Batch Normalization
是google团队2015年提出的,能够加速网络的收敛并提升准确率
1.Batch Normalization原理
图像预处理过程中通常会对图像进行标准化处理,能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应的feature map的数据要满足分布规律)。而我们BN的目的就是使feature map满足均值为0,方差为1的分布规律。

对于一个拥有d维的输入x,我们将对它的每一个维度进行标准化处理。假设我们输入的x是RGB三通道的彩色图像,那么这里的d就是输入图像的channels即d=3,其中x^1就代表我们的R通道所对应的特征矩阵,依次类推。标准化处理也就是分别对R通道,G通道,B通道进行处理。

让feature map满足某一分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律,也就是说要计算出整个训练集的feature map然后再进行标准化处理,对于一个大型的数据集明显是不可能的,所以论文中说的BN,也就是计算一个Batch数据的feature map然后进行标准化(batch越大越接近整个数据集的分布,效果越好)。

上图展示了一个batch size为2(两张图片)的Batch Normalization的计算过程,假设feature1、feature2分别是由image1、image2经过一系列卷积池化后得到的特征矩阵,feature的channel为2,那么x^1代表batch的所有的feature的channel1的数据。然后分别计算x^1和x^2的均值和方差。然后再根据标准差计算公式分别计算每个channel 的值(是很小的常量,放置分母为0的情况)。在训练过程中要去不断地计算每个batch的均值和方差,并使用移动平均(moving average)的方法记录统计的均值和方差,在训练完后我们可以近似认为所统计的均值和方差就等于整个训练集的均值和方差。然后再我们的验证以及预测过程中,就使用统计得到的均值和方差进行标准化处理。
是用来调整数值分布的方差大小,默认为1,
是用来调节数值均值的位置,默认值为0。这两个参数实在反向传播过程中学习到的。
2.使用Pytorch进行实验
在训练过程中,均值和方差是同通过计算当前批次数据得到的记录为,而我们的验证以及预测过程中使用的均值方差是一个统计量为
。具体更新策略如下,其中momentum默认取0.1:
(1)bn_process函数是自定义的bn处理方法验证是否和使用官方bn处理方法结果一致。在bn_process中计算输入batch数据的每个维度(这里的维度是channel维度)的均值和标准差(标准差等于方差开平方),然后通过计算得到的均值和总体标准差对feature每个维度进行标准化,然后使用均值和样本标准差更新统计均值和标准差。
(2)初始化统计均值是一个元素为0的向量,元素个数等于channel深度;初始化统计方差是一个元素为1的向量,元素个数等于channel深度,初始化=0,
=1。
import numpy as np
import torch.nn as nn
import torch
def bn_process(feature, mean, var):
feature_shape = feature.shape
for i in range(feature_shape[1]):
# [batch,channel, height, weight]
feature_t = feature[:, i, :, :]
mean_t = feature_t.mean()
#总体标准差
std_t1 = feature_t.std()
#样本标准差
std_t2 = feature_t.std(ddof = 1)
#bn process
#这里记得加上eps和pytorch保持一致
feature[:, i, :, :] = (feature[:, i, :, :] - mean_t) / np.sqrt(std_t1 ** 2+ 1e-5)
#更新计算均值
mean[i] = mean[i]*0.9 + mean_t * 0.1
var[i] = var[i] * 0.9 + (std_t2 ** 2) * 0.1
print(feature)
#随机生成一个batch为2,channel为2,height=width=2的特征向量
#[batch, channel, height, width]
feature1 = torch.randn(2, 2, 2, 2)
#初始化统计均值和方差
calculate_mean = [0.0, 0.0]
calculate_var = [1.0, 1.0]
#print(feature1.numpy())
#注意要使用copy()深拷贝
bn_process(feature1.numpy().copy(), calculate_mean, calculate_var)
bn = nn.BatchNorm2d(2, eps = 1e-5)
output = bn(feature1)
print(output) 
3.使用BN时需要注意的问题
(1)训练时要将training采纳数设置为True,在验证时将training参数设置为False。在Pytorch中了可以通过创建模型的model.train()和model.eval()方法控制。
(2)batch size尽可能设置大点,设置小后表现很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
(3)建议将bn层放在卷积层和激活层之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,及时使用了偏置bias求出的结果也是一样的。
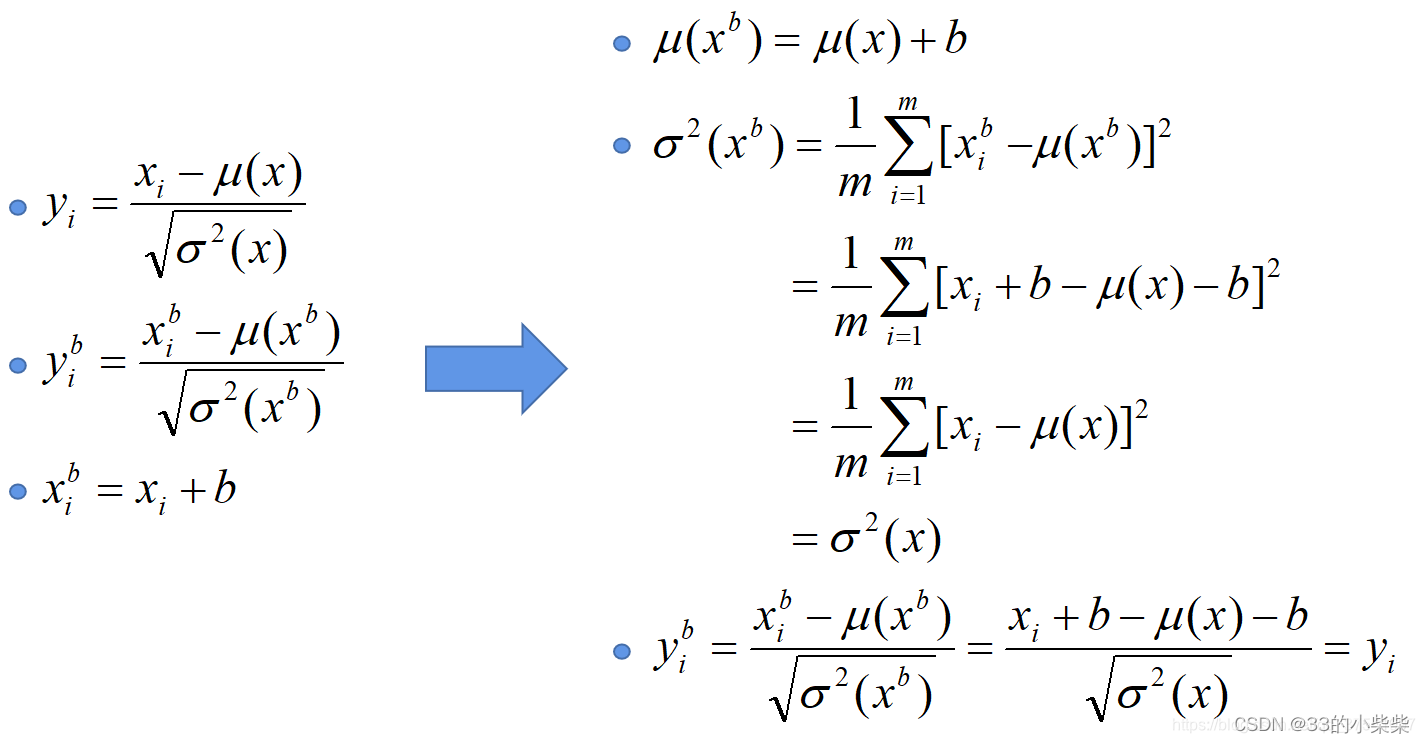
Layer Normalization
Layer Normalization针对自然语言处理提出的,为什么不用BN呢,因为在RNN这类时序网络中,时序的长度并不是一个定值(网络深度不一定相同),比如每句话的长短都不一定相同,所以很难去使用BN,所以作者提出了Layer Normalization(图像处理领域BN比LN更有效),但现在很多人将自然语言领域的模型用来处理图像,比如Vision Transformer,此时会涉及到LN。
直接看Pytorch 官方给出的关于LayerNorm 的介绍。不同的是,BN是对一个batch数据的每个channel进行Norm处理,一个for循环,但LN是对单个数据的制定维度进行Norm处理与batch无关。而且BN中训练时是需要累计moving_mean和moving_var两个变量的(所以BN中有4个参数moving_mean,moving_var,),但LN不需要累计只有
两个参数。
在Pytorch的LayerNorm类中有个normalized_shape参数,可以指定要Norm的维度(注意,函数说明中the last certain number of dimensions,指定的维度必须是从最后一维开始)。比如我们的数据shape是[4,2,3],那么normalized_shape可以是[3](最后一维进行Norm处理),也可以是[2,3](Norm最后两个维度),也可以是整个维度[4,2,3],但不能是[2]或者[4,2],否则会报错。
import torch
import torch.nn as nn
def layer_norm_process(feature:torch.Tensor, beta=0.,gamma = 1.,eps=1e-5):
var_mean = torch.var_mean(feature, dim = -1, unbiased = False)
#均值
mean = var_mean[1]
#方差
var = var_mean[0]
#layer norm process
feature = (feature - mean[..., None]) / torch.sqrt(var[..., None] + eps)
feature = feature*gamma+beta
return feature
def main():
t = torch.randn(4, 2, 3)
print(t)
#仅在最后一个维度上做norm处理
norm = nn.LayerNorm(normalized_shape= t.shape[-1], eps = 1e-5)
#官方layer norm处理
t1 = norm(t)
#自己实现的layer norm处理
t2 = layer_norm_process(t, eps = 1e-5)
print("t1:\n",t1)
print("t2:\n",t2)
if __name__ == '__main__':
main()tensor([[[ 0.8512, 0.4201, -0.3457],
[ 0.4701, -0.0647, 0.0733]],
[[-0.9950, -0.4634, 0.0540],
[ 0.4096, 0.4037, -0.0914]],
[[-2.3165, 1.3059, 0.3183],
[-0.9716, 0.4956, 0.4524]],
[[-0.6209, -0.5958, 0.3212],
[-0.8762, 0.3176, -0.5427]]])
t1:
tensor([[[ 1.0963, 0.2254, -1.3218],
[ 1.3697, -0.9893, -0.3804]],
[[-1.2302, 0.0110, 1.2192],
[ 0.7198, 0.6942, -1.4140]],
[[-1.3642, 1.0050, 0.3591],
[-1.4137, 0.7385, 0.6752]],
[[-0.7355, -0.6783, 1.4138],
[-1.0123, 1.3614, -0.3490]]], grad_fn=<NativeLayerNormBackward0>)
t2:
tensor([[[ 1.0963, 0.2254, -1.3218],
[ 1.3697, -0.9893, -0.3804]],
[[-1.2302, 0.0110, 1.2192],
[ 0.7198, 0.6942, -1.4140]],
[[-1.3642, 1.0050, 0.3591],
[-1.4137, 0.7385, 0.6752]],
[[-0.7355, -0.6783, 1.4138],
[-1.0123, 1.3614, -0.3490]]])