Hadoop 复习 ---- chapter01【大数据概念】
- 1. 什么是大数据
- 大数据的简介
- 从IT过渡到DT
- 2. Hadoop生态系统工具
- HADOOP
- HBASE
- HIVE
- STORM
- ZooKeeper
- Sqoop
- MAHOUT
1. 什么是大数据
大数据的简介
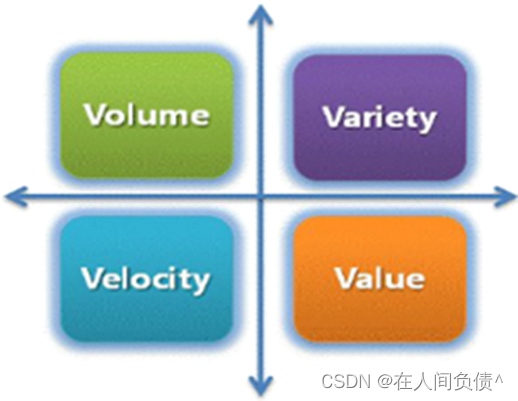
指“无法由现有软件工具进行提取、存储、搜索、共享、分析和处理的庞大而复杂的数据集”。
通常由四个 V 来描述(大量数据、多样化、价值密度低、速度快)。
- 大量数据(valume):从 TB 级别,跃升到 PB 级别
- 多样化(variety):网络日志、视频、图片、地理位置
- 价值密度低(value):价值密度与数据总量成反比。
- 速度快(velocity):大数据区分为传统数据挖掘的显著特征–一秒定律。
从IT过渡到DT
- IT时代:信息处理技术以自我控制和自我管理为主导。
- DT时代:DT(数据技术)时代是一种数据处理技术,它是一种服务于公众并刺激生产力的技术。
2. Hadoop生态系统工具
HADOOP

- Hadoop 是由 Apache Foundation 开发的分布式系统基础结构。
- MapReduce 框架可以将应用程序分解为许多并行计算命令,从而在大量计算节点上运行非常大的数据集,使用“分而治之”的思想,Map 用于分隔大数据,Reduce 用于合并 Map 计算的结果。
- HDFS:分布式文件系统为海量数据和大文件提供存储服务,将大文件(大于 64M/128M)拆分为块(每块 64M或者128M),多节点存放。
HBASE

- HBASE 是 apache 的开源 KV(Key-Value)数据库。它基于 HDFS,为数据库系统提供了可靠性、高性能、列存储、可伸缩性和实时读写功能。
- 它只能通过行键和行键范围来搜索数据。它支持单行事务。主要用于存储非结构化和半结构化的松散数据。
HBASE 的特征:
- 大:一个表可以有上亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
HIVE

- Apache Hive 数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在 Apache Hadoop 之上。
- 可以对数据进行提取、转化、加载。
- HIVE 可以存储、查询、分析存储在 HDFS(或者HBase)中的大规模数据。
- 通过将 SQL 转化为 MapReduce 作业在 Hadoop 上运行。
- Hive 定义了一种类似 SQL 的查询语言,称为 HQL。
Hive 的缺点:
- Hive 目前不支持事务
- 不能对表数据进行修改(不能更新、删除、插入;只能通过文件追加数据、重新导入数据)
- 查询速度比较慢
STORM

- Apache Storm 是一个免费和开源的分布式实时计算系统,它简化了流数据的可靠处理。
- Storm 具有许多应用场景,包括实时数据分析,在线学习,连续计算,分布式 RPC、ETL 等。
- Storm 速度非常快,并且测试在单个节点上每秒执行一百万个组处理。
ZooKeeper

- ZooKeeper 是一种高性能、分布式、开源的分布式应用程序协调服务。它是 Storm 和 HBase 的重要组成部分。
- ZooKeeper 是一个领导者,负责编写服务于数据同步。
特征:
- 顺序一致性
- 原子性
- 均匀度
- 可靠性
- 及时性
使用场景:
- 数据发布与订阅
- 名称空间服务
- 分布式通知、协调
- 集群管理
Sqoop

- Sqoop 是 Apache 的顶级项目,它允许用户将关系数据库中的数据提取到 Hadoop 中进行进一步处理,获得分析结果后,Sqoop 还可以将分析结果导回数据库,以供其它客户端使用。
MAHOUT

- Mahout 是功能强大的数据挖掘工具和一组分布式机器学习算法,包括分布式协调过滤的实现,分类和聚类。