文章目录
- 摘要
- Abstract
- 文献阅读
- 题目
- 问题
- 本文贡献
- 方法
- aGNN
- 输入和输出模块
- 嵌入模块
- 编码器和解码器模块:支持多头注意的GCN
- 多头自注意力机制
- GCN
- 模型解释:SHAP
- 案例研究
- 地下水流动与污染物运移模型
- 研究场景设计
- 数据集
- 实验结果
- 代码复现
- 结论
摘要
本周阅读了一篇基于注意力图神经网络的污染物传输建模与源属性的文章,文中作者引入了一种新的基于注意力的图神经网络(aGNN),用于利用有限的监测数据对污染物传输进行建模,并量化污染物源(驱动因素)及其传播(结果)之间的因果关系。在涉及异质含水层中不同监测网络的五个合成案例研究中,aGNN在多步预测中表现优于基于LSTM(长短期记忆)和基于CNN(卷积神经网络)的方法。基于aGNN的解释性分析量化了每个污染源的影响,这已经通过基于物理的模型进行了验证,结果一致,R2值超过92%。此外,还对文章的代码进行复现。
Abstract
This week, an article about modeling pollutant transport and attributing sources using Attention-based Graph Neural Networks is readed. In the paper, the authors introduce a novel Attention-based Graph Neural Network (aGNN), designed to model pollutant transmission with limited monitoring data and to quantify causal relationships between pollutant sources (drivers) and their dispersion (outcomes). Across five synthetic case studies involving diverse monitoring networks in heterogeneous aquifers, the aGNN outperforms methods based on LSTM (Long Short-Term Memory) and CNN (Convolutional Neural Networks) in multi-step predictions. The explanatory analysis based on aGNN quantifies the impact of each pollution source, which has been validated against physically-based models with consistent results, yielding R² values exceeding 92%. Additionally, an effort was made to reproduce the article’s code.
文献阅读
题目
Contaminant Transport Modeling and Source Attribution With Attention‐Based Graph Neural Network
问题
(a 地下水流动路径和优先流动和迁移状态隐藏在地下,难以确定;
(b 污染物迁移过程涉及各种机制,如平流和扩散,可能在时空模式中产生高度非线性;
(c 污染物传播依赖于关于各种人类活动和自然反应的数据的收集,学习起来十分复杂。
本文贡献
(a 研究比较了aGNN与GNN/CNN/LSTM在多过程污染物传输建模中的性能,这些方法都适用于相同的多步空间预测的端到端学习任务。
(b 研究评估了所提出的aGNN通过归纳学习的数据和含水层的异质性的可用性。还评估了使用aGNN与使用基于物理的模型相比的时间效率。
(c 采用了一种可解释的人工智能技术,即Shapley值,它起源于合作博弈论的概念,来计算每个属性对预测的贡献,在本研究中,Shapley值代表多源排放情况下的污染物源属性。
方法
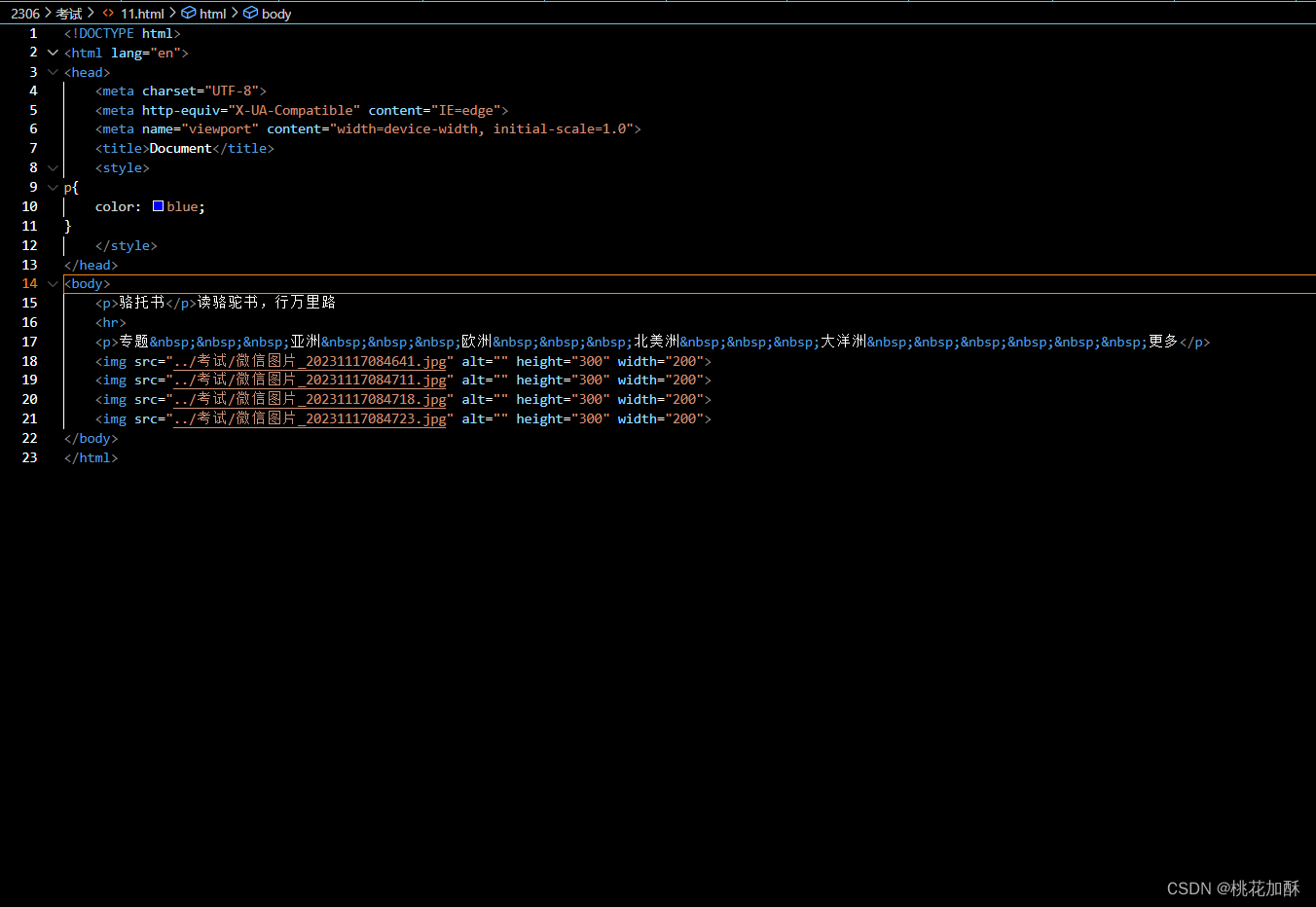
下图概述了使用两种方法进行污染物传输建模的工作流程和数据:深度学习和基于物理的模型(MODFLOW和MT3DMS)。模型的评估分为三个任务:转换学习、归纳学习和模型解释:
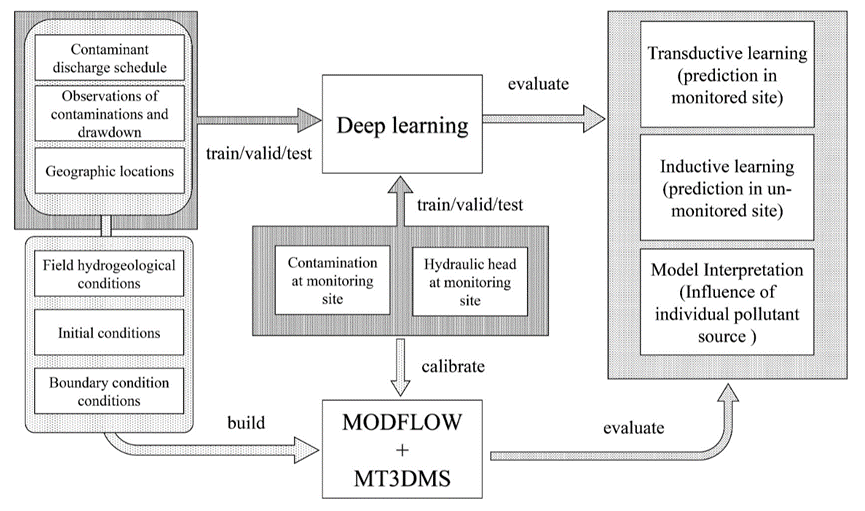
aGNN
如上图所示,aGNN的体系结构包括五个模块:
(1)输入模块,用于构建编解码器的节点特征向量、空间信息和邻接矩阵;
(2)图形嵌入模块,用于从原始数据建立空间嵌入和时间嵌入;
(3)编码模块,包含两层GCN并结合多头注意机制;
(4)解码模块,用于将两层GCN与来自编码器的关注度、状态和隐藏信息相耦合;
(5)输出模块,用于生成预测的多步时空图。
输入和输出模块
输入和输出模块构建时空图,这些图由描述观测井空间位置的节点和表征监测网络中节点信息变化的特征向量表示。
图的结构由节点V和边ES的集合组成(即,G=(V,E,A))。在本研究中,节点集合V表示N个观测点,节点Vi的节点表示xi可以是存储所有观测值的向量。E是连接两个节点(Vi,Vj)的边。N×N维的邻接矩阵(A)表示每两个节点之间的依赖关系,从而刻画了图的拓扑结构。

嵌入模块
在aGNN中,作者开发并嵌入了一个嵌入模块,对空间图中的空间异质性和时间序列中的顺序信息进行编码。空间异构性嵌入适用于地理坐标,并由径向基网络层构成。时间顺序信息建立在位置嵌入的基础上,在其应用中显示出协同效应和注意机制。


给定时间序列S = ( s 0 , s 1 , … , s T ),时间嵌入层形成有限维表示来指示Si在序列 S 中的位置。
研究中的时间嵌入是正弦变换到时间顺序的串联,形成矩阵 ,其中 T 和 demb 分别是时间长度和向量维度。
,其中 T 和 demb 分别是时间长度和向量维度。
TE由公式2和公式3得出,其中2d和2d+1分别表示偶数和奇数维度,t是时间序列中的时间位置。时间嵌入的维度为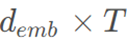 。
。
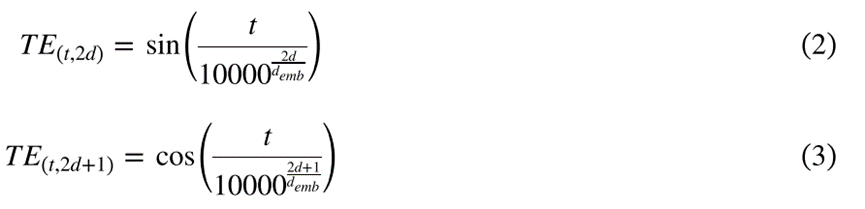
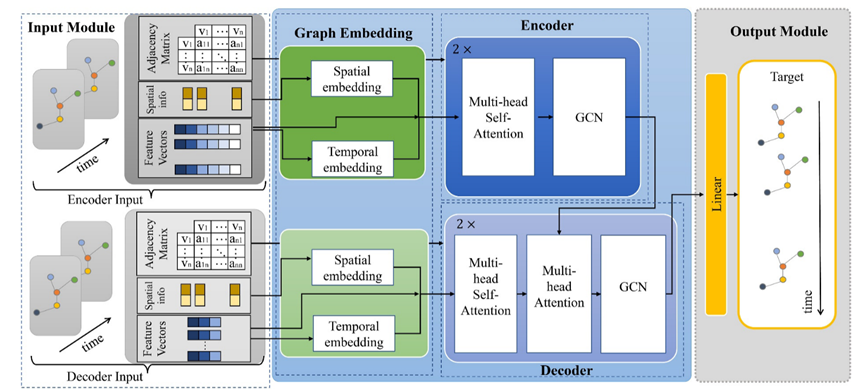
编码器和解码器模块:支持多头注意的GCN
AGNN的核心是编解码器模块。编码器和解码器都由多层构建块组成,包括多头自我注意(MSA)、GCN和多头注意(MAT)块。MSA对时间序列本身中的动态相关性进行建模,GCN尝试捕获来自监测站的观测之间的空间相关依赖关系,并且MAT将信息从编码器传输到解码器。
多头自注意力机制
在MAT中,Q、K和V通过不同的学习线性变换被投影h次(公式5和公式6)。如图所示,将得到的序列连接起来并进行后续的线性变换。
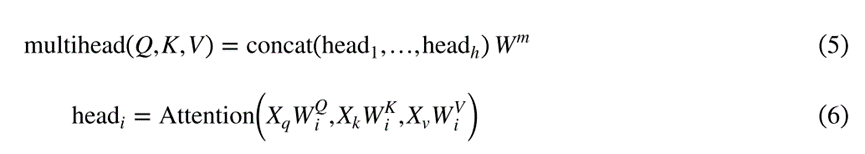
MSA允许模型捕获输入序列中的不同方面和依赖关系。
GCN
GCN通过图结构在节点之间交换信息来提取中间表示,以建模空间依赖关系。
对于输入矩阵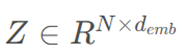 ,GCN通过添加自环的邻接矩阵(A)来聚合节点的邻接特征及其特征,信息的传播表示为
,GCN通过添加自环的邻接矩阵(A)来聚合节点的邻接特征及其特征,信息的传播表示为 ,利用图拉普拉斯矩阵来收集邻接信息。
,利用图拉普拉斯矩阵来收集邻接信息。
随后,如公式7所示,应用线性投影和非线性变换,其中σ是非线性激活函数, 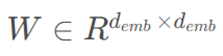 是可学习的线性化参数。
是可学习的线性化参数。

总而言之,MAT是编码器和解码器之间的纽带。将编码器的堆叠输出作为V和K传递给MAT,并且将注意力分数分配给解码器输入的表示(即Q)。解码器中的MSA和GCN执行类似于机器翻译任务的学习过程,在该任务中,解码器输入代表需要被翻译成另一种“语言”的“语言中的句子”
模型解释:SHAP
Shapley值法量化了合作博弈中每个参与者的贡献,可以用来衡量DL方法中各个特征的重要性。在本研究中,作者根据提出的aGNN预测的地下水污染的空间位置,通过Shap来评估每个污染源的影响。
在涵盖N个污染点的区域中,假设SN代表N个污染点的一个子集,定义fi.j(SN)为仅考虑子集SN内污染源对指定地点(i, j)处地下水所产生的污染物浓度贡献。该点d(d=1,Φ)的Shapley值…i,jN) 可由公式8来具体量化:

其中|SN|是子集SN中的污染点的数目,而fi.j(SN∪{d})−fi.j(SN)是由其诱导污染fi.j表示的点d的边际贡献。Fi.j(.)可以通过基于物理的地下水流动和污染物运移模型(即MODFLOW和MT3DMS)以及aGNN来获得。
案例研究
地下水流动与污染物运移模型
基于物理的模型(MODFLOW和MT3DMS)可以模拟研究区的地下水流动和溶质运移,考虑地下水和污染源排放对污染物羽流运动的影响。含水层的天然孔隙结构和污染源是不同的。
MODFLOW构建了具有空间变化的水力传导性的非均质地质介质。
MT3DMS模拟了多个污染源,这些污染源位于不同的位置,具有不同的释放强度,在污染物迁移模拟中驱动污染物的移动。
研究场景设计
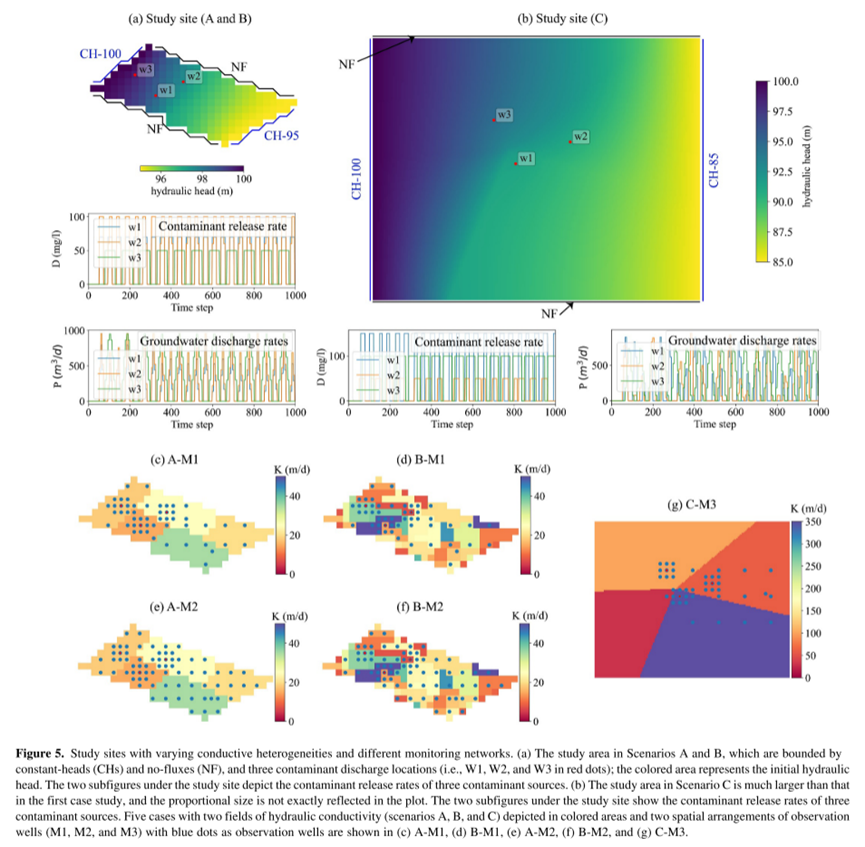
为促进方法的开发与验证,本研究设立了两个综合实验场地,均基于无承压含水层特性。首块场地覆盖497,500平方米,如图5a展示,通过MODFLOW软件被划分成30列乘以15行的网格,每格尺寸为50米乘50米。该场地的水文边界条件设定为两侧无流量边界及两侧固定水头(分别为100米和95米),自然水力梯度促使地下水流动。水文地质参数设定包括渗透系数为0.3,储水系数为0.0001 (1/m),孔隙度为0.3。为了探讨水力传导率(HC)变异性对污染物迁移模型的效应,研究设置了两种不同的水力传导率场景:
A场景由五个区间构成,水力传导率在15至35米/日间变化(见图5c和5e);
B场景的水力传导率变异更大,范围自0至50米/日不等(图5d和5f所示)。
利用MT3DMS模型,整个研究区域设定30米的纵向弥散度来模拟污染物传输过程。区域内有三口注水井(W3位于上游,W1和W2位于下游)周期性注入污染物,其操作时间和释放浓度在图5a中有所体现,整个模拟周期长达2100天,分为2100个时间步长,每步代表一天。
另一研究区域(C场景)面积达180平方公里,约为首个场地的360倍(见图5b),在MODFLOW中的网格布局为120列乘150行,每格为100米乘100米。水文边界同样设计为两侧无流量及两侧固定水头(100米和85米)。该区域的水力传导率异质性更为显著,通过四个区域展现,跨度从30至350米/日(图5g)。此外,污染模拟也涉及W1、W2和W3三口井的间歇性注入,遵循特定排放计划与浓度,与前一场地的污染模拟方式保持一致。
数据集
污染物运移数据集由MODFLOW和MT3DMS模拟生成。在所有数据样本中,80%用于训练DL模型,其余20%用于性能评估。对400个周期的16个时空大数据集进行批优化训练,输出为50个时间步长的观测点的GD和CC预测。

表1展示了三种监测网不同算法的输入维度和参数个数。
实验结果
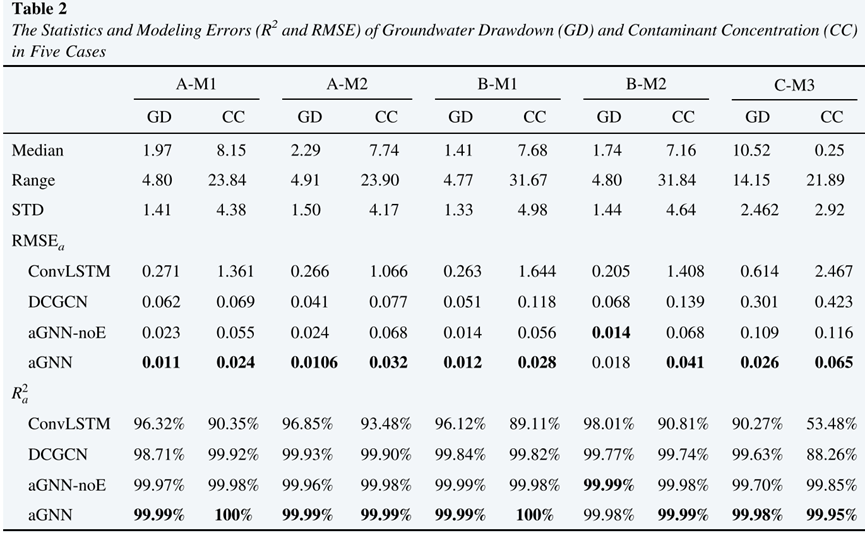
表2展示了五种情况下地下水降深和污染物浓度的统计建模误差(R2和RMSE),在所有的算法中,aGNN在几乎所有的五种情况下都获得了最低的RMSEa和最高的R2 a(表2),表明它在模拟非均匀分布的监测系统中的污染物传输方面比其他算法具有更好的性能。
代码复现
以下是模型的一些关键代码,包括GCN,多头自注意力机制,位置编码等关键部分。
import torch
import torch.nn as nn
import torch.nn.functional as F
import copy
import math
import numpy as np
from utils_dpl3_contam import norm_Adj
class RBF(nn.Module):
"""
Transforms incoming data using a given radial basis function:
u_{i} = rbf(||x - c_{i}|| / s_{i})
Arguments:
in_features: size of each input sample
out_features: size of each output sample
Shape:
- Input: (N, in_features) where N is an arbitrary batch size
- Output: (N, out_features) where N is an arbitrary batch size
Attributes:
centres: the learnable centres of shape (out_features, in_features).
The values are initialised from a standard normal distribution.
Normalising inputs to have mean 0 and standard deviation 1 is
recommended.
log_sigmas: logarithm of the learnable scaling factors of shape (out_features).
basis_func: the radial basis function used to transform the scaled
distances.
"""
def __init__(self, in_features, out_features, num_vertice,basis_func):
super(RBF, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.centres1 = nn.Parameter(torch.Tensor(num_vertice, self.in_features)) # (out_features, in_features)
self.alpha = nn.Parameter(torch.Tensor(num_vertice,out_features))
self.log_sigmas = nn.Parameter(torch.Tensor(out_features))
self.basis_func = basis_func
self.reset_parameters()
# self.alpha1 = nn.Parameter(torch.Tensor(num_vertice, self.out_features))
def reset_parameters(self):
nn.init.normal_(self.centres1, 0, 1)
nn.init.constant_(self.log_sigmas, 0)
def forward(self, input):
size1= (input.size(0), input.size(0), self.in_features)
x1 = input.unsqueeze(1).expand(size1)
c1 = self.centres1.unsqueeze(0).expand(size1)
distances1 = torch.matmul((x1 - c1).pow(2).sum(-1).pow(0.5),self.alpha) / torch.exp(self.log_sigmas).unsqueeze(0)
return self.basis_func(distances1) #distances1
# RBFs
def gaussian(alpha):
phi = torch.exp(-1 * alpha.pow(2))
return phi
def linear(alpha):
phi = alpha
return phi
def quadratic(alpha):
phi = alpha.pow(2)
return phi
def inverse_quadratic(alpha):
phi = torch.ones_like(alpha) / (torch.ones_like(alpha) + alpha.pow(2))
return phi
def multiquadric(alpha):
phi = (torch.ones_like(alpha) + alpha.pow(2)).pow(0.5)
return phi
def inverse_multiquadric(alpha):
phi = torch.ones_like(alpha) / (torch.ones_like(alpha) + alpha.pow(2)).pow(0.5)
return phi
def spline(alpha):
phi = (alpha.pow(2) * torch.log(alpha + torch.ones_like(alpha)))
return phi
def poisson_one(alpha):
phi = (alpha - torch.ones_like(alpha)) * torch.exp(-alpha)
return phi
def poisson_two(alpha):
phi = ((alpha - 2 * torch.ones_like(alpha)) / 2 * torch.ones_like(alpha)) \
* alpha * torch.exp(-alpha)
return phi
def matern32(alpha):
phi = (torch.ones_like(alpha) + 3 ** 0.5 * alpha) * torch.exp(-3 ** 0.5 * alpha)
return phi
def matern52(alpha):
phi = (torch.ones_like(alpha) + 5 ** 0.5 * alpha + (5 / 3) \
* alpha.pow(2)) * torch.exp(-5 ** 0.5 * alpha)
return phi
def basis_func_dict():
"""
A helper function that returns a dictionary containing each RBF
"""
bases = {'gaussian': gaussian,
'linear': linear,
'quadratic': quadratic,
'inverse quadratic': inverse_quadratic,
'multiquadric': multiquadric,
'inverse multiquadric': inverse_multiquadric,
'spline': spline,
'poisson one': poisson_one,
'poisson two': poisson_two,
'matern32': matern32,
'matern52': matern52}
return bases
###############################################################################################################
def clones(module, N):
'''
Produce N identical layers.
:param module: nn.Module
:param N: int
:return: torch.nn.ModuleList
'''
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
def subsequent_mask(size):
'''
mask out subsequent positions.
:param size: int
:return: (1, size, size)
'''
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0 # 1 means reachable; 0 means unreachable
class spatialGCN(nn.Module):
def __init__(self, sym_norm_Adj_matrix, in_channels, out_channels):
super(spatialGCN, self).__init__()
self.sym_norm_Adj_matrix = sym_norm_Adj_matrix # (N, N)
self.in_channels = in_channels
self.out_channels = out_channels
self.Theta = nn.Linear(in_channels, out_channels, bias=False)
def forward(self, x):
'''
spatial graph convolution operation
:param x: (batch_size, N, T, F_in)
:return: (batch_size, N, T, F_out)
'''
batch_size, num_of_vertices, num_of_timesteps, in_channels = x.shape
x = x.permute(0, 2, 1, 3).reshape((-1, num_of_vertices, in_channels)) # (b*t,n,f_in)
return F.relu(self.Theta(torch.matmul(self.sym_norm_Adj_matrix, x)).reshape((batch_size, num_of_timesteps, num_of_vertices, self.out_channels)).transpose(1, 2))
class GCN(nn.Module):
def __init__(self, sym_norm_Adj_matrix, in_channels, out_channels):
super(GCN, self).__init__()
self.sym_norm_Adj_matrix = sym_norm_Adj_matrix # (N, N)
self.in_channels = in_channels
self.out_channels = out_channels
self.Theta = nn.Linear(in_channels, out_channels, bias=False)
def forward(self, x):
'''
spatial graph convolution operation
:param x: (batch_size, N, F_in)
:return: (batch_size, N, F_out)
'''
return F.relu(self.Theta(torch.matmul(self.sym_norm_Adj_matrix, x))) # (N,N)(b,N,in)->(b,N,in)->(b,N,out)
class Spatial_Attention_layer(nn.Module):
'''
compute spatial attention scores
'''
def __init__(self, dropout=.0):
super(Spatial_Attention_layer, self).__init__()
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
'''
:param x: (batch_size, N, T, F_in)
:return: (batch_size, T, N, N)
'''
batch_size, num_of_vertices, num_of_timesteps, in_channels = x.shape
x = x.permute(0, 2, 1, 3).reshape((-1, num_of_vertices, in_channels)) # (b*t,n,f_in)
score = torch.matmul(x, x.transpose(1, 2)) / math.sqrt(in_channels) # (b*t, N, F_in)(b*t, F_in, N)=(b*t, N, N)
score = self.dropout(F.softmax(score, dim=-1)) # the sum of each row is 1; (b*t, N, N)
return score.reshape((batch_size, num_of_timesteps, num_of_vertices, num_of_vertices))
class spatialAttentionGCN(nn.Module):
def __init__(self, sym_norm_Adj_matrix, in_channels, out_channels, dropout=.0):
super(spatialAttentionGCN, self).__init__()
self.sym_norm_Adj_matrix = sym_norm_Adj_matrix # (N, N)
self.in_channels = in_channels
self.out_channels = out_channels
self.Theta = nn.Linear(in_channels, out_channels, bias=False)
self.SAt = Spatial_Attention_layer(dropout=dropout)
def forward(self, x):
'''
spatial graph convolution operation
:param x: (batch_size, N, T, F_in)
:return: (batch_size, N, T, F_out)
'''
batch_size, num_of_vertices, num_of_timesteps, in_channels = x.shape
spatial_attention = self.SAt(x) # (batch, T, N, N)
x = x.permute(0, 2, 1, 3).reshape((-1, num_of_vertices, in_channels)) # (b*t,n,f_in)
spatial_attention = spatial_attention.reshape((-1, num_of_vertices, num_of_vertices)) # (b*T, n, n)
return F.relu(self.Theta(torch.matmul(self.sym_norm_Adj_matrix.mul(spatial_attention), x)).reshape((batch_size, num_of_timesteps, num_of_vertices, self.out_channels)).transpose(1, 2))
# (b*t, n, f_in)->(b*t, n, f_out)->(b,t,n,f_out)->(b,n,t,f_out)
class spatialAttentionScaledGCN(nn.Module):
def __init__(self, sym_norm_Adj_matrix, in_channels, out_channels, dropout=.0):
super(spatialAttentionScaledGCN, self).__init__()
self.sym_norm_Adj_matrix = sym_norm_Adj_matrix # (N, N)
self.in_channels = in_channels
self.out_channels = out_channels
self.Theta = nn.Linear(in_channels, out_channels, bias=False)
self.SAt = Spatial_Attention_layer(dropout=dropout)
def forward(self, x):
'''
spatial graph convolution operation
:param x: (batch_size, N, T, F_in)
:return: (batch_size, N, T, F_out)
'''
batch_size, num_of_vertices, num_of_timesteps, in_channels = x.shape
spatial_attention = self.SAt(x) / math.sqrt(in_channels) # scaled self attention: (batch, T, N, N)
x = x.permute(0, 2, 1, 3).reshape((-1, num_of_vertices, in_channels))
# (b, n, t, f)-permute->(b, t, n, f)->(b*t,n,f_in)
spatial_attention = spatial_attention.reshape((-1, num_of_vertices, num_of_vertices)) # (b*T, n, n)
return F.relu(self.Theta(torch.matmul(self.sym_norm_Adj_matrix.mul(spatial_attention), x)).reshape((batch_size, num_of_timesteps, num_of_vertices, self.out_channels)).transpose(1, 2))
# (b*t, n, f_in)->(b*t, n, f_out)->(b,t,n,f_out)->(b,n,t,f_out)
class SpatialPositionalEncoding_RBF(nn.Module):
def __init__(self, d_model, logitudelatitudes,num_of_vertices, dropout, gcn=None, smooth_layer_num=0):
super(SpatialPositionalEncoding_RBF, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# self.embedding = torch.nn.Embedding(num_of_vertices, d_model)
self.embedding = RBF(2, d_model, num_of_vertices,quadratic) # gaussin nn.Linear(4, d_model-4)
self.logitudelatitudes = logitudelatitudes
self.gcn_smooth_layers = None
if (gcn is not None) and (smooth_layer_num > 0):
self.gcn_smooth_layers = nn.ModuleList([gcn for _ in range(smooth_layer_num)])
def forward(self, x,log1,lat1):
'''
:param x: (batch_size, N, T, F_in)
:return: (batch_size, N, T, F_out)
'''
# x,log,lat,t= x[0],x[1],x[2],x[3]
batch, num_of_vertices, timestamps, _ = x.shape
x_indexs = torch.concat((torch.unsqueeze(log1.mean(0).mean(-1),-1),torch.unsqueeze(lat1.mean(0).mean(-1),-1)),-1)# (N,)
x_ind = torch.concat((
x_indexs[:, 0:1] ,
x_indexs[:, 1:] )
, axis=1)
embed = self.embedding(x_ind.float()).unsqueeze(0)
if self.gcn_smooth_layers is not None:
for _, l in enumerate(self.gcn_smooth_layers):
embed = l(embed) # (1,N,d_model) -> (1,N,d_model)
x = x + embed.unsqueeze(2) # (B, N, T, d_model)+(1, N, 1, d_model)
return self.dropout(x)
class TemporalPositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len, lookup_index=None):
super(TemporalPositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
self.lookup_index = lookup_index
self.max_len = max_len
# computing the positional encodings once in log space
pe = torch.zeros(max_len, d_model)
for pos in range(max_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i+1] = math.cos(pos / (10000 ** ((2 * (i + 1)) / d_model)))
pe = pe.unsqueeze(0).unsqueeze(0) # (1, 1, T_max, d_model)
self.register_buffer('pe', pe)
# register_buffer:
# Adds a persistent buffer to the module.
# This is typically used to register a buffer that should not to be considered a model parameter.
def forward(self, x,t):
'''
:param x: (batch_size, N, T, F_in)
:return: (batch_size, N, T, F_out)
'''
if self.lookup_index is not None:
x = x + self.pe[:, :, self.lookup_index, :] # (batch_size, N, T, F_in) + (1,1,T,d_model)
else:
x = x + self.pe[:, :, :x.size(2), :]
return self.dropout(x.detach())
class SublayerConnection(nn.Module):
'''
A residual connection followed by a layer norm
'''
def __init__(self, size, dropout, residual_connection, use_LayerNorm):
super(SublayerConnection, self).__init__()
self.residual_connection = residual_connection
self.use_LayerNorm = use_LayerNorm
self.dropout = nn.Dropout(dropout)
if self.use_LayerNorm:
self.norm = nn.LayerNorm(size)
def forward(self, x, sublayer):
'''
:param x: (batch, N, T, d_model)
:param sublayer: nn.Module
:return: (batch, N, T, d_model)
'''
if self.residual_connection and self.use_LayerNorm:
return x + self.dropout(sublayer(self.norm(x)))
if self.residual_connection and (not self.use_LayerNorm):
return x + self.dropout(sublayer(x))
if (not self.residual_connection) and self.use_LayerNorm:
return self.dropout(sublayer(self.norm(x)))
class PositionWiseGCNFeedForward(nn.Module):
def __init__(self, gcn, dropout=.0):
super(PositionWiseGCNFeedForward, self).__init__()
self.gcn = gcn
self.dropout = nn.Dropout(dropout)
def forward(self, x):
'''
:param x: (B, N_nodes, T, F_in)
:return: (B, N, T, F_out)
'''
return self.dropout(F.relu(self.gcn(x)))
def attention(query, key, value, mask=None, dropout=None):
'''
:param query: (batch, N, h, T1, d_k)
:param key: (batch, N, h, T2, d_k)
:param value: (batch, N, h, T2, d_k)
:param mask: (batch, 1, 1, T2, T2)
:param dropout:
:return: (batch, N, h, T1, d_k), (batch, N, h, T1, T2)
'''
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # scores: (batch, N, h, T1, T2)
if mask is not None:
scores = scores.masked_fill_(mask == 0, -1e9) # -1e9 means attention scores=0
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# p_attn: (batch, N, h, T1, T2)
return torch.matmul(p_attn, value), p_attn # (batch, N, h, T1, d_k), (batch, N, h, T1, T2)
class MultiHeadAttention(nn.Module):
def __init__(self, nb_head, d_model, dropout=.0):
super(MultiHeadAttention, self).__init__()
assert d_model % nb_head == 0
self.d_k = d_model // nb_head
self.h = nb_head
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
'''
:param query: (batch, N, T, d_model)
:param key: (batch, N, T, d_model)
:param value: (batch, N, T, d_model)
:param mask: (batch, T, T)
:return: x: (batch, N, T, d_model)
'''
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(1) # (batch, 1, 1, T, T), same mask applied to all h heads.
nbatches = query.size(0)
N = query.size(1)
# (batch, N, T, d_model) -linear-> (batch, N, T, d_model) -view-> (batch, N, T, h, d_k) -permute(2,3)-> (batch, N, h, T, d_k)
query, key, value = [l(x).view(nbatches, N, -1, self.h, self.d_k).transpose(2, 3) for l, x in
zip(self.linears, (query, key, value))]
# apply attention on all the projected vectors in batch
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# x:(batch, N, h, T1, d_k)
# attn:(batch, N, h, T1, T2)
x = x.transpose(2, 3).contiguous() # (batch, N, T1, h, d_k)
x = x.view(nbatches, N, -1, self.h * self.d_k) # (batch, N, T1, d_model)
return self.linears[-1](x)
class MultiHeadAttentionAwareTemporalContex_qc_kc(nn.Module): # key causal; query causal;
def __init__(self, nb_head, d_model, num_of_lags, points_per_lag, kernel_size=3, dropout=.0):
'''
:param nb_head:
:param d_model:
:param num_of_weeks:
:param num_of_days:
:param num_of_hours:
:param points_per_hour:
:param kernel_size:
:param dropout:
'''
super(MultiHeadAttentionAwareTemporalContex_qc_kc, self).__init__()
assert d_model % nb_head == 0
self.d_k = d_model // nb_head
self.h = nb_head
self.linears = clones(nn.Linear(d_model, d_model), 2) # 2 linear layers: 1 for W^V, 1 for W^O
self.padding = kernel_size - 1
self.conv1Ds_aware_temporal_context = clones(nn.Conv2d(d_model, d_model, (1, kernel_size), padding=(0, self.padding)), 2) # # 2 causal conv: 1 for query, 1 for key
self.dropout = nn.Dropout(p=dropout)
self.n_length = num_of_lags * points_per_lag
def forward(self, query, key, value, mask=None, query_multi_segment=False, key_multi_segment=False):
'''
:param query: (batch, N, T, d_model)
:param key: (batch, N, T, d_model)
:param value: (batch, N, T, d_model)
:param mask: (batch, T, T)
:param query_multi_segment: whether query has mutiple time segments
:param key_multi_segment: whether key has mutiple time segments
if query/key has multiple time segments, causal convolution should be applied separately for each time segment.
:return: (batch, N, T, d_model)
'''
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(1) # (batch, 1, 1, T, T), same mask applied to all h heads.
nbatches = query.size(0)
N = query.size(1)
# deal with key and query: temporal conv
# (batch, N, T, d_model)->permute(0, 3, 1, 2)->(batch, d_model, N, T) -conv->(batch, d_model, N, T)-view->(batch, h, d_k, N, T)-permute(0,3,1,4,2)->(batch, N, h, T, d_k)
if query_multi_segment and key_multi_segment:
query_list = []
key_list = []
if self.n_length > 0:
query_h, key_h = [l(x.permute(0, 3, 1, 2))[:, :, :, :-self.padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2) for l, x in zip(self.conv1Ds_aware_temporal_context, (query[:, :, self.w_length + self.d_length:self.w_length + self.d_length + self.h_length, :], key[:, :, self.w_length + self.d_length:self.w_length + self.d_length + self.h_length, :]))]
query_list.append(query_h)
key_list.append(key_h)
query = torch.cat(query_list, dim=3)
key = torch.cat(key_list, dim=3)
elif (not query_multi_segment) and (not key_multi_segment):
query, key = [l(x.permute(0, 3, 1, 2))[:, :, :, :-self.padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2) for l, x in zip(self.conv1Ds_aware_temporal_context, (query, key))]
elif (not query_multi_segment) and (key_multi_segment):
query = self.conv1Ds_aware_temporal_context[0](query.permute(0, 3, 1, 2))[:, :, :, :-self.padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key_list = []
if self.n_length > 0:
key_h = self.conv1Ds_aware_temporal_context[1](key[:, :,0:self.n_length, :].permute(0, 3, 1, 2))[:, :, :, :-self.padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key_list.append(key_h)
key = torch.cat(key_list, dim=3)
else:
import sys
print('error')
sys.out
# deal with value:
# (batch, N, T, d_model) -linear-> (batch, N, T, d_model) -view-> (batch, N, T, h, d_k) -permute(2,3)-> (batch, N, h, T, d_k)
value = self.linears[0](value).view(nbatches, N, -1, self.h, self.d_k).transpose(2, 3)
# apply attention on all the projected vectors in batch
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# x:(batch, N, h, T1, d_k)
# attn:(batch, N, h, T1, T2)
x = x.transpose(2, 3).contiguous() # (batch, N, T1, h, d_k)
x = x.view(nbatches, N, -1, self.h * self.d_k) # (batch, N, T1, d_model)
return self.linears[-1](x)
class MultiHeadAttentionAwareTemporalContex_q1d_k1d(nn.Module): # 1d conv on query, 1d conv on key
def __init__(self, nb_head, d_model, num_of_lags, points_per_lag, kernel_size=3, dropout=.0): #num_of_weeks, num_of_days, num_of_hours
super(MultiHeadAttentionAwareTemporalContex_q1d_k1d, self).__init__()
assert d_model % nb_head == 0
self.d_k = d_model // nb_head
self.h = nb_head
self.linears = clones(nn.Linear(d_model, d_model), 2) # 2 linear layers: 1 for W^V, 1 for W^O
self.padding = (kernel_size - 1)//2
self.conv1Ds_aware_temporal_context = clones(
nn.Conv2d(d_model, d_model, (1, kernel_size), padding=(0, self.padding)),
2) # # 2 causal conv: 1 for query, 1 for key
self.dropout = nn.Dropout(p=dropout)
self.n_length = num_of_lags * points_per_lag #num_of_hours * points_per_hour
def forward(self, query, key, value, mask=None, query_multi_segment=False, key_multi_segment=False):
'''
:param query: (batch, N, T, d_model)
:param key: (batch, N, T, d_model)
:param value: (batch, N, T, d_model)
:param mask: (batch, T, T)
:param query_multi_segment: whether query has mutiple time segments
:param key_multi_segment: whether key has mutiple time segments
if query/key has multiple time segments, causal convolution should be applied separately for each time segment.
:return: (batch, N, T, d_model)
'''
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(1) # (batch, 1, 1, T, T), same mask applied to all h heads.
nbatches = query.size(0)
N = query.size(1)
# deal with key and query: temporal conv
# (batch, N, T, d_model)->permute(0, 3, 1, 2)->(batch, d_model, N, T) -conv->(batch, d_model, N, T)-view->(batch, h, d_k, N, T)-permute(0,3,1,4,2)->(batch, N, h, T, d_k)
if query_multi_segment and key_multi_segment:
query_list = []
key_list = []
if self.n_length > 0:
query_h, key_h = [l(x.permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2) for l, x in zip(self.conv1Ds_aware_temporal_context, (query[:, :,0: self.n_length, :], key[:, :, 0: self.n_length, :]))]
query_list.append(query_h)
key_list.append(key_h)
query = torch.cat(query_list, dim=3)
key = torch.cat(key_list, dim=3)
elif (not query_multi_segment) and (not key_multi_segment):
query, key = [l(x.permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2) for l, x in zip(self.conv1Ds_aware_temporal_context, (query, key))]
elif (not query_multi_segment) and (key_multi_segment):
query = self.conv1Ds_aware_temporal_context[0](query.permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key_list = []
if self.n_length > 0:
key_h = self.conv1Ds_aware_temporal_context[1](key[:, :, 0:self.n_length, :].permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key_list.append(key_h)
key = torch.cat(key_list, dim=3)
else:
import sys
print('error')
sys.out
# deal with value:
# (batch, N, T, d_model) -linear-> (batch, N, T, d_model) -view-> (batch, N, T, h, d_k) -permute(2,3)-> (batch, N, h, T, d_k)
value = self.linears[0](value).view(nbatches, N, -1, self.h, self.d_k).transpose(2, 3)
# apply attention on all the projected vectors in batch
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# x:(batch, N, h, T1, d_k)
# attn:(batch, N, h, T1, T2)
x = x.transpose(2, 3).contiguous() # (batch, N, T1, h, d_k)
x = x.view(nbatches, N, -1, self.h * self.d_k) # (batch, N, T1, d_model)
return self.linears[-1](x)
class MultiHeadAttentionAwareTemporalContex_qc_k1d(nn.Module): # query: causal conv; key 1d conv
def __init__(self, nb_head, d_model, num_of_lags, points_per_lag, kernel_size=3, dropout=.0):
super(MultiHeadAttentionAwareTemporalContex_qc_k1d, self).__init__()
assert d_model % nb_head == 0
self.d_k = d_model // nb_head
self.h = nb_head
self.linears = clones(nn.Linear(d_model, d_model), 2) # 2 linear layers: 1 for W^V, 1 for W^O
self.causal_padding = kernel_size - 1
self.padding_1D = (kernel_size - 1)//2
self.query_conv1Ds_aware_temporal_context = nn.Conv2d(d_model, d_model, (1, kernel_size), padding=(0, self.causal_padding))
self.key_conv1Ds_aware_temporal_context = nn.Conv2d(d_model, d_model, (1, kernel_size), padding=(0, self.padding_1D))
self.dropout = nn.Dropout(p=dropout)
self.n_length = num_of_lags * points_per_lag
def forward(self, query, key, value, mask=None, query_multi_segment=False, key_multi_segment=False):
'''
:param query: (batch, N, T, d_model)
:param key: (batch, N, T, d_model)
:param value: (batch, N, T, d_model)
:param mask: (batch, T, T)
:param query_multi_segment: whether query has mutiple time segments
:param key_multi_segment: whether key has mutiple time segments
if query/key has multiple time segments, causal convolution should be applied separately for each time segment.
:return: (batch, N, T, d_model)
'''
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(1) # (batch, 1, 1, T, T), same mask applied to all h heads.
nbatches = query.size(0)
N = query.size(1)
# deal with key and query: temporal conv
# (batch, N, T, d_model)->permute(0, 3, 1, 2)->(batch, d_model, N, T) -conv->(batch, d_model, N, T)-view->(batch, h, d_k, N, T)-permute(0,3,1,4,2)->(batch, N, h, T, d_k)
if query_multi_segment and key_multi_segment:
query_list = []
key_list = []
if self.n_length > 0:
query_h = self.query_conv1Ds_aware_temporal_context(query[:, :, 0: self.n_length, :].permute(0, 3, 1, 2))[:, :, :, :-self.causal_padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1,
4, 2)
key_h = self.key_conv1Ds_aware_temporal_context(key[:, :,0: self.n_length, :].permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
query_list.append(query_h)
key_list.append(key_h)
query = torch.cat(query_list, dim=3)
key = torch.cat(key_list, dim=3)
elif (not query_multi_segment) and (not key_multi_segment):
query = self.query_conv1Ds_aware_temporal_context(query.permute(0, 3, 1, 2))[:, :, :, :-self.causal_padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key = self.key_conv1Ds_aware_temporal_context(query.permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
elif (not query_multi_segment) and (key_multi_segment):
query = self.query_conv1Ds_aware_temporal_context(query.permute(0, 3, 1, 2))[:, :, :, :-self.causal_padding].contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key_list = []
if self.n_length > 0:
key_h = self.key_conv1Ds_aware_temporal_context(key[:, :, 0: self.n_length, :].permute(0, 3, 1, 2)).contiguous().view(
nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
key_list.append(key_h)
key = torch.cat(key_list, dim=3)
else:
import sys
print('error')
sys.out
# deal with value:
# (batch, N, T, d_model) -linear-> (batch, N, T, d_model) -view-> (batch, N, T, h, d_k) -permute(2,3)-> (batch, N, h, T, d_k)
value = self.linears[0](value).view(nbatches, N, -1, self.h, self.d_k).transpose(2, 3)
# apply attention on all the projected vectors in batch
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# x:(batch, N, h, T1, d_k)
# attn:(batch, N, h, T1, T2)
x = x.transpose(2, 3).contiguous() # (batch, N, T1, h, d_k)
x = x.view(nbatches, N, -1, self.h * self.d_k) # (batch, N, T1, d_model)
return self.linears[-1](x)
class EncoderDecoder(nn.Module):
def __init__(self, encoder, trg_dim,decoder1, src_dense, encode_temporal_position,decode_temporal_position, generator1, DEVICE,spatial_position): #generator2,
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder1 = decoder1
# self.decoder2 = decoder2
self.src_embed = src_dense
# self.trg_embed = trg_dense
self.encode_temporal_position = encode_temporal_position
self.decode_temporal_position = decode_temporal_position
self.prediction_generator1 = generator1
# self.prediction_generator2 = generator2
self.spatial_position = spatial_position
self.trg_dim = trg_dim
self.to(DEVICE)
def forward(self, src, trg,x,y,te,td):
'''
src: (batch_size, N, T_in, F_in)
trg: (batch, N, T_out, F_out)
'''
encoder_output = self.encode(src,x,y,te) # (batch_size, N, T_in, d_model)
trg_shape = self.trg_dim#int(trg.shape[-1]/2)
return self.decode1(trg[:, :, :, -trg_shape:], encoder_output, trg[:, :, :, :trg_shape],x,y,td)#trg[:, :, :, :trg_shape],x,y,td) # src[:,:,-1:,:2])#
def encode(self, src,x,y,t):
'''
src: (batch_size, N, T_in, F_in)
'''
src_emb = self.src_embed(src)
if self.encode_temporal_position ==False:
src_tmpo_emb = src_emb
else:
src_tmpo_emb = self.encode_temporal_position(src_emb,t)
if self.spatial_position == False:
h = src_tmpo_emb
else:
h = self.spatial_position(src_tmpo_emb, x,y)
return self.encoder(h)
def decode1(self, trg, encoder_output,encoder_input,x,y,t):
trg_embed = self.src_embed
trg_emb_shape = self.trg_dim
trg_emb = torch.matmul(trg, list(trg_embed.parameters())[0][:, trg_emb_shape:].T)
if self.encode_temporal_position ==False:
trg_tempo_emb = trg_emb
else:
trg_tempo_emb = self.decode_temporal_position(trg_emb, t)
if self.spatial_position ==False:
a = self.prediction_generator1(self.decoder1(trg_tempo_emb, encoder_output))+encoder_input#[:,:,:,0:2]
return a
else:
a = self.prediction_generator1(self.decoder1(self.spatial_position(trg_tempo_emb,x,y), encoder_output))+encoder_input#[:,:,:,0:2]
return a
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, gcn, dropout, residual_connection=True, use_LayerNorm=True):
super(EncoderLayer, self).__init__()
self.residual_connection = residual_connection
self.use_LayerNorm = use_LayerNorm
self.self_attn = self_attn
self.feed_forward_gcn = gcn
if residual_connection or use_LayerNorm:
self.sublayer = clones(SublayerConnection(size, dropout, residual_connection, use_LayerNorm), 2)
self.size = size
def forward(self, x):
'''
:param x: src: (batch_size, N, T_in, F_in)
:return: (batch_size, N, T_in, F_in)
'''
if self.residual_connection or self.use_LayerNorm:
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, query_multi_segment=True, key_multi_segment=True))
return self.sublayer[1](x, self.feed_forward_gcn)
else:
x = self.self_attn(x, x, x, query_multi_segment=True, key_multi_segment=True)
return self.feed_forward_gcn(x)
class Encoder(nn.Module):
def __init__(self, layer, N):
'''
:param layer: EncoderLayer
:param N: int, number of EncoderLayers
'''
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = nn.LayerNorm(layer.size)
def forward(self, x):
'''
:param x: src: (batch_size, N, T_in, F_in)
:return: (batch_size, N, T_in, F_in)
'''
for layer in self.layers:
x = layer(x)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, gcn, dropout, residual_connection=True, use_LayerNorm=True):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward_gcn = gcn
self.residual_connection = residual_connection
self.use_LayerNorm = use_LayerNorm
if residual_connection or use_LayerNorm:
self.sublayer = clones(SublayerConnection(size, dropout, residual_connection, use_LayerNorm), 3)
def forward(self, x, memory):
'''
:param x: (batch_size, N, T', F_in)
:param memory: (batch_size, N, T, F_in)
:return: (batch_size, N, T', F_in)
'''
m = memory
tgt_mask = subsequent_mask(x.size(-2)).to(m.device) # (1, T', T')
if self.residual_connection or self.use_LayerNorm:
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask, query_multi_segment=False, key_multi_segment=False)) # output: (batch, N, T', d_model)
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, query_multi_segment=False, key_multi_segment=True)) # output: (batch, N, T', d_model)
return self.sublayer[2](x, self.feed_forward_gcn) # output: (batch, N, T', d_model)
else:
x = self.self_attn(x, x, x, tgt_mask, query_multi_segment=False, key_multi_segment=False) # output: (batch, N, T', d_model)
x = self.src_attn(x, m, m, query_multi_segment=False, key_multi_segment=True) # output: (batch, N, T', d_model)
return self.feed_forward_gcn(x) # output: (batch, N, T', d_model)
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = nn.LayerNorm(layer.size)
def forward(self, x, memory):
'''
:param x: (batch, N, T', d_model)
:param memory: (batch, N, T, d_model)
:return:(batch, N, T', d_model)
'''
for layer in self.layers:
x = layer(x, memory)
return self.norm(x)
class EmbedLinear(nn.Module):
def __init__(self, encoder_input_size, d_model,bias=False):
'''
:param layer: EncoderLayer
:param N: int, number of EncoderLayers
'''
super(EmbedLinear, self).__init__()
self.layers = nn.Linear(encoder_input_size, d_model, bias=bias)
def forward(self, x):
'''
:param x: src: (batch_size, N, T_in, F_in)
:return: (batch_size, N, T_in, F_in)
'''
#for layer in self.layers:
y = self.layers(x)
return y
def search_index(max_len, num_of_depend, num_for_predict,points_per_hour, units):
'''
Parameters
----------
max_len: int, length of all encoder input
num_of_depend: int,
num_for_predict: int, the number of points will be predicted for each sample
units: int, week: 7 * 24, day: 24, recent(hour): 1
points_per_hour: int, number of points per hour, depends on data
Returns
----------
list[(start_idx, end_idx)]
'''
x_idx = []
for i in range(1, num_of_depend + 1):
start_idx = max_len - points_per_hour * units * i
for j in range(num_for_predict):
end_idx = start_idx + j
x_idx.append(end_idx)
return x_idx
def make_model(DEVICE,logitudelatitudes, num_layers, encoder_input_size,decoder_input_size, decoder_output_size, d_model, adj_mx, nb_head, num_of_lags,points_per_lag,
num_for_predict, dropout=.0, aware_temporal_context=True,
ScaledSAt=True, SE=True, TE=True, kernel_size=3, smooth_layer_num=0, residual_connection=True, use_LayerNorm=True):
# LR rate means: graph Laplacian Regularization
c = copy.deepcopy
norm_Adj_matrix = torch.from_numpy(norm_Adj(adj_mx)).type(torch.FloatTensor).to(DEVICE) # 通过邻接矩阵,构造归一化的拉普拉斯矩阵
num_of_vertices = norm_Adj_matrix.shape[0]
src_dense = EmbedLinear(encoder_input_size, d_model, bias=False)#nn.Linear(encoder_input_size, d_model, bias=False)
if ScaledSAt: # employ spatial self attention
position_wise_gcn = PositionWiseGCNFeedForward(spatialAttentionScaledGCN(norm_Adj_matrix, d_model, d_model), dropout=dropout)
else: #
position_wise_gcn = PositionWiseGCNFeedForward(spatialGCN(norm_Adj_matrix, d_model, d_model), dropout=dropout)
# encoder temporal position embedding
max_len = num_of_lags
if aware_temporal_context: # employ temporal trend-aware attention
attn_ss = MultiHeadAttentionAwareTemporalContex_q1d_k1d(nb_head, d_model, num_of_lags, points_per_lag, kernel_size, dropout=dropout)
attn_st = MultiHeadAttentionAwareTemporalContex_qc_k1d(nb_head, d_model,num_of_lags, points_per_lag, kernel_size, dropout=dropout)
att_tt = MultiHeadAttentionAwareTemporalContex_qc_kc(nb_head, d_model, num_of_lags, points_per_lag, kernel_size, dropout=dropout)
else: # employ traditional self attention
attn_ss = MultiHeadAttention(nb_head,d_model, dropout=dropout) #d_model, dropout=dropout)
attn_st = MultiHeadAttention(nb_head,d_model, dropout=dropout)# d_model, dropout=dropout)
att_tt = MultiHeadAttention(nb_head,d_model, dropout=dropout) #d_model, dropout=dropout)
encode_temporal_position = TemporalPositionalEncoding(d_model, dropout, max_len) # en_lookup_index decoder temporal position embedding
decode_temporal_position = TemporalPositionalEncoding(d_model, dropout, num_for_predict)
spatial_position = SpatialPositionalEncoding_RBF(d_model, logitudelatitudes,num_of_vertices, dropout, GCN(norm_Adj_matrix, d_model, d_model), smooth_layer_num=smooth_layer_num) #logitudelatitudes,
encoderLayer = EncoderLayer(d_model, attn_ss, c(position_wise_gcn), dropout, residual_connection=residual_connection, use_LayerNorm=use_LayerNorm)
encoder = Encoder(encoderLayer, num_layers)
decoderLayer1 = DecoderLayer(d_model, att_tt, attn_st, c(position_wise_gcn), dropout, residual_connection=residual_connection, use_LayerNorm=use_LayerNorm)
decoder1 = Decoder(decoderLayer1, num_layers)
generator1 = nn.Linear(d_model, decoder_output_size)#
model = EncoderDecoder(encoder,decoder_output_size,
decoder1,
src_dense,
encode_temporal_position,
decode_temporal_position,
generator1,
DEVICE,
spatial_position) #,generator2
# param init
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
以下是pytorch输出的模型结构部分示意图:

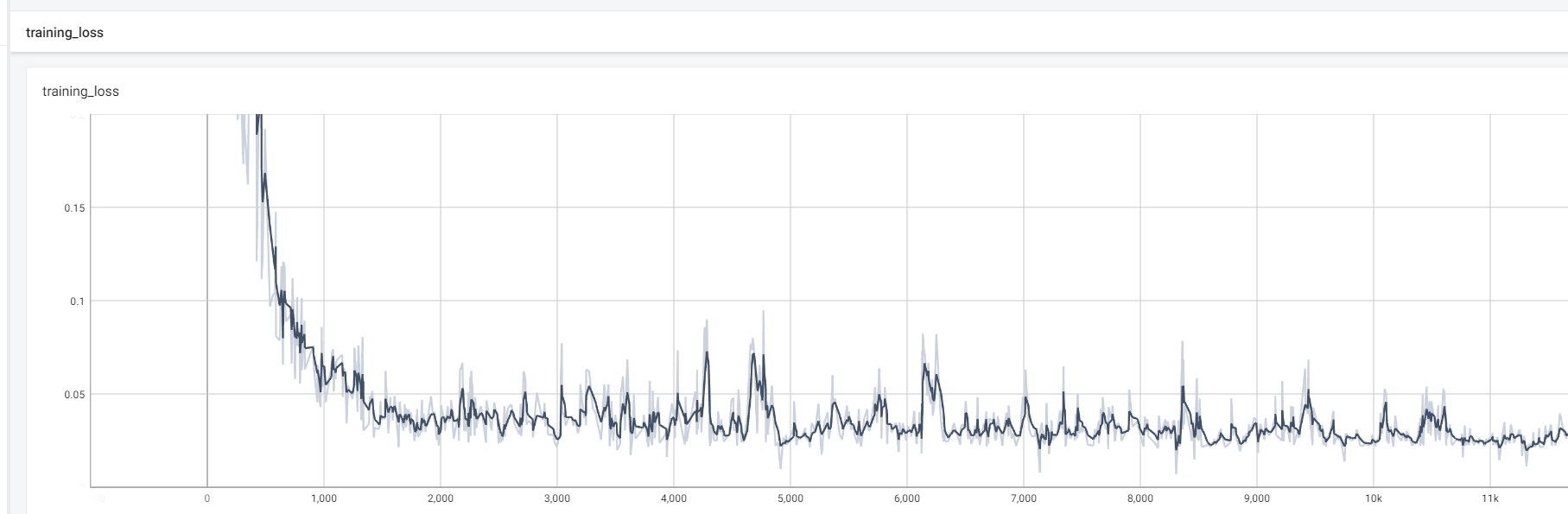
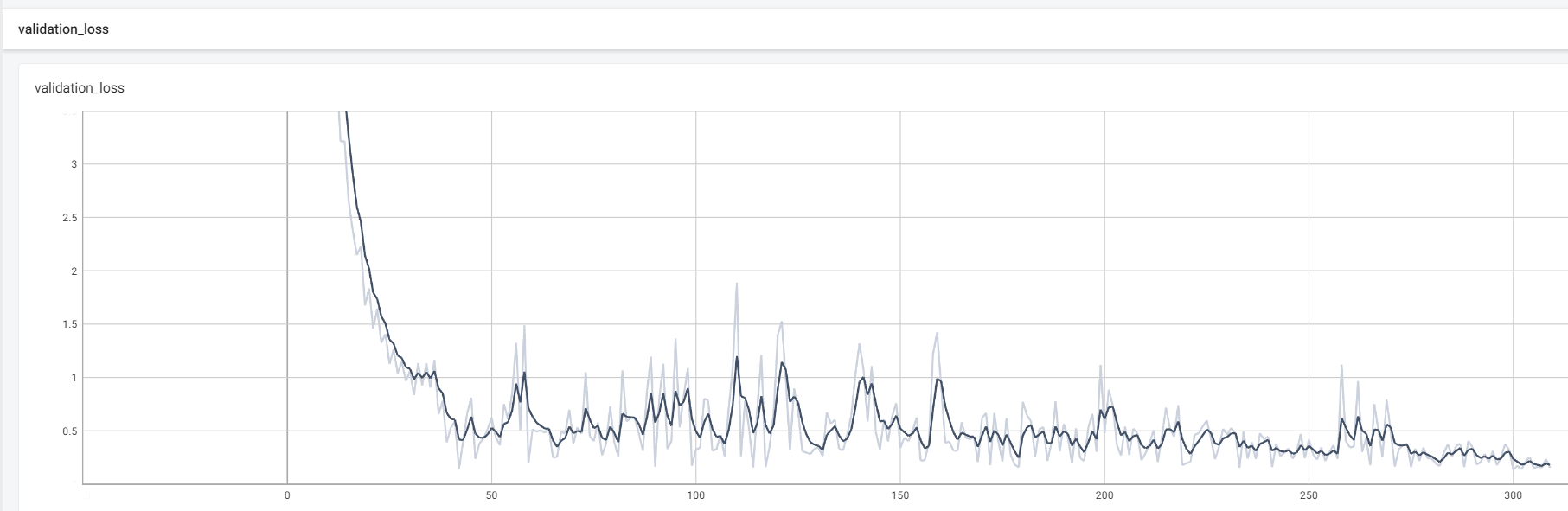
模型训练和验证的损失变化如下图所示:
结论
该研究在aGNN中加入了三个重要的构件,即注意机制和时空嵌入层,以及学习污染物传输对人为源的高度非线性时空依赖性的GCN层。这三个构建块通过在基于物理的污染物运移图结构中采用动态权重分配、先验特征变换和信息传递来提高时空学习精度。在实验中,aGNN的R2值高达99%,这显示了作者集成的注意机制和嵌入层的高水平预测能力。