前言
日积跬步,能至千里。
水平有限,不足之处望请斧正。
选择题
1、以下程序运行后的输出结果是( )
#include <stdio.h>
void fun(char **p) {
int i;
for(i = 0; i < 4; i++) {
printf("%s", p[i]);
}
int main() {
char *s[6] = {"ABCD", "EFGH", "IJKL", "MNOP", "QRST", "UVWX"};
fun(s);
printf("\n");
return 0;
}
A:ABCDEFGHIJKL
B:ABCD
C:AEIM
D:ABCDEFGHIJKLMNOP
char *s[6]:
s是字符指针数组,每个元素是char*。
"ABCD", "EFGH"等都是字符串常量,会被看作char*的指针,存放在常量区。
fun(s):
数组传参时降维成指向其首元素的指针,即char**。
fun内的p[i]会拿到s[0], s[1], ..., s[3],即"ABCD", "EFGH", "IJKL", "MNOP"的地址。按%s的格式打印。
正确答案:D
#字符串常量(字符串字面量)
int main()
{
char* str;
str = "a string";
printf("%s\n", str);
return 0;
}
str:字符指针,存于栈区"a string":字符串常量,存于常量区
用一双引号括起来的一串字符序列,在C语言中被看作 字符串常量。
C语言会将字符串常量看作只读的字符数组,所以它也是char*的指针。如,
printf("%s\n", "test");
调用printf时,会传递"test"的地址,即常量区中存储字符t的内存单元的地址。
2、数组 a 的定义为: int a[3][4]; 下面哪个不能表示 a[1][1] ( )
A:*(&a[0][0]+5)
B:*(*(a+1)+1)
C:*(&a[1]+1)
D:*(a[1]+1)
int a[3][4]:
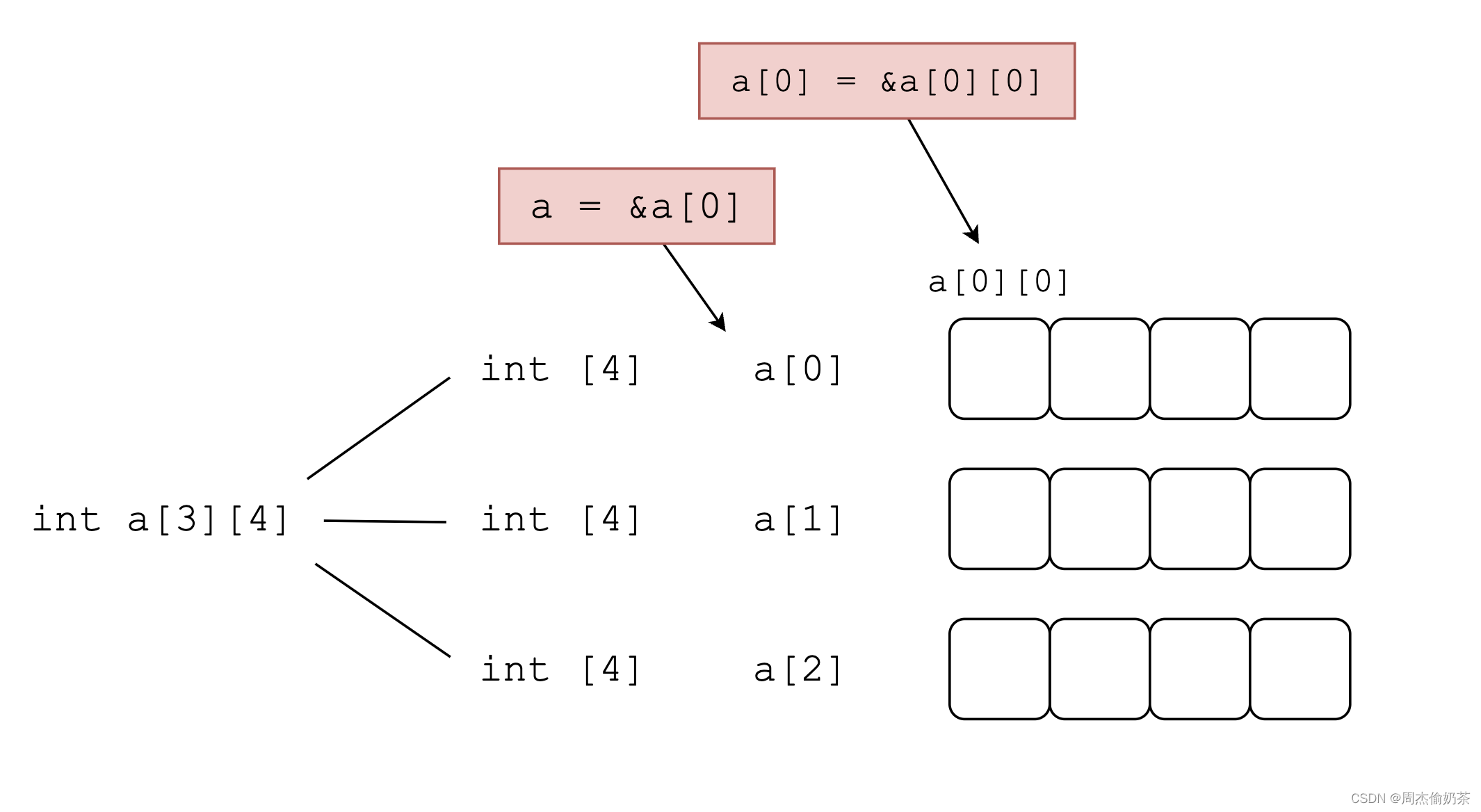
a是整个数组(int [3][4])的数组名,a = &a[0],类型为int (*)[4]
a[0]是第0行(int [4])的数组名,a[0] = &a[0][0],类型为int*
A:&a[0][0] == a[0],a[0]类型为int*,又因为数组是连续存储,所以*(a[0] + 5) == a[1][1]。可以表示。
B:a = &a[0],类型为int (*)[4],&a[0] + 1 = &a[1],*(&a[1]) == a[1]
a[1] = &a[1][0],类型为int*,&a[1][0] + 1 == &a[1][1],*(&a[1][1]) == a[1][1]。可以表示。
C:&a[1] = a + 1,类型为int (*)[4],&a[1] + 1 == &a[2],*(&a[2]) == a[2]。无法表示。
D:a[1] = &a[1][0],类型为int*,&a[1][0] + 1 == &a[1][1],*(&a[1][1]) == a[1][1],可以表示。
正确答案:C
总结
数组名是首元素地址,如对于二维数组int a[3][4]
a = &a[0]a[0] = &a[0][0]
3、void (*s[5])(int)表示意思为( )
A:函数指针
B:函数指针数组
C:数组指针函数
D:语法错误
老方法:通过优先级判断名字和谁结合,要么是数组,要么是指针,剩下的就是数组元素类型或指针指向的数据类型。
优先级:[] > *。
s和[5]结合,代表这是数组。剩下的void (*)(int)代表数组的元素是无返回值、有一个int参数的函数指针。所以这是函数指针数组。
正确答案:B
总结
通过优先级判断名字和谁结合,要么是数组,要么是指针,剩下的就是数组元素类型或指针指向的数据类型。
4、在64位操作系统上,下面程序返回结果是( )
int main() {
int *k[10][30];
printf("%d\n", sizeof(k));
return 0;
}
A:4
B:8
C:1200
D:2400
64位操作系统,内存单元的编号有64位二进制数来描述,所以指针的大小为64bits == 8bytes。300 * 8 = 2400。
正确答案:D
总结
指针大小:32位下4bytes,64位下8bytes
5、假设函数原型和变量说明如下,则调用合法的是( )
void f(int **p);
int a[4]={1,2,3,4};
int b[3][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
int *q[3]={b[0],b[1],b[2]};
A:f(a);
B:f(b);
C:f(q);
D:f(&a);
f需要int**类型的参数。
A:a = &a[0],类型为int *。不符合。
B:b = &b[0],类型为int (*)[4]。不符合。
C:q = &q[0],类型为int **。符合。
D:&a是a的地址,类型为int (*)[4]。不符合。
总结
数组名是首元素地址,两个例外:
&数组名取整个数组的地址sizeof(数组名):计算整个数组的大小
编程题
1. 第一个只出现一次的字符
描述
在一个长为 n 字符串中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1(需要区分大小写).(从0开始计数)
数据范围:100000≤n≤10000,且字符串只有字母组成。
要求:空间复杂度 O(n),时间复杂度O(n)
示例1
输入:
"google"
返回值:
4
示例2
输入:
"aa"
返回值:
-1
思路
出现次数……这不就是我们之前提过的hash映射的思想嘛:构建哈希表,统计每个字符出现次数,最后再次遍历,第一个出现次数为1的就是要找的。
参考代码
class Solution {
public:
int FirstNotRepeatingChar(string str) {
vector<int> hash(128);
for(auto e : str)
{
++hash[e];
}
for(size_t i = 0; i < str.size(); ++i)
{
if(hash[str[i]] == 1) return i;
}
return -1;
}
};
2. 判定字符是否唯一
实现一个算法,确定一个字符串 s 的所有字符是否全都不同。
示例 1:
输入: s = "leetcode"
输出: false
示例 2:
输入: s = "abc"
输出: true
限制:
0 <= len(s) <= 100s[i]仅包含小写字母
思路
同样的hash思想也能解决:某个字符出现了两次就代表有相同的字符。
参考代码
class Solution {
public:
bool isUnique(string astr) {
vector<int> hash(128);
for(auto e : astr)
{
++hash[e];
if(hash[e] > 1) return false;
}
return true;
}
};
总结
查找还得hash
#字符串常量
今天的分享就到这里了
这里是培根的blog,期待与你共同进步!
下期见~