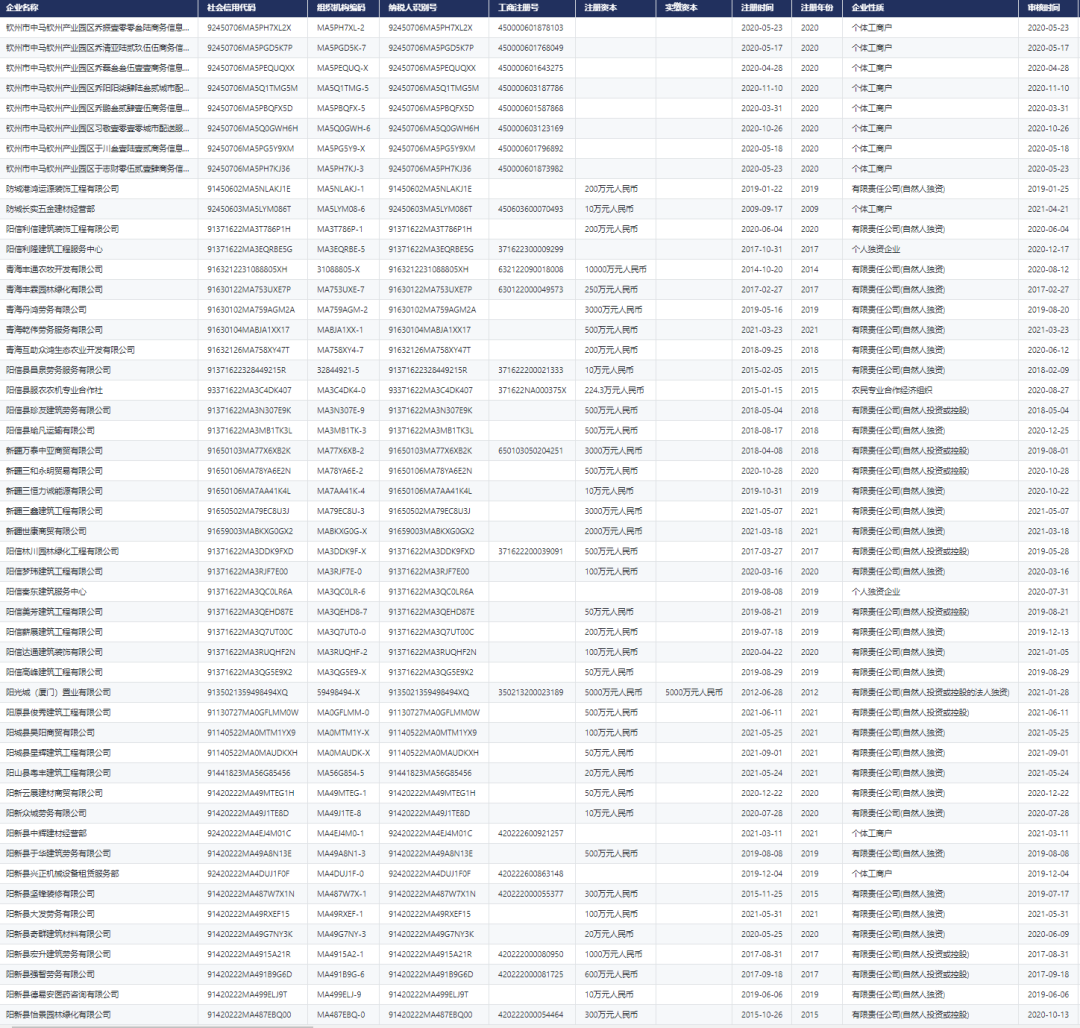
基于蜣螂算法改进的随机森林分类算法 - 附代码
文章目录
- 基于蜣螂算法改进的随机森林分类算法 - 附代码
- 1.数据集
- 2.RF模型
- 3.基于蜣螂算法优化的RF
- 4.测试结果
- 5.Matlab代码
摘要:为了提高随机森林数据的分类预测准确率,对随机森林中的树木个数和最小叶子点数参数利用蜣螂搜索算法进行优化。
1.数据集
数据的来源是 UCI 数据库中的肿瘤数据。数据信息如下:
data.mat 的大小为569*32。
其中第2列为标签数据,包含两类标签。
第3列到最后一列为特征数据。
所以RF模型的数据输入维度为30;输出维度为1。
2.RF模型
随机森林请自行参考相关机器学习书籍。
3.基于蜣螂算法优化的RF
蜣螂搜索算法的具体原理参考博客:https://blog.csdn.net/u011835903/article/details/128280084。
蜣螂算法的优化参数为RF中树木个数和最小叶子节点数。适应度函数为RF对训练集和测试集的预测错误率,错误率越低越好。
f
i
n
t
e
n
e
s
s
=
e
r
r
o
r
R
a
t
e
[
p
r
e
d
i
c
t
(
t
r
a
i
n
)
]
+
e
r
r
o
r
R
a
t
e
[
p
r
e
d
i
c
t
(
t
e
s
t
)
]
finteness = errorRate[predict(train)] + errorRate[predict(test)]
finteness=errorRate[predict(train)]+errorRate[predict(test)]
4.测试结果
数据划分信息如下: 训练集数量为500组,测试集数量为69组
蜣螂参数设置如下:
%% 定义蜣螂优化参数
pop=20; %种群数量
Max_iteration=30; % 设定最大迭代次数
dim = 2;%维度,即树个数和最小叶子点数
lb = [1,1];%下边界
ub = [50,20];%上边界
fobj = @(x) fun(x,P_train,T_train,P_test,T_test);



寻优得到的树个数:17
最小叶子节点:1
蜣螂优化随机森林结果展示:----------------
训练集正确率Accuracy = 99.6%(498/500)
测试集正确率Accuracy = 95.6522%(66/69)
病例总数:569 良性:357 恶性:212
训练集病例总数:500 良性:316 恶性:184
测试集病例总数:69 良性:41 恶性:28
良性乳腺肿瘤确诊:40 误诊:1 确诊率p1=97.561%
恶性乳腺肿瘤确诊:26 误诊:2 确诊率p2=92.8571%
传统随机森林结果展示:----------------
训练集正确率Accuracy = 100%(500/500)
测试集正确率Accuracy = 94.2029%(65/69)
病例总数:569 良性:357 恶性:212
训练集病例总数:500 良性:316 恶性:184
测试集病例总数:69 良性:41 恶性:28
良性乳腺肿瘤确诊:40 误诊:1 确诊率p1=97.561%
恶性乳腺肿瘤确诊:25 误诊:3 确诊率p2=89.2857%
从结果来看,经过改进后的蜣螂-RF明显优于未改进前的结果。











![[oeasy]python0066_控制序列_光标位置设置_ESC_逃逸字符_CSI](https://img-blog.csdnimg.cn/img_convert/6115b00c1d0ec500a9d4ca2911d2562e.jpeg)