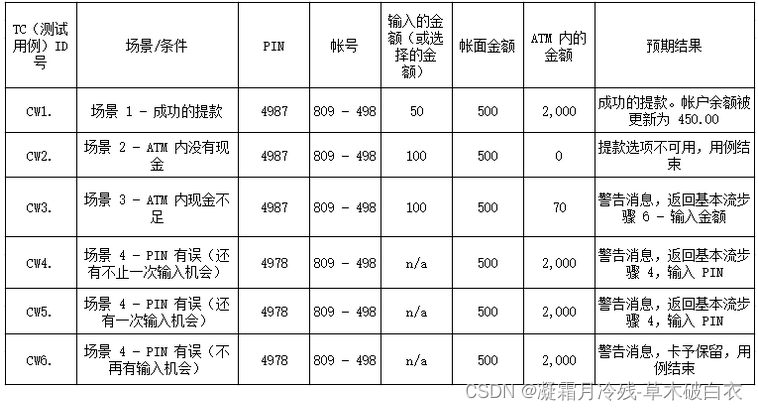
看到什么函数就记录了,没有什么逻辑关系
spark 中DataFrame 和 pandas的DataFrame的区别
1. F.split() 和 df.withColumn()
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import *
df = spark.sql(sql)
split_col = F.split(df_order['xxxx'], '\|') # 对列切分
df_order = df_order.withColumn('llat', split_col.getItem(0).cast('float')) #withColumn 新增一列,第二个参数传入已有列的Column对象,否则会报错2. F.collect_list() 和 df.groupby()
F.collect_list() 聚合函数,返回一个list
Spark SQL/DataFrame/DataSet操作(三)-----分组聚合groupBy_微步229的博客-CSDN博客
df_group = df_order.groupby(['user_id', 'loc_h3_id']).agg(
F.collect_list("loaded_latlon").alias("loaded_latlon"),
F.collect_list("order_datetime").alias("time"),
F.collect_list("sl_distance").alias("sl_distance")). \
filter(F.size('loaded_latlon') >= 2).persist() # 持久化3. F.udf() 第一个传入函数名,函数可以用lambda表达式;第二个是返回类型,如果有多个返回值,用StructType()
def get_h3_heat_schema(res=12):
schema = StructType([
StructField("h3_res{}_d7".format(res), IntegerType(), False),
StructField("h3_res{}_d14".format(res), IntegerType(), False),
StructField("h3_res{}_d30".format(res), IntegerType(), False),
StructField("h3_res{}_d60".format(res), IntegerType(), False),
StructField("h3_res{}_d90".format(res), IntegerType(), False),
StructField("h3_res{}_d120".format(res), IntegerType(), False),
StructField("h3_res{}_decay7".format(res), FloatType(), False),
StructField("h3_res{}_decay30".format(res), FloatType(), False),
])
return schema
def get_h3_features(data):
# 获取h3相关特征feature
feature_list = []
interval_list = [7, 14, 30, 60, 90, 120]
for interval in interval_list:
feature_list.append(len(list(filter(lambda x: x <= interval, data))))
head_decay_7, head_decay_30 = 0, 0
for time in data:
head_decay_7 += math.pow(DECAY_7, time)
head_decay_30 += math.pow(DECAY_30, time)
feature_list.extend([round(head_decay_7, 2), round(head_decay_30, 2)])
return feature_list
schema = get_h3_heat_schema(11)
udf_get_h3_features = F.udf(get_h3_features, schema)
df = df_order.groupBy('load_h3_11') \
.agg(F.collect_list('time_days').alias("time_days"), \
F.countDistinct('user_id').alias("h3_11_user_cnt")) \
.withColumn('h3_11_heat', udf_get_h3_features(F.col('time_days'))) \
.select('load_h3_11', 'h3_11_user_cnt', 'h3_11_heat.*')简单的可以使用以下方式注册udf函数
@F.udf(returnType=IntegerType())
def get_time_ago(order_date, end_date):
order_date = datetime.strptime(order_date, '%Y-%m-%d %H:%M:%S')
return (end_date - order_date).days + 14. .alias() # alias()起别名后在dataframe会增加一个新列,和withColumn()效果一致
5. F.struct() # 这种数据结构同C语言的结构体,内部可以包含不同类型的数据
df = df_order.groupBy('loc_h3_11') \
.agg(F.collect_list(F.struct('load_h3_12', 'time_days')).alias("tuple")) \
.withColumn('trans_prob', get_trans_prob(F.col('tuple'))) \
.drop('tuple')6. F.lit(x) 创建一列值为x的列,也可以把这个值作为参数
第一种用法:
df.withColumn("spark_user",F.lit(True))结果如下:

第二种用法:
@F.udf(returnType=StringType())
def lat_lng_to_h3(lat, lng, h3_level=12):
"""
map lng lat to h3
"""
return h3.geo_to_h3(lat, lng, h3_level)
df_order = df_order.withColumn('loc_h3_11', lat_lng_to_h3(F.col('alat'), F.col('alng'), F.lit(11))) #把一列的11作为参数传入7. F.countDistinct() 去重统计
8. df.select() 和 df.selectExpr()
Spark---DataFrame学习(二)——select、selectExpr函数_stan1111的博客-CSDN博客_selectexpr
9. 两个表进行关联的方式
cond = [order_df.user_id == personalized_df.user_id, order_df.loc_h3_9 == personalized_df.loc_h3_id]
joined_df = order_df.join(personalized_df, on=cond, how='inner'). \
drop(personalized_df.user_id) # on传入的是条件,how传入的是关联方式,有inner、left、right、outer,关联完记得要把两个表里的相同列名删除一个,否则会多出来一个10. F.explode() 把列数据变为多个行数据
spark之explode()方法--- 行转列_卢子墨的博客-CSDN博客_spark中explode
11. 将列中为空的值过滤掉
order_df = order_df.filter(F.col('slat').isNotNull())12. F.filter(condition) # 保留满足条件的值