课程地址:【北京大学】Tensorflow2.0_哔哩哔哩_bilibili
Python3.7和TensorFlow2.1
六讲:
神经网络计算:神经网络的计算过程,搭建第一个神经网络模型
神经网络优化:神经网络的优化方法,掌握学习率、激活函数、损失函数和正则化的使用,用Python语言写出SGD、Momentum、Adagrad、RMSProp、Adam五种反向传播优化器
神经网络八股:神经网络搭建八股,六步法写出手写数字识别训练模型
网络八股扩展:神经网络八股扩展,增加自制数据集、数据增强、断点续训、参数提取和acc/loss可视化,实现给图识物的应用程序
卷积神经网络:用基础CNN、LeNet、AlexNet、VGGNet、InceptionNet和ResNet实现图像识别
循环神经网络:用基础RNN、LSTM、GRU实现股票预测
回顾:卷积神经网络(借助卷积核提取空间特征后,送入全连接网络)

卷积就是特征提取器,就是CBAPD。这种特征提取是借助卷积核实现的参数空间共享,通过卷积计算层提取空间信息,比如:可以用卷积核提取一张图片的空间特征,再把提取到的空间特征送入全连接网络,实现离散数据的分类
然而,有些数据是与时间序列相关的,是可以根据上文预测出下文的(通过脑记忆体提取历史数据的特征,预测出接下来最可能发生的情况,其中脑记忆体就是循环核)

本讲:用循环神经网络(RNN/LSTM/GRU)实现连续数据的预测(以股票预测为例)
循环神经网络(Recurrent Neural Network,RNN)
(一)循环核
循环核具有记忆力,通过不同时刻的参数共享,实现了对时间序列的信息提取
每个循环核有多个记忆体,记忆体下面、侧面、上面分别有三组待训练的参数矩阵

RNN循环核,图中的多个小圆柱即记忆体
记忆体内存储着每个时刻的状态信息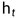


(二)循环核按时间步展开
就是把循环核按照时间轴方向展开,如图:

循环神经网络就是借助循环核实现时间特征提取后,把提取到的信息送入全连接网络,从而实现连续数据的预测
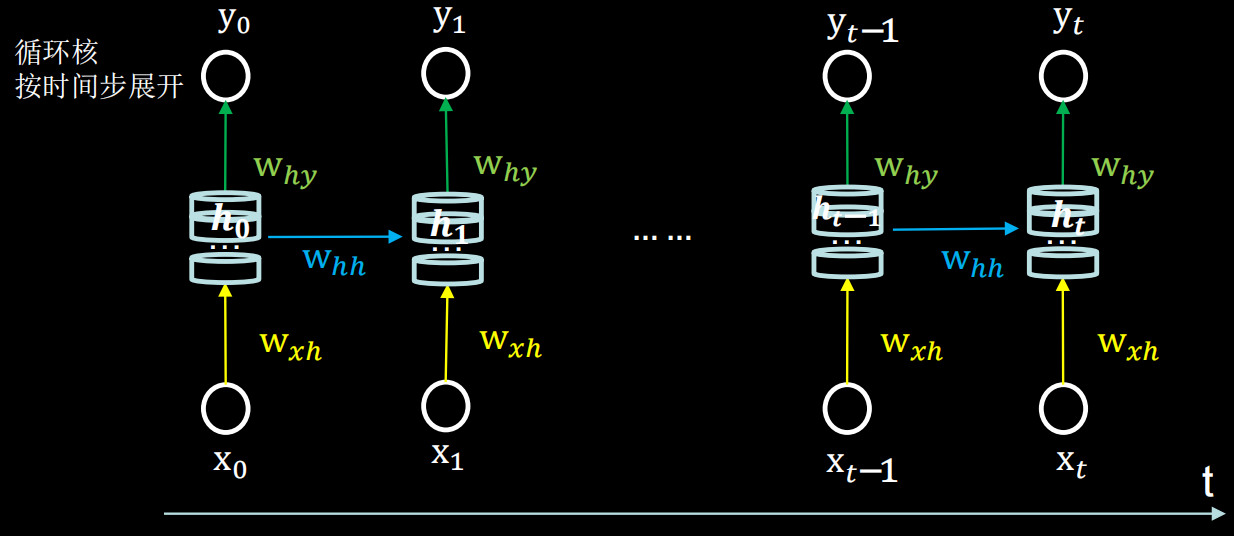
(三)循环计算层:向输出方向增长
每个循环核构成一层循环计算层,循环计算层的层数是向输出方向增长的
每个循环核中记忆体的个数可以根据需求任意指定
(四)TF2描述循环计算层
tf.keras.layers.SimpleRNN(
循环核中记忆体的个数/神经元个数,
activation=‘激活函数’, # 使用什么激活函数计算ht。若不写,默认用tanh
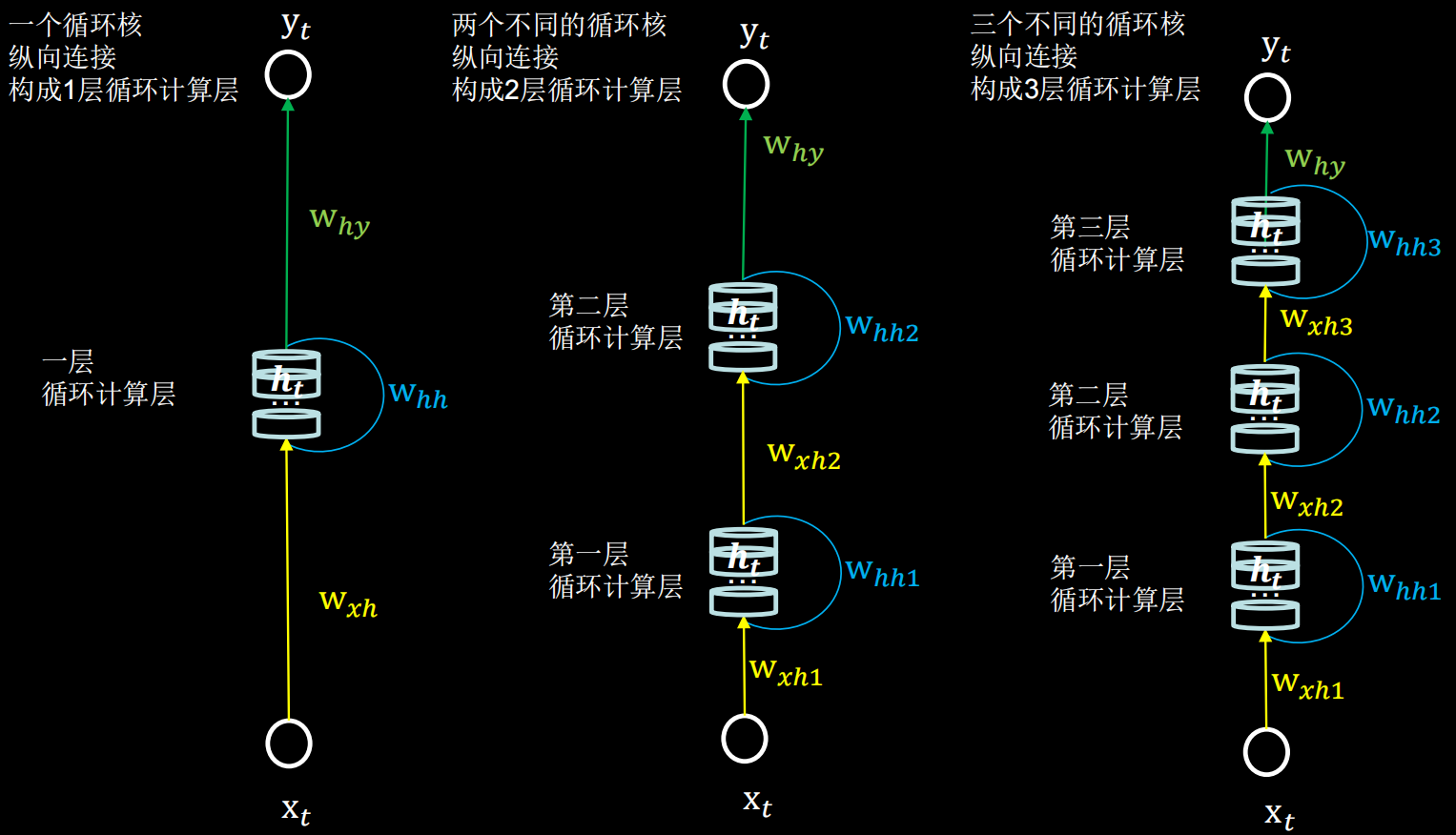
return_sequences=是否每个时刻输出ht到下一层 # True/False,默认False
)参数return_sequences
在输出序列中,返回最后时间步的输出值(False)还是全部时间步的输出(True)
当下一层依然是RNN层,通常为True;反之如果后面是Dense层,通常为False。即:最后一层的循环核用False,仅在最后一个时间步输出;中间层的循环核用True,每个时间步都把输出给下一层
各时间步输出ht
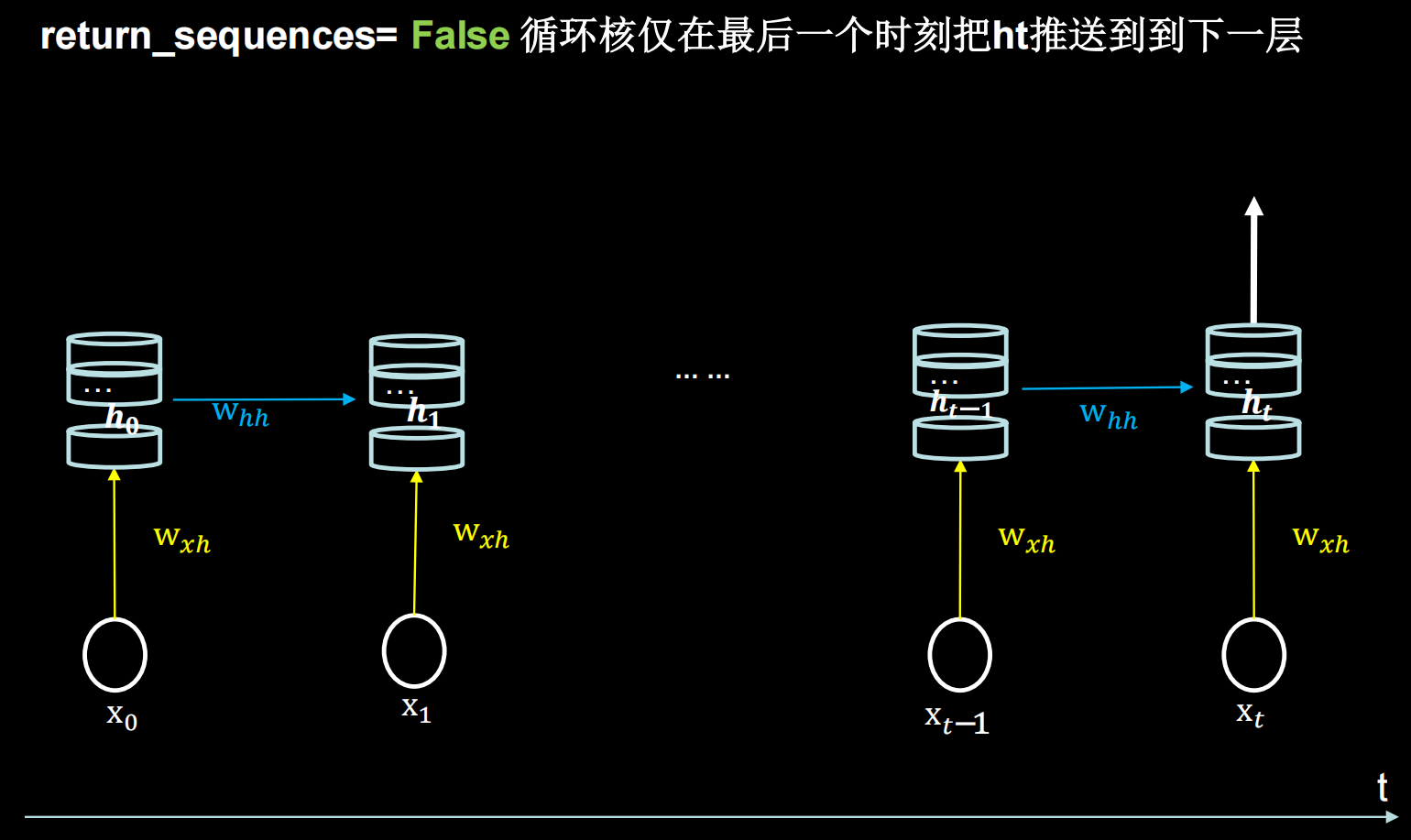
仅最后时间步输出ht
输入/输出维度
输入:API对输入循环层的数据维度是有要求的,是一个三维张量
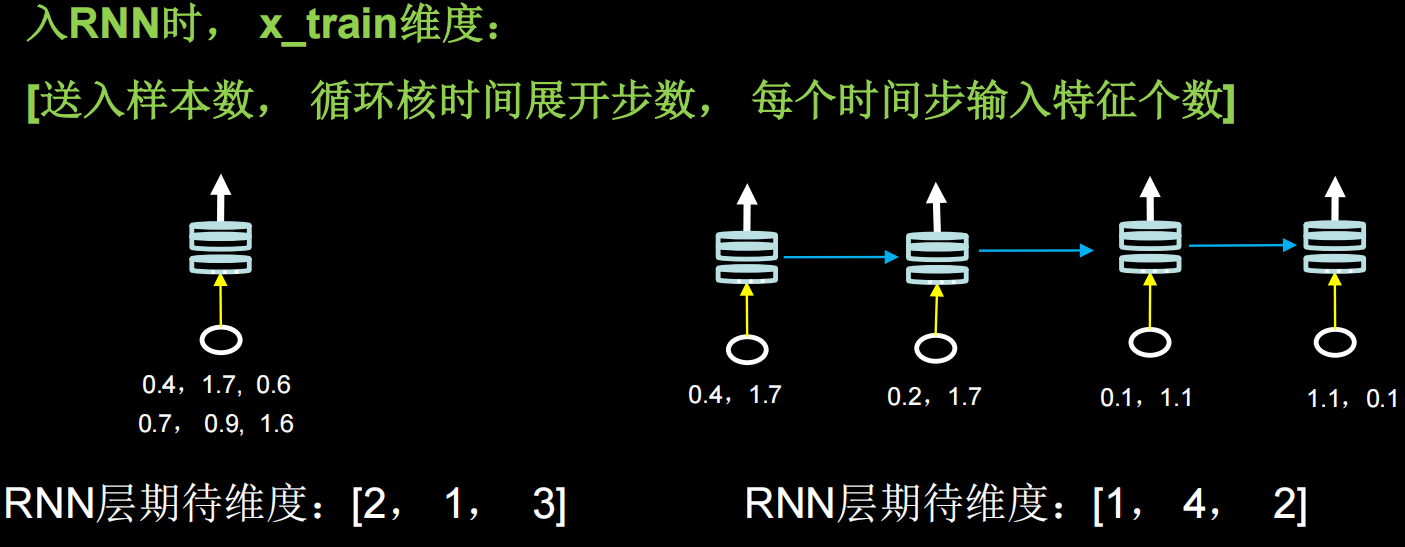
输出:
当return_sequences=True时,三维张量(输入样本数,循环核时间展开步数,本层神经元个数)
当return_sequences=False时,二维张量(输入样本数,本层神经元个数)
(五)循环计算过程
手动计算循环计算层的前向传播,具体见实践:字母预测
实践:字母预测
RNN最典型的应用就是利用历史数据,预测下一时刻将发生什么,即根据以前见过的历史规律做预测。以字母预测的例子来说明循环网络的计算过程
计算机不认识字母,只能处理数字,所以需要对字母编码,有独热编码(one-hot)和Embedding编码两种方式
one-hot编码
(一)1pre1(输入一个字母,预测下一个字母)
如:输入a 预测出 b、输入 b 预测出 c、输入 c 预测出 d、输入 d 预测出 e、输入 e 预测出 a

字母独热编码
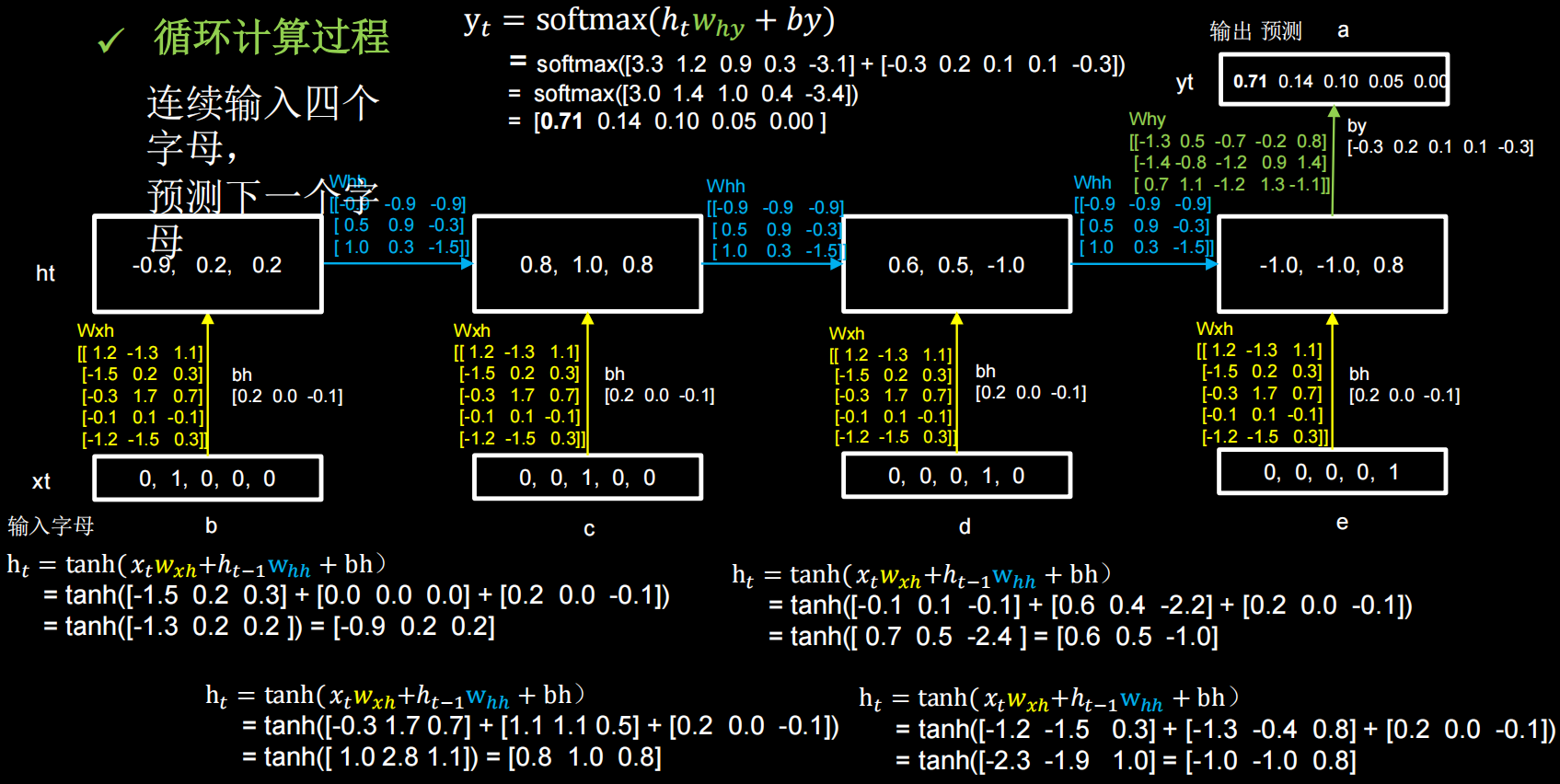
假设使用一层 RNN 网络,记忆体的个数选取 3,随机生成了Wxh、Whh和Why三个参数矩阵。字母预测网络如下图:
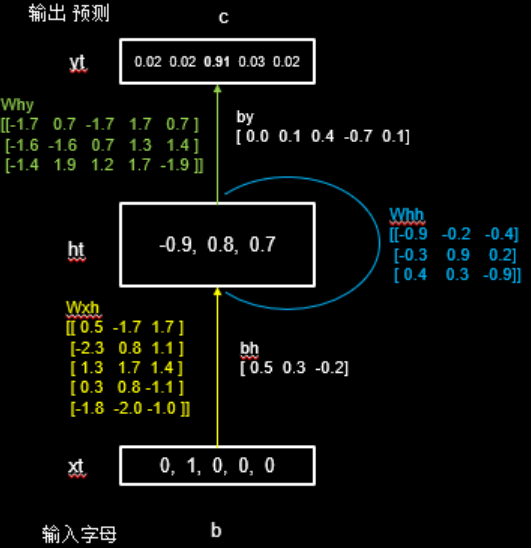


完整代码实现如下:
# 用RNN实现输入一个字母,预测下一个字母
# 字母使用独热码编码
import numpy as np
import tensorflow as tf
from keras.layers import Dense, SimpleRNN
import matplotlib.pyplot as plt
import os
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.], 4: [0., 0., 0., 0., 1.]} # id编码为one-hot
# 输入特征a,对应标签b;输入特征b,对应标签c...以此类推
x_train = [id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']],
id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]]
y_train = [w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e'], w_to_id['a']]
# 打乱顺序
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
# 使x_train符合SimpleRNN的输入要求:[送入样本数,循环核时间展开步数,每个时间步输入特征个数]
# 此处整个数据集送入,故送入样本数为len(x_train)=5;
# 输入1个字母出结果,故循环核时间展开步数为1;
# 表示为独热码有5个输入特征,故每个时间步输入特征个数为5
x_train = np.reshape(x_train, (len(x_train), 1, 5))
y_train = np.array(y_train) # 把y_train变为numpy格式
# 构建模型
model = tf.keras.Sequential([
SimpleRNN(3), # 搭建具有3个记忆体的循环层(记忆体个数越多,记忆力越好,但是占用资源会更多)
Dense(5, activation='softmax') # 全连接,实现了输出层yt的计算;由于要映射到独热码编码,找到输出概率最大的字母,故为5
])
# 配置训练方法
model.compile(optimizer=tf.keras.optimizers.Adam(0.01), # 学习率
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 断点续训
checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True,
monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型
# 执行反向传播,训练参数矩阵
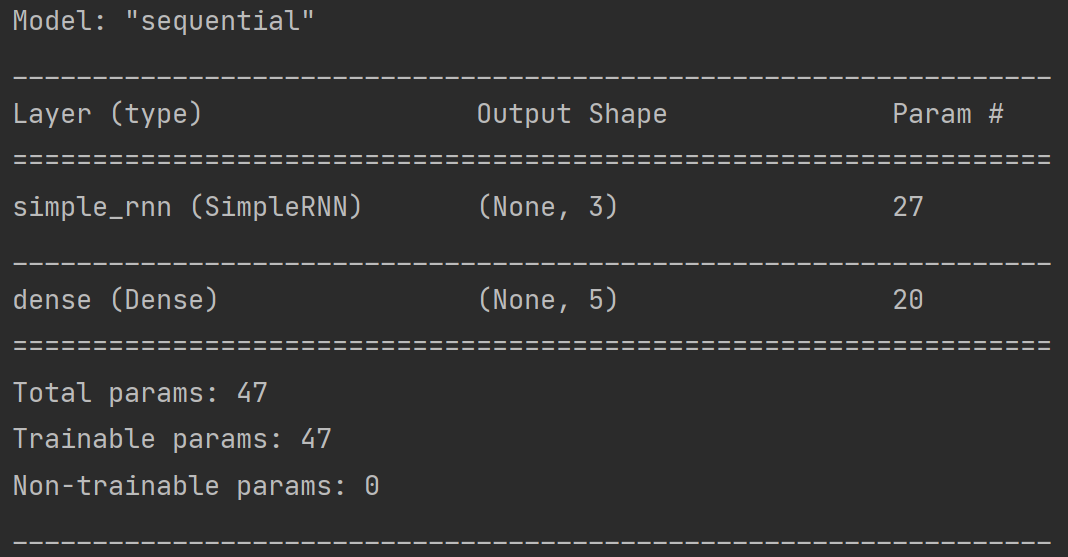
history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback])
# 打印网络结构,统计参数数目
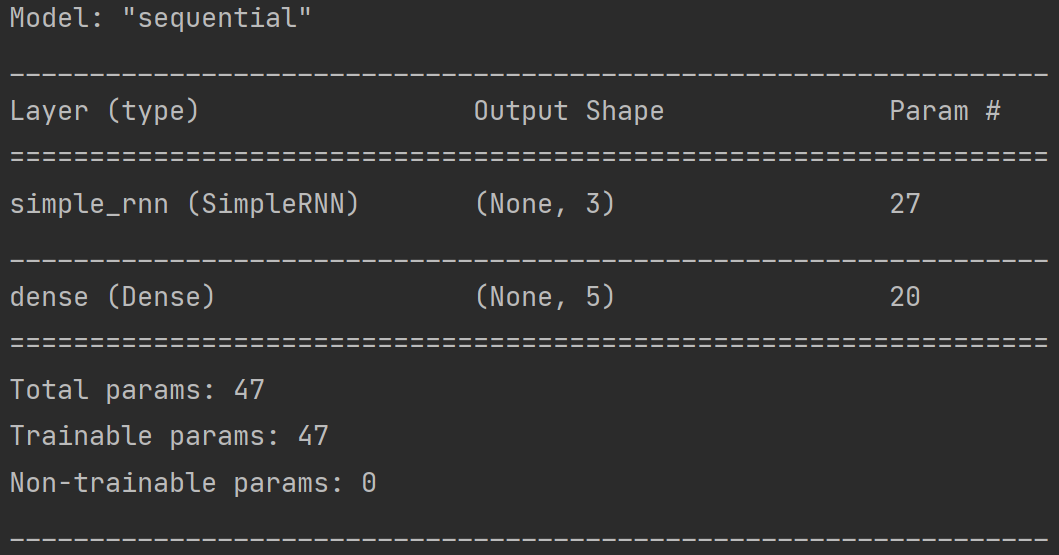
model.summary()
# 提取参数
# print(model.trainable_variables)
file = open('./rnn_onehot_1pre1_weights.txt', 'w') # 参数提取
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
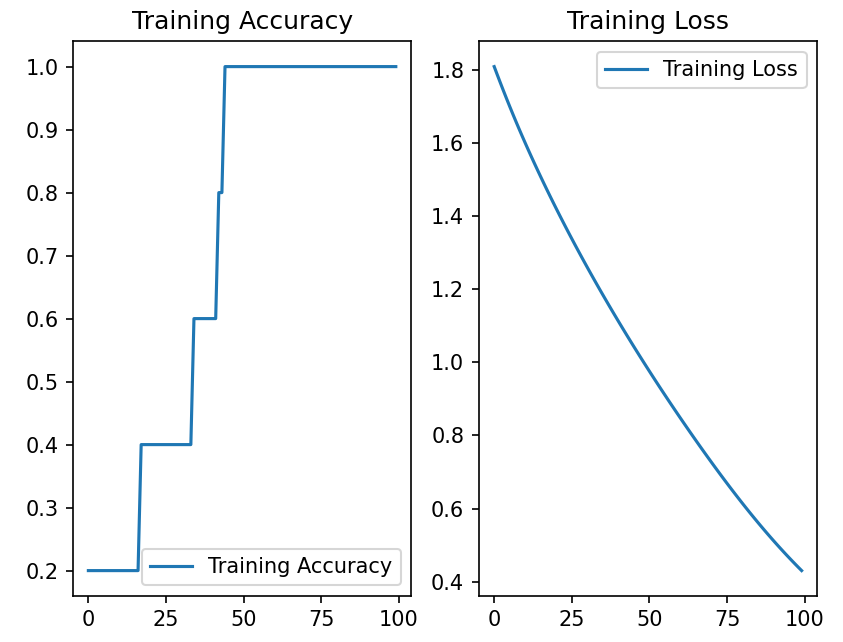
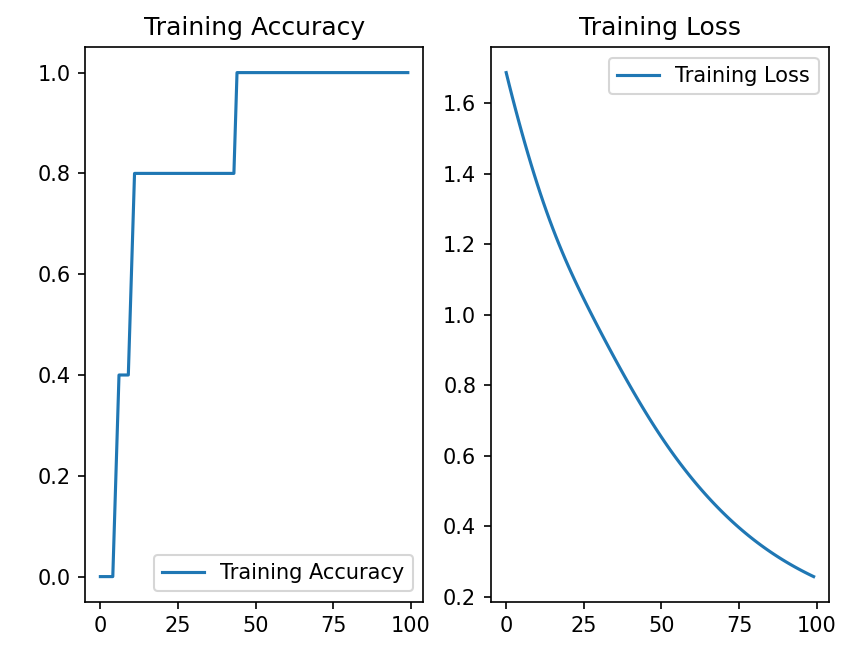
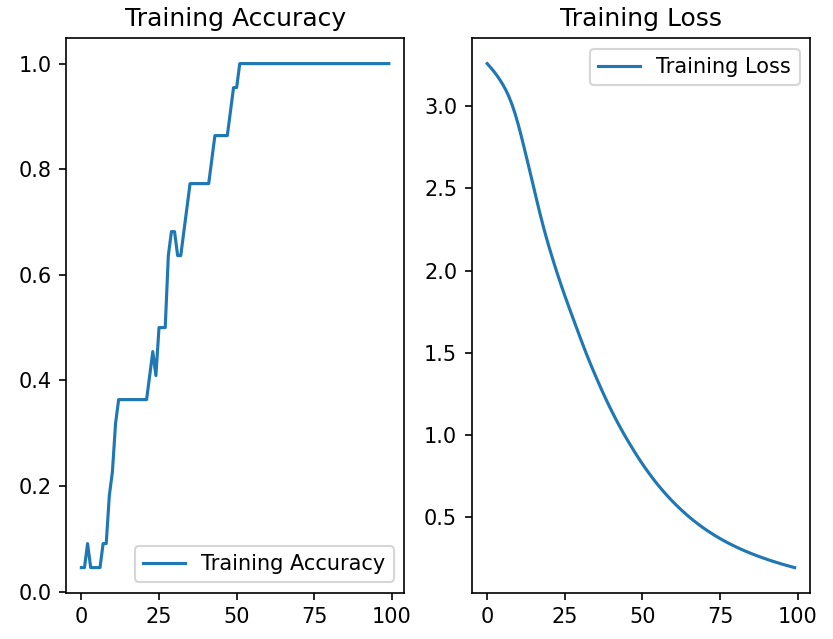
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
############### predict #############
# 展示预测效果
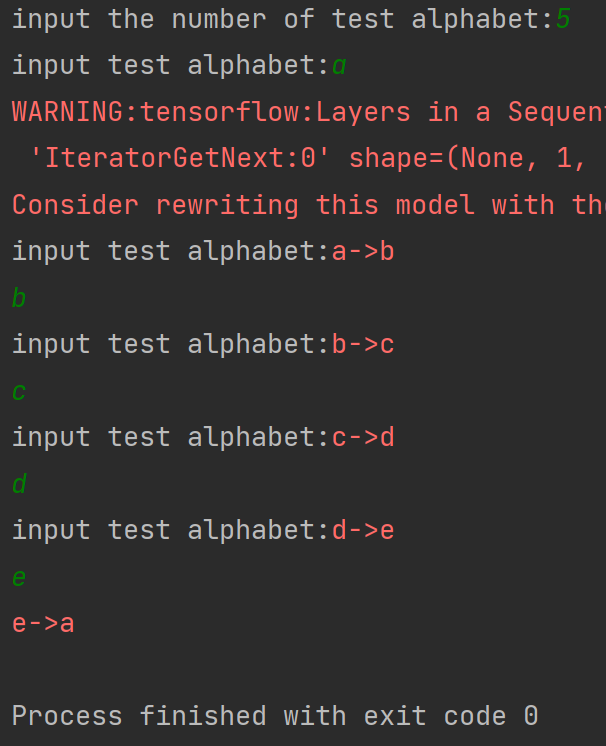
preNum = int(input("input the number of test alphabet:")) # 先输入要执行几次预测任务
for i in range(preNum):
alphabet1 = input("input test alphabet:") # 输入一个字母
alphabet = [id_to_onehot[w_to_id[alphabet1]]] # 把这个字母转换为独热码
# 使alphabet符合SimpleRNN输入要求:[送入样本数,循环核时间展开步数,每个时间步输入特征个数]
# 此处验证效果送入了1个样本,送入样本数为1;
# 输入1个字母出结果,所以循环核时间展开步数为1;
# 表示为独热码有5个输入特征,每个时间步输入特征个数为5
alphabet = np.reshape(alphabet, (1, 1, 5))
result = model.predict([alphabet]) # 得到预测结果
pred = tf.argmax(result, axis=1) # 选出预测结果最大的一个
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred]) # input_word = "abcde"
运行效果:
(二)多pre1(连续输入多个字母,预测下一个字母)
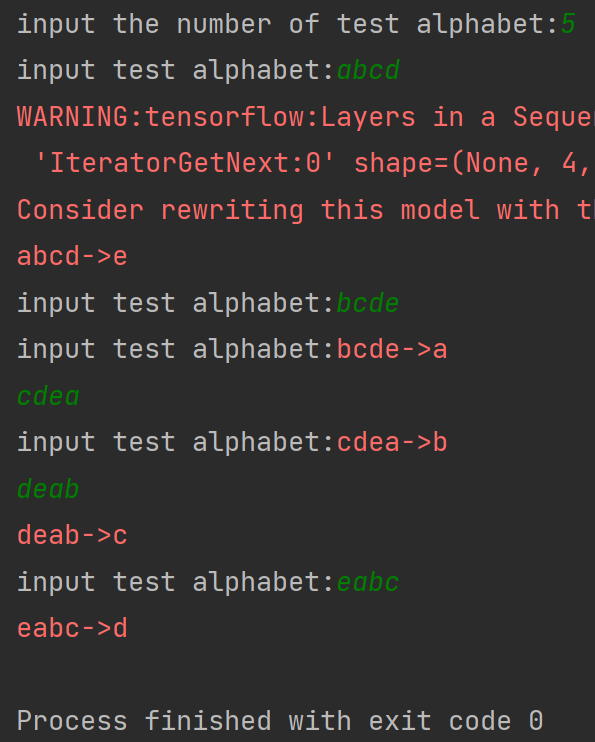
把循环核按时间步展开,连续输入多个字母预测下一个字母(以连续输入4个字母预测下一个字母为例,即输入abcd输出e,输入bcde输出a,输入cdea输出b,输入deab输出c,输入eabc输出d)
仍然使用三个记忆体,初始时刻记忆体内的记忆是 0;用一套训练好的参数矩阵感受循环计算的前向传播过程,在这个过程中,每个时刻参数矩阵是固定的,记忆体会在每个时刻被更新
下面以输入 bcde 预测 a 为例:

代码实现如下(只列出与rnn_onehot_1pre1.py代码不同的地方):
# 连续输入四个字母预测下一个字母
# 字母使用独热码编码
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.], 4: [0., 0., 0., 0., 1.]} # id编码为one-hot
'''
输入连续的abcd,对应的标签是e
输入连续的bcde,对应的标签是a
输入连续的cdea,对应的标签是b
输入连续的deab,对应的标签是c
输入连续的eabc,对应的标签是d
'''
x_train = [
[id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']]],
[id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]],
[id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']]],
[id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']]],
[id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']]],
]
y_train = [w_to_id['e'], w_to_id['a'], w_to_id['b'], w_to_id['c'], w_to_id['d']]
# 使x_train符合SimpleRNN输入要求:[送入样本数,循环核时间展开步数,每个时间步输入特征个数]。
# 此处整个数据集送入,送入样本数为len(x_train)=5;
# 输入4个字母出结果(四个字母通过四个连续的时刻输入网络),循环核时间展开步数为4;
# 表示为独热码有5个输入特征,每个时间步输入特征个数为5
x_train = np.reshape(x_train, (len(x_train), 4, 5))
y_train = np.array(y_train)
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:") # 等待连续输入四个字母
alphabet = [id_to_onehot[w_to_id[a]] for a in alphabet1] # 把这四个字母转换为独热码
# 使alphabet符合SimpleRNN输入要求:[送入样本数,循环核时间展开步数,每个时间步输入特征个数]
# 此处验证效果送入了1个样本,送入样本数为1;
# 输入4个字母出结果,所以循环核时间展开步数为4;
# 表示为独热码有5个输入特征,每个时间步输入特征个数为5
alphabet = np.reshape(alphabet, (1, 4, 5))
result = model.predict([alphabet])
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])
运行效果:
Embedding编码
独热码的位宽要与词汇量一致,若词汇量增大时,非常浪费资源(独热码的缺点:数据量大、过于稀疏、映射之间是独立的,没有表现出关联性)
Embedding是一种单词编码方法,用低维向量实现了编码。这种编码通过神经网络训练优化,能表达出单词间的相关性
Tensorflow2中的词向量空间编码层:
输入维度:二维张量 [送入样本数,循环核时间展开步数]
输出维度:三维张量 [送入样本数,循环核时间展开步数,编码维度]
tf.keras.layers.Embedding(词汇表大小,编码维度)
# 词汇表大小:编码一共要表示多少个单词
# 编码维度:用几个数字表达一个单词在Sequential搭建网络时,相比于one-hot形式增加了一层Embedding层
(一)1pre1(输入一个字母,预测下一个字母)
代码实现如下(只列出与rnn_onehot_1pre1.py不同的地方):
# 用RNN实现输入一个字母,预测下一个字母
# 字母使用Embedding编码
from keras.layers import Dense, SimpleRNN, Embedding
input_word = "abcde"
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典
x_train = [w_to_id['a'], w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e']]
y_train = [w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e'], w_to_id['a']]
# 使x_train符合Embedding输入要求:[送入样本数,循环核时间展开步数]
# 此处整个数据集送入,所以送入样本数为len(x_train)=5;
# 输入1个字母出结果,循环核时间展开步数为1
x_train = np.reshape(x_train, (len(x_train), 1))
y_train = np.array(y_train) # 把y_train变为numpy格式
# 搭建网络
model = tf.keras.Sequential([
Embedding(5, 2), # 对输入数据进行编码,生成一个五行两列的可训练参数矩阵,实现编码可训练
SimpleRNN(3), # 设定具有3个记忆体的循环层
Dense(5, activation='softmax') # 设定全连接Dense层,实现输出层y的全连接计算
])
############### predict #############
preNum = int(input("input the number of test alphabet:"))
for i in range(preNum):
alphabet1 = input("input test alphabet:")
alphabet = [w_to_id[alphabet1]] # 把读到的输入字母直接查找表示它的ID值
# 使alphabet符合Embedding输入要求:[送入样本数,循环核时间展开步数]
# 此处验证效果送入了1个样本,送入样本数为1;
# 输入1个字母出结果,循环核时间展开步数为1
alphabet = np.reshape(alphabet, (1, 1))
result = model.predict(alphabet)
pred = tf.argmax(result, axis=1)
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])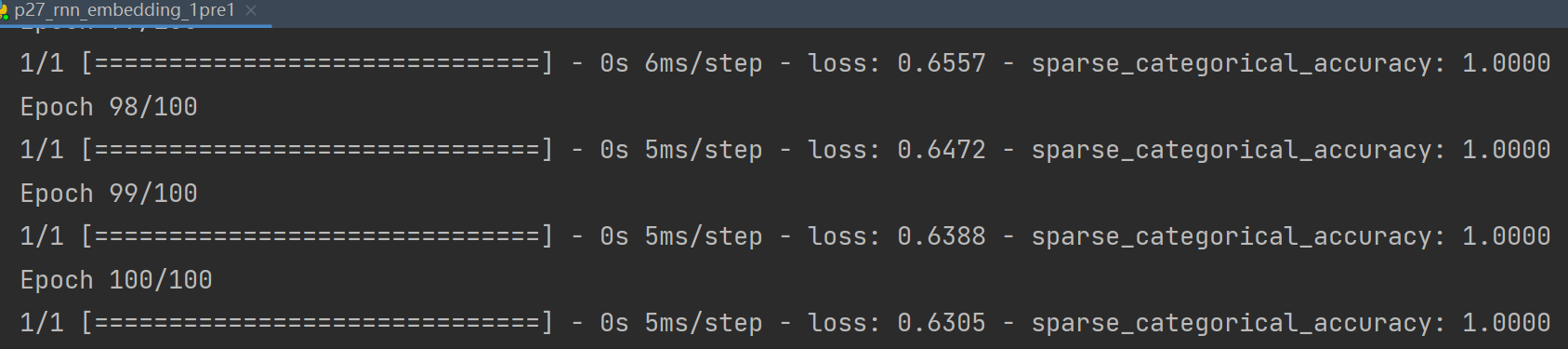
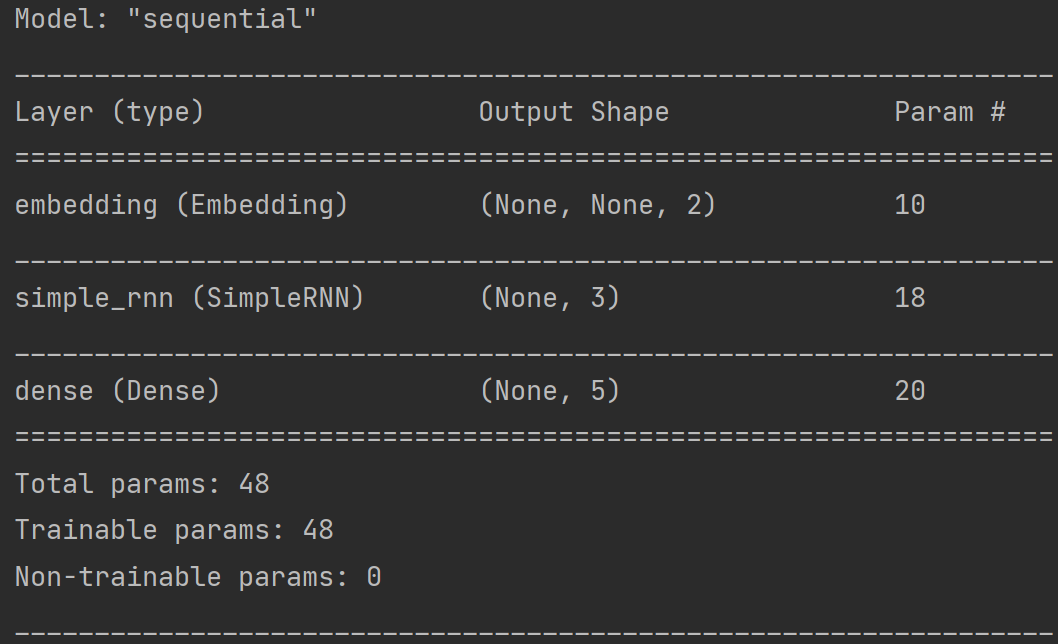
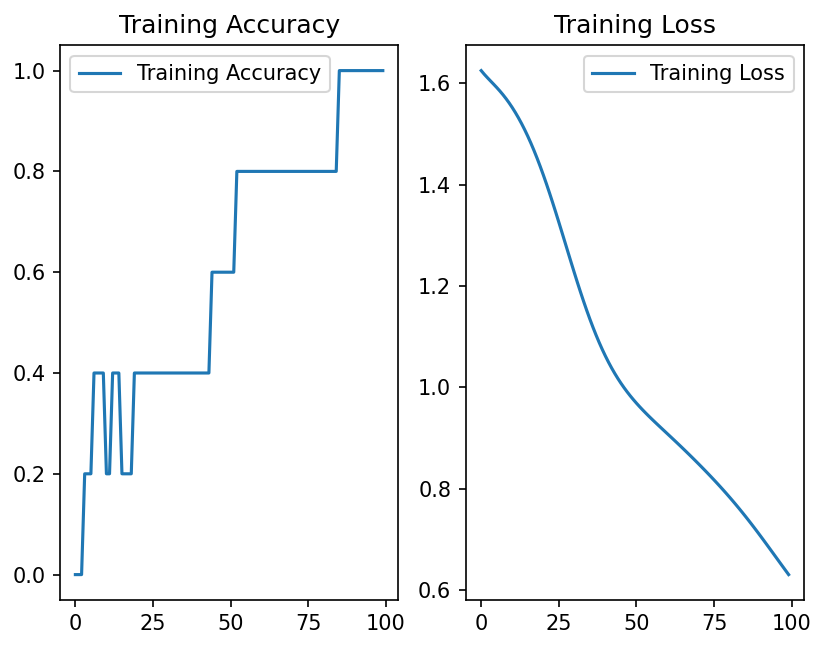
运行效果如下:
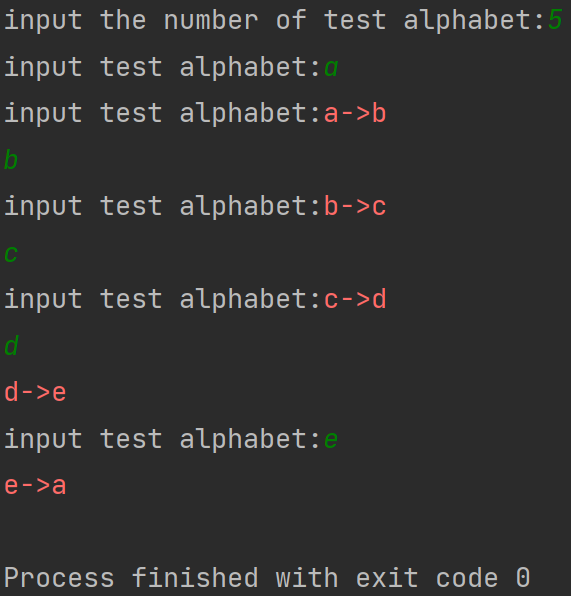
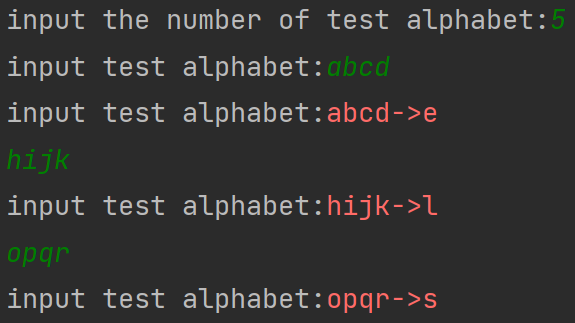
(二)多pre1(连续输入多个字母,预测下一个字母)
将词汇量扩充到26个(A-Z)
代码实现如下(只列出与rnn_onehot_1pre1.py不同的地方):
# 连续输入四个字母预测下一个字母
# 字母使用Embedding编码
from keras.layers import Dense, SimpleRNN, Embedding
input_word = "abcdefghijklmnopqrstuvwxyz" # 26个字母
# 建立一个映射表,把字母用数字表示为0-25
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4,
'f': 5, 'g': 6, 'h': 7, 'i': 8, 'j': 9,
'k': 10, 'l': 11, 'm': 12, 'n': 13, 'o': 14,
'p': 15, 'q': 16, 'r': 17, 's': 18, 't': 19,
'u': 20, 'v': 21, 'w': 22, 'x': 23, 'y': 24, 'z': 25} # 单词映射到数值id的词典
training_set_scaled = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25]
x_train = []
y_train = []
# 用for循环从数字列表中把连续4个数作为输入特征,添加到x_train;第5个数作为标签,添加到y_train
for i in range(4, 26):
x_train.append(training_set_scaled[i - 4:i])
y_train.append(training_set_scaled[i])
# 使x_train符合Embedding输入要求:[送入样本数,循环核时间展开步数]
# 此处整个数据集送入所以送入,送入样本数为len(x_train)=22(26个字母连续取4个,可以得到22组);
# 输入4个字母出结果,循环核时间展开步数为4
x_train = np.reshape(x_train, (len(x_train), 4))
y_train = np.array(y_train)
# 搭建网络
model = tf.keras.Sequential([
Embedding(26, 2), # 词汇量是26,每个单词用2个数值编码;生成一个26行2列的可训练参数矩阵,实现编码可训练
SimpleRNN(10), # 设定具有10个记忆体的循环层
Dense(26, activation='softmax') # 全连接层,实现输出层yt的计算;输出会是26个字母之一
])
################# predict ##################
preNum = int(input("input the number of test alphabet:")) # 先输入要执行几次检测
for i in range(preNum):
alphabet1 = input("input test alphabet:") # 等待连续输入四个字母
alphabet = [w_to_id[a] for a in alphabet1]
# 使alphabet符合Embedding输入要求:[送入样本数,时间展开步数]
# 此处验证效果送入了1个样本,送入样本数为1;
# 输入4个字母出结果,循环核时间展开步数为4
alphabet = np.reshape(alphabet, (1, 4))
result = model.predict([alphabet]) # 输入网络进行预测
pred = tf.argmax(result, axis=1) # 选出预测结果最大的一个
pred = int(pred)
tf.print(alphabet1 + '->' + input_word[pred])
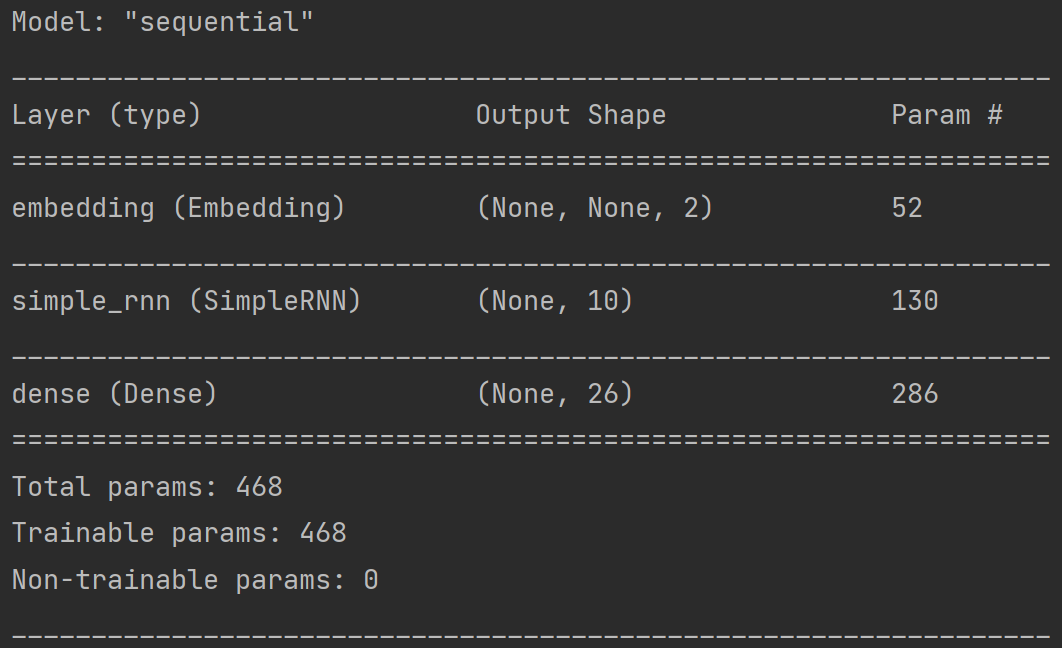
运行效果:
实践:股票预测
RNN
LSTM
GRU
见链接: