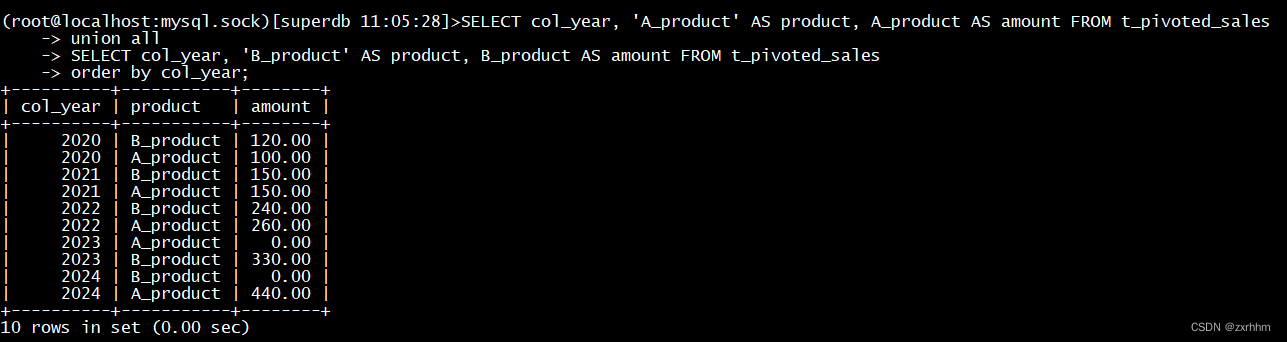
弱监督的WSI分类通常被形式化为多实例学习(MIL)问题,其中每张slide都被视为一个bag,从中切出的patch被视为实例。现有的方法要么通过伪标记训练实例分类器,要么通过注意力机制将实例特征聚合为bag特征,然后训练袋分类器,其中注意力得分可以用于实例级分类。然而,前者构建的伪实例标签通常包含大量噪声,而后者构建的注意力得分不够准确,这两者都会影响它们的性能。在这里,作者提出了一个基于对比学习和原型学习的实例级MIL框架,以有效地完成实例分类和袋分类任务。贡献如下:
- 首次提出了一种在MIL设置下的实例级弱监督对比学习算法,以有效地学习实例特征表示。
- 提出了一种通过原型学习精确生成伪标签的方法。
- 开发了一种用于弱监督对比学习、原型学习和实例分类器训练的联合训练策略。
来自:Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Good Instance Classifier is All You Need
工程:https://github.com/miccaiif/INS
目录
- 背景概述
- related work-基于实例的MIL
- related work-基于bag的MIL
- related work-MIL与对比学习
- related work-MIL与原型学习
- Reference
- 方法
- 问题定义
- 框架概述
- 实例级弱监督对比学习
- family集和non-family集样本
- 对比损失
- embedding队列更新
- 基于原型生成伪标签与bag约束
- 伪标签生成
- 原型更新
- 实例分类器损失
- Bag约束
- 实验设置
- 数据集
- CIFAR-10
- Camelyon16
- TCGA lung cancer
- Cervical Cancer
- 评价指标和对比方法
- 实现细节
背景概述
基于深度学习的WSI处理技术有望极大地促进病理图像诊断和分析的自动化。然而,WSI在大小上与自然图像大不相同,大小可以在1亿到100亿像素之间,这使得无法将为自然图像开发的深度学习模型直接用于WSI。将WSI划分为许多不重叠的小patch进行处理是一种常见的方法,但为这些patch提供细粒度的注释是非常昂贵的(一个WSI通常可以产生数万个patch),这使得基于patch的监督方法不可行。因此,基于MIL的方法变成主流。在MIL设置中,每个WSI作为一个bag,patch作为instance。对于阳性袋子,至少有一个阳性实例,而对于阴性袋子,所有实例都是阴性的。在临床应用中,WSI分类有两个主要任务:袋级分类和实例级分类,袋级分类准确预测WSI的类别,实例级分类准确识别阳性实例。
目前,用于WSI分类的MIL方法可分为基于实例的方法和基于袋的方法。基于实例的方法通常用伪标签训练实例分类器,然后聚合实例的预测以获得袋级预测。这种方法的主要问题是实例伪标签包含大量噪声。由于每个实例的真实标签是未知的,因此分配给所有实例的伪标签的质量是决定这类方法性能的关键因素。然而,现有的研究通常通过继承袋子的标签来分配实例伪标签,这导致伪标签中存在大量噪声,极大地限制了它们的性能。图1A显示了基于实例的方法的典型训练过程和问题。
基于bag的方法首先使用实例级特征提取器来提取袋子中每个实例的特征,然后聚合这些特征以获得袋子级特征,用于训练bag分类器。最近的基于bag的方法利用注意力机制来聚合实例特征,并引入了一个独立的score模块来为每个实例特征生成可学习的注意力权重,该权重可用于实现实例级分类。尽管这种类型的方法克服了基于实例的方法中有噪声标签的问题,但它也存在以下问题:
- 实例级分类性能低。研究发现,在同一个阳性袋中识别不同阳性病例的难度不同,例如,肿瘤面积较大的病例比肿瘤面积较小的病例更容易识别。基于注意力的方法定义了袋级别的损失,这通常导致这样的结果,即通过高注意力得分只找到了最容易识别的阳性实例,而忽略了其他更难识别的实例。换句话说,模型只为最容易识别的阳性实例分配更高的注意力权重,以实现正确的袋分类,而不去找到所有的阳性实例,这大大限制了其实例级分类性能。
- 袋分类性能不稳定。如前所述,袋分类在很大程度上依赖于score网络分配给每个实例的注意力分数。当这些注意力得分不准确时,袋分类器的性能也会受到影响。比如,在对具有大量困难阳性实例而很少有容易阳性实例的bag进行分类时很容易失效。
图1B显示了基于bag方法的训练过程和问题。
在基于深度学习的MIL研究史上,尽管最早提出了基于实例的方法,但它们对难以获得的实例伪标签的依赖导致了性能瓶颈。相反,越来越多的研究人专注于在bag水平上使用更强的基于注意力的方法来提供准确的注意力得分。然而,直观地说,只要损失函数是在bag级别定义的,基于注意力的score方法就不可避免地会在寻找更困难的阳性实例方面表现出“懒惰”。与上述研究不同,作者提出了一种基于实例以及基于对比学习和原型学习的MIL框架,称为INS。图1C展示了INS的主要思想和基本组件。主要目标是在细粒度实例级别直接训练一个高效的实例分类器,这需要满足两个要求:
- 获得良好的实例级别特征表示,
- 为每个实例分配一个准确的伪标签。
为此,作者首次在MIL设置中提出了实例级弱监督对比学习(IWSCL,instance-level weakly supervised contrastive learning),以学习良好的实例表示,更好地分离特征空间中的阴性实例和阳性实例。作者还提出了基于原型的伪标签生成(PPLG)策略,该策略通过维护两个代表性特征向量作为原型,一个用于阴性实例,另一个用于阳性实例,为每个实例生成高质量的伪标签。作者进一步为IWSCL、PPLG和实例分类器开发了一种联合训练策略。总之,IWSCL和PPLG是在实例分类器预测的指导下完成的。同时,IWSCL的良好特征表示和PPLG的准确伪标签可以进一步改进实例分类器。更重要的是,作者有效地利用训练集中阴性bag中的真实阴性实例来指导所有实例分类器,IWSCL和PPLG,确保INS朝着正确的方向迭代。在训练了实例分类器之后,由于其强大的实例分类性能,可以使用简单的mean pooling来完成准确的袋分类。
作者使用模拟的CIFAR10数据集和三个包含乳腺癌、肺癌和cervical cancer(宫劲癌)的真实数据集,全面评估了INS在六项任务中的性能。大量的实验结果表明,与最先进的方法相比,INS在实例和bag分类方面都取得了更好的性能。更重要的是,实验不仅包括人类医生可以直接从H&E染色的载玻片中判断的任务,如肿瘤诊断和肿瘤分型,还包括人类医生无法直接从HE载玻片中做出决定的任务,包括预测原发病变的淋巴结转移、患者预后和免疫组织化学标志物的预测。鉴于INS强大的实例级分类能力,我们可以在这些困难的临床任务中使用它进行可解释的研究和新知识发现。在预测癌症原发病灶的淋巴结转移的任务中,作者使用INS对高风险和低风险病例进行分类,从而确定表明淋巴结转移高风险的“Micropapillae”病理模式。

- 图1:A.现有的基于实例的MIL方法通常将袋子的标签作为伪标签分配给其实例,导致实例伪标签中存在大量噪声。
- B.基于bag的MIL方法的损失函数是在袋层面定义的,通常只找到最容易识别的阳性实例,而忽略其他困难的实例。
- C.与这些方法相比,作者提出了一个有效的基于实例的MIL框架,该框架基于对比学习和原型学习以及联合训练策略。目标是使用实例级弱监督对比学习和伪标签生成来开发一种有效的实例分类器。对比学习旨在改进实例表征,以便更好地区分特征空间中的阴性实例和阳性实例。然后基于代表性特征向量为每个实例生成高质量伪标签。特征学习和伪标签生成都以实例分类器为指导,增强其能力。
related work-基于实例的MIL
基于实例的方法通过为每个实例分配伪标签来训练实例分类器,而袋分类是通过聚合袋中所有实例的预测来实现的。早期的方法通常将袋标签分配给其所有实例,导致阳性袋中有大量嘈杂的标签。最近的一些方法[15,16,13]选择关键实例,仅用于训练,从而在一定程度上减少了噪声的影响(仅为关键实例分配标签)。作者提出了一个强大的实例分类器,作者认为一个好的实例分类器需要良好的实例级表示学习和准确的伪实例标签。为了实现这一目标,提出了在MIL设置下的实例级弱监督对比学习,实现了高效的实例特征表示。
related work-基于bag的MIL
基于袋的方法首先提取实例特征,然后将这些特征聚合到袋中以生成用于训练袋分类器的袋特征。基于注意力的方法[18, 23]是该范式的主流,通常对每个实例特征使用独立的score网络来产生可学习的注意力权重,该权重也可用于生成实例预测。这些方法的主要问题是无法准确识别困难的正实例,导致实例和袋分类性能有限。最近,一些研究[14]将实例级分类损失添加到bag损失中,但分配给实例的伪标签仍然是噪声的。此外,还提出了一些使用图学习[35]和贝叶斯学习[36]来实现WSI分类的方法。然而,它们都不能有效地完成实例分类任务。
related work-MIL与对比学习
现有方法通常首先使用WSI patch通过自监督学习对实例级特征提取器进行预训练,然后使用提取的特征进行模型训练。他们中的大多数使用对比自监督学习方法[40]来提取实例特征,但这个过程是完全无监督的,它只能尝试尽可能多地分离所有实例,而不能有效地分离阳性实例和阴性实例。在最新的研究中,[27]提出了一种基于特征的袋级对比学习方法,但仍无法进行有效的实例分类。相反,作者提出了在MIL设置下的实例级弱监督对比学习(IWSCL)。图2显示了现有对比学习方法与所提出的IWSCL之间的差异。

- 图2:红色框和蓝色框分别表示阳性实例和阴性实例。“Ins”是实例的缩写,“pos”表示阳性,“neg”表示阴性,“CL”表示对比学习。A.自监督的实例级对比学习尽可能地分离实例特征,无论它们是阳性的还是阴性的。B.袋级的弱监督对比学习没有考虑实例特征。C.所提出的IWSCL试图在特征空间中直接分离阳性实例和阴性实例。
related work-MIL与原型学习
原型学习源于最近均值分类器,旨在为实例提供表示。最近的研究证明了使用原型进行表示和判别的潜力[50]。PMIL[52]采用无监督聚类来构建原型,通过评估bag内的实例相似性来增强袋子特征。TPMIL[53]创建可学习的原型,利用注意力得分作为软的伪标签来分配实例(label只有阳性和阴性)。然而,PMIL的不可学习原型专注于bag特征,这对细粒度的实例分类提出了挑战。TPMIL在很大程度上依赖于注意力得分,而注意力得分往往无法准确识别那些困难的阳性实例。
准确地说,原型不是局部特征的描述,而是一个完整类的代表,可以理解为meta cells。
Reference
[15] Clinical-grade computational pathology using weakly supervised deep learning on whole slide images
[16] Multiple Instance Learning with Center Embeddings for Histopathology Classification
[13] DGMIL: Distribution Guided Multiple Instance Learning for Whole Slide Image Classification
[18] Attention-based deep multiple instance learning, ICML, 2018
[23] DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for Histopathology Whole Slide Image Classification, CVPR, 2022
[14] Bi-directional Weakly Supervised Knowledge Distillation for Whole Slide Image Classification, NIPS, 2022
[35] Hybrid Graph Convolutional Network With Online Masked Autoencoder for Robust Multimodal Cancer Survival Prediction, TMI, 2023
[36] Bayesian Collaborative Learning for Whole-Slide Image Classification, TMI, 2023
[40] A simple framework for contrastive learning of visual representations, ICML, 2020
[27] Scl-wc: Cross-slide contrastive learning for weakly-supervised whole-slide image classification, NIPS, 2022
[50] Weakly supervised 3d point cloud segmentation via multi-prototype learning, TCSVT, 2023
[52] Prototypical multiple instance learning for predicting lymph node metastasis of breast cancer from whole-slide pathological images, MIA, 2023
[53] TPMIL: Trainable Prototype Enhanced Multiple Instance Learning for Whole Slide Image Classification, MIDL, 2023
方法
问题定义
给定数据集
X
=
{
X
1
,
.
.
.
,
X
N
}
X=\left\{X_{1},...,X_{N}\right\}
X={X1,...,XN}包含
N
N
N个WSIs,
X
i
X_{i}
Xi可以导出不重叠的patches
{
x
i
,
j
,
j
=
1
,
2
,
.
.
.
,
n
i
}
\left\{x_{i,j},j=1,2,...,n_{i}\right\}
{xi,j,j=1,2,...,ni},其中,
n
i
n_{i}
ni是
X
i
X_{i}
Xi中的patch数量。bag标签是
Y
i
∈
{
0
,
1
}
,
i
=
1
,
.
.
.
,
N
Y_{i}\in\left\{0,1\right\},i=1,...,N
Yi∈{0,1},i=1,...,N。注意bag标签和instance标签
{
y
i
,
j
,
j
=
1
,
2
,
.
.
.
,
n
i
}
\left\{y_{i,j},j=1,2,...,n_{i}\right\}
{yi,j,j=1,2,...,ni}之间有下面关系:

这表明阴性bag中的所有实例都是阴性的,而在阳性bag中,至少存在一个阳性实例。在弱监督MIL的设置中,只有训练集中bag的标签可用,而且阳性bag中的实例的标签未知。目标是准确预测测试集中每个bag的标签(包分类)和每个实例的标签(实例分类)。
框架概述
图3展示了INS的总体框架,旨在使用实例级弱监督对比学习(IWSCL)和基于原型的伪标签生成(PPLG)来训练高效的实例分类器。作者使用训练集中阴性bag中的真实负实例来指导所有实例分类器,IWSCL和PPLG,确保INS朝着正确的方向迭代。
具体来说,在一次迭代中,首先从训练集中的所有实例中随机选择一个实例 x i , j x_{i,j} xi,j,并使用两个不同的augmentations生成query view和key view。对于query view分支,query view输入编码器,然后将其输出到实例分类器和基于MLP的投影器,以分别获得预测的类 y ^ i , j ∈ R 2 \widehat{y}_{i,j}\in R^{2} y i,j∈R2(表示阴性或者阳性的one-hot vector)和特征embedding q i , j ∈ R d q_{i,j}\in R^{d} qi,j∈Rd。对于key view分支,key view输入到编码器,然后将其输出到投影器,以获得特征嵌入 k i , j ∈ R d k_{i,j}∈R^{d} ki,j∈Rd,其中编码器和投影器都是通过query view分支中基于动量的方法更新的。
受MOCO和Pico的启发,这里维护了一个大的embedding队列来存储Key View分支的特征嵌入以及相应实例的预测类标签。然后,使用当前实例的
y
^
i
,
j
,
q
i
,
j
,
k
i
,
j
\widehat{y}_{i,j},q_{i,j},k_{i,j}
y
i,j,qi,j,ki,j和来自先前迭代的embedding队列来执行实例级弱监督对比学习(IWSCL)。对于
q
i
,
j
q_{i,j}
qi,j,我们拉近embedding队列中具有相同预测类的实例嵌入,并推开具有不同预测类的嵌入。在PPLG模块中,我们在训练期间维护两个具有代表性的特征向量作为阳性类和阴性类的原型。我们使用
q
i
,
j
q_{i,j}
qi,j和来自上一次迭代的原型向量来生成
x
i
,
j
x_{i,j}
xi,j的伪标签。最后,我们使用
y
^
i
,
j
,
k
i
,
j
\widehat{y}_{i,j},k_{i,j}
y
i,j,ki,j更新embedding队列,使用
y
^
i
,
j
,
q
i
,
j
\widehat{y}_{i,j},q_{i,j}
y
i,j,qi,j更新原型向量,并使用生成的伪标签训练实例分类器,从而完成当前迭代。此外,为了防止训练过程中bag-level下降,添加了bag-level约束损失函数。

- 图3:INS架构
实例级弱监督对比学习
在对比学习中,最重要的步骤是构建阳性样本集和阴性样本集,然后通过在特征空间中拉近阳性样本和推远阴性样本来学习稳健的特征表示。为了区分MIL环境中的阳性和阴性实例,我们分别使用family/non-family样本集来表示对比学习中的阳性/阴性样本集。
在传统的自监督对比学习中,构建family集和non-family集的标准方法是使用同一样本的两个数据增强视图作为family样本,而所有其他样本都被视为non-family集。这只能迫使所有样本在特征空间中尽可能远离彼此,导致不能在MIL设置中分离阳性实例和阴性实例。相反,在MIL设置中,训练集中来自阴性bag的所有实例都具有真正的阴性标签。这种弱标签信息可以有效地指导实例级对比学习,而这在现有研究中被忽视了。INS在训练期间维护一个很大的embedding队列,以存储大量实例的特征嵌入 k i , j k_{i,j} ki,j及其由实例分类器预测的类 y ^ i , j \widehat{y}_{i,j} y i,j。注意,对于真正的阴性实例,我们不再保存它们的预测类,而是直接为它们分配一个确定的阴性类,即 y ^ i , j = 0 \widehat{y}_{i,j}=0 y i,j=0。
family集和non-family集样本
对于instance x i , j x_{i,j} xi,j和它的embedding q i , j q_{i,j} qi,j,我们使用instance分类器的预测输出 y ^ i , j \widehat{y}_{i,j} y i,j和embedding队列构建family set F ( q i , j ) F(q_{i,j}) F(qi,j)和non-family set F ′ ( q i , j ) F'(q_{i,j}) F′(qi,j),然后执行对比学习。具体来说, F ( q i , j ) F(q_{i,j}) F(qi,j)来自两个部分,第一部分由 q i , j q_{i,j} qi,j和 k i , j k_{i,j} ki,j组成,第二部分由embedding队列中标签为 y ^ i , j \widehat{y}_{i,j} y i,j的所有embeddings组成。embedding队列中的其他类标签的embedding组成non-family set F ′ ( q i , j ) F'(q_{i,j}) F′(qi,j)。
数学上,对于mini-batch,所有query和key embedding被记为
B
q
B_{q}
Bq和
B
k
B_{k}
Bk,embedding队列为
Q
Q
Q,对于一个instance (
x
i
,
j
,
q
i
,
j
,
y
^
i
,
j
x_{i,j},q_{i,j},\widehat{y}_{i,j}
xi,j,qi,j,y
i,j),对比embedding pool定义为:
P
(
q
i
,
j
)
=
(
B
q
∪
B
k
∪
Q
)
n
o
{
q
i
,
j
}
P(q_{i,j})=(B_{q}\cup B_{k}\cup Q) no \left\{q_{i,j}\right\}
P(qi,j)=(Bq∪Bk∪Q)no{qi,j}在
P
(
q
i
,
j
)
P(q_{i,j})
P(qi,j)中,family set
F
(
q
i
,
j
)
F(q_{i,j})
F(qi,j)和non-family set
F
′
(
q
i
,
j
)
F'(q_{i,j})
F′(qi,j)为:

对比损失
构建对比损失为:

其中,
k
+
k_{+}
k+为
q
i
,
j
q_{i,j}
qi,j的family样本,
k
−
k_{-}
k−为
q
i
,
j
q_{i,j}
qi,j的non-family样本,
τ
\tau
τ为温度系数。
embedding队列更新
在每次迭代结束时,将当前实例的动量嵌入 k i , j k_{i,j} ki,j及其预测标签 y ^ i , j \widehat{y}_{i,j} y i,j或真阴性标签添加到embedding队列中,并将最旧的嵌入及其标签出列。
基于原型生成伪标签与bag约束
在获得有意义的特征表示的基础上,通过原型学习为instance分配更准确的伪标签。为此,作者保留两个具有代表性的特征向量,一个用于阴性实例,另一个用于阳性实例,作为原型向量 μ r ∈ R d \mu_{r}\in R^{d} μr∈Rd,其中 r = 0 , 1 r=0,1 r=0,1。
准确地说,原型不是局部特征的描述,而是一个完整类的代表,可以理解为meta cells。
伪标签的生成和原型的更新过程也受到真阴性实例和实例分类器的指导。如果当前实例 x i , j x_{i,j} xi,j来自阳性bag,我们使用其嵌入 q i , j q_{i,j} qi,j和原型向量 μ r \mu_r μr来生成其伪标签 s i , j ∈ R 2 s_{i,j}∈R^2 si,j∈R2。
同时,我们使用相应类的预测标签 y ^ i , j \widehat{y}_{i,j} y i,j和嵌入 q i , j q_{i,j} qi,j来更新相应类的原型向量。如果当前实例 x i , j x_{i,j} xi,j来自阴性袋,我们直接为其分配阴性标签,并使用其嵌入 q i , j q_{i,j} qi,j更新阴性原型向量。然后,使用生成的伪标签来训练实例分类器并完成此迭代。
伪标签生成
如果当前实例
x
i
,
j
x_{i,j}
xi,j来自阳性bag,则计算
q
i
,
j
q_{i,j}
qi,j与原型向量
μ
r
\mu_{r}
μr之间的内积,并选择距离较小的原型标签作为
x
i
,
j
x_{i,j}
xi,j的伪标签更新方向
z
i
,
j
∈
R
2
z_{i,j}\in R^{2}
zi,j∈R2。然后,更新实例的伪标签如下:

其中,
α
\alpha
α是用于更新的系数,onehot是将值转换为2D one-hot向量的函数。该更新策略可以使伪标签的更新过程平滑稳定。
原型更新
如果当前instance
x
i
,
j
x_{i,j}
xi,j来自阳性bag,我们根据其预测的类别
y
^
i
,
j
\widehat{y}_{i,j}
y
i,j和嵌入
q
i
,
j
q_{i,j}
qi,j更新相应的原型向量
μ
c
\mu_c
μc:

其中,
β
\beta
β是更新系数,Norm是归一化函数。
如果当前instance
x
i
,
j
x_{i,j}
xi,j来自阴性bag,则更新
μ
0
\mu_{0}
μ0如下:

实例分类器损失
我们使用实例分类器的预测值 p i , j ∈ R 2 p_{i,j}∈R^2 pi,j∈R2和伪标签 s i , j s_{i,j} si,j之间的交叉熵损失来训练实例分类器: L c l s = C E ( p i , j , s i , j ) L_{cls}=CE(p_{i,j},s_{i,j}) Lcls=CE(pi,j,si,j)。
Bag约束
为了进一步利用bag标签,作者记录每个实例的bag索引,并应用以下bag约束损失:

其中,Mean表示Mean pooling。
总的损失为:

实验设置
数据集
CIFAR-10
为了评估INS在不同阳性比率下的性能并将其与比较方法进行比较,作者使用10类自然图像数据集CIFAR-10构建了一个具有不同阳性比率的模拟数据集,称为CIFAR-MIL。
CIFAR-10数据集由60000张32×32像素的彩色图像组成,分为10类(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车),每类包含6000张图像。在这些图像中,50000张用于训练,10000张用于测试。为了模拟WSI,作者将CIFAR-10数据集的每个类别的一组随机图像组合起来构建WSI。具体而言,作者将CIFAR-10数据集每个类别的每个图像作为一个instance进行处理,只有“卡车”类别的所有实例被标记为阳性,而其他实例则被标记为阴性(在这里,卡车类别只是随机选择的结果)。然后,从所有实例中随机选择了 a a a个阳性实例和 100 − a 100-a 100−a个阴性实例(不重复)组成阳性bag,阳性比率为 a / 100 a/100 a/100。同样的,随机选择了一个由100个阴性实例组成的阴性bag(不重复)。重复这个过程,直到CIFAR-10数据集中的所有阳性或阴性实例都用完为止。通过调整 a a a的值,作者构建了CIFAR-MIL数据集的5个子集,阳性率分别为5%、10%、20%、50%和70%。
Camelyon16
Camelyon16数据集是一个公开可用的组织病理学图像数据集,用于检测乳腺癌症淋巴结转移。含有转移灶的WSI标记为阳性,而没有转移灶的则标记为阴性。除了指示WSI是阳性还是阴性的WSI级别标签外,数据集还提供了转移区域的像素级别标签。为了满足弱监督场景,实验仅使用WSI级别标签进行训练,并使用癌症区域的像素级别标签评估每个算法的实例分类性能。
在训练之前,作者将每个WSI划分为10倍放大的不重叠的512×512图像patch。熵小于5的patch被移除作为背景,如果patch包含25%或更多的癌症区域,则贴片被标记为阳性,否则,其被标记为阴性。共获得186604个实例用于训练和测试,其中243张WSI用于训练,111张用于测试。
TCGA lung cancer
TCGA Lung cancer数据集包括从癌症基因组图谱(TCGA)数据门户获得的1054个WSI,该数据门户由两种癌症亚型组成,即肺腺癌(Lung Adenocarcinoma)和肺鳞状细胞癌( Lung Squamous Cell Carcinoma)。目标是准确诊断这两种亚型,肺腺癌的WSI标记为阴性,肺鳞状细胞癌的WSI标记为阳性。此数据集仅提供WSI级别的标签,patch级别的标签不可用。该数据集包含约520万个20倍放大的patch,平均每张WSI约有5000个patch。这些WSI被随机划分为840张训练WSIs和210张测试WSIs(丢弃了4张低质量损坏的WSIs)。
Cervical Cancer
宫颈癌数据集是一个临床病理数据集,包括不同患者的374个H&E染色的宫颈癌症原发性病变WSI。作者在5倍放大下进行了所有实验,并将每个WSI划分为大小为224×224的非重叠patch,以形成一个bag。从原始WSI中丢弃熵值小于5的背景patch。
为了预测原发性肿瘤的淋巴结转移,作者将发生盆腔淋巴结转移的患者的相应WSI标记为阳性(209例),未发生盆腔淋巴转移的患者标记为阴性(165例)。将WSI随机分为一个训练集(300例)和一个测试集(74例)。
对于患者生存预后的预测,根据详细的随访记录对所有患者进行分组,使用中位数作为截止值,其中三年内未发生癌症相关死亡的患者被标记为阴性(预后良好),而发生癌症相关死亡的患者则被标记为阳性(预后不良)。然后,根据标签将WSI随机分为训练集(294例)和测试集(80例)。
为了预测免疫组织化学标记物KI-67,根据详细的KI-67免疫组织化学报告,使用中位数作为截止值,对所有患者进行分组,其中低于75的KI-67s水平标记为阴性,高于75的标记为阳性。然后,根据标签将WSI随机分为训练集(294例)和测试集(80例)。
评价指标和对比方法
对于实例和袋分类,作者使用曲线下面积(AUC,Area Under Curve)和Accuracy作为评估指标。bag分类性能在所有数据集上进行评估,但实例级分类性能仅在CIFAR-MIL数据集和Cameyon 16数据集上评估,因为只有这两个数据集具有实例标签。将INS与11个方法进行了比较,包括三种基于实例的方法:MILRNN、Chi-MIL和DGMIL,以及八种基于袋的方法:ABMIL、Loss ABMIL、CLAM、DSMIL、TransMIL、DTFD-MIL、TPMIL和WENO。
实现细节
根据DSMIL,作者对WSI数据集进行了预处理,如patch裁剪和背景去除。对于所有数据集,编码器都是使用ResNet18实现的。实例分类器是使用MLP实现的。投影器是一个2层MLP,原型矢量为128维。SGD优化器用于优化网络参数,学习率为0.01,动量为0.9,batch大小为64。embedding队列的长度为8192。为了使训练过程顺利进行,根据经验设置了warm-up epochs。warm-up后,更新了伪标签,并给出了真正的阴性标签。每个数据集的超参数阈值各不相同,作者在验证集上使用网格搜索来确定最佳值。