python字典应用
文章目录
- python字典应用
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 字典的综合案例
- 使用collections模块的defaultdict类来实现创建字典。
- 拓展知识一:内置函数globals()和locals()
- 拓展知识二:有序字典 collections.OrderedDict
- 拓展知识三:内置函数sorted()
- 拓展知识四:Python支持字典推导式快速生成符合特定条件的字典
- 序列解包
一、实验目的
掌握字典的应用
二、实验原理
字典是包含若干“键:值”元素的无序可变序列,字典中每个元素包含“键”和“值”两部分,表示一种映射或对应关系。定义字典时,每个元素的键和值用冒号分割开,不通风元素之间用逗号分隔,所有的元素放在一对大括号“{”和“}”中。
字典中的“键”可以是Python中任意不可变数据,如整数、实数、复数、字符串、元组等,但是不能使用列表、集合、字典或其他可变类型作为字典的“键”。另外,字典中“键”不允许重复,而“值”是可以重复的。
三、实验环境
Python 3.6以上
IPython
PyCharm
四、实验内容
字典应用
五、实验步骤
字典的综合案例
统计分析在很多领域都有重要的用途,如密码破解,图像直方图等。下面的代码首先生成包含1000个随机字符的字符串,然后统计每个字符出现的次数。
#导入模块
import string
import random
x=string.ascii_letters+string.digits+string.punctuation
x
#生成包含1000个随机字符的列表
y=[random.choice(x) for i in range(1000)]
#把列表中的字符连接成字符串
z=''.join(y)
d=dict()
for ch in z:
#修改每个字符的词频
d[ch]=d.get(ch,0)+1
print(d)

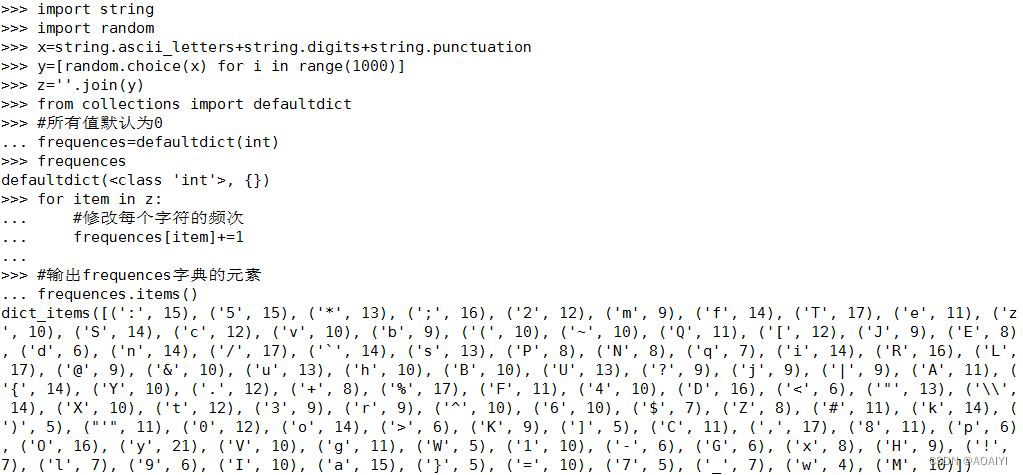
使用collections模块的defaultdict类来实现创建字典。
import string
import random
x=string.ascii_letters+string.digits+string.punctuation
y=[random.choice(x) for i in range(1000)]
z=''.join(y)
from collections import defaultdict
#所有值默认为0
frequences=defaultdict(int)
frequences
for item in z:
#修改每个字符的频次
frequences[item]+=1
#输出frequences字典的元素
frequences.items()
使用collections模块的Counter类,快速实现“统计字符串中每个字符出现次数”这个功能。
import string
import random
x=string.ascii_letters+string.digits+string.punctuation
y=[random.choice(x) for i in range(1000)]
z=''.join(y)
from collections import defaultdict
#所有值默认为0
frequences=defaultdict(int)
from collections import Counter
frequences=Counter(z)
frequences.items()
#返回出现次数最多的1个字符及其频率
frequences.most_common(1)
#返回出现次数最多的3个字符及其频率
frequences.most_common(3)

拓展知识一:内置函数globals()和locals()
内置函数globals()和locals()分别返回包含当前作用域内所有全局变量和局部变量的名称及值的字典
#全局变量
a=(1,2,3,4)
#全局变量
b='hello world.'
def demo():
#局部变量
a=3
#局部变量
b=[1,2,3]
print('locals:',locals())
print('globals:',globals())
demo()

拓展知识二:有序字典 collections.OrderedDict
有序字典,Python内置字典是无序的,如果需要一个可以记住元素插入顺序的字典,可以使用collections.OrderedDict.
import collections
x=collections.OrderedDict()
x['a']=3
x['b']=5
x['c']=8
x

拓展知识三:内置函数sorted()
内置函数sorted()可以对字典元素进行排序并返回新列表,充分利用key参数可以实现丰富的排序功能。
phonebook={'Linda':'7750','Bob':'9345','Carol':'5834'}
from operator import itemgetter
#按字典的“值”进行排序
sorted(phonebook.items(),key=itemgetter(1))
#按字典的“键”进行排序
sorted(phonebook.items(),key=itemgetter(0))
#按字典的“键”进行排序
sorted(phonebook.items(),key=lambda item:item[0])

persons=[{'name':'Dong','age':37},{'name':'Zhang','age':40},{'name':'Li','age':50},{'name':'Dong','age':43}]
print(persons)
#使用key来指定排序依据,先按姓名升序排序,姓名相同的年龄降序排序
print(sorted(persons ,key=lambda x:(x['name'],-x['age'])))

注意:在某一项前面加负号表示降序排序,这一点只适用于数字类型。
拓展知识四:Python支持字典推导式快速生成符合特定条件的字典
{i:str(i) for i in range(1,5)}
x=['A','B','C','D']
y=['a','b','c','d']
{i:j for i,j in zip(x,y)}

序列解包
在实际开发中,序列解包是非常重要和常用的一个功能,可以使用非常简洁的形式完成复杂的功能,大幅度提高了代码的可读性。
1.使用序列解包对多个变量同时进行赋值
#多个变量同时赋值
x,y,z=1,2,3
v_tuple=(False,3.5,'exp')
(x,y,z)=v_tuple
x,y,z=v_tuple
#使用range对象进行解包
x,y,z=range(3)
#使用迭代对象进行序列解包
x,y,z=map(str,range(3))

2.序列解包也可以用于列表和字典,但是对字典使用时,默认是对字典“键”进行操作,如果需要对“键:值”对进行操作,需要使用字典的items()方法明确指定。如果需要对字典的“值”进行操作,需要使用字典的values()方法明确指定。
a=[1,2,3]
#列表页支持序列解包
b,c,d=a
b
#sorted函数返回排序后的列表
x,y,z=sorted([1,3,2])
#对字典进行序列解包
s={'a':1,'b':2,'c':3}
b,c,d=s.items()
b
#使用字典时不用太多考虑元素的顺序
b,c,d=s
b
b,c,d=s.values()
print(b,c,d)

3.使用序列解包可以很方便地同时遍历多个序列。
keys=['a','b','c','d']
values=[1,2,3,4]
for k,v in zip(keys,values):
print(k,v)

4.下面代码演示了对内置函数enmerate()返回的迭代对象进行遍历时,序列解包的用法。
x=['a','b','c']
for i,v in enumerate(x):
print('The value on position{0} is {1}'.format(i,v))

5.下面对字典的操作也使用到序列解包:
s={'a':1,'b':2,'c':3}
for k,v in s.items():
#字典中每个元素包含“键”和“值”两部分
print(k,v)
#序列解包还支持下面的用法
print(*[1,2,3],4,*(5,6))
*range(4),4
{*range(4),4,*(5,6,7)}
{'x':1,**{'y':2}}

注意:在调用函数时,在实参前面加上一个星号(*)也可以进行序列解包。