一 前言
上篇实现了数据库的持久化,就是一个质的飞跃,虽然代码不复杂,但是对没有这方面经验者来说,还是意思的,下一步就是要完成另外一个飞跃,将存储的数据结构采用B+树的形式来保存。在改造之前,还有些准备工作,一是将代码改动下,引入游标这个概念,二是对B+树的结构和原理再做一次梳理,然后才能进入代码开发阶段。
二 游标cursor
游标这个概念,再这里面可以抽象认为为指向一行的指针,通过这个指针我们可以做插入或查询、以及移动到下一行row等。 定义结构如下:
typedef struct {
Table* table;
uint32_t row_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;定义内容比较简单,游标归属的表,归属的行号、是否为表的结尾,遍历时候使用,表结束后退出查询等。
定义好游标,第一个想法可能是如何创建游标,由于游标可以用来遍历之用,我们在一些语言的集合遍历的时候也有定义类似Iter 之类的,和游标类似,一般通过集合的start()行数创建,创建指向第一个元素,这里面的游标也是类似,start创建即指向第一个游标,end指向最后一个元素。
Cursor* table_start(Table* table) {
Cursor* cursor = ( Cursor* )malloc(sizeof(Cursor));
cursor->table = table;
cursor->row_num = 0;
cursor->end_of_table = (table->num_rows == 0);
return cursor;
}
Cursor* table_end(Table* table) {
Cursor* cursor =( Cursor* ) malloc(sizeof(Cursor));
cursor->table = table;
cursor->row_num = table->num_rows;
cursor->end_of_table = true;
return cursor;
}有了这个定义,我们就可以简化定位一行的操作,原来的核心行数:
void* row_slot(Table* table, uint32_t row_num)可以改成才有游标的形式:
void* cursor_value(Cursor* cursor)里面的内容也需要按照数据结构做调整:
void *row_slot(Cursor* cursor)
{
// 行号通过游标获取
uint32_t row_num = cursor->row_num;
uint32_t page_num = row_num / ROWS_PER_PAGE;
// 页面参数通过游标获取到table后再获取pager
void *page = get_page(cursor->table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}对于游标的递增,可以通过下面行数实现:
void cursor_advance(Cursor* cursor) {
cursor->row_num += 1;
// 如果行数达到了表的最大行数,设置游标的表结束标志
// 循环时候可以根据这个判断来决定是否结束
if (cursor->row_num >= cursor->table->num_rows) {
cursor->end_of_table = true;
}
}对于我们原来的核心代码中的执行逻辑也要进行改动了,查询循环原来是按照行数遍历现在改成游标的方式,只所以用游标抽象一层,是因为我们通过游标可以封装后面的B+树的遍历,而我们原来的遍历是和表的行紧密绑定的,这里面又包含了将容易改变的部分要抽离出来,整个架构依赖于抽象实现,抽象的具体实现,就可以根据需要灵活改动,而上层架构不受到影响,秒啊!
ExecuteResult execute_select(Statement *statement, Table *table)
{
Row row;
Cursor *cursor = table_start(table);
// for (uint32_t i = 0; i < table->num_rows; i++) {
// deserialize_row(row_slot(table, i), &row);
// print_row(&row);
// }
// 直到游标是最后标记则结束
while (!(cursor->end_of_table)) {
deserialize_row(cursor_value(cursor), &row);
print_row(&row);
// 游标向下移动一行
cursor_advance(cursor);
}
return EXECUTE_SUCCESS;
}同样插入操作也要改动,首先我们获取需要插入的行,然后定义一个指向表结尾的游标,为什么要指向表结尾的游标那,因为我们的插入操作其实是一种追加,直接追加到最后一个,然后通过cursor_value 获取游标处的内存页,将表的行持久化到游标处的内存页中。
ExecuteResult execute_insert(Statement *statement, Table *table)
{
if (table->num_rows >= TABLE_MAX_ROWS) {
return EXECUTE_TABLE_FULL;
}
Row *row_to_insert = &(statement->row_to_insert);
Cursor *cursor = table_end(table);
serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
free(cursor);
return EXECUTE_SUCCESS;
}获取游标处的内存操作如下,和原来类似,通过行号定位到属于哪个页面,通过行号定位到偏移量,如果仔细看的同学可能会发现,这里面的定位的时候是按照最后一行定位的,不应该是最后一行的下一行那,这里面实际没问题的,因为行的偏移量从0开始的,比如如果表里面只有一行数据,那表的row_num为1,则row_num为1的偏移量其实是没数据的,将数据插入到这个空闲位置没问题。
void *cursor_value(Cursor *cursor)
{
uint32_t row_num = cursor->row_num;
uint32_t page_num = row_num / ROWS_PER_PAGE;
void *page = get_page(cursor->table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return (char *)page + byte_offset;
}游标抽象化之后测试:
[root@localhost microdb]# ./a.out db.mb
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
(6,d,d@qq.com)
(7,f,f@qq.com)
(8,g,g@qq.com)
(10,q,q@163.com)
Executed.
microdb > insert 11 dd dd@qq.com
Executed.
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
(6,d,d@qq.com)
(7,f,f@qq.com)
(8,g,g@qq.com)
(10,q,q@163.com)
(11,dd,dd@qq.com)
Executed.
microdb > .exit
[root@localhost microdb]# ./a.out db.mb
microdb > select
(1,a,a@qq.com)
(2,b,b@qq.com)
(1,a,a@qq.com)
(4,rrr,rrr@qq.com)
(5,ttt,ttt@qq.com)
(6,d,d@qq.com)
(7,f,f@qq.com)
(8,g,g@qq.com)
(10,q,q@163.com)
(11,dd,dd@qq.com)
Executed.
microdb > quit
Unrecognized keyword at start of 'quit'.
microdb > .exit三 B+树
3.1 搜索
我理解的搜索是从大量数据中提取所需要的数据,比如图书馆去找一本书,比如在一本书里面搜寻特定的关键词,那如何能快速搜索那,核心在于每步搜索都能快速缩减数据集合,仔细体会下,如果我们每步查询都可以将搜索的集合减少一半,那就是典型的二分法的搜索,那给我们一堆数据,比如以上设计的数据库,去搜索的时候,由于数据之间和位置之间是没有任何关系的,我们只能一行行遍历查询比较。但是这样的性能是和行数成正比的,即行数越多,我们需要查询的平均时间越长。
有什么办法解决这个问题那,然我们用一组数据在内存中简单模拟下我们的表数据情况,如果要快速搜索这组数据,数据又很大的话,那么如果数据是排序的数组组成,我们可以通过二分法快速的找到所要的数据。但是如果用数组存储这组数据,在插入数据的时候,就需要将插入位置的元素都向后移动,导致插入的时候后面的元素都要向后移动一位。同样如果我们做删除操作,需要将删除位置的后面的数据向前移动,补上删除的空洞。
从上面描述来看,用数组保存排序的数据,查询速度快,但是插入和删除太慢了。而想插入和删除的速度快,我们很容易想到的数据结构是链表,链表插入和删除都是更改指针的事情,比较简单,但是遍历的时候,我们只能沿着链表一个个去查,性能又和数据集合大小相关了。
好吧,再思考下排序数组按照二分法来查找数据的场景,每次都可以将要搜索的数据集合缩小一半,那么我们是不是可以把单链表改造下,将排序链表从中间值提溜起来, 中间值作为root节点,比root节点保存值小的,放在左边的链表中,比root值大的放在右边链表中,即变成一个二叉树,这样就变成了一个完全二叉树,插入和删除性能很高,查询的时候性能仍然很高(完全二叉树插入需要平衡,这个也影响了性能,所以设计了红黑树等取插入、删除、查询都均衡的数据结构)。
二叉树的数据结构在内存中保存数据挺好,但是如果作为存在磁盘上的数据就有很多麻烦,二叉树每个节点最多有两个子树,如果数量大,导致整个树的高度比较高,树高了之后那,那需要指针就比较多,每次指针指向一个页面的话,导致需要从磁盘中读取N多个页面,这对我们搜索数据很不利。
3.2 B树和B+树
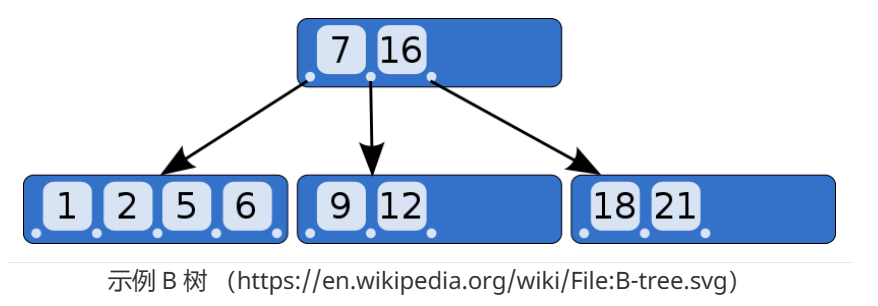
B树结构可以看作是二叉树的进化,我们的指针每次指向一个页面,因为一个磁盘的页面现在一般都是4KB大小,这个页面可以保存很多行数据,那我们的B树结构就可以在一个页面有多个分叉,一个页面又可以保存很多数据。
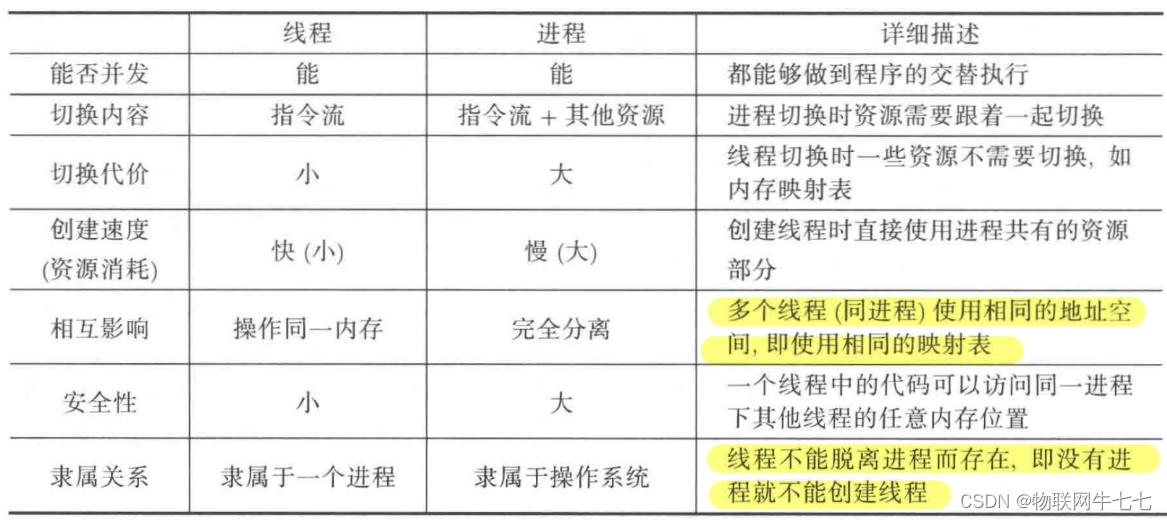
数据的数据存储有的是B+树,有的是B树这两者有何区别那,如下表: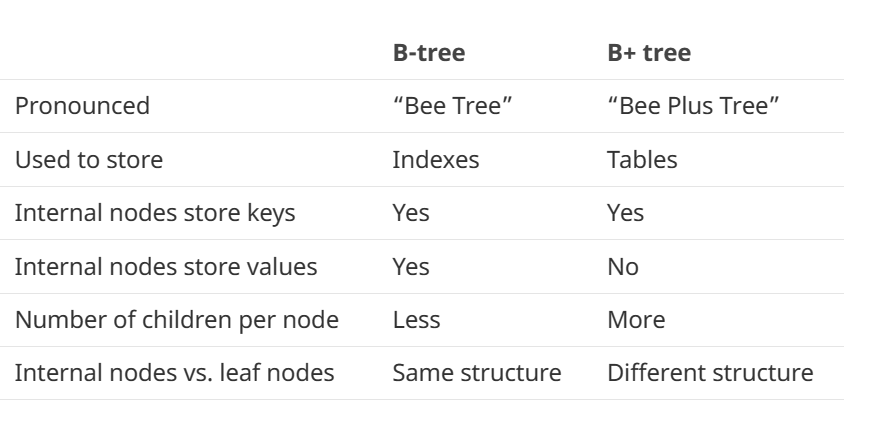
B+树用来存储表数据的,Mysql的InnoDB引擎采用B+树存储,多少个索引就多少个B+树,数据存储在主键的B+树上的,B+树的内部节点只保存key,叶子节点是全部行数据,因为内部节点只保存key,所以一个节点可以保存更多的数据,而B树的节点保存不管是key还包含value,所以一个页面能存储的数量更少。
B树的内部节点和叶子节点有相同的数据结构,而B+树是不同的,B+树内部节点保存的是key和指针数据,叶子节点是完整的多行数据。
还要注意一点B+树和B树的节点一般对应一个磁盘页面,页面内的数据是有序的。 查找时候可以按照二分法进行查找。
3.3 m阶有序树
我们刚才聊到B树或B+树的可以有N多个子节点,节点内的数据又是有序的,我们可以叫做N阶排序树。这种树的内部节点和叶子节点是不同的,具体区别如下: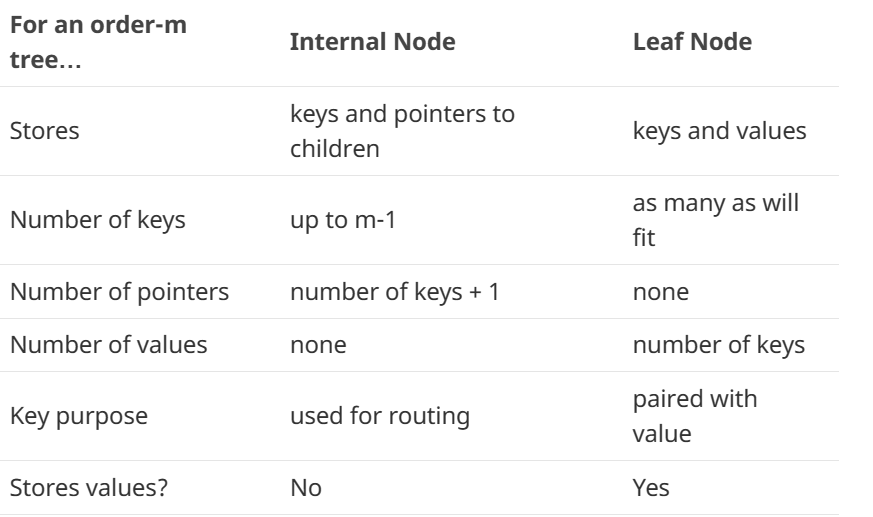
内部节点存储的是key和指向子节点的指针,叶子节点保存的是key和value
内部节点的保存key的数量最大为m-1个,而叶子节点能保存多少保存多少
内部节点保存指针的数量为key的数量+1个,而叶子节点不保存指针。
内部节点保存key的目的是为了路由,叶子节点保存key的目的是为了和value关联。
内不能节点不保存value,而叶子节点保存value数据。
3.4 3阶排序树的插入过程
按照上述定义,我们来画图模拟三阶排序树的插入过程,三阶排序树有以下约束:
每个内部节点最多保存三个子节点。
每个内部节点最多保存二个key。
每个内部节点至少有两个子节点。
每个内不能节点至少有一个key。
初始是一颗空树:
这个空树直接作为没存任何数据的叶子节点。
我们插入两个数据,如下:
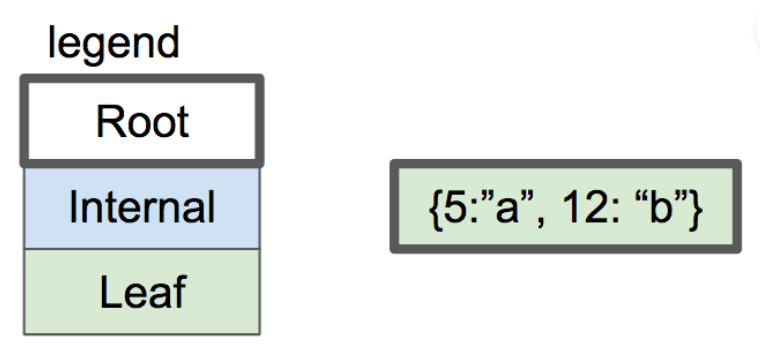 数据没超出三个数据的范围,我们将两条数据直接保存在这个节点上。
数据没超出三个数据的范围,我们将两条数据直接保存在这个节点上。假如一个节点只能保存2个数据,那么上述数据结构再插入一个数据后,会怎么办,只能分裂:
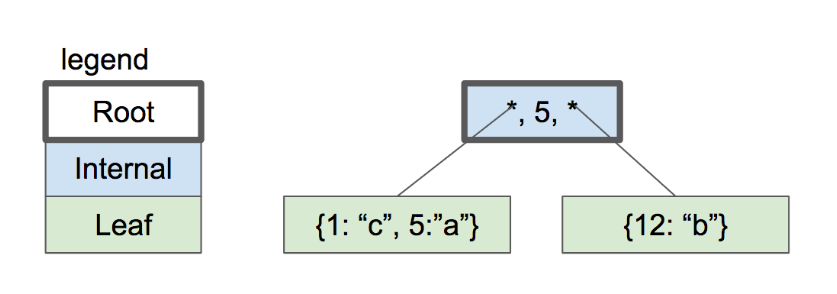 我们插入数据后,由于不够保存,只能拆分上面的叶子节点,分成一个根节点和两个叶子节点,数据分到两个叶子节点上,根节点保存两个指针和一个key。 查询的时候,找小于等于5的走左边的子节点,查大于等于5的,走右边的子节点。
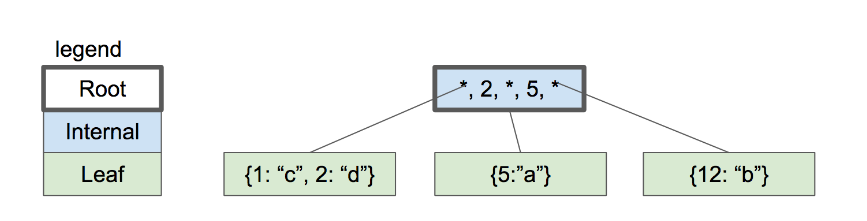
我们插入数据后,由于不够保存,只能拆分上面的叶子节点,分成一个根节点和两个叶子节点,数据分到两个叶子节点上,根节点保存两个指针和一个key。 查询的时候,找小于等于5的走左边的子节点,查大于等于5的,走右边的子节点。插入key2 后,按照查找路由,找到叶子节点,但是叶子节点满了,只能分裂叶子节点,将原来的key5 分裂到新的叶子节点上去,并对key 2创建新的条目。
继续插入18和21两条数据,树的结构变化如下:
 当插入21 的时候,右边的叶子节点不够存储,如果再次创建叶子节点,则根节点要增加个指针,但是根节点也满了,需要将根节点再拆分,这样就增加了B+树的高度。
当插入21 的时候,右边的叶子节点不够存储,如果再次创建叶子节点,则根节点要增加个指针,但是根节点也满了,需要将根节点再拆分,这样就增加了B+树的高度。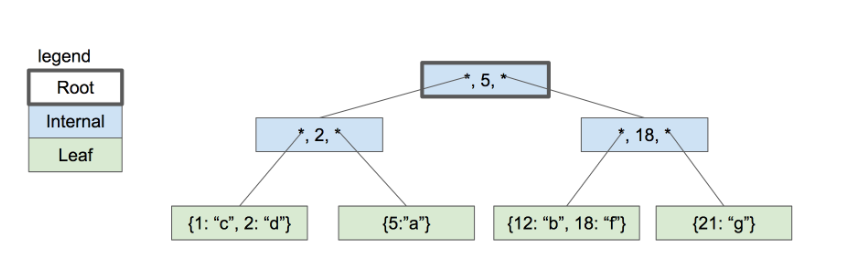
后续的B+树的数据结构实现下篇幅再来聊聊。