如今,网络服务、数字媒体、传感器日志数据等众多来源产生了大量数据,只有一小部分数据得到妥善管理或利用来创造价值。读取大量数据、处理数据并根据这些数据采取行动比以往任何时候都更具挑战性。
在这篇文章中,我试图展示:
- 在 Python 中生成模拟用户配置文件数据
- 通过 Kafka Producer 将模za拟数据发送到 Kafka 主题
- 使用 Logstash 读取数据并上传到 Elasticsearch
- 使用 Kibana 可视化流数据
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我实现了如下的一个数据 pipeline:

在今天的文章中,我将实现如下的一个数据 pipeline:
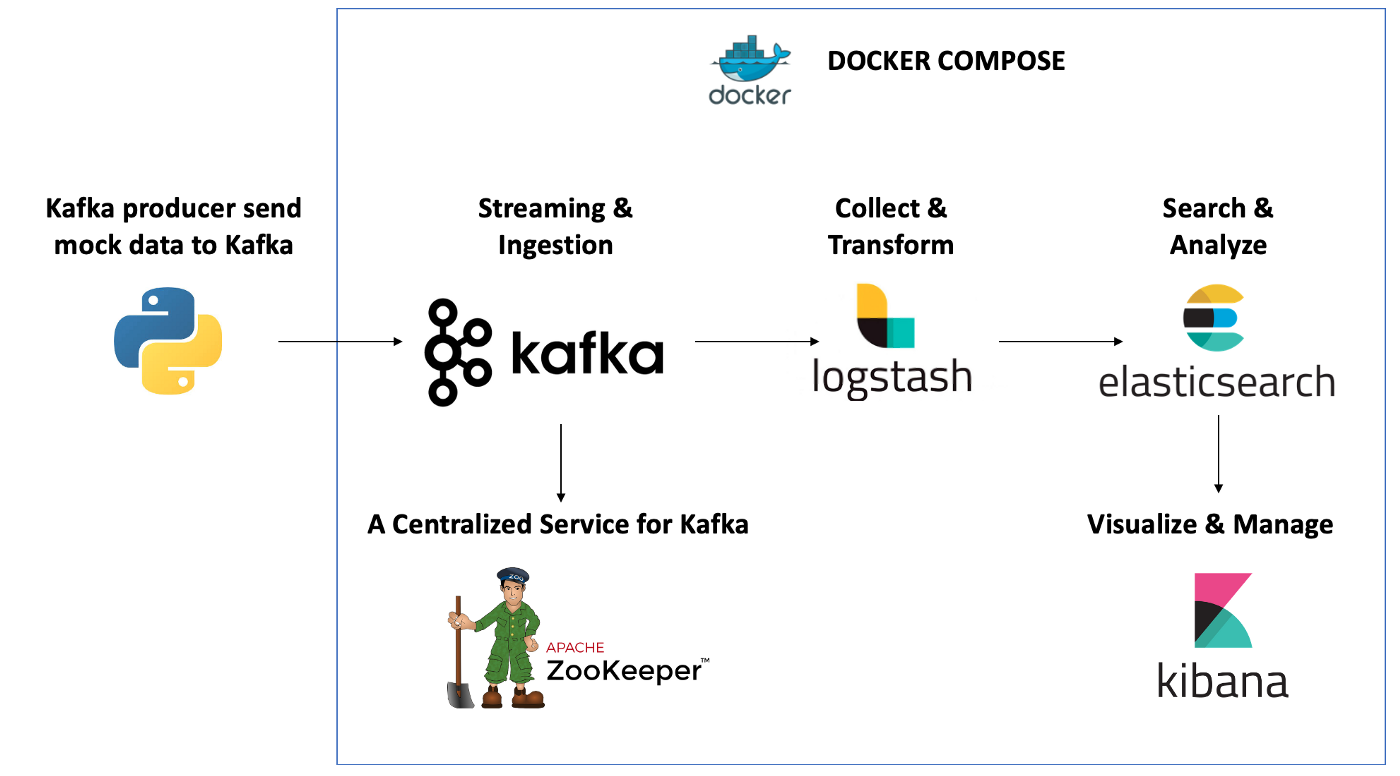
在今天的展示中,我将使用最新的 Elastic Stack 8.6.1 来进行展示。我将使用如下的配置:
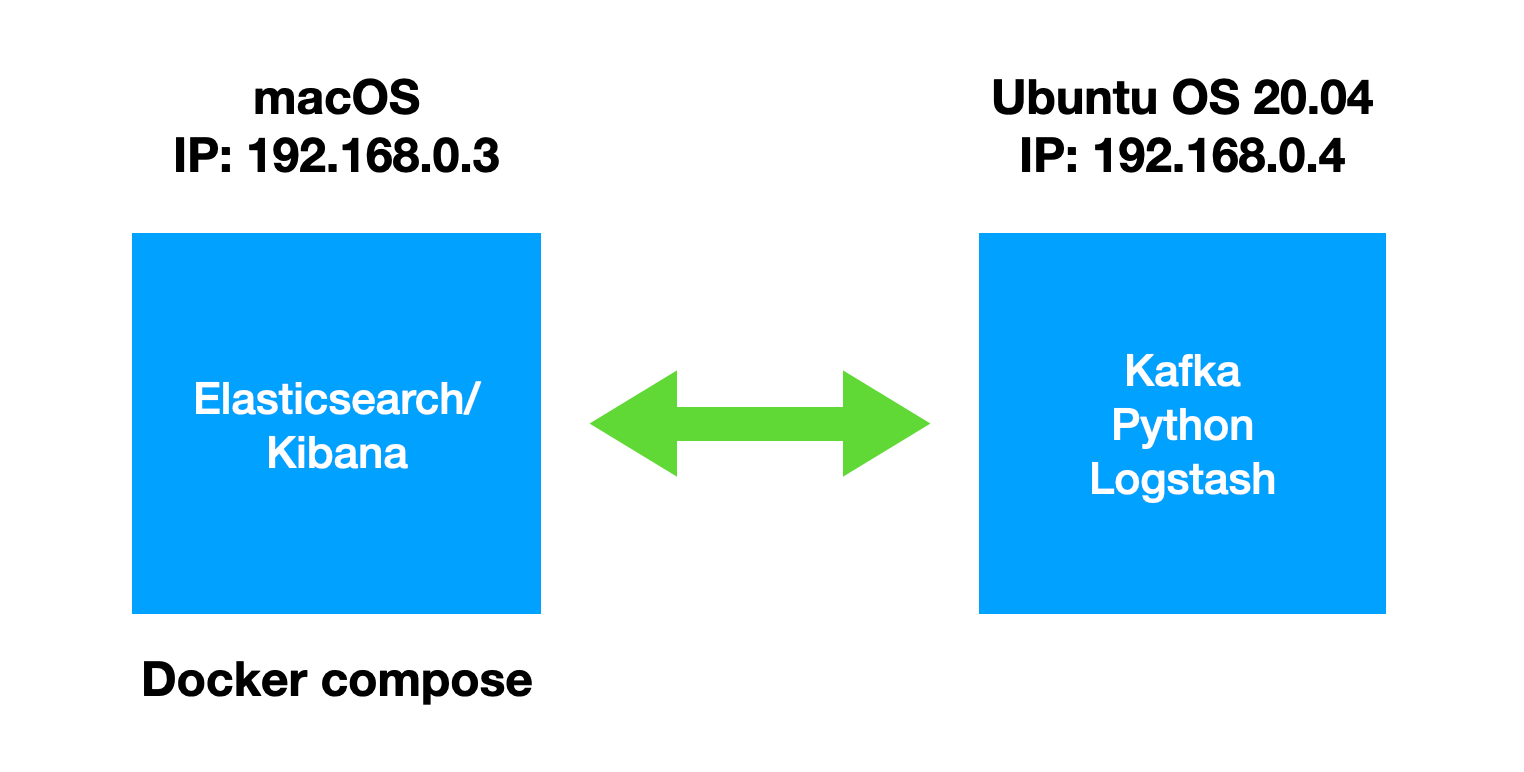
如上所示,我使用两台机器:macOS 用于安装 Elastic Stack,而另外一台 Ubuntu 机器将被用于安装 Kafka 及 Logstash。我将在 Ubuntu OS 机器上使用 Python 向 Kafka 写入数据。
安装
Elasticsearch 及 Kibana
我将使用 docker compose 的方法来安装 Elasticsearch 及 Kibana。我们可以参考文章 “Elasticsearch:使用 Docker compose 来一键部署 Elastic Stack 8.x” 来进行部署。当然,我们也可以参阅如下的文章来进行部署:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在默认的情况下,Elasticsearch 的访问是带有 HTTPS 的安全访问。
我们可以在电脑的 terminal 中打入如下的命令来检查:
curl -k -u elastic:password https://192.168.0.3:9200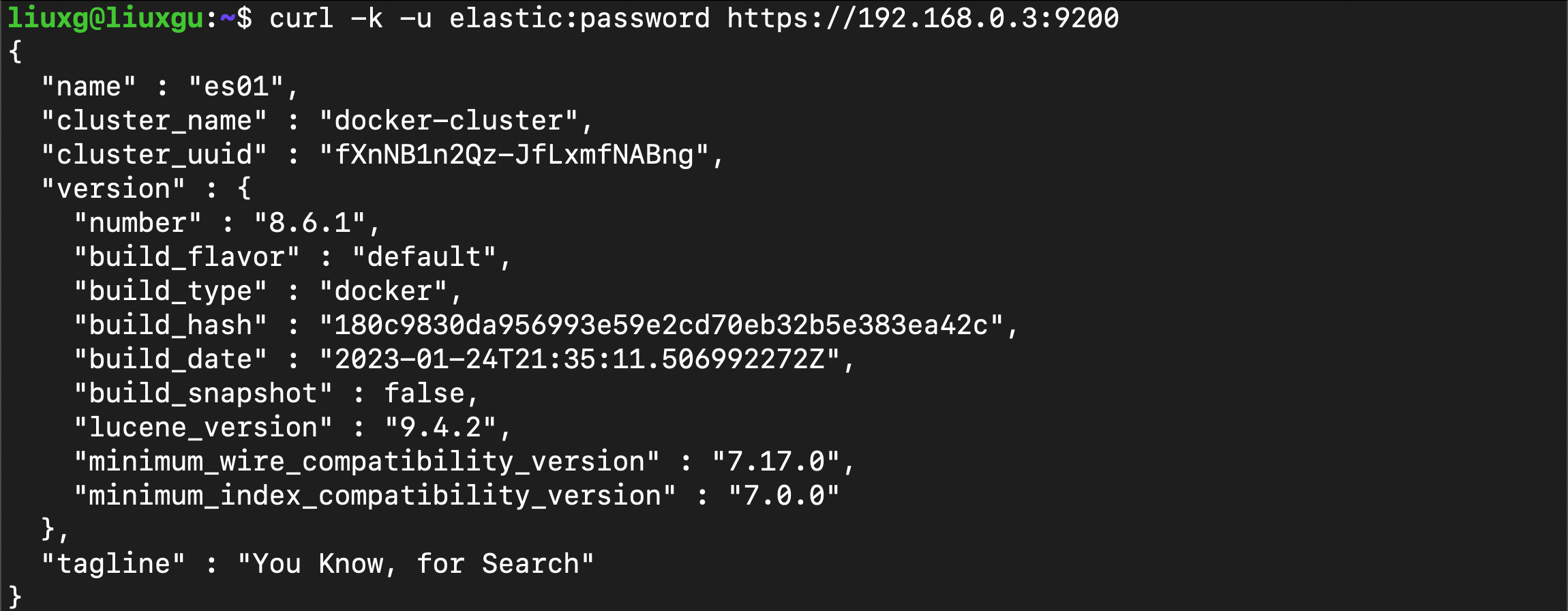
上述命令是在 Ubuntu OS 的机器上运行。它表明,我们可以在 Ubuntu OS 的机器上成功地访问 Elasticsearch。
安装 Kafka
我们安装涉及设置 Apache Kafka(我们的消息代理)。Kafka 使用 ZooKeeper 来维护配置信息和同步,因此在设置 Kafka 之前,我们需要先安装 ZooKeeper:
sudo apt-get install zookeeperd接下来,让我们下载并解压缩 Kafka:
wget https://apache.mivzakim.net/kafka/2.4.0/kafka_2.13-2.4.0.tgz
tar -xzvf kafka_2.13-2.4.0.tgz
sudo cp -r kafka_2.13-2.4.0 /opt/kafka现在,我们准备运行 Kafka,我们将使用以下脚本进行操作:
sudo /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties你应该开始在控制台中看到一些 INFO 消息:

Kafka 的配置如下:
- Kafka 正在监听 9092 端口
- Zookeeper 正在监听 2181 端口
- Kafka Manager 正在监听 9000 端口
我们接下来打开另外一个控制台中,并为 registered_user 创建一个主题:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic registered_user我们创建了一个叫做 registered_user 的 topic。上面的命令将返回如下的结果:
$ /opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic registered_user
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic registered_user.我们现在已经完全为开始管道做好了准备。
有关 kafka 的安装,我们也可以使用 docker-compose 来进行安装。具体安装步骤请参考 “Elastic:Data pipeline:使用 Kafka => Logstash => Elasticsearch”。
Logstash
我们接下来安装 Logstash。我们到 Elastic 的官方网站来下载时候我们平台的安装包:
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4wliuxg@liuxgu:~/logstash$ wget https://artifacts.elastic.co/downloads/logstash/logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w
--2023-01-29 14:20:31-- https://artifacts.elastic.co/downloads/logstash/logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w
Resolving artifacts.elastic.co (artifacts.elastic.co)... 34.120.127.130, 2600:1901:0:1d7::
Connecting to artifacts.elastic.co (artifacts.elastic.co)|34.120.127.130|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 341638094 (326M) [binary/octet-stream]
Saving to: ‘logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w’
logstash-8.6.1-amd64.de 100%[==============================>] 325.81M 10.7MB/s in 31s
2023-01-29 14:21:03 (10.6 MB/s) - ‘logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w’ saved [341638094/341638094]
liuxg@liuxgu:~/logstash$ mv 'logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w' logstash-8.6.1-amd64.deb
我们使用如下的命令来安装 Logstash:
sudo dpkg -i logstash-8.6.1-amd64.deb liuxg@liuxgu:~/logstash$ sudo dpkg -i logstash-8.6.1-amd64.deb
[sudo] password for liuxg:
(Reading database ... 386953 files and directories currently installed.)
Preparing to unpack logstash-8.6.1-amd64.deb ...
Unpacking logstash (1:8.6.1-1) over (1:8.4.2-1) ...
Setting up logstash (1:8.6.1-1) ...
Installing new version of config file /etc/logstash/jvm.options ...为了能够配置 Logstash 能够正确地访问 Elasticsearch,我们可以参考我之前的文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。我们需要按照文章里的要求创建一个叫做 truststore.p12 的文件。由于我们是以 docker 的形式启动 Elasticsearch 及 Kibana 的,我们在 macOS 的机器上使用如下的命令来拷贝证书。我们先查看容器:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a2374f620b78 docker.elastic.co/kibana/kibana:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 0.0.0.0:5601->5601/tcp elastic8-kibana-1
e2d6443b8edb docker.elastic.co/elasticsearch/elasticsearch:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 9200/tcp, 9300/tcp elastic8-es03-1
a29bbeb4bdf2 docker.elastic.co/elasticsearch/elasticsearch:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 9200/tcp, 9300/tcp elastic8-es02-1
81de3d45943c docker.elastic.co/elasticsearch/elasticsearch:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 0.0.0.0:9200->9200/tcp, 9300/tcp elastic8-es01-1我们可以看到有一个叫做 elastic8-es01-1 的容器。
$ pwd
/Users/liuxg/data/elastic8
$ ls
docker-compose.yml http_ca.crt kibana.yml write_to_kafka.py
$ docker cp 81de3d45943c:/usr/share/elasticsearch/config/certs/ca/ca.crt .
$ ls
ca.crt docker-compose.yml http_ca.crt kibana.yml write_to_kafka.py
$ ls
ca.crt docker-compose.yml kibana.yml 运用 ca.crt 文件,我们使用如下的命令来创建一个叫做 truststore.p12 的文件。它的 storepass 是 password:
keytool -import -file ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12$ keytool -import -file ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12
Certificate was added to keystore
$ ls
ca.crt docker-compose.yml kibana.yml truststore.p12从上面,我们可以看出来它创建了 truststore.p12 这个文件。我们接下来把这个文件拷贝到 Ubuntu OS 机器下的 /etc/logstash/conf.d 目录中。
liuxg@liuxgu:/etc/logstash/conf.d$ ls
truststore.p12我们接下来在地址 /etc/logstash/conf.d 创建一个叫做叫做 kafka_to_logstash.conf 的配置文件:
kafka_to_logstash.conf
input {
kafka {
bootstrap_servers => "192.168.0.4:9092"
topics => ["registered_user"]
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["https://192.168.0.3:9200"]
index => "registered_user"
workers => 1
user => "elastic"
password => "password"
ssl_certificate_verification => true
truststore => "/etc/logstash/conf.d/truststore.p12"
truststore_password => "password"
}
}在上面,请注意的是:
- 我们使用 Elasticsearch 的超级用户 elastic 来连接 Elasticsearch。它的密码是 password。在实际的使用中,我们可以创建一个合适权限的用户来进行连接。
这样我们的 Logstash 的配置就完成了。
sudo service logstash start我们可以通过如下的命令来检查 Logstash 是否已经成功地运行起来了。
service logstash statusliuxg@liuxgu:~$ service logstash status
● logstash.service - logstash
Loaded: loaded (/lib/systemd/system/logstash.service; disabled; vendor preset: enabled)
Active: active (running) since Sun 2023-01-29 15:25:57 CST; 7s ago
Main PID: 60841 (java)
Tasks: 33 (limit: 18977)
Memory: 508.6M
CGroup: /system.slice/logstash.service
└─60841 /usr/share/logstash/jdk/bin/java -Xms1g -Xmx1g -Djava.awt.headless=true ->
1月 29 15:25:57 liuxgu systemd[1]: Started logstash.
1月 29 15:25:57 liuxgu logstash[60841]: Using bundled JDK: /usr/share/logstash/jdk上面表明我们的 logstash 服务已经被成功地运行起来了。我们还可以通过如下的命令来查看 logstash 服务的日志:
journalctl -u logstash向 Kafka topic 写入数据
我们使用如下的 Python 应用向我们的 Kafka topic “registered_user” 来写入数据:
write_to_kafka.py
from faker import Faker
from kafka import KafkaProducer
import json
fake = Faker()
import time
def get_registered_data():
return {
'first name': fake.first_name(),
'last name': fake.last_name(),
'age': fake.random_int(0, 60),
'address': fake.address(),
'register_year': fake.year(),
'register_month': fake.month(),
'register_day': fake.day_of_month(),
'monthly_income': fake.random_int(28000, 100000)
}
def json_serializer(data):
return json.dumps(data).encode('utf-8')
producer = KafkaProducer(bootstrap_servers=['192.168.0.4:9092'],
value_serializer=json_serializer)
if __name__ == '__main__':
while True:
registered_data = get_registered_data()
print(registered_data)
producer.send('registered_user', registered_data)
time.sleep(3)为了运行上面的应用,我们必须安装如下的两个包:
pip3 install Faker
pip3 install kafka-python我们在 Ubuntu OS 机器上运行上面的代码:
python write_to_kafka.py 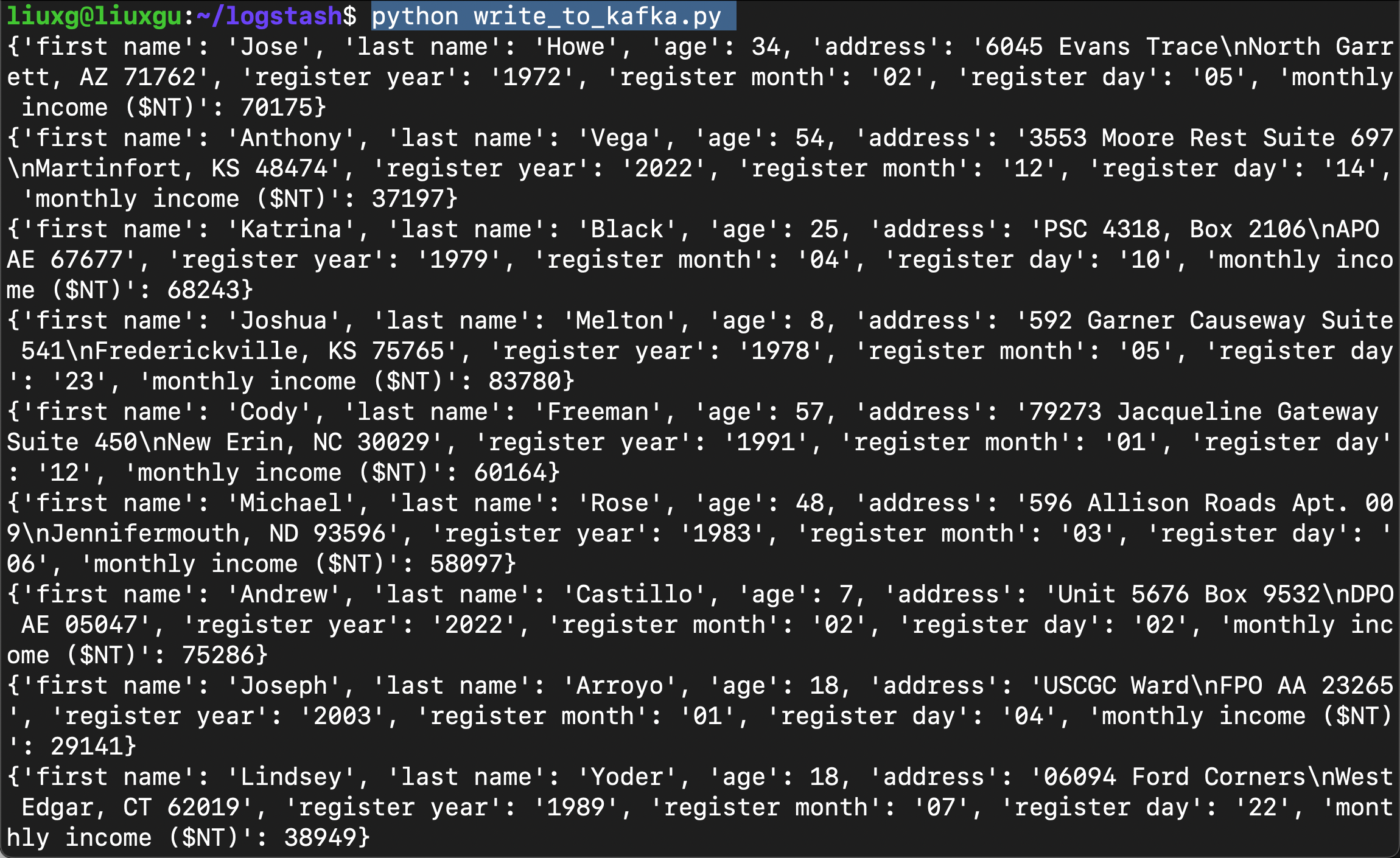
我们回到 Kibana 的界面来进行查看:
GET _cat/indices上面的命令显示:
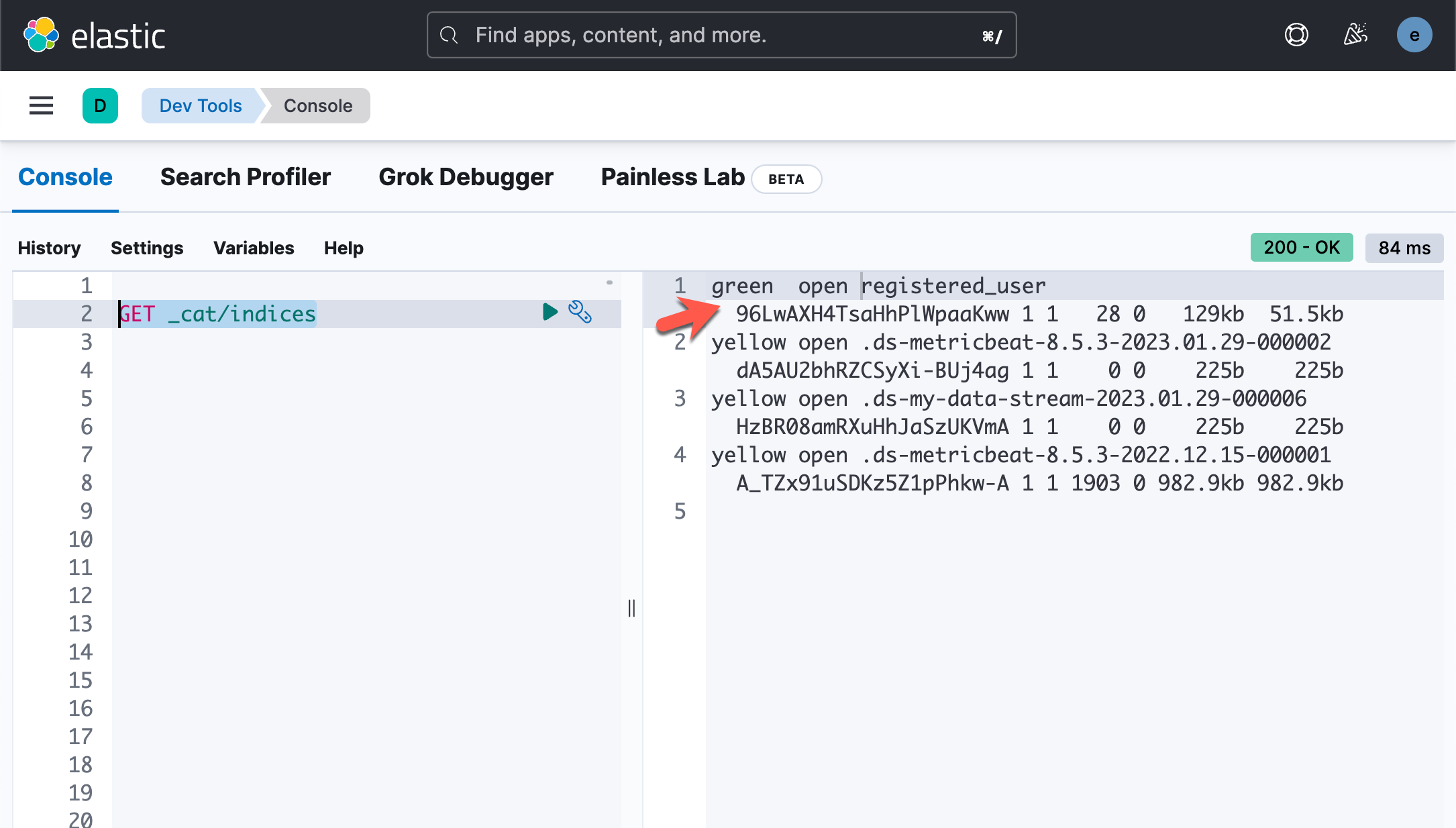
我们可以对这个文件进行搜索:
GET registered_user/_search我们可以看到如下的结果:
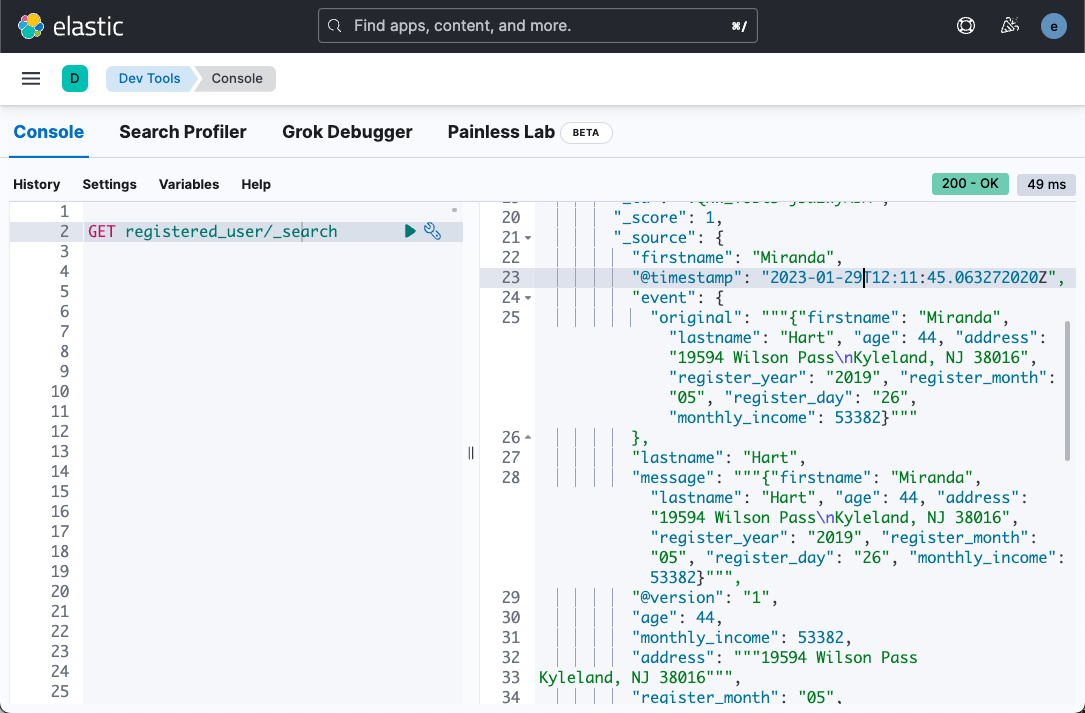
从上面,我们可以看出来我们的数据已经被结构化。
我们可以针对这个索引进行可视化。你可以阅读我博客里的相应文章以了解更多。







![[羊城杯 2020]easyre 1题解](https://img-blog.csdnimg.cn/img_convert/5e9c92147c93327669d029a8957b676d.jpeg)