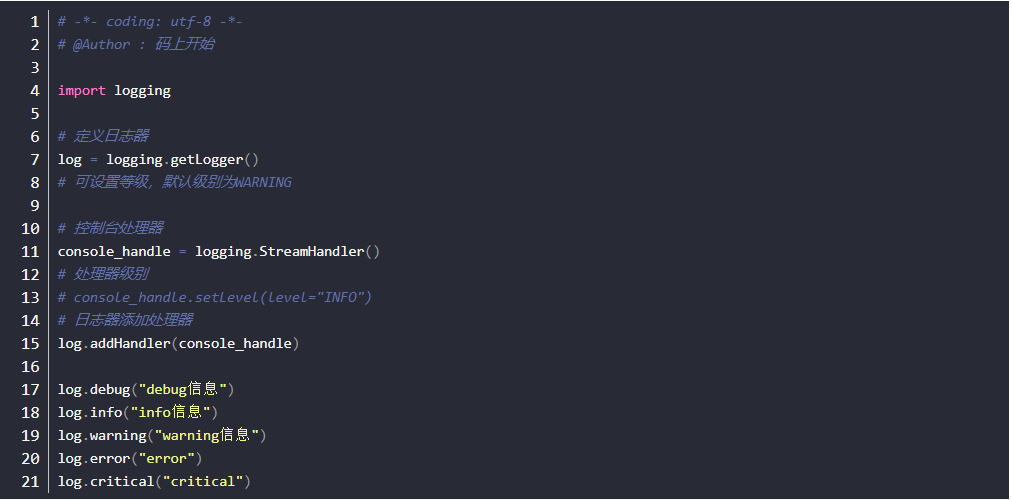
- 使用basicConfig中的参数format
运行结果
- 默认名字显示的root(可否显示一个自定义名字?继续往下看)

日志流程
第1步:创建日志器
- 提供程序使用的接口,可以理解就创建一个logging实例化类
- 默认日志级别为:WARNING

第2步:创建处理器
- 由处理器来处理日成生的位置(控制台或文件或两者同时存在)
- 重点:日志器添加处理器
控制台处理器
运行结果
- 如果日志器级别 >处理器级别则显示日志器级别,反之显示处理器级别
- 默认级别为WARING,所以只打印这三条日志

文件处理器
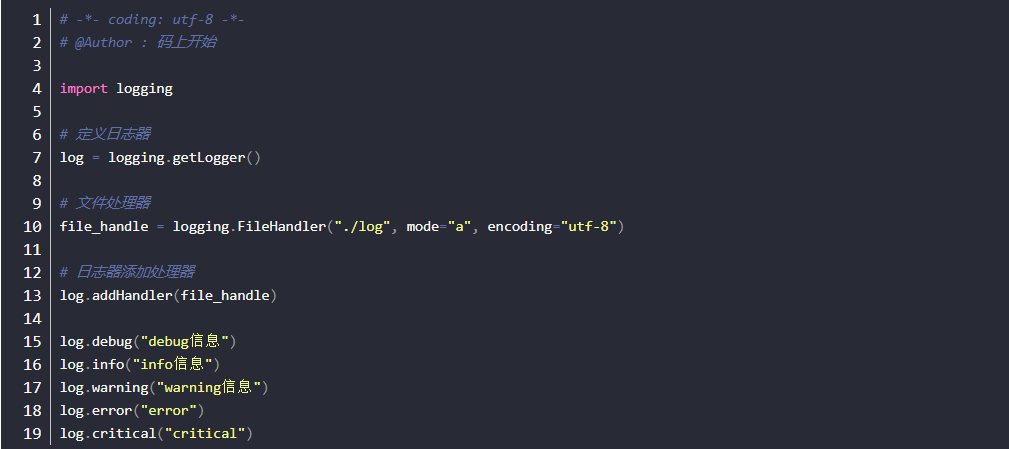
第3步:格式器
- 决定日志生成的最终输出格式
- 重点:处理器添加格式器
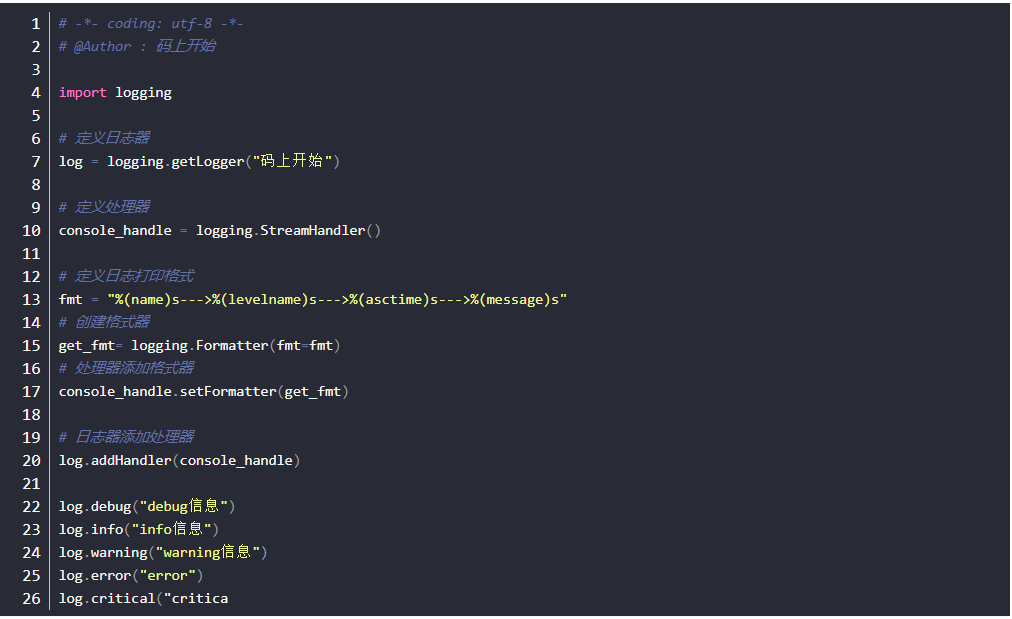
运行结果:

日志同时生成在控制台和文本
- 重点就是创建1个控制台/文本处理器
- 小伙伴可能会发现,我们的代码没有进行封装,那最后一步,我们封装日志模块
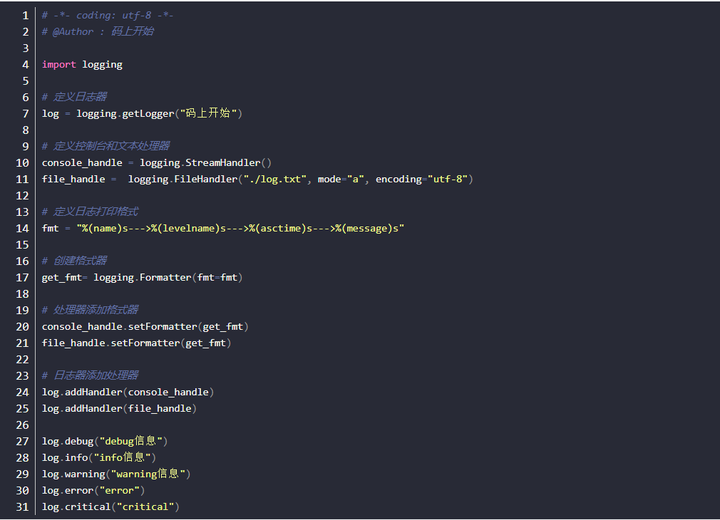
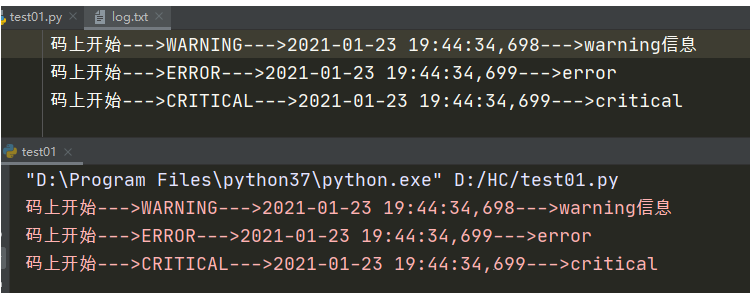
封装日志模块
- 第1步:创建日志器

- 第2步:创建处理器
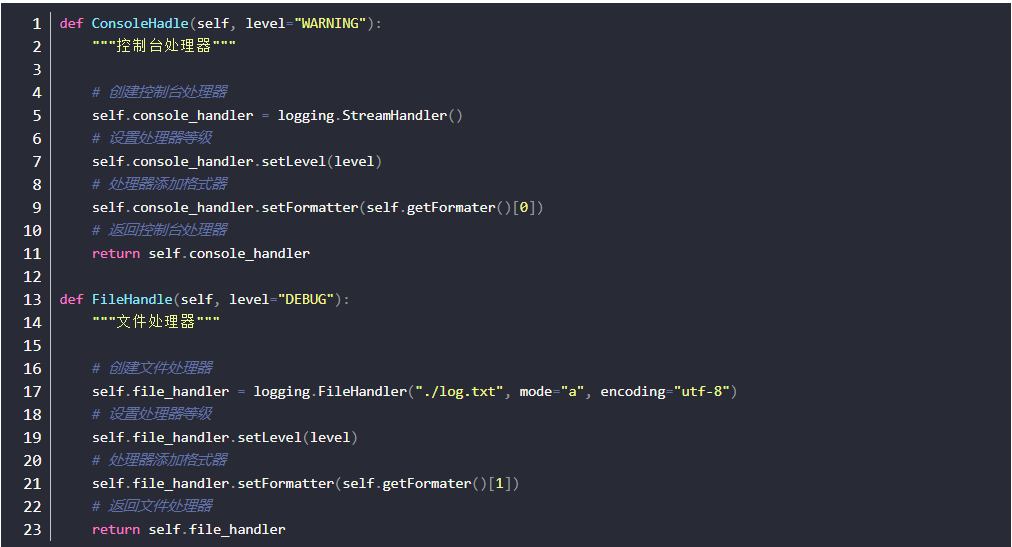
- 第3步:创建格式器

- 第4步:日志器添加格式器

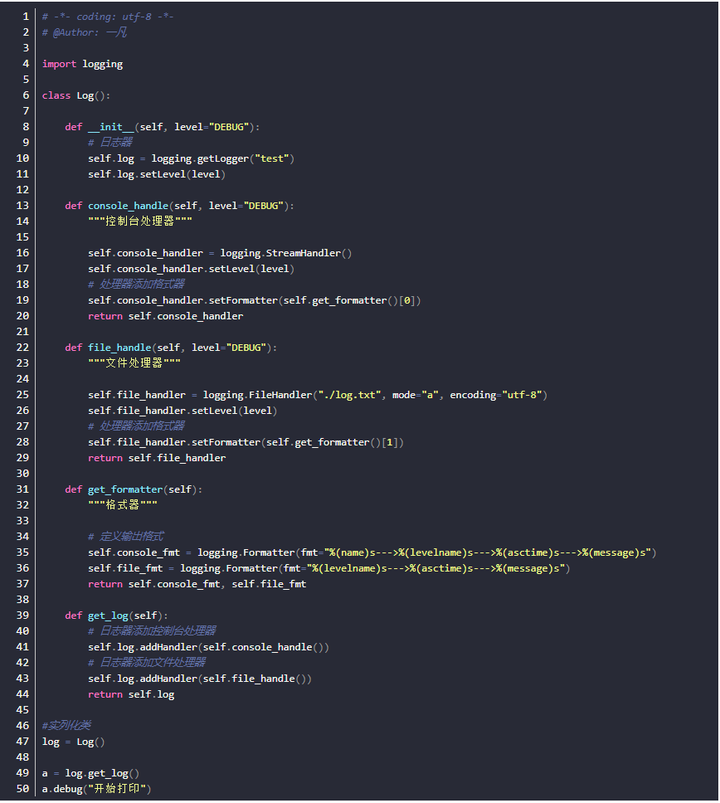
完整代码
POM模型
Page Object Model (POM) 直译为“页面对象模型”,这种设计模式旨在为每个待测试的页面创建一个页面对象(class),将那些繁琐的定位操作封装到这个页面对象中,只对外提供必要的操作接口,是一种封装思想。
POM优势有哪些
- 让UI自动化更早介入项目中,可项目开发完再进行元素定位的适配与调试
- POM 将页面元素定位和业务操作流程分开,分离了测试对象和测试脚本
- 如果UI页面元素更改,测试脚本不需要更改,只需要更改页面对象中的某些代码就可以
- POM能让我们的测试代码变得可读性更好,高可维护性,高复用性
- 可多人共同维护开发脚本,利于团队协作
为什么使用POM设计模式
- 少数的自动化测试用例维护起来看起来是很容易的。但随着时间的迁移,测试套件将持续的增长。脚本也将变得越来越臃肿庞大。
- 如果变成我们需要维护10个页面,100个页面,甚至1000个呢?而且页面元素很多是公用的。那页面元素的任何改变都会让我们的脚本维护变得繁琐复杂,而且变得耗时易出错。
思路解析
- 需要一个文件用于管理页面元素,如login_page.py
- 封装一个公用的操作方法
- 最后需要一个文件用于编写测试用例
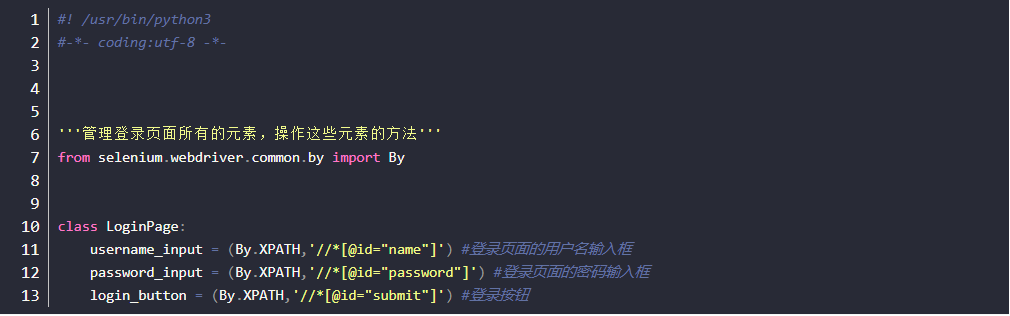
login_page.py文件
- 该文件用于管理登录页面所有的元素,操作这些元素的方法
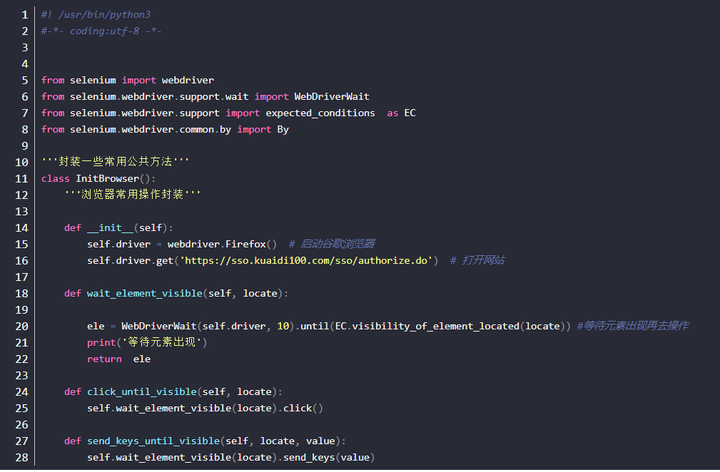
common.py
- 该文件有用于封装一些共用的操作方法
TestCase.py
- 该文件用于管理测试用例
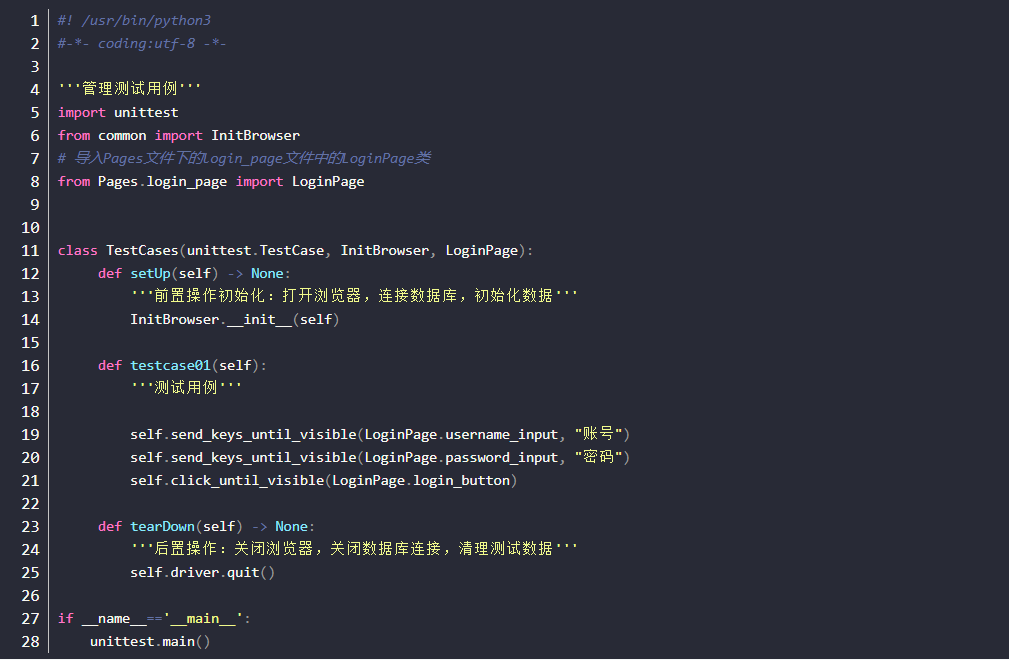
unittest介绍
- unittest是Python自带的测试框架,可用于单元测试
- unittest测试框架可组织执行测试用例
- unittest提供丰富的断言方法
unittest语法
- 用import unittest导入unittest模块
- 继承unittest.TestCase类,如class xxx(unittest.TestCase)
- 每个测试用例执行前先执行setUp或setUpClass方法,执行完毕后执行tearDown或tearDownClass方法
- 用例必须名以test开头,否则unittest不能识别
- 调用unittest.main(),执行测试用例
unittest四大组件
test case
- 测试用例,方法命名基于test开头,测试用例自行排序执行顺序规则A-Z, a-z, 0-9
- 如用例test01/test02
- add的用例不是用test开始就不会被识别,所以不会运行
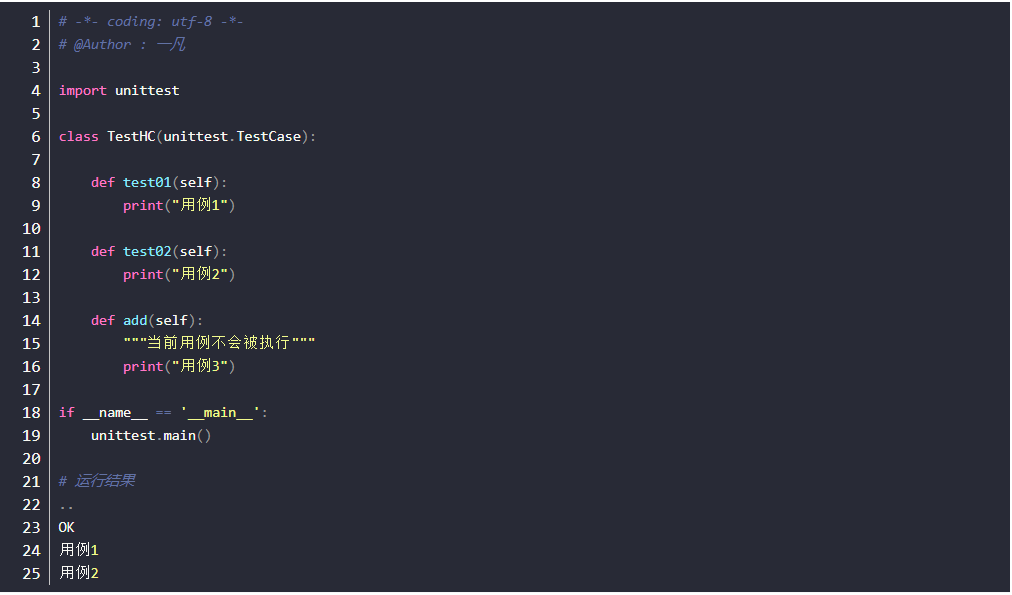
- 成功是 .失败是 F,出错是 E
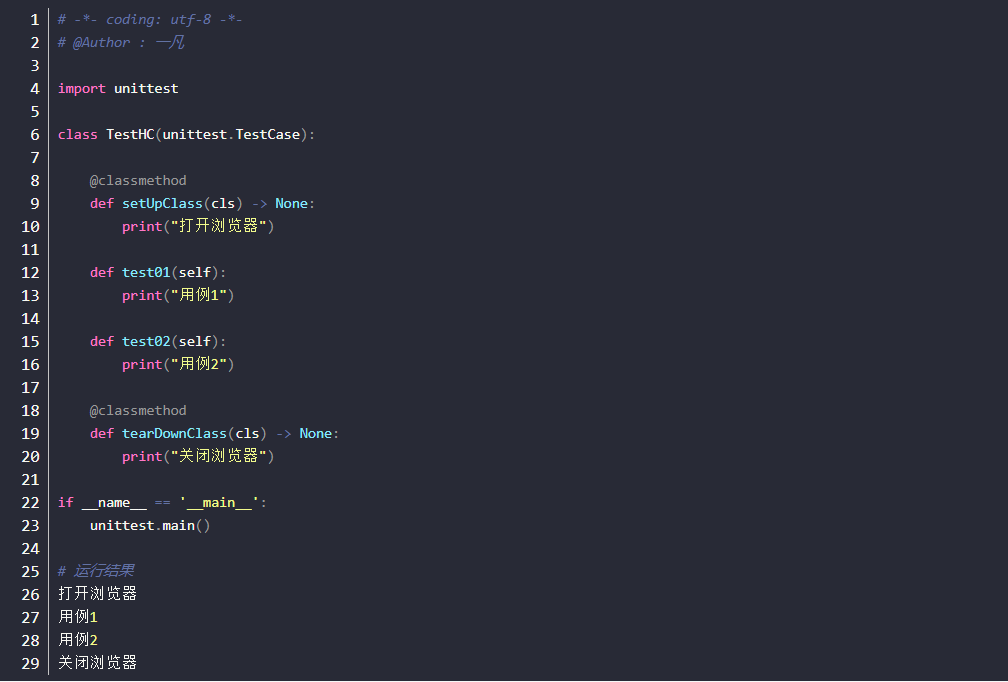
test fixture
- 设置前置条件(setUp),后置条件(tearDown),每个测试用例方法执行前后都要执行前后置条件
- 用例前后都执行了setUp和tearDown,且运行了两次了?能否只打开一次浏览器和关闭浏览器一次

- 设置前置条件(setUpClass),后置条件(tearDownClass),所有用例只会执行一次setUpClass和tearDownClass
- 方法前必须加装饰器: @classmethod
- 打开浏览器和关闭浏览器只运行了一次
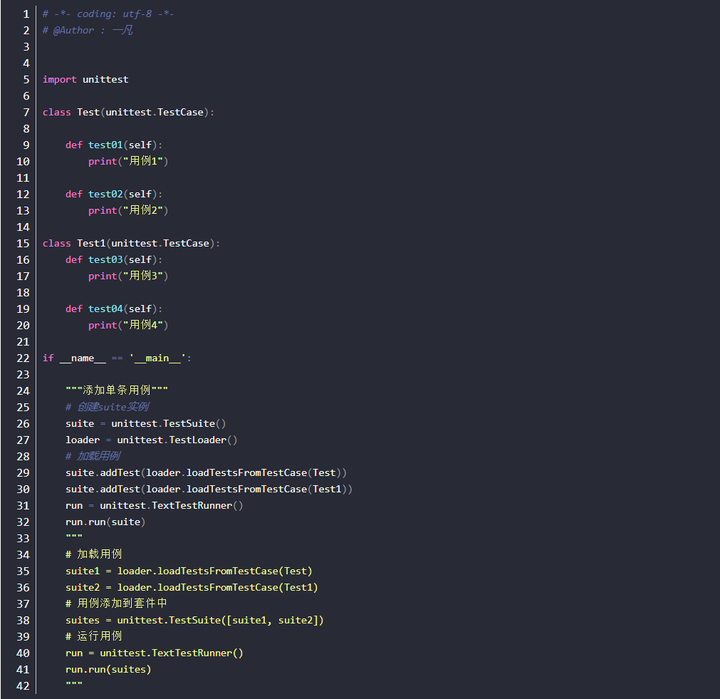
test suite
- 先通过unittest.TestSuite() 创建测试套件实例对象,如:suite = unittest.TestSuite()
- 再通过addTest() 方法添加单个测试用例,或通过addTests([…]) 添加多个测试用例(列表中为用例方法名)
- 执行测试套件里的测试用例
方式一:加载测试用例

方式二:加载测试用例类
- 先通过unittest.TestSuite() 创建测试套件实例对象。
- 再通过unittest.TestLoader()创建加载对象,加载测试用例类
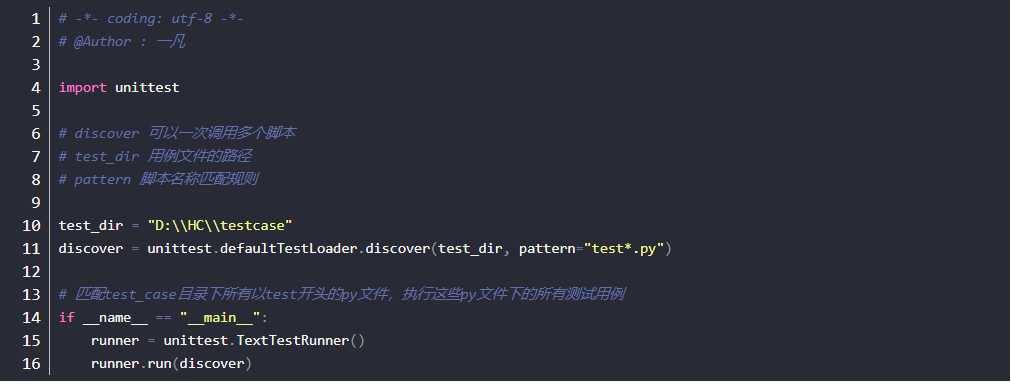
方法三:加载指定路径里的测试用例
- 通过unittest.defaultTestLoader.discover()将指定路径的测试用例加载至测试用例集
- 注意:这里不需要创建unittest.TestSuite对象
- test_dir为指定路径, pattern=test_*.py 表示加载以test_开头的模块中的测试用例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wI6KlwyE-1634193811891)(C:\Users\zhichao\AppData\Roaming\Typora\typora-user-images\image-20210228152457445.png)]
test runner
unittest框架执行测试用例之前,需先创建TextTestRunner实例,
再调用该实例的run()方法执行用例

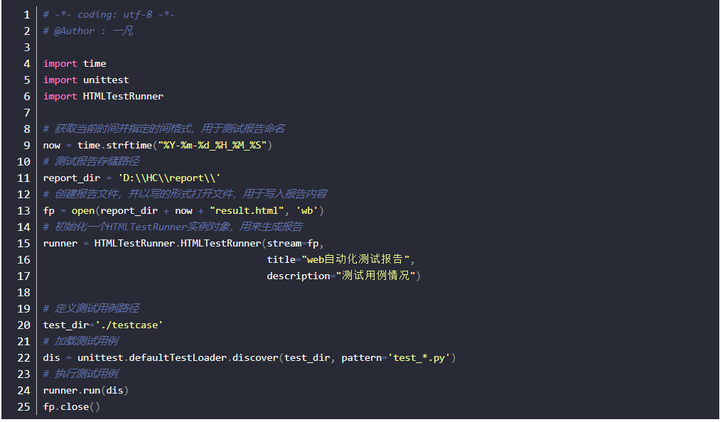
unittest生成测试报告
- unittest框架执行测试用例完成后会在控制台输出如上的结果
- 实际测试过程中,我们需要输出测试报告,这个时候我们需要使用第三方模块
下载HTMLTestRunner
- 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
文件修改
- 94行引入的名称要改,从 import StringIO修改成 import io
- 539行self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer=io.StringIO()
- 631行 print >>sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime)修改成print (sys.stderr, - ‘\nTime Elapsed: %s’ %(self.stopTime-self.startTime))
- 642行,if not rmap.has_key(cls): 修改成 if not cls in rmap:
- 766行的uo = o.decode(‘latin-1’),修改成 uo=o
- 772行,把 ue = e.decode(‘latin-1’) 直接改成 ue = e
存放路径
- 将修改完成的模块存放在Python路径下Lib目录里即可
- D:\Program Files\python37\Lib
实例
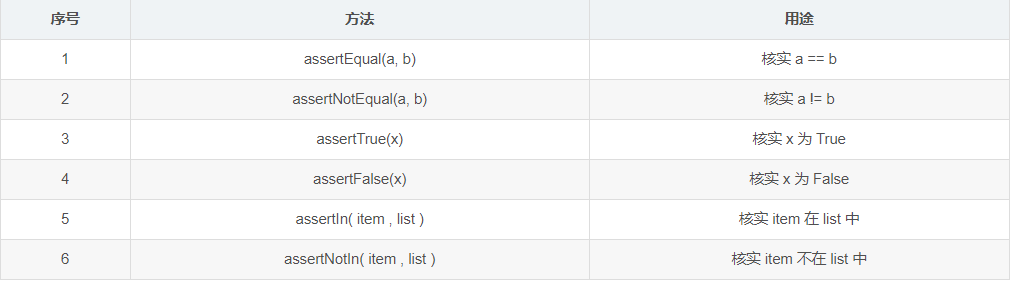
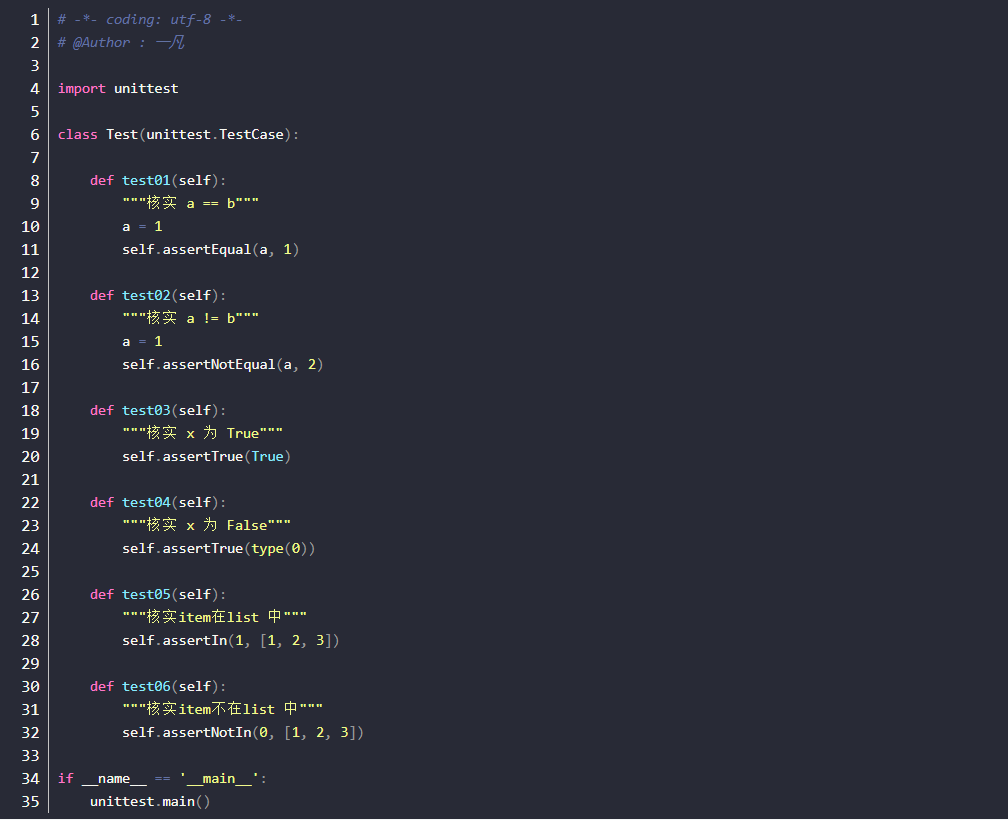
unittest断言
- 断言即测试用例执行结果和预期做对比,符合就即测试用例通过,反之不通过
- 只能在继承 unittest.TestCase 的类中使用这些方法
- 常见的几个断言方法(更多断言方法请自行查询)
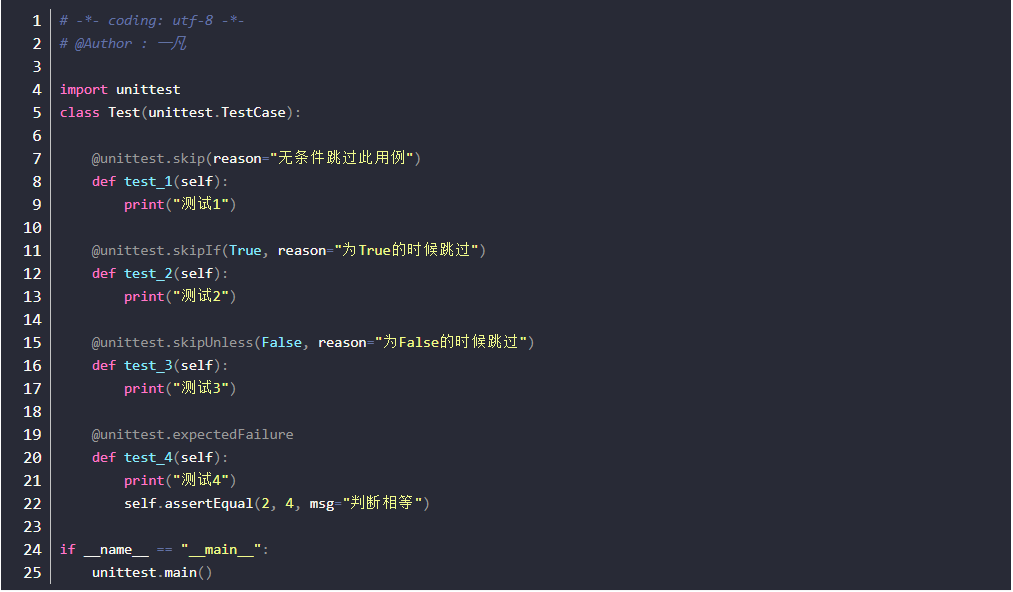
跳过用例的执行(skip)
- unittest提供了一些跳过指定用例的方法
- @unittest.skip(reason):强制跳转, reason是跳转原因
- @unittest.skipIf(condition, reason):condition为True的时候跳转
- @unittest.skipUnless(condition, reason):condition为False的时候跳转
- @unittest.expectedFailure:如果test失败了,这个test不计入失败的case数目
总结
当我们再次使用登录时,只需要修改login_page.py里的定位元素方法和值就可以了
以上代码当然还有很多不足的地方,比如账号密码没有提出来,小伙伴可自行尝试
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!