在机器学习和数据挖掘领域,相似性搜索是一项基本且重要的任务,它涉及到在大型数据集中找到与特定对象最相似的对象。Faiss是一个由Facebook AI Research开发的库,专门用于高效地进行相似性搜索和聚类,它之所以重要,是因为它提供了一种快速且准确的方式来执行这一任务,尤其是在处理大规模高维向量数据集时。
在本文中,将深入探讨Faiss的核心概念和功能。将介绍如何安装和使用Faiss,以及如何通过选择合适的索引结构、利用GPU加速和进行有效的数据预处理来优化Faiss的性能。此外,还将提供一些实用的示例,展示如何在实际应用中使用Faiss进行相似性搜索。
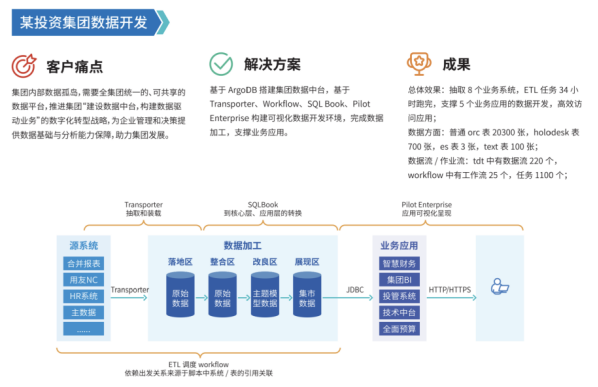
Faiss简介
在开始任何代码之前,许多人可能会问——Faiss是什么?
Faiss是由Facebook AI开发的一个库,专门用于高效地进行相似性搜索和聚类。它特别适合处理大规模的高维向量数据集,如图像和文本数据中的特征向量。Faiss之所以特殊,主要得益于以下几个方面:
- 高效的向量相似性搜索:Faiss提供了多种算法来快速找到一个向量在大型数据集中的最近邻和近邻,这对于机器学习和数据挖掘任务非常有用。例如,它支持K最近邻(K-Nearest Neighbors,KNN)搜索,这可以用于多种应用,如推荐系统、图像检索和自然语言处理。。
- 灵活的索引结构:Faiss支持多种索引结构,如HNSW(Hierarchical Navigable Small World)、IVF(Inverted Indexed Vector File)和PQ(Product Quantization),这些结构可以针对不同的数据和查询需求进行优化。HNSW适合于处理大规模数据集的近似最近邻搜索,而IVF和PQ则适用于需要高效存储和查询的场景。
- GPU加速:Faiss利用GPU进行向量计算,大大提高了相似性搜索的速度,尤其是在处理大规模数据集时。这种加速对于那些需要处理海量数据的应用来说至关重要,因为它可以显著减少搜索时间。
- 易于集成:Faiss可以很容易地集成到Python和其他编程语言中,并且与常见的机器学习框架(如TensorFlow和PyTorch)兼容。这使得开发者可以轻松地在他们的项目中使用Faiss,而无需进行复杂的调整。
- 可扩展性:Faiss可以水平扩展,支持在多个服务器和GPU上运行,非常适合处理和搜索百亿甚至千亿级别的向量。这种可扩展性使得Faiss成为处理大规模数据集的优选工具。
Faiss的基本概念是使用索引技术来加速相似性搜索。当我们有一组向量时,我们可以使用Faiss对它们进行索引——然后使用另一个向量(查询向量),我们在索引中搜索最相似的向量。Faiss不仅允许我们构建索引和搜索——它还大大加快了搜索时间,达到惊人的性能水平。
如何最好地使用Faiss?
- 选择合适的索引:根据数据的特性和查询需求选择合适的索引结构,以实现最佳的搜索性能。
- 利用GPU加速:如果可能的话,使用GPU来加速相似性搜索,尤其是在处理大规模数据集时。
- 处理稀疏数据:Faiss支持稀疏数据的处理,这对于图像和文本数据特别有用。
- 使用Faiss API:Faiss提供了丰富的API,可以方便地在各种机器学习应用中使用。
- 考虑数据预处理:有效的数据预处理可以显著提高Faiss的性能,比如特征缩放和维度减少。
Faiss安装
安装Faiss非常简单,以下是安装Faiss的步骤:
-
使用conda:
-
如果使用的是conda环境管理器,可以通过以下命令安装Faiss:
conda install -c pytorch faiss-gpu如果没有GPU或需要安装CPU版本的Faiss,可以安装
faiss-cpu:conda install -c pytorch faiss-cpu
-
-
使用pip:
-
如果使用的是pip,可以安装Faiss的CPU版本:
pip install faiss-cpu -
如果有GPU支持,也可以安装GPU版本的Faiss:
pip install faiss-gpu
-
-
验证安装:
-
安装完成后,可以通过以下命令验证Faiss是否安装成功:
import faiss faiss.test() -
如果安装正确,这个命令会返回一个结果,表示Faiss的测试通过。
-
通过以上步骤,可以成功地安装Faiss,并验证其是否安装成功。
简单尝试
准备数据
首先,获取一些文本数据并处理成嵌入向量。
import requests
from io import StringIO
import pandas as pd
# 获取数据
res = requests.get('https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/sick2014/SICK_train.txt')
# create dataframe
data = pd.read_csv(StringIO(res.text), sep='\t')
data.head()
# 准备句子
sentences = data['sentence_A'].tolist() + data['sentence_B'].tolist()
# 使用更多数据集
urls = [
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2012/MSRpar.train.tsv',
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2012/MSRpar.test.tsv',
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2012/OnWN.test.tsv',
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2013/OnWN.test.tsv',
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2014/OnWN.test.tsv',
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2014/images.test.tsv',
'https://raw.githubusercontent.com/brmson/dataset-sts/master/data/sts/semeval-sts/2015/images.test.tsv'
]
for url in urls:
res = requests.get(url)
data = pd.read_csv(StringIO(res.text), sep='\t', header=None, error_bad_lines=False)
sentences.extend(data[1].tolist() + data[2].tolist())
# 去重
sentences = [word for word in list(set(sentences)) if type(word) is str]
# pip install sentence_transformers
from sentence_transformers import SentenceTransformer
# 初始化 transformer model
model = SentenceTransformer('bert-base-nli-mean-tokens')
# 构建句子嵌入
sentence_embeddings = model.encode(sentences)
sentence_embeddings.shape
移除重复项,留下14.5K个唯一的句子,然后使用sentence-BERT库为每个句子构建密集向量表示。
构建Faiss索引
首先,可以使用IndexFlatL2来构建一个简单的索引。IndexFlatL2计算查询向量与索引中所有向量之间的L2(或欧几里得)距离。这种索引方法简单且准确,但可能不适用于大规模数据集,因为它在搜索时速度较慢。
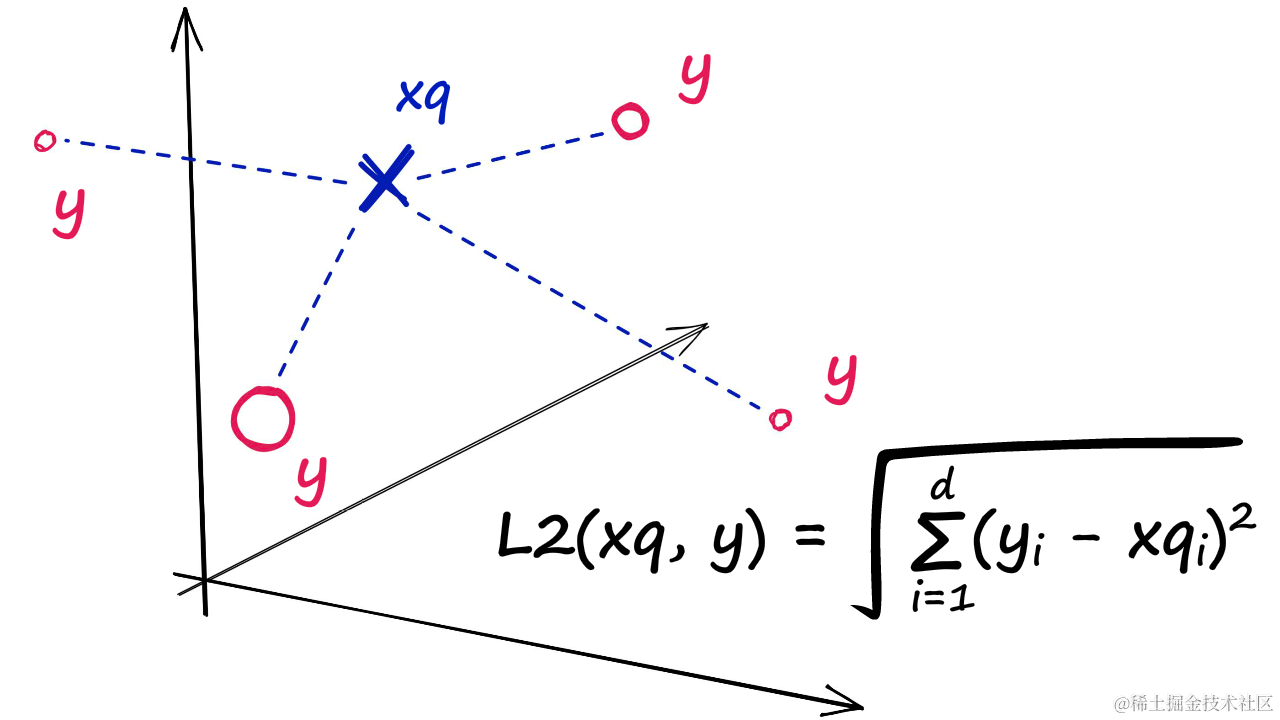
在Python中,使用以下代码初始化IndexFlatL2索引,使用上述获得的嵌入向量维度(768维,句子嵌入的输出大小):
import faiss
d = sentence_embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.is_trained
通常,需要在加载数据之前对其进行训练的索引,使用is_trained方法来检查一个索引是否需要训练。IndexFlatL2是一个不需要训练的索引,所以应该返回False。准备好后,加载嵌入和查询:
index.add(sentence_embeddings)
index.ntotal
k = 4
xq = model.encode(["Someone sprints with a football"])
%%time
D, I = index.search(xq, k) # search
print(I) # [[8306 153 6241 8184]]
# CPU times: user 146 ms, sys: 11.7 ms, total: 158 ms
# Wall time: 7.78 ms
for i in I[0]:
print(sentences[i])
# ('A group of football players is running in the field',
# 'A group of people playing football is running in the field',
# 'Two groups of people are playing football',
# 'A person playing football is running past an official carrying a football')
这返回了与查询向量xq最接近的前k个向量,分别是8306,153,6241和8184。可以看到匹配的内容翻译过来就是——要么是拿着足球奔跑的人,要么是在足球比赛背景中。如果想从Faiss中提取数值向量,也可以这样做。
# we have 4 vectors to return (k) - so we initialize a zero array to hold them
vecs = np.zeros((k, d))
# then iterate through each ID from I and add the reconstructed vector to our zero-array
for i, val in enumerate(I[0].tolist()):
vecs[i, :] = index.reconstruct(val)
vecs.shape # (4, 768)
vecs[0][:100]
速度
IndexFlatL2索引在执行详尽搜索时计算成本高,且不易扩展。这种索引方法要求查询向量与索引中的每个向量逐一比较,对于一个包含14.5K个向量的数据集,每次搜索都会进行大约14.5K次L2距离计算。当数据集规模扩大到1M或10亿个向量时,即使只处理一个查询,搜索时间也会急剧增加。
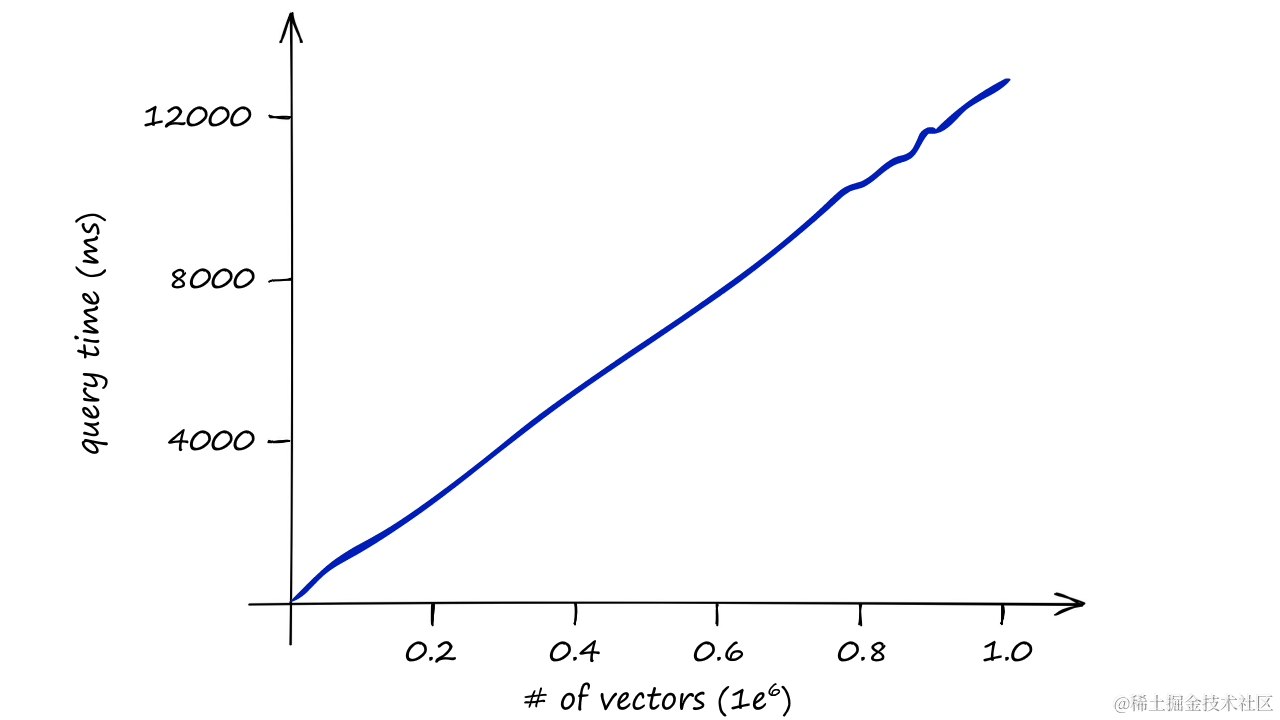
返回结果所需毫秒数(y轴)/ 索引中的向量数(x轴)——仅依靠IndexFlatL2会迅速变得缓慢
例如,假设数据集包含1亿个向量,使用IndexFlatL2进行一次详尽搜索可能需要数小时。这对于实时应用来说是不切实际的。因此,为了提高搜索效率,需要采用更高效的索引策略,如分区索引或向量量化。
分区索引
Faiss提供了一种将索引划分为Voronoi细胞的方法,这是一种有效的策略来加速相似性搜索。通过将向量分配到特定的Voronoi细胞中,我们可以在引入新查询向量时,首先测量它与质心的距离,然后仅在相应的细胞中进行搜索。
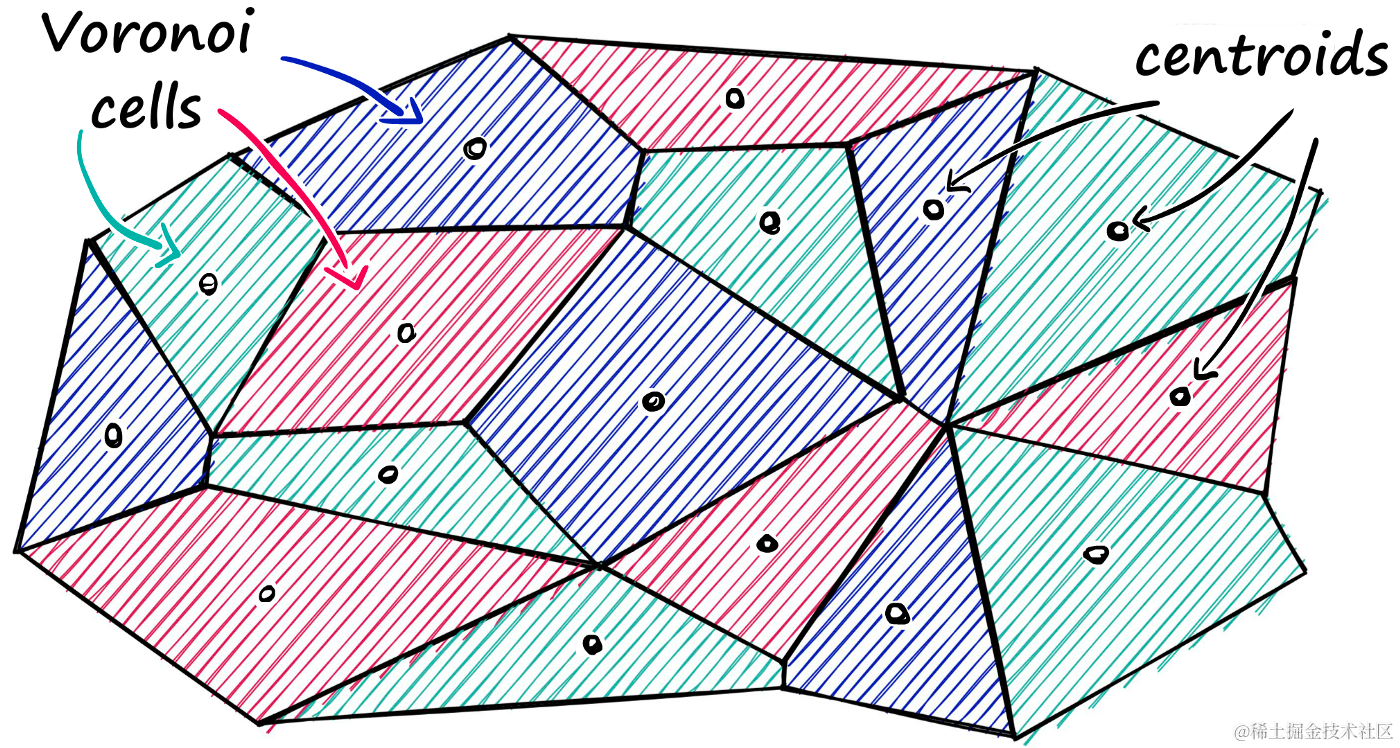
这种方法大大减少了需要比较的向量数量,从而显著加快了搜索速度。例如,如果我们有一个包含1亿个向量的数据集,使用分区索引可以从一个需要比较1亿次的情况减少到只需比较分区中的少量向量。
在Python中,可以通过以下步骤实现:
1. 初始化分区索引:
nlist = 50 # 指定分区数量
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist)
2. 训练和添加数据:
index.is_trained
index.train(sentence_embeddings)
index.is_trained # check if index is now trained
index.add(sentence_embeddings)
index.ntotal # number of embeddings indexed
3. 进行搜索:
%%time
D, I = index.search(xq, k) # search
print(I)
# [[8306 153 6241 8184]]
# CPU times: user 0 ns, sys: 2.11 ms, total: 2.11 ms
# Wall time: 1.4 ms
通过增加nprobe参数,我们可以进一步优化搜索性能。nprobe定义了搜索时考虑的邻近细胞数量,增加它可以帮助找到更准确的近似结果。
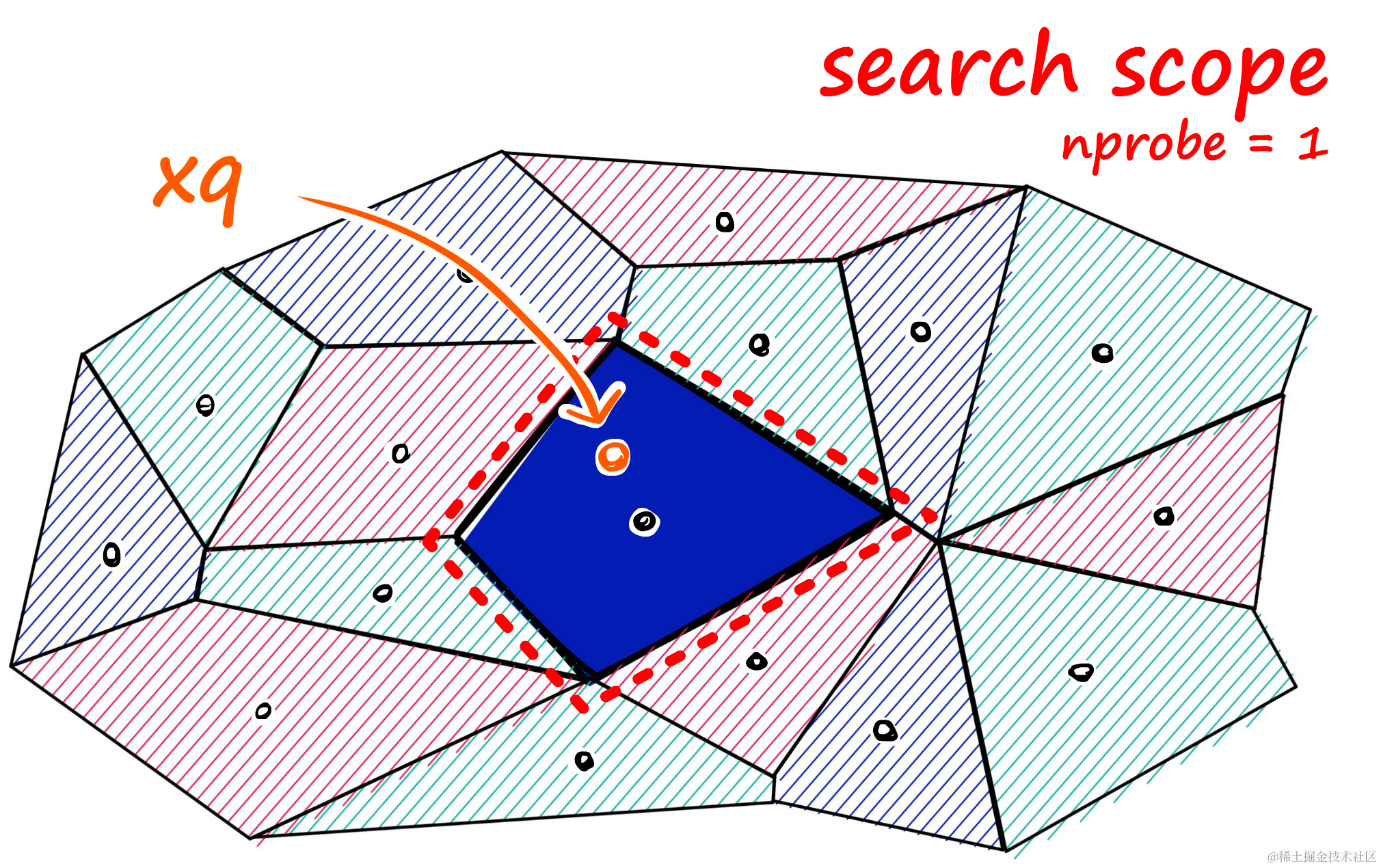
当nprobe == 1时(左图),搜索单个最近的细胞;当nprobe == 8时(右图),搜索八个最近的细胞。
可以轻松实现这个变化,可以通过nprobe参数增加要搜索的邻近细胞的数量。
index.nprobe = 10
%%time
D, I = index.search(xq, k) # search
print(I)
# [[8306 153 6241 8184]]
# CPU times: user 5.8 ms, sys: 0 ns, total: 5.8 ms
# Wall time: 2.84 ms
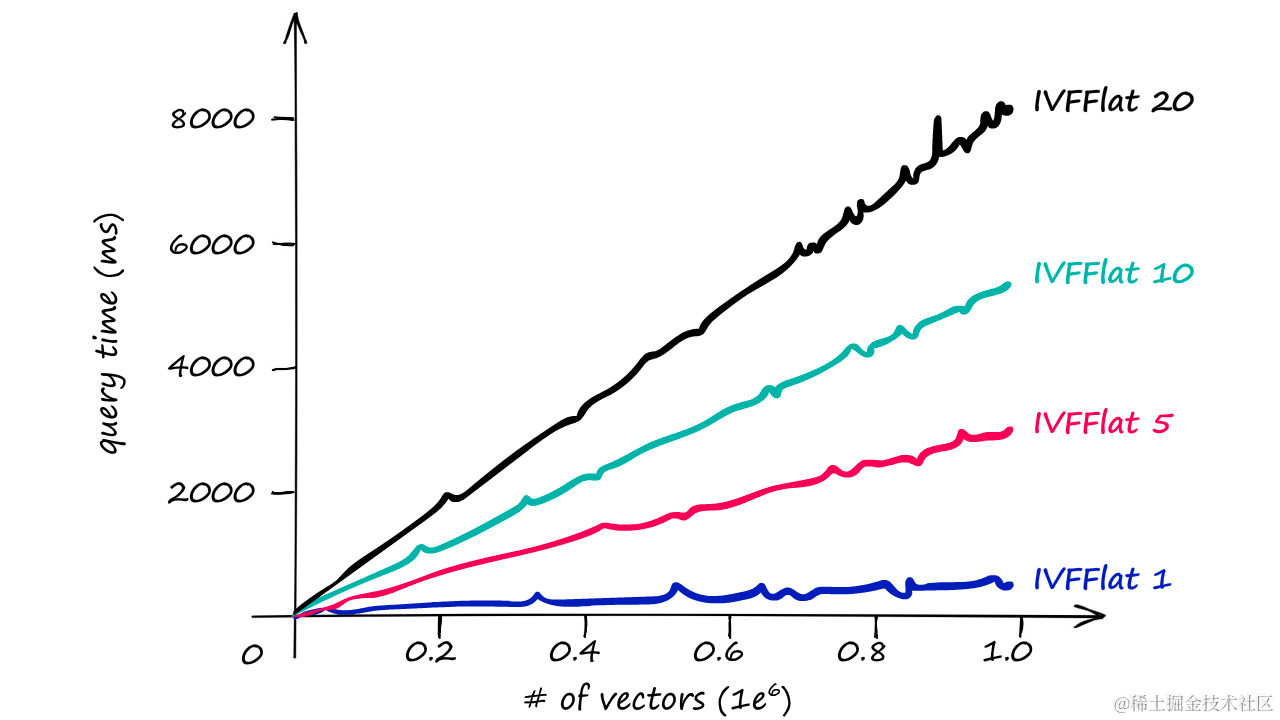
查询时间/向量数量对于具有不同nprobe值的IVFFlat索引——1, 5, 10, 和 20
使用分区索引后,可以看到搜索时间明显减少,同时保持较高的搜索精度。这对于处理大规模数据集尤其重要,因为它允许我们以更快的速度进行近似搜索,而不会牺牲太多准确性。
向量重构
当我们使用分区索引(如IndexIVFFlat)时,原始向量与其在索引中的位置之间不再有直接的映射关系。这意味着如果我们尝试直接重构一个向量,例如使用index.reconstruct(),我们会遇到RuntimeError。
为了能够重构向量,我们需要首先创建一个直接映射,这可以通过调用index.make_direct_map()来实现。这个步骤为每个向量分配一个唯一的ID,使得我们可以根据ID重构原始向量。
以下是如何创建直接映射并重构向量的示例:
index.make_direct_map()
vec = index.reconstruct(7460)[:100] # 重构向量的前100个元素
从那时起,就可以像以前一样使用这些ID来重构向量了。
量化
在处理大规模数据集时,存储和检索完整的向量可能变得非常低效。幸运的是,Faiss提供了一种称为产品量化(Product Quantization,PQ)的向量压缩技术。PQ通过将原始向量分解成多个子向量,并为每个子向量集创建质心,从而实现向量的近似表示。
PQ的三个步骤如下:
- 子向量分割:将原始向量分割成多个子向量。
- 聚类操作:对每个子向量集执行聚类操作,创建多个质心。
- 向量替换:在子向量向量中,将每个子向量替换为其最近的特定质心的ID。
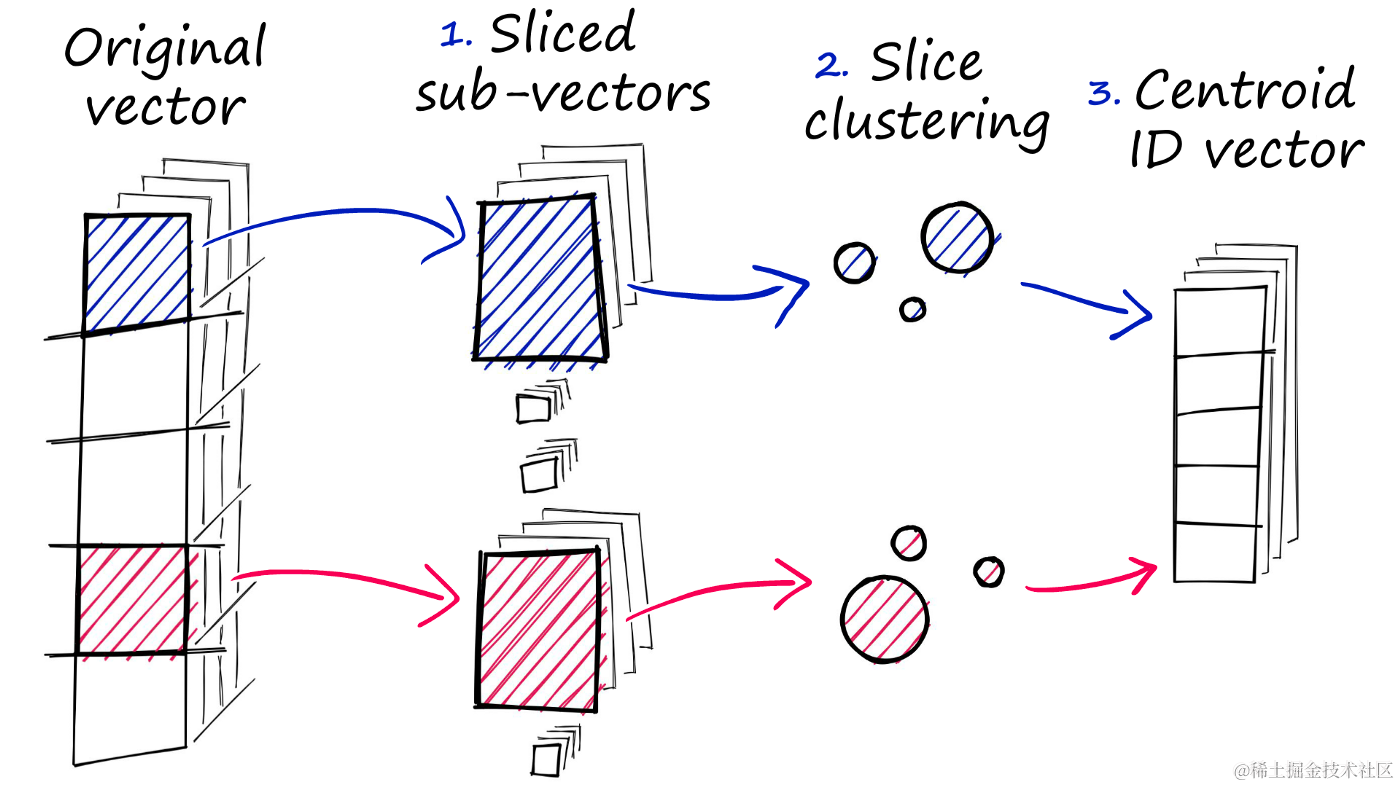
通过使用IndexIVFPQ索引,可以实现这些步骤。在添加嵌入之前,我们需要训练索引,并且需要在索引中添加数据。
以下是如何使用PQ索引的示例:
m = 8 # 每个压缩向量的质心数量
bits = 8 # 每个质心的比特数
quantizer = faiss.IndexFlatL2(d) # 保持相同的L2距离flat索引
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, bits)
# 训练索引
index.train(sentence_embeddings)
# 添加向量
index.add(sentence_embeddings)
现在准备开始使用新索引进行搜索。
index.nprobe = 10 # align to previous IndexIVFFlat nprobe value
%%time
D, I = index.search(xq, k)
print(I)
# [[ 153 2912 8306 8043]]
# CPU times: user 2.95 ms, sys: 96 µs, total: 3.05 ms
# Wall time: 2.01 ms
通过使用PQ,可以显著减少存储空间和搜索时间,同时保持足够的搜索精度。这对于处理大规模数据集和实现高效的相似性搜索至关重要。
速度还是精度
通过添加产品量化(PQ),我们成功地将IVF搜索时间从约7.5毫秒减少到约5毫秒,这在小数据集上可能看起来微不足道,但在处理大规模数据集时,这个性能提升是非常显著的。
虽然返回的结果顺序略有不同,但我们的优化措施仍然能够提供高度相关的搜索结果,如:
[f'{i}: {sentences[i]}' for i in I[0]]
这些结果虽然与原始搜索有所不同,但仍然保持了高度的相关性,如:
- ‘153: A group of people playing football is running in the field’
- ‘2912: A group of football players running down the field.’
- ‘8306: A group of football players is running in the field’
- ‘8043: A football player is running past an official carrying a football’
这种权衡显示了在实际应用中,可以在保持搜索速度的同时,接受一定程度的搜索精度损失。这对于需要快速响应的应用场景尤为重要。
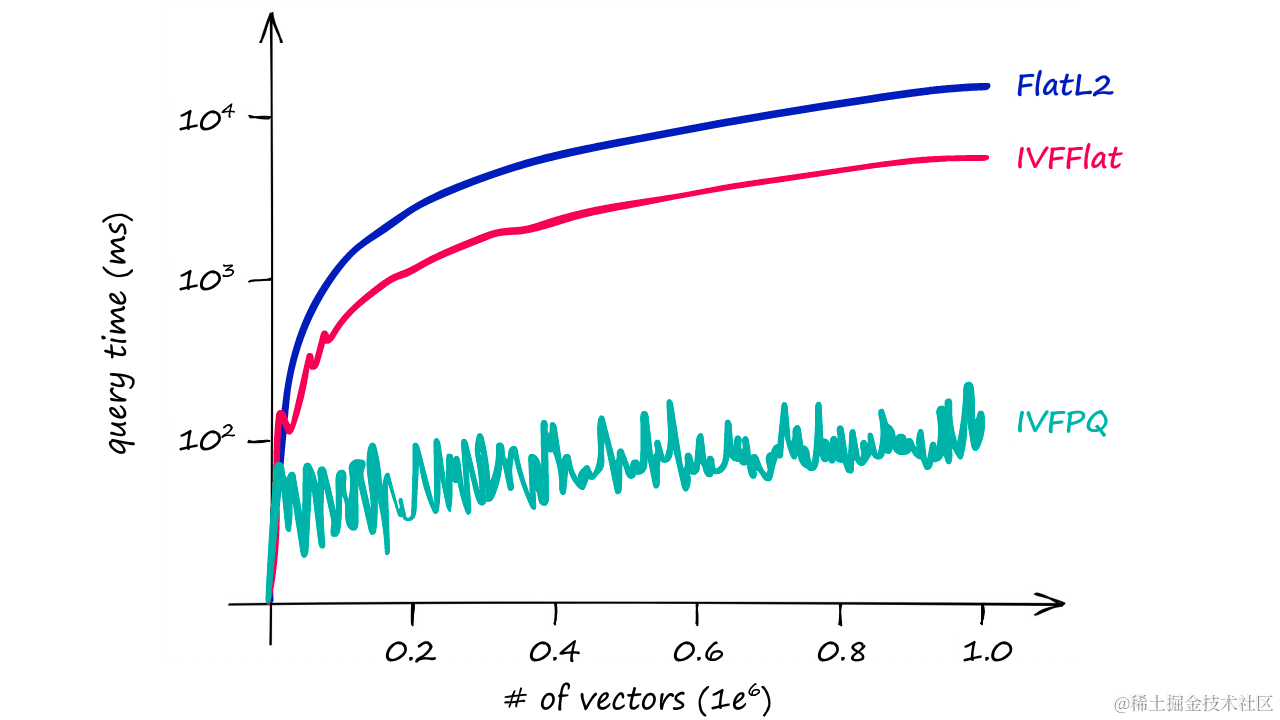
查询时间/向量数量
上图显示了随着索引大小的增加,不同索引策略下的查询时间差异。这表明,尽管存在精度损失,PQ和IVF的结合仍然能够提供高效的搜索解决方案。
总结
本文介绍了如何使用Faiss库来构建高性能的相似性搜索索引。探讨了Faiss的核心概念、主要功能以及如何安装和使用这个库。
此外,还探讨了如何通过添加产品量化(PQ)和IVF(Inverted Indexed Vector File)分区索引来进一步优化搜索速度。虽然这些优化可能以一定程度的搜索精度为代价,但它们在处理大规模数据集时提供了显著的速度提升。
最后,强调了Faiss在处理高维数据和提高搜索效率方面的潜力。无论是数据科学家还是机器学习工程师,Faiss都是一个强大的工具,可以帮助我们在相似性搜索任务中实现快速和准确的结果。
参考
- https://www.pinecone.io/learn/series/faiss