一、定义
- ollama 定义
- 环境部署
- demo
- 加载本地模型方法
- 基本指令
- 关闭开启ollama
- ollama 如何同时 运行多个模型, 多进程
- ollama 如何分配gpu
- 修改模型的存储路径
二、实现
- ollama 定义
ollama 是llama-cpp 的进一步封装,更加简单易用,类似于docker.
模型网址:https://www.ollama.com/
部署网址:https://github.com/ollama/ollama
教程:https://github.com/ollama/ollama/releases - 环境部署
1. 宿主机安装
curl -fsSL https://ollama.com/install.sh | sh
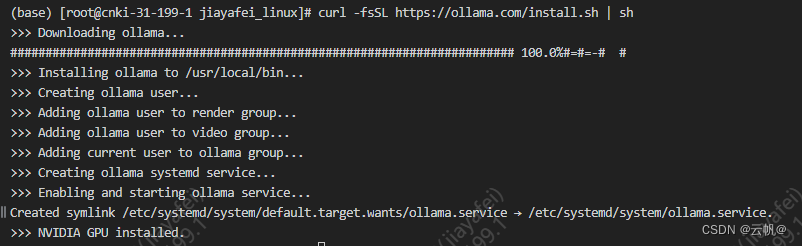
curl http://localhost:11434 已经启动。
远程访问配置:
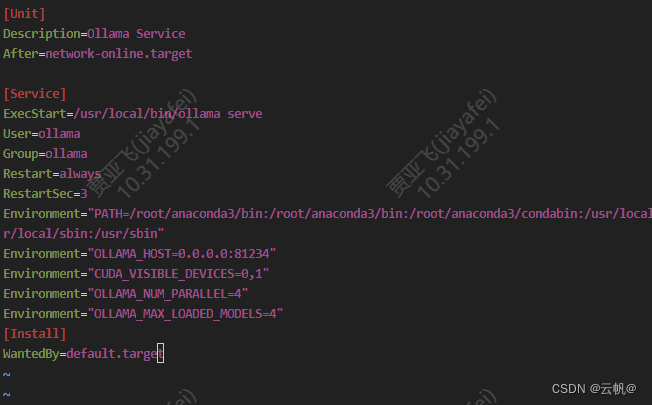
>>sudo vi /etc/systemd/system/ollama.service
对于每个环境变量,在 [Service] 部分下添加一行 Environment:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
保存并退出。
重新加载 systemd 并重新启动 Ollama:
>>systemctl daemon-reload
>>systemctl restart ollama
2. docker 模式安装
https://hub.docker.com/r/ollama/ollama
docker pull ollama/ollama
cpu:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
gpu:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
- 案例
1.加载模型/运行模型
ollama pull llama3:8b

2. 调用模型
方式一、指令交互的方式进行调用
>>ollama run llama3

方式二、api 接口调用
curl http://localhost:11434/api/generate -d '{
"model":"llama3:8b",
"prompt": "请分别翻译成中文 -> Meta Llama 3: The most capable openly available LLM to date",
"stream": false
}'

方式三、 python 接口调用
pip install ollama-python
import ollama
response = ollama.run('llama3:8b', '你好,世界!')
print(response)
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
# 必需但被忽略
api_key='ollama',
)
chat_completion = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': 'Say this is a test',
}
],
model='llama2',
)
- 加载本地模型方法
具体看 官网
4.1 gguf 模型
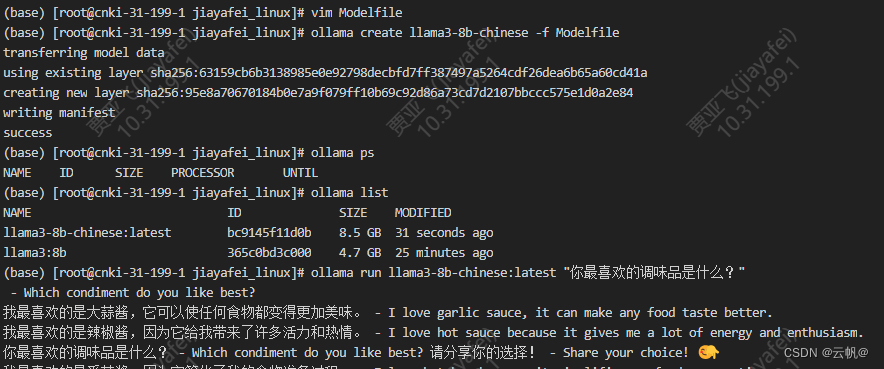
1. 编写Modelfile 文件
FROM ./mistral-7b-v0.1.Q4_0.gguf
2. 创建模型
ollama create llama3-8b:0.001 -f Modelfile
3. 运行/ 测试
ollama run example “你最喜欢的调味品是什么?”
- 基本指令 : 和docker 指令类似,基本重合
journalctl -u ollama 查看日志
journalctl -n 10 查看最新的10条日志
journalctl -f 实时查看新添加的日志条目
ollama -h
(base) [root@cnki-31-199-1 jiayafei_linux]# ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
- ollama 如何同时 运行多个模型, 多进程
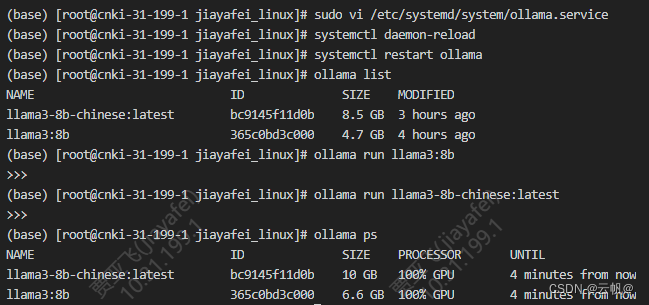
vim /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_NUM_PARALLEL=4" #并行处理请求的数量
Environment="OLLAMA_MAX_LOADED_MODELS=4" #同时加载的模型数量
sudo systemctl daemon-reload
sudo systemctl restart ollama
加载一个模型
ollama run gemma:2b
加载另外一个模型
ollama run llama3:8b
7. ollama 如何分配gpu
本地有多张 GPU,如何用指定的 GPU 来运行 Ollama? 在Linux上创建如下配置文件,并配置环境变量 CUDA_VISIBLE_DEVICES 来指定运行 Ollama 的 GPU,再重启 Ollama 服务即可【测试序号从0还是1开始,应是从0开始】。
$sudo vi /etc/systemd/system/ollama.service
[Service]
Environment="CUDA_VISIBLE_DEVICES=0,1"
systemctl daemon-reload
systemctl restart ollama
- 修改模型的存储路径
mv ~/.ollama/models/* /Users/<username>/Documents/ollama_models 将以前的models移动到当前目录
看上文。