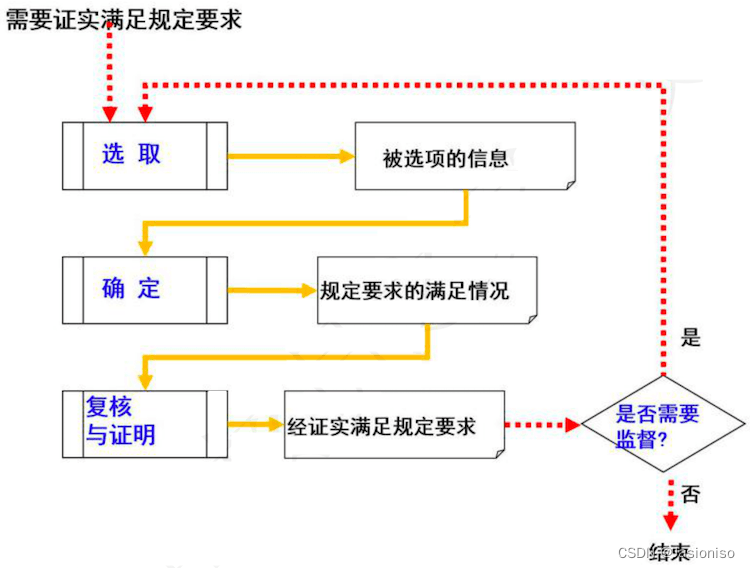
EfficientAD
- 简介
- 方法
- 高效的patch描述
- PDN
- 教师pretraining
- 轻量级的师生模型
- 逻辑异常检测
- 异常图像的标准化
- 实验
- 局限性

EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies
EfficientAD:毫秒级延迟的准确视觉异常检测, WACV 2024
paper:https://arxiv.org/pdf/2303.14535v3
GitHub:(无官方code)
https://github.com/nelson1425/EfficientAD(个人推荐)
https://github.com/openvinotoolkit/anomalib/tree/main/src/anomalib/models/image/efficient_ad(paper with code推荐)
摘要:
在图像中检测异常是一项重要任务,尤其是在实时计算机视觉应用中。在本研究中,我们专注于计算效率,并提出了一种轻量级的特征提取器,该提取器在现代GPU上处理图像的时间不到一毫秒。随后,我们采用学生-教师方法来检测异常特征。我们训练一个学生网络,使其能够预测正常(即无异常)训练图像的提取特征。在测试时,通过学生网络无法预测其特征来检测异常。我们提出了一种训练损失,阻止学生模仿教师特征提取器超出正常图像的范围。这使得我们能够大幅降低学生-教师模型的计算成本,同时提高异常特征的检测能力。
此外,我们还解决了检测涉及正常局部特征无效组合的挑战性逻辑异常问题,例如物体错误排序。我们通过高效地结合一个分析图像全局的自动编码器来检测这些异常。我们评估了我们的方法,称为EfficientAD,在来自三个工业异常检测数据集集合的32个数据集上。EfficientAD为异常的检测和定位设定了新的标准。在延迟为两毫秒、吞吐量为每秒六百张图像的情况下,它能够快速处理异常。结合其低错误率,这使其成为现实世界应用的经济解决方案,并为未来的研究提供了坚实的基础。
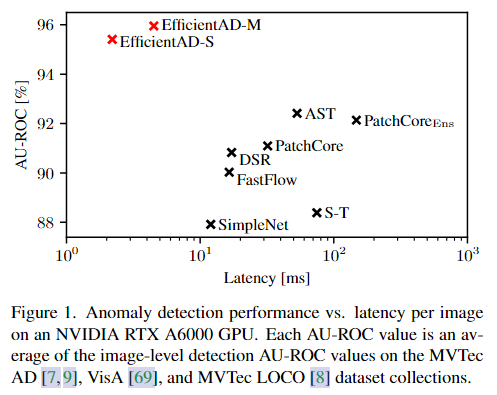
图 1. NVIDIA RTX Aϋυυυ GPU 上的异常检测性能与每个图像的延迟。每个 AU-ROC 值是 MVTecAD、VisA 和 MVTec LOCO 数据集集合上图像级检测 AU-ROC 值的平均值。
简介
提出了 EfficientAD,在工业异常检测领域实现了性能和推理运行时间的新标准。
先引入了一种高效的网络架构,可以在现代 GPU 上以不到一毫秒的速度计算表达特征。
使用学生-教师方法,训练学生网络来预测教师网络(教师网络经过预训练)在正常(即无异常)训练图像上计算的特征。由于学生没有接受过异常图像方面的训练,因此通常无法在这些方面模仿老师。因此,教师和学生的输出之间存在较大距离,因此可以在测试时检测到异常情况。
为了进一步增强这种效果,我们以训练损失的形式提出损失引起的不对称性,阻碍了学生超越正常图像模仿老师。这种损失不会影响测试时的计算成本,也不会限制架构设计。它使我们能够为学生和教师使用高效的网络架构,同时改进异常特征的检测。
一个具有挑战性的问题是违反有关 正常对象的位置、大小、排列等的逻辑约束。 为了解决这个问题,EfficientAD 包含一个自动编码器,可以学习训练图像的逻辑约束并在测试时检测违规行为。我们将自动编码器与学生-教师模型有效地集成。提出了一种通过在合并自动编码器和学生-教师模型的检测结果之前校准它们的结果来提高异常检测性能的方法。
贡献总结如下:
- 大幅提高了工业基准上异常检测和定 位的技术水平,延迟时间为 2 毫秒,吞吐量每秒超过 600 张图像
- 提出了一种高效的网络架构,可以将特征提取速度提高一个数量级
- 引入了一种训练损失,可以显着提高学生-教师模型的异常检测性能,而不影响其推理运行时间
- 实现了基于自动编码器的有效逻辑异常检测,并提出了一种将检测结果与学生-教师模型的检测结果校准组合的方法。
方法
高效的patch描述
PDN
使用深度大大减少的网络作为特征提取器。它仅由 四个卷积层组成,如图 2 所示。每个输出神经元都有一个 33×33 像素的感受野,因此每个输出 特征向量描述一个 33×33 的块。由于这种明确 的对应关系,我们将该网络称为补丁描述网络 (PDN)。 PDN 是完全卷积的,可以应用于可 变大小的图像,以在单次前向传递中生成所有特征向量。
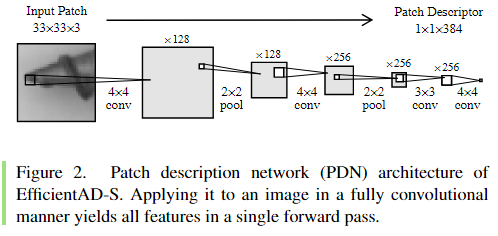
Fig2.EfficientAD-S 的补丁描述网络 (PDN) 架构。以完全卷积方式将其应用于图像可以在一次前向传递中产生所有特征。
通过所提出的 PDN,我们能够在 NVIDIA RTX A6000 GPU 上在不到 800 μs 的时间内获得尺寸 为 256×256 的图像的特征。
教师pretraining
为了使 PDN 生成富有表现力的特征,将深度预训练分类网络提炼到其中。使用与 WideResNet-101中的 PatchCore相同的预训练特征。通过最小化PDN输出与从预训练网络中提取的特征之间的均方差来训练来自 ImageNet的图像。
PDN 还有另一个好处。根据设计,PDN 生成的特征向量仅取决于其各自 33×33 块中的像素。预训练分类器的特征向量表现出对图像其他部分的远程依赖性。 如图 3 所示,以 PatchCore 的特征提取器为例。 PDN 定义明确的感受野确保图像某一部分的异常 不会触发其他远处部分的异常特征向量,从而损害异常的定位。
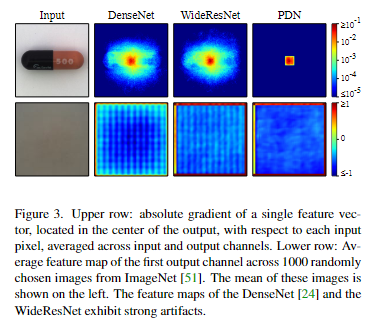
Fig3. 上:位于输出中心的单个特征向量相对于每个输入像素的绝对梯度,在输入和输出通道上取平 均值。
下:来自 ImageNet的 1000 张随机选择图像的第一个输出通道的平均特征图。这些图像的平均值显示在左侧。 DenseNet 和 WideResNet 的特征图表现出很强的伪影。
轻量级的师生模型
PDN这种轻量级的学生-教师对缺乏以前的方法所使用的技术来提高异常检测性能。因此,我们引入了训练损失,可以显着改善异常 检测,而不会影响测试时的计算要求。
我们的目标是向学生展示足够的数据,以便其能够在正常图像上充分模仿教师,同时避免泛化到异常图像。与 Online Hard Example Mining (在线硬样本挖掘)类似,我们因此将学生的损失限制在图像中最相关的部分。这些是学生目前模仿老师最少的patch。 提出了一种硬特征损失,它只使用损失最高的输出元素进行反向传播。
将每个元组 (c, w, h) 的平方差计算为(教师 T 和学生 S 应用于训练图像 I)
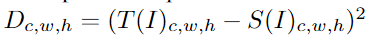
基于挖掘因子phard ∈ [0, 1],然后我们计算 D 元素的 phard分位数。 给定 phard分位数 dhard ,计算训练损失 Lhard 作为所有 Dc,w,h ≥ dhard的均值。将 phard设置为零会产生原始的 S-T 损失。在实验中,我们将 phard设置为 0.999,这相当于平均使用 D 的三个维度中每个维度的 10% 的值进行反向传播。图 4 可视化了 phard = 0.999 时硬特征损失的影响。

Fig4. 训练期间由硬特征损失生成的随机选取的损失掩码。掩模像素的亮度指示相应特征向量的多少维被选择用于反向传播。学生网络已经在背景上很好地模仿了老师,因此专注于学习不同旋转螺钉的特征。
除了硬特征损失之外,我们在训练 期间使用损失惩罚,进一步阻止学生在不属于正 常训练图像的图像上模仿老师。在标准 S-T 框架 中,教师在图像分类数据集上进行预训练,或者 它是此类预训练网络的精炼版本。学生没有接受 预训练数据集的训练,而仅接受应用程序的正常 图像的训练。我们建议还使用教师在训练期间预训练的图像来训练学生模型。具体来说,我们在每个训练步骤中从预 训练数据集中(在我们的例子中为 ImageNet)中 采样随机图像P。我们将学生的损失计算为
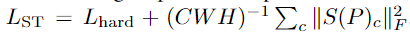
这种惩罚 会阻碍学生将对老师的模仿推广到分布外的图像。
逻辑异常检测
什么是逻辑异常:
逻辑异常不仅仅是物理上的缺陷(如划痕、凹陷等),而是涉及到产品的组装错误、部件缺失或位置错误等问题。这要求IAD算法不仅要识别图像上的异常模式,还需要理解产品的组装逻辑或结构逻辑。
逻辑IAD更加依赖于全局特征的提取,因为识别逻辑异常需要对整个产品或其组成部分的全局布局和关系有一个综合理解。这与那些主要依赖局部特征来识别物理缺陷的传统IAD方法有所不同。
使用自动编码器来学习训练图像的逻辑约束并 检测对这些约束的违反。图 5 描述了 EfficientAD 的异常检测方法。它由上述的学生-教师对和一个自动编码器组成。自动编码器经过训练来预测教师的输出。
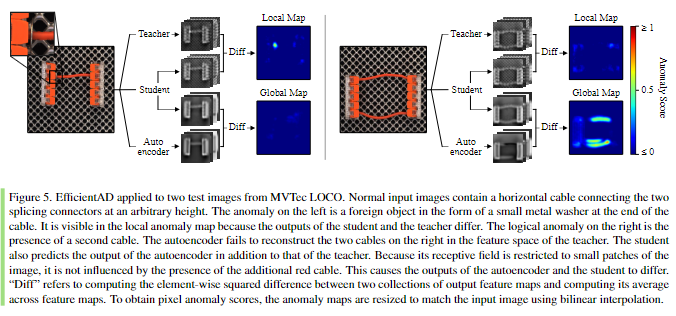
Fig5.EfficientAD应用于MVTec LOCO的两个测试图像。正常输入图像包含一个水平电缆,连接任意高度的两个拼接连接器。左边的异常是一个外来物体,其形式是一根小金属在电缆的末端。在本地异常图中可见,因为学生和教师的输出不同。右边的逻辑异常是第二个电缆的存在。自动编码器无法在教师的特征空间的右侧重建两条电缆。除了老师之外,学生还预测自动编码器的输出。因为它的感受野仅限于图像的小块,所以它不受附加红色电缆的存在的影响。这导致自动编码器和学生的输出不同。
”Diff”是指计算两个输出特征图集合之间的元素平方差异,并计算其跨特征图的平均值。为了获得像素异常分数,使用双线性插值调整异常图以匹配输入图像。
使用标准的卷积自动编码器,包括编码器中的跨步卷积和解码器中的双线性上采样。与基于patch的学生相比,自动编码器必须通过 64 个潜在维度的 bottleneck 对完整图像进行编码和解码。对于具有逻辑异常的图像,自动编码器通常无法生成正确的潜在代码来重建教师特征空间中的图像。然而,它的重建在正常图像上也存在缺陷,因为自动编码器通常难以重建细粒度模式。这是图 5 中背景网格的情况。在这些情况下,使用教师输出和自动编码器重建之间的差异作为异常图会导致误报检测。
我们将学生网络的输出通道数量加倍,并训练它来预测自动编码器的输出以及教师的输出
学生的附加损失: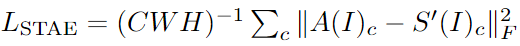
学生学习自动编码器在正常图像上的系统重建误差,例如模糊重建。同时,它不会学习异常的重建错误,因为这些不是训练集的一部分。这使得自动编码器的输出和学生的输出之间的差异非常 适合计算异常图。
与学生-教师对类似,异常图是两个输出之间的平方差,跨通道平均。我们将 异常图称为全局异常图,并将由学生-教师对生成 的异常图称为局部异常图。我们对这两个异常图进行平均以计算组合异常图,并使用其最大值作为图像级异常得分。因此,组合异常图包含学生-教师对的检测结果和自动编码器-学生对的检测结果。在这些检测结果的计算中共享学生的隐藏层使方法能够保持较低的计算要求,同时能够检测结构和逻辑异常。
异常图像的标准化
局部和全局异常图必须先标准化为相似的比例,然后再对其进行平均以获得组合异常图。这对于仅在其中一张 map 中检测到异常的情况非常重要,否则 一张 map 中的噪声可能会使另一张 map 中的准确检测在组合 map 中无法辨别。
为了估计正常图像中噪声的规模,我们使用验证图像,即训练集中未见过的图像。对于两种异常图类型中 的每一种,我们计算验证图像上所有像素异常分数的集合。然后,为每个集合计算两个 p-分位数:qa 和 qb ,分别表示 p = a 和 p = b。我们确定一个线性变换,将 qa 映射到异 常分数 0,将 qb 映射到分数 0.1。
在测试时,局部和全局异常图通过各自的线性变换进 行归一化。通过使用分位数,归一化对于正常图像上的异常分数的分布变得鲁棒,该分布可能因场景而异。qa 和 qb之间的分数是否呈正态分布或混合高斯分布或遵循其他分布对归 一化没有影响。
我们的实验包括对 a 和 b 值的 消融研究。映射目标值 0 和 0.1 的选择对异常检测指标没有影响,选择 0 和 0.1 是因为它们生成适合标准零到一颜色比例的maps。
实验
数据集:MVTec AD、VisA 、MVTec LOCO
比较方法:AST、DSR、Fast-Flow、GCAD、PatchCore、SimpleNet、 S–T
评估指标:AU-ROC、AU-PRO、AU-sPRO
表 1 报告了每种方法的总体异常检测性能。 EfficientAD 实现了强大的异常图像级检测和像素级定位。可靠地定位图像中的异常可提 供可解释的检测结果,并允许发现检测中的虚假 相关性。它还支持灵活的后处理,例如根据大小排除缺陷分割。
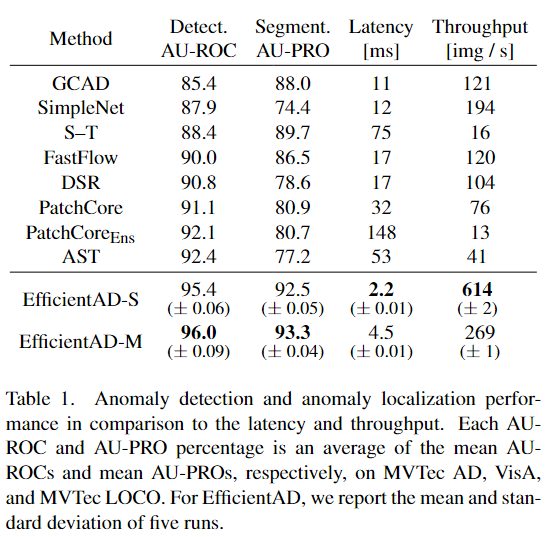
Tab1. 异常检测和异常定位性能与延迟和吞吐量的比较。每个 AU-ROC 和 AU-PRO 百分比分别是 MVTec AD、VisA 和 MVTec LOCO 上平均 AU-ROC 和平均 AU-PRO 的平均值。对于 EfficientAD,我们报告五次运行的平均值和标准差。
表 2 将总体异常检测性能分解为 三个数据集集合。结果表明,EfficientAD 在逻辑异常和结构异常方面的性能在 MVTec LOCO 上同等领先。
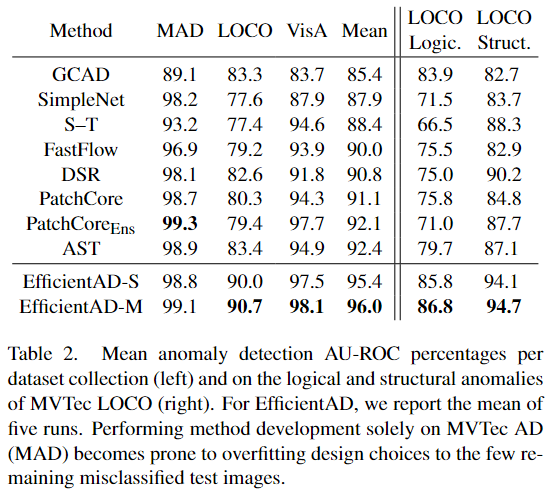
Tab2. 每个数据集集合的平均异常检测 AU-ROC 百分比 (左)以及 MVTec LOCO 的逻辑和结构异常 (右)。对于 EfficientAD,我们报告五次运行的平均值。仅在 MVTec AD(MAD) 上执行方法开发很容易导致设计选择过度拟合少数剩余的错误分类测试图像。
在表 3 中,我们评估了 EfficientAD 对不同超参数的鲁棒性。此外,还测量了推理过程中每种方法的计算成本。
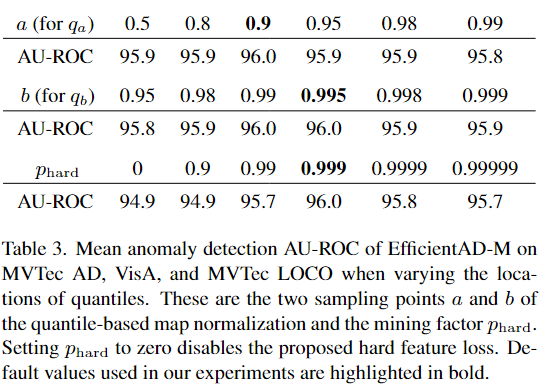
Tab3. 当改变分位数位置时,EfficientAD-M 在 MVTec AD、VisA 和 MVTec LOCO 上的平均异常检测 AU-ROC。这些是基于分位数的map归一化和挖掘因子 phard 的两个采样点 a 和 b。将 phard 设置为零会禁用所提出的硬特征丢失。我们实验中使用的默认值以粗体突出显示。
如上所述,参数数量可能是卷积架构延迟和吞吐量的误导性代理指标,因为它没有考虑卷积输入特征图的分辨率,即前向传递中使用参数的频率。 同样,浮点运算(FLOP)的数量可能会产生误导,因为它没有考虑并行计算的容易程度。为了透明起见,我们在补充材料中报告了参数数量、 FLOP 数量以及每个方法的内存占用量。
在这里,我们重点关注与异常检测应用程序最相关的指标:延迟和吞吐量。
我们测量批量大小为 1 时 的延迟和批量大小为 16 时的吞吐量。表 1 报告 了每种方法在 NVIDIA RTX A6000 GPU 上的测量结果。图 6 显示了我们实验设置中每个 GPU 上每种方法的延迟。
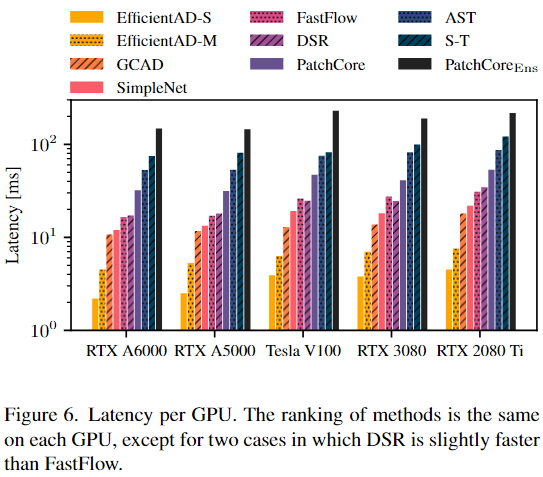
Fig6. 每个 GPU 的延迟。每个 GPU 上的方法排名 相同,但 DSR 比 FastFlow 稍快的两种情况除外。
在图 7 中,我们显示了 EfficientAD 在 VisA 数据集集合上随机采样的定性结果。

Fig7. EΩcientAD onVisA 的非精选定性结果。对于 12 个场景中的每一个,我们都展示了随机采样的缺陷图像、 地面实况分割掩模以及 EΩcientAD-M 生成的异常图。
在表 4 和表 5 所示的消融研究中检查 了 EfficientAD 组件的效果。
评估了两个提出的损失项用于训练学生-教师对的效果。在表 4 中,硬特征损失将异常检测 AU-ROC 提高了 1.0%。 仅此一项改进就大于或等于表 1 中 FastFlow、DSR、PatchCore、PatchCore Ens 和 AST 连续行之间的每个改进幅度。
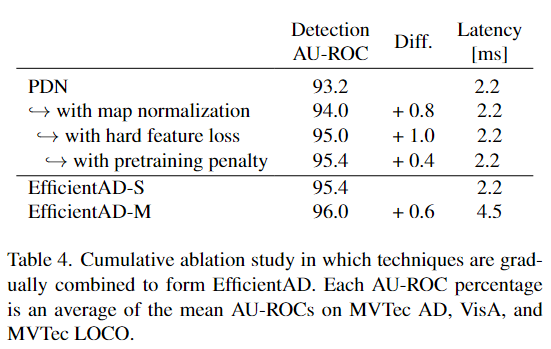
Tab4. 累积消融研究,其中技术逐渐组合以形成 EfficientAD。每个 AU-ROC 百分比是 MVTec AD、 VisA 和 MVTec LOCO 上平均 AU-ROC 的平均值。
学生对预训练图像的惩罚进一步提高了异常检测性能。值得注意的是,所提出的地图归一化、硬特征损失和预训练惩罚使 EfficientAD 的计算要求保持较低,同时创造了可观的裕度。异常检测性能。
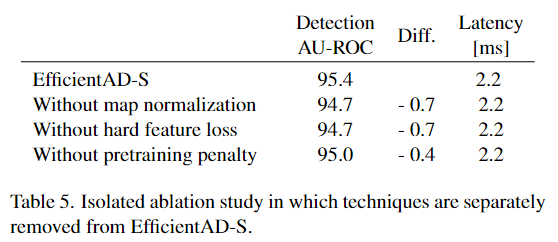
Tab5. 单独的消融研究,其中的技术是从 EfficientAD-S 中单独删除的。
对于没有提出的 基于分位数的图归一化的实验,我们使用相反,基于高斯的map归一化作为基线。计算线性变换参数,使得验证集上的像素异常得分的平均值为零,方差为一。此基线标准化对验证异常分数的分布很敏感,该分数可能因场景而异。基于分位数的归一化与 qa 和 qb 之间的分数如何分布无关,并且表现明显优于基线。
局限性
学生-教师模型和自动编码器旨在检测不同类型的异常。自动编码器检测逻辑异常, 而学生-教师模型检测粗粒度和细粒度的结构异 常。然而,细粒度的逻辑异常仍然是一个挑战,例如,螺丝太长了两毫米。为了检测这些,从业者必须使用传统的计量方法。至于与其他最近的异常检测方法相比的局限性:与基于 kNN 的方法相比,我们的方法需要训练,特别是让自动编码器学习正常图像的逻辑约束。在我们的实验设置中这需要二十分钟。