Meta LLaMA 1 大模型技术解读
LLaMA 1:小模型+大数据
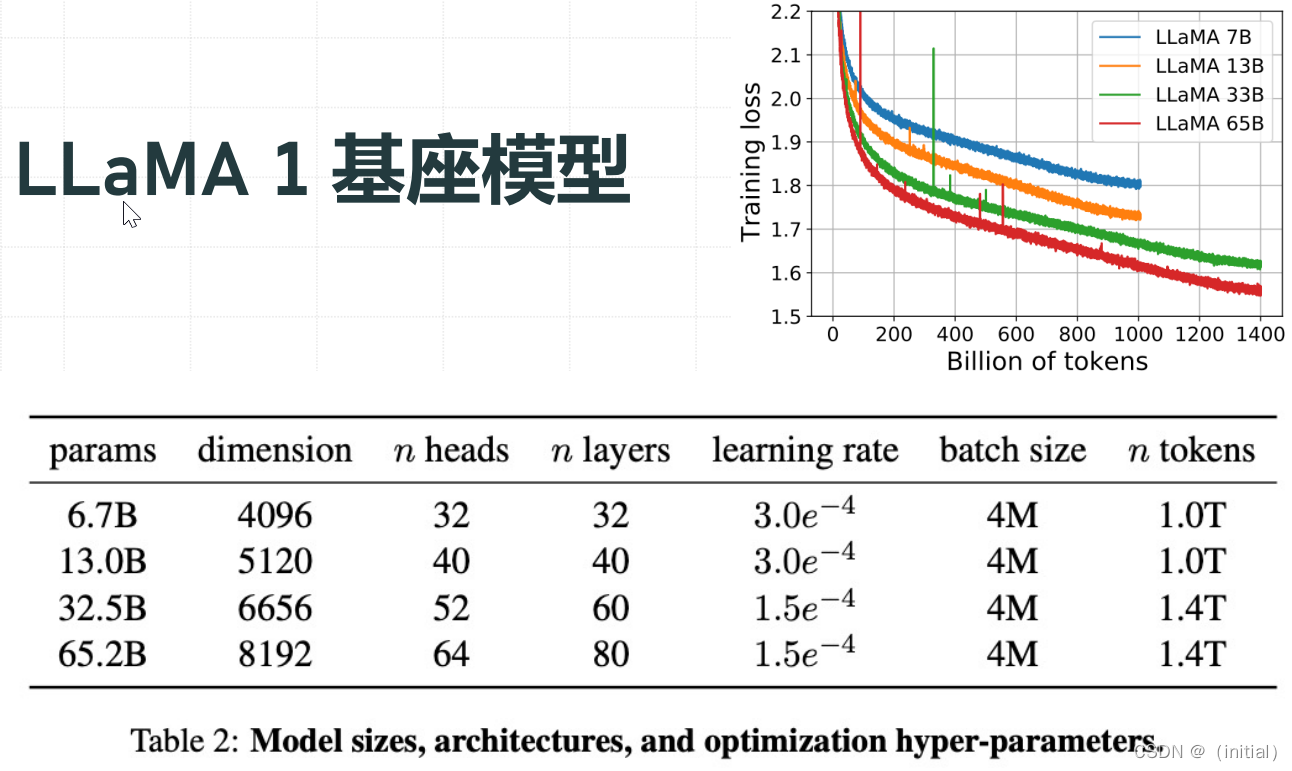
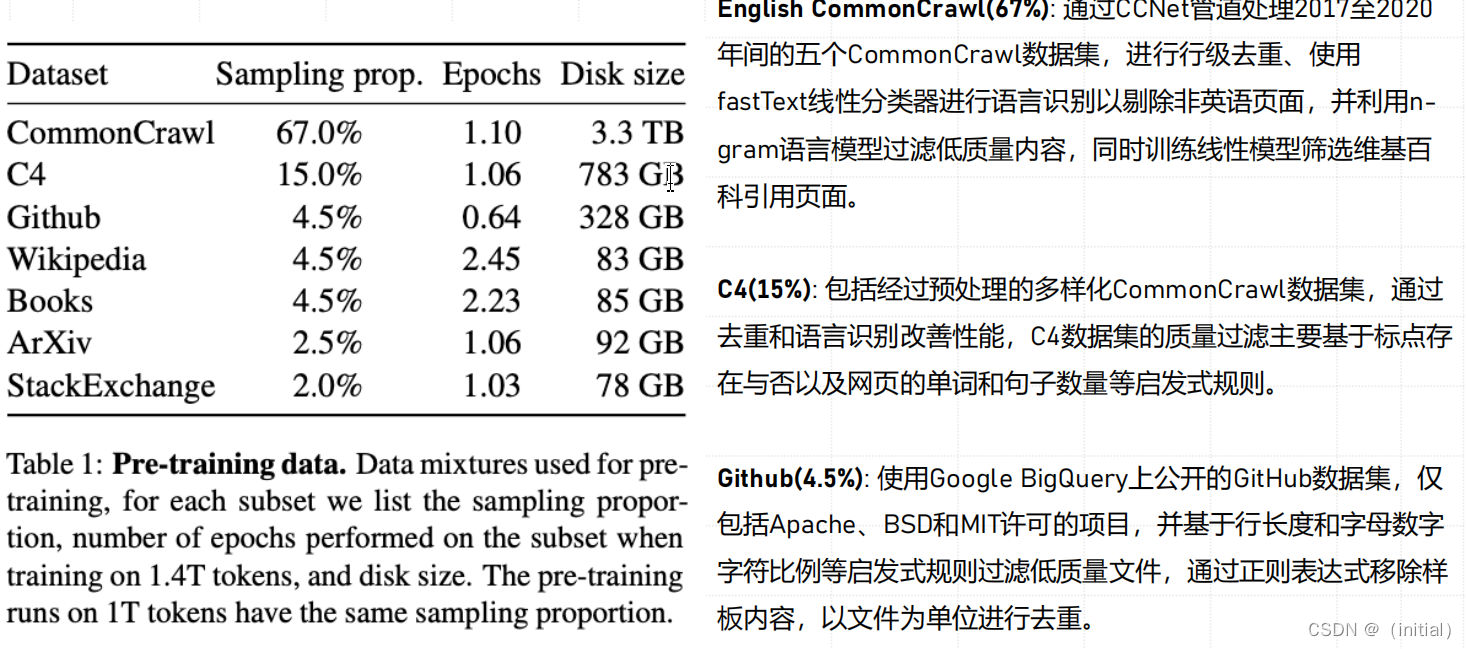
LLaMA 1 在万亿 Token 公开数据集上预训练
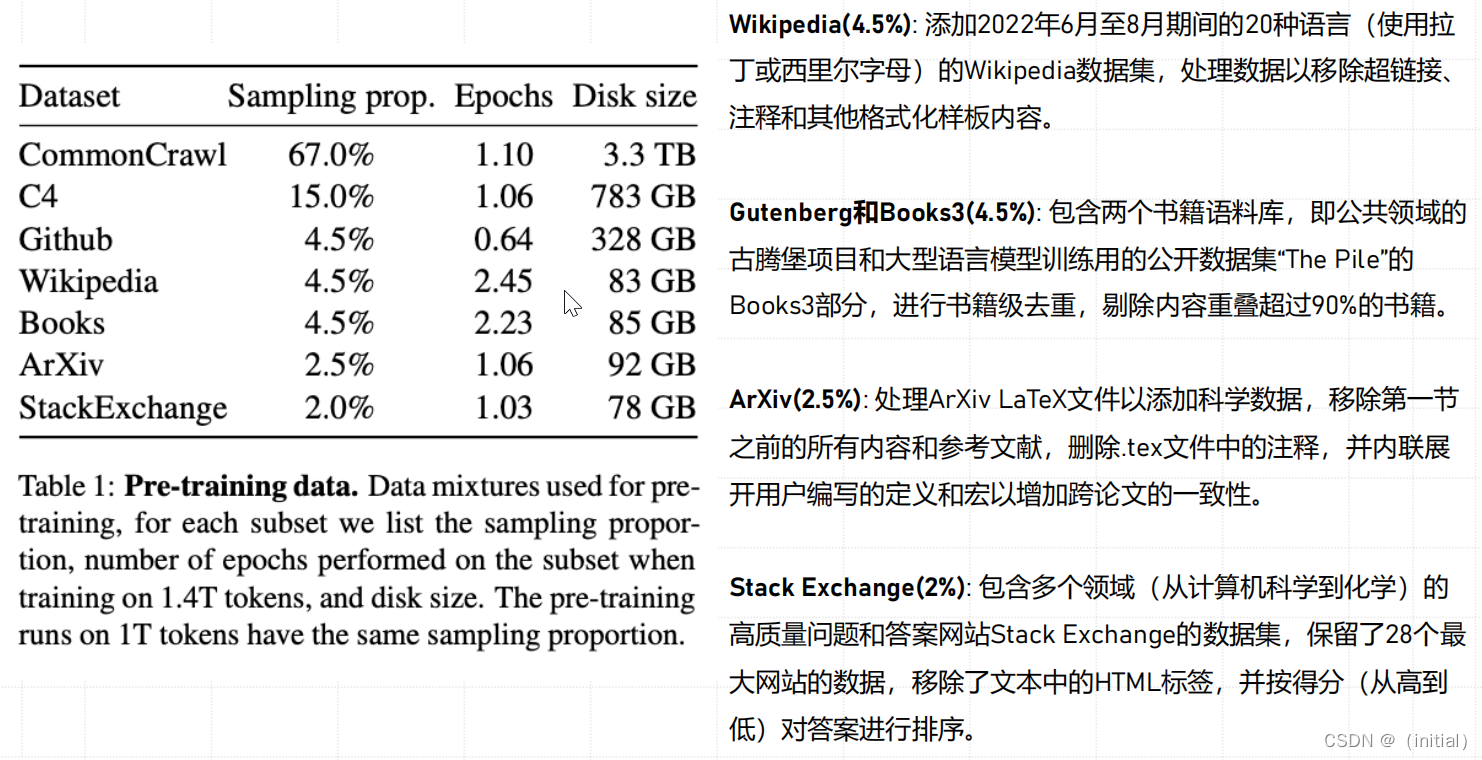
LLaMA 1 模型网络架构改进

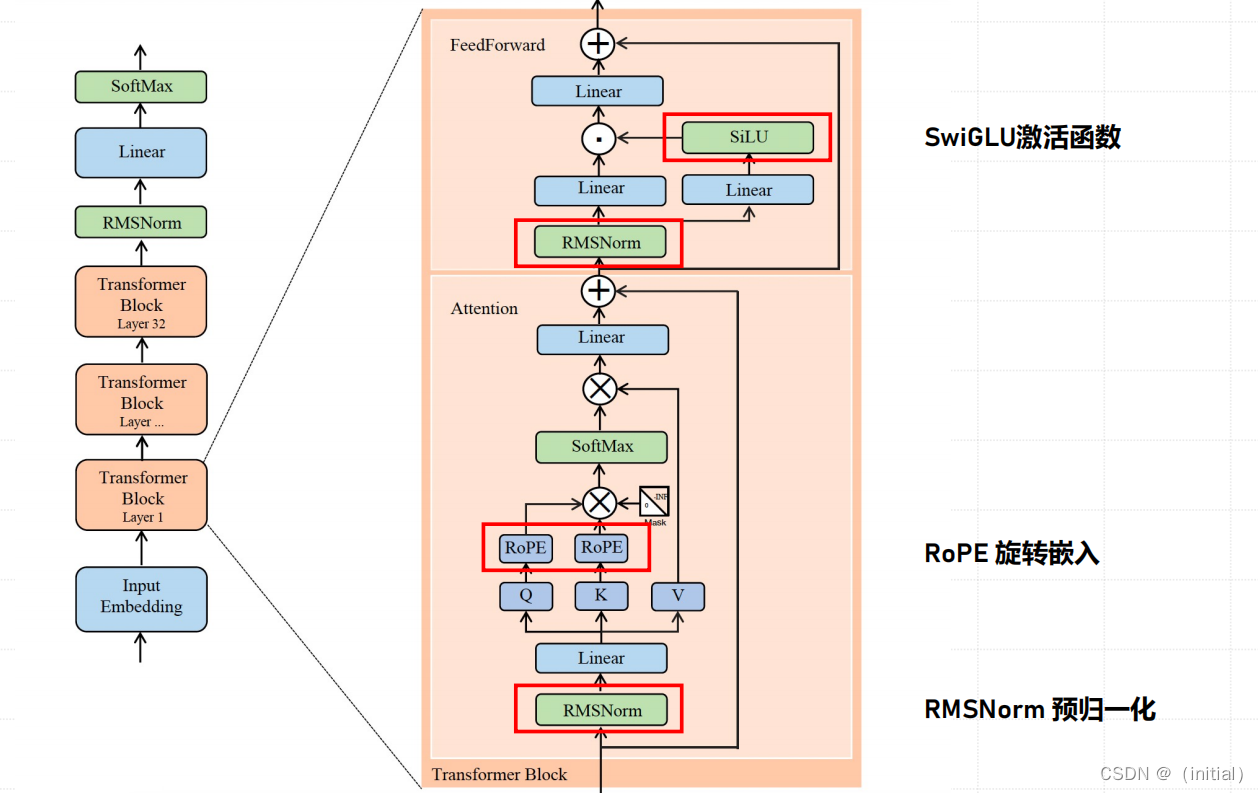
大模型网络架构差异性配置总览
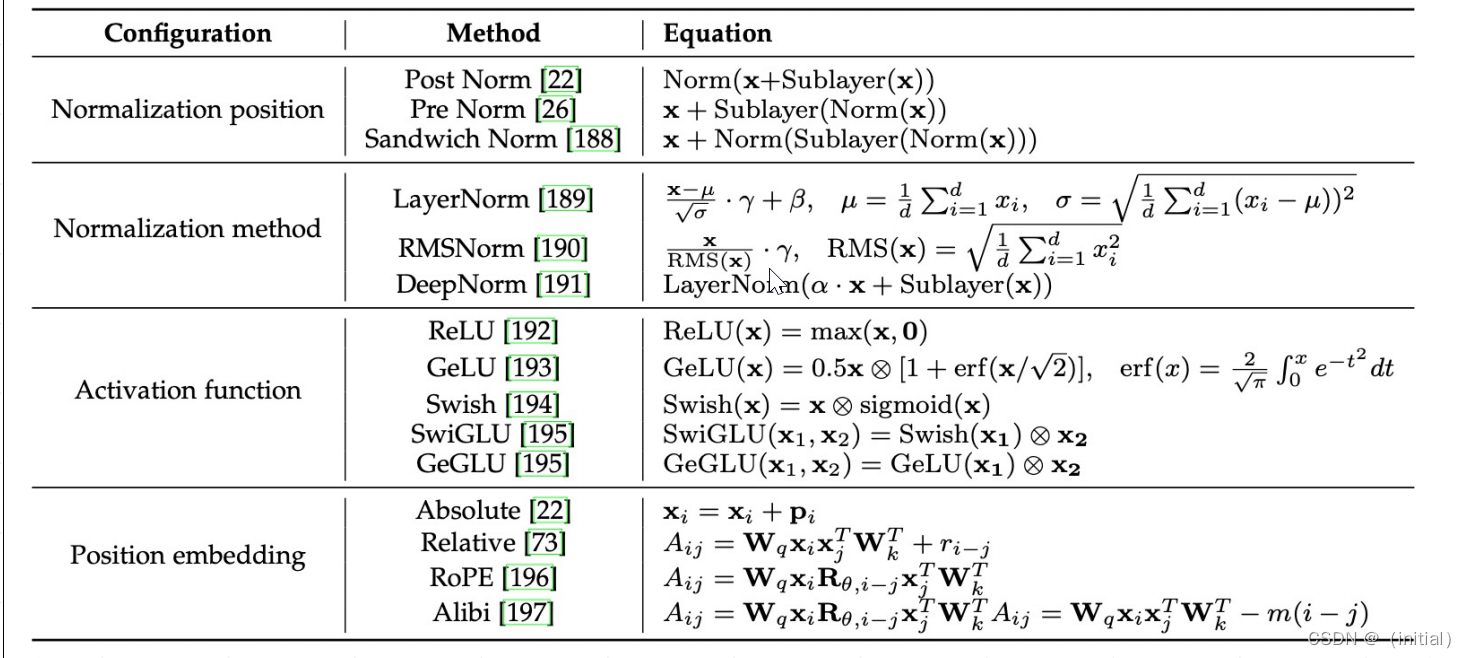
典型大模型网络架构对比
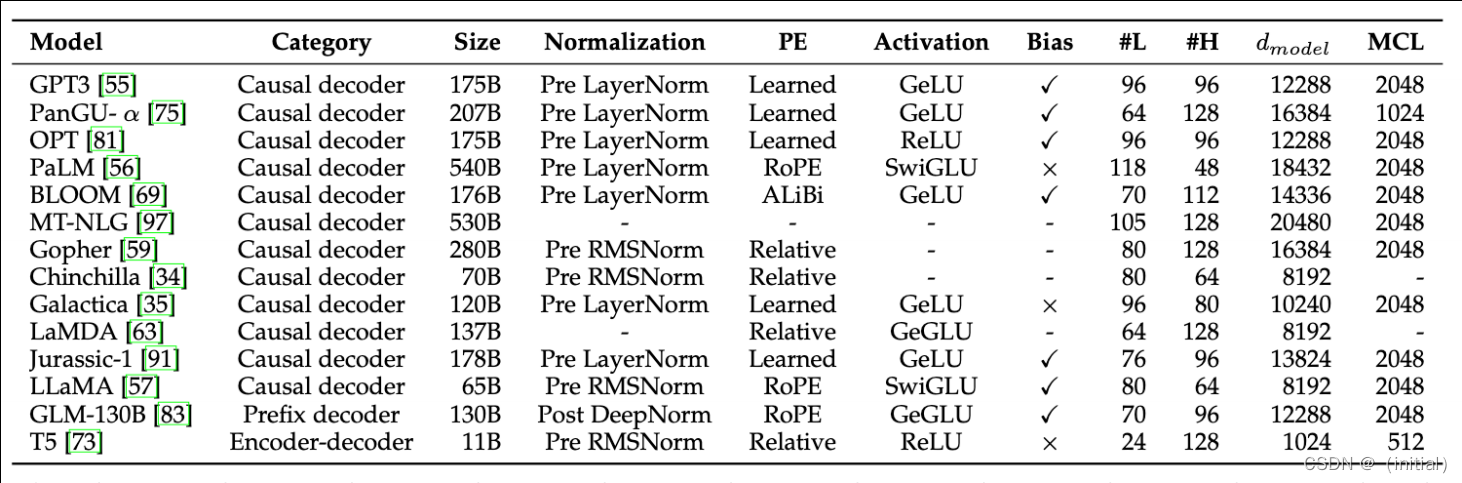
LLaMA 1 预训练超参数配置

典型大模型训练超参数对比
LLaMA 1 预训练效率提升与成本评估
为提升模型训练速度,Meta 团队基于进行了多项优化:
- • **因果多头注意力:**采用xformers库的因果多头注意力实现,减少显存使用和运行时间。不存储注意力权重,且不不计算由于语言建模任务的因果性质而被掩盖的key/query分数来实现的 。
- • 减少重复激活计算:在反向传播过程中通过检查点技术,减少了需要重新计算的激活量。具体来说,保存计算成本高的激活输出,如线性层的输出。这是通过手动实现Transformer层的反向传播函数(替代 PyTorch autograd)。
- • 模型并行和流水线并行:尽可能调度使得激活值计算和GPU间网络通信重叠,提升效率。
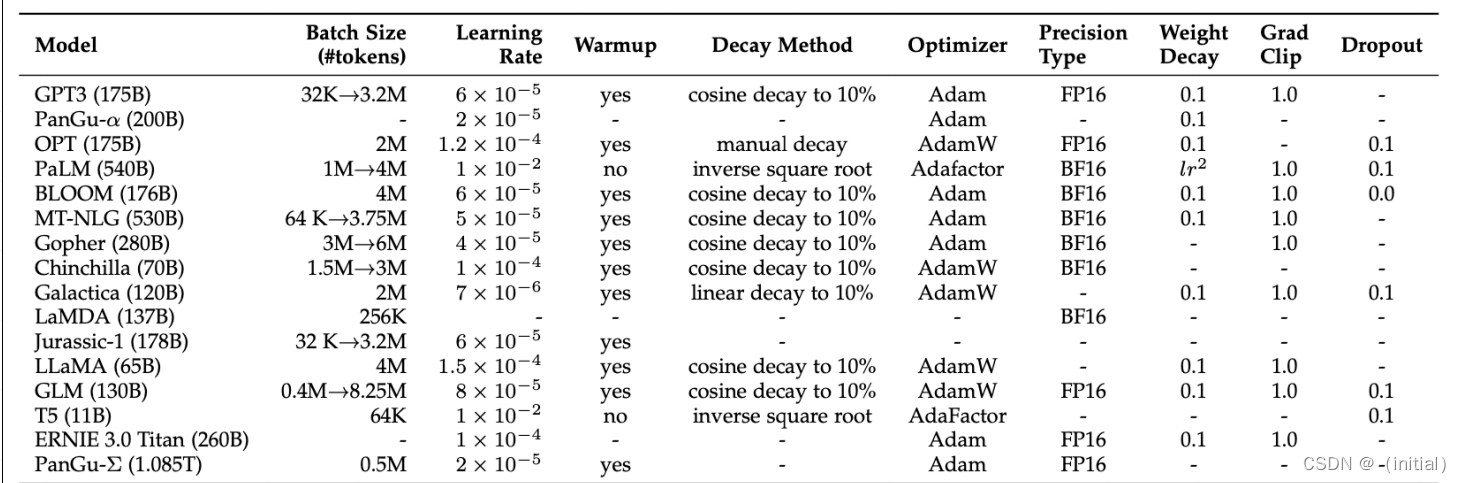
在训练 65B 模型时,Meta 代码在2048个A100 GPU(80GB)上处理速度约为380 tokens/sec/GPU 。这意味着在1.4T Tokens
数据集上训练需要约21天。与其他大模型的训练成本横向对比如下:
实验结果
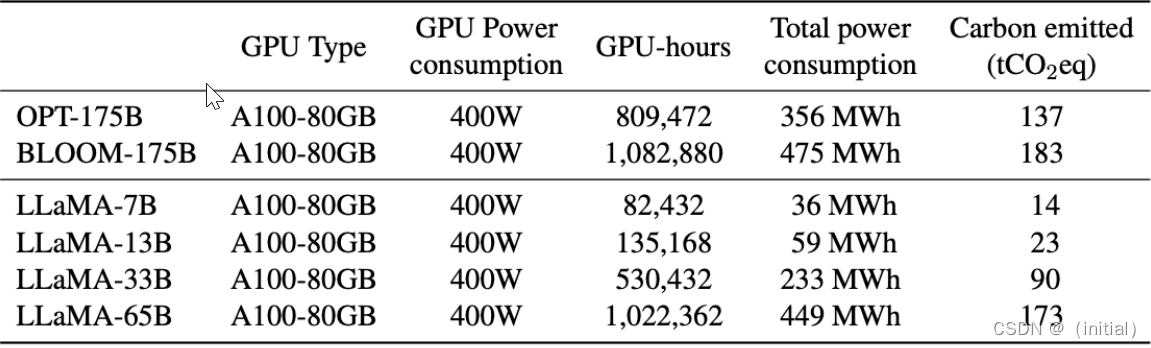
LLaMA 1****实验结果 - Zero-shot 常识推理任务
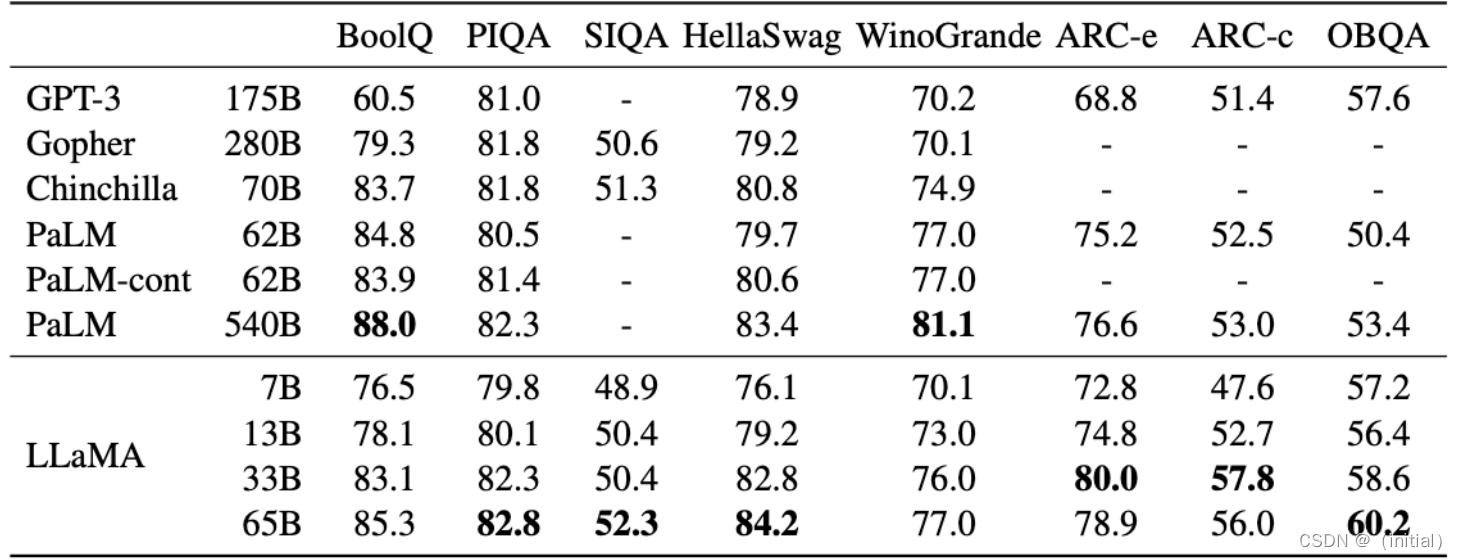
LLaMA 1****实验结果 – QA 和语义理解任务
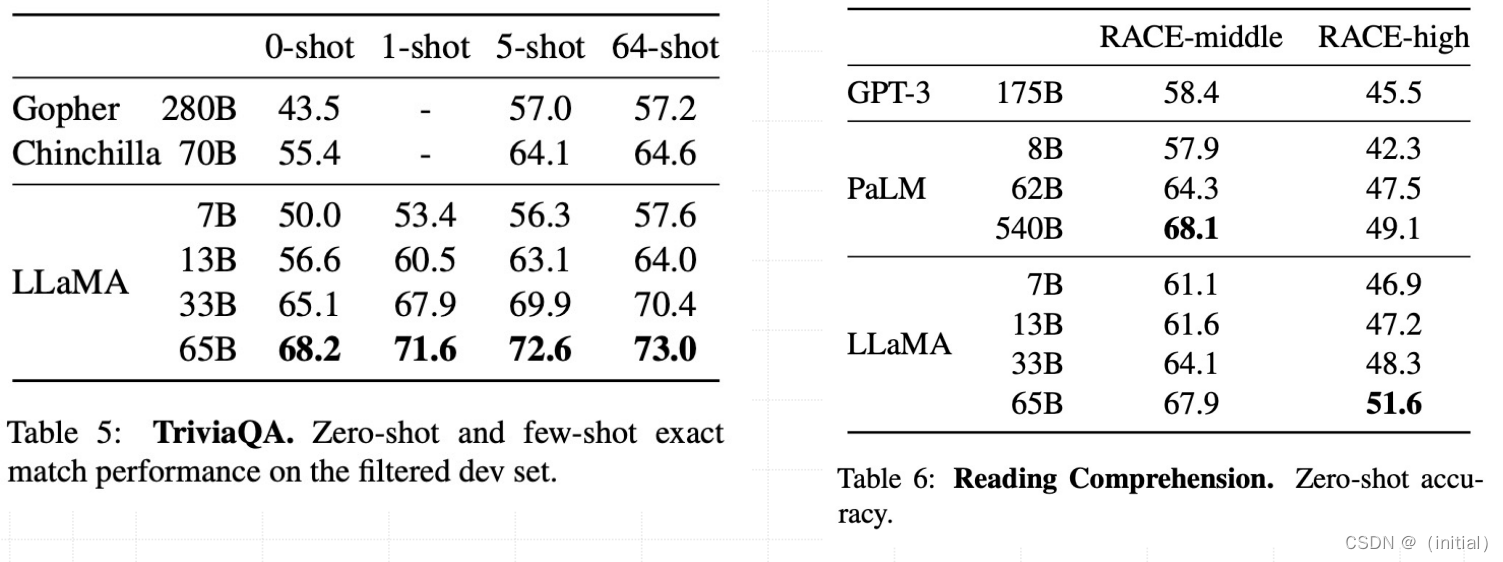
LLaMA 1****实验结果 – 数学和代码生成任务
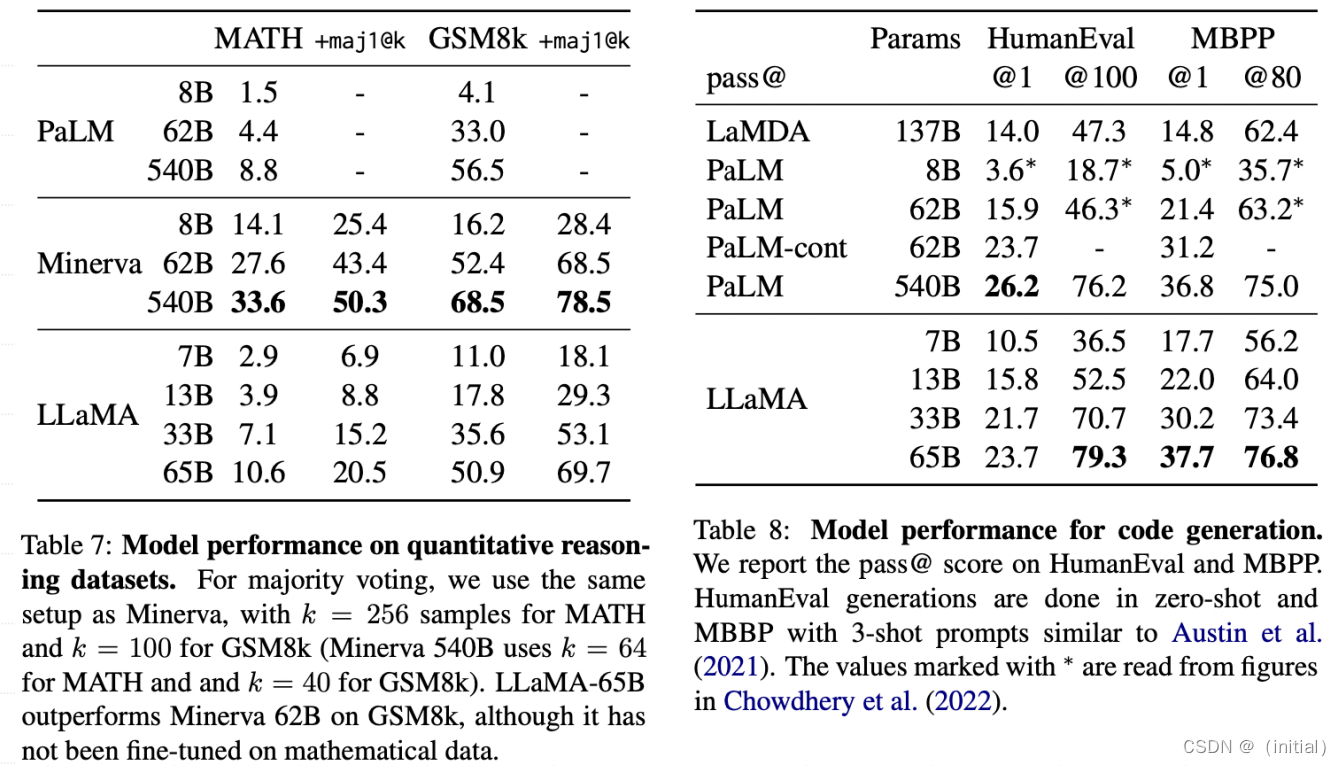
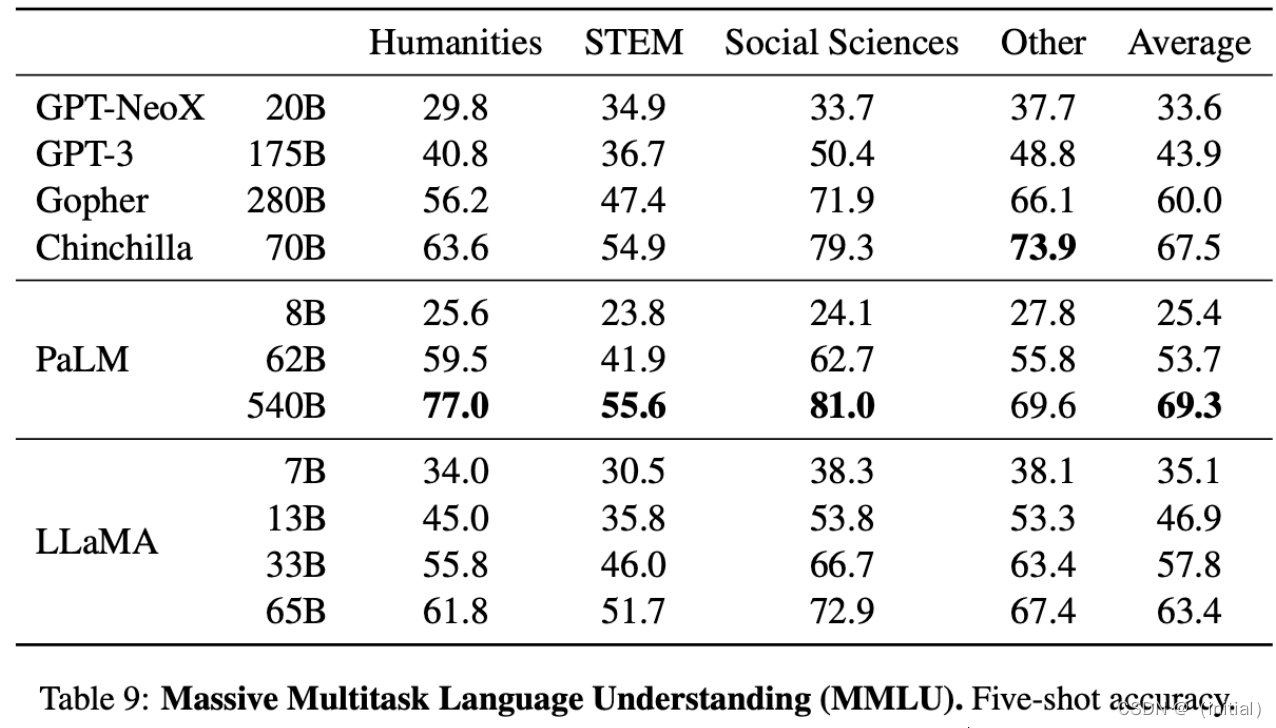
LLaMA 1****实验结果 – 多任务能力
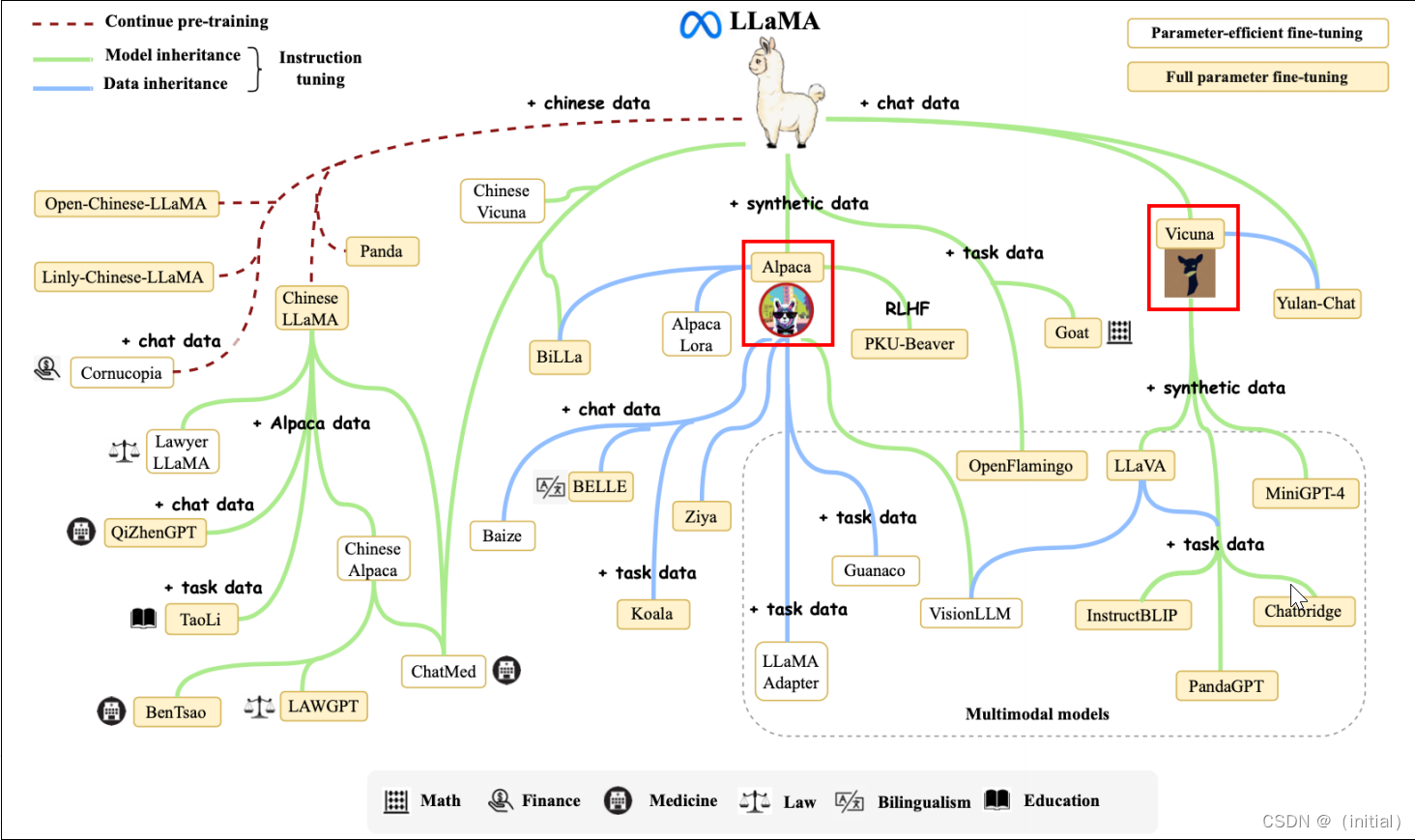
LLaMA 衍生模型家族
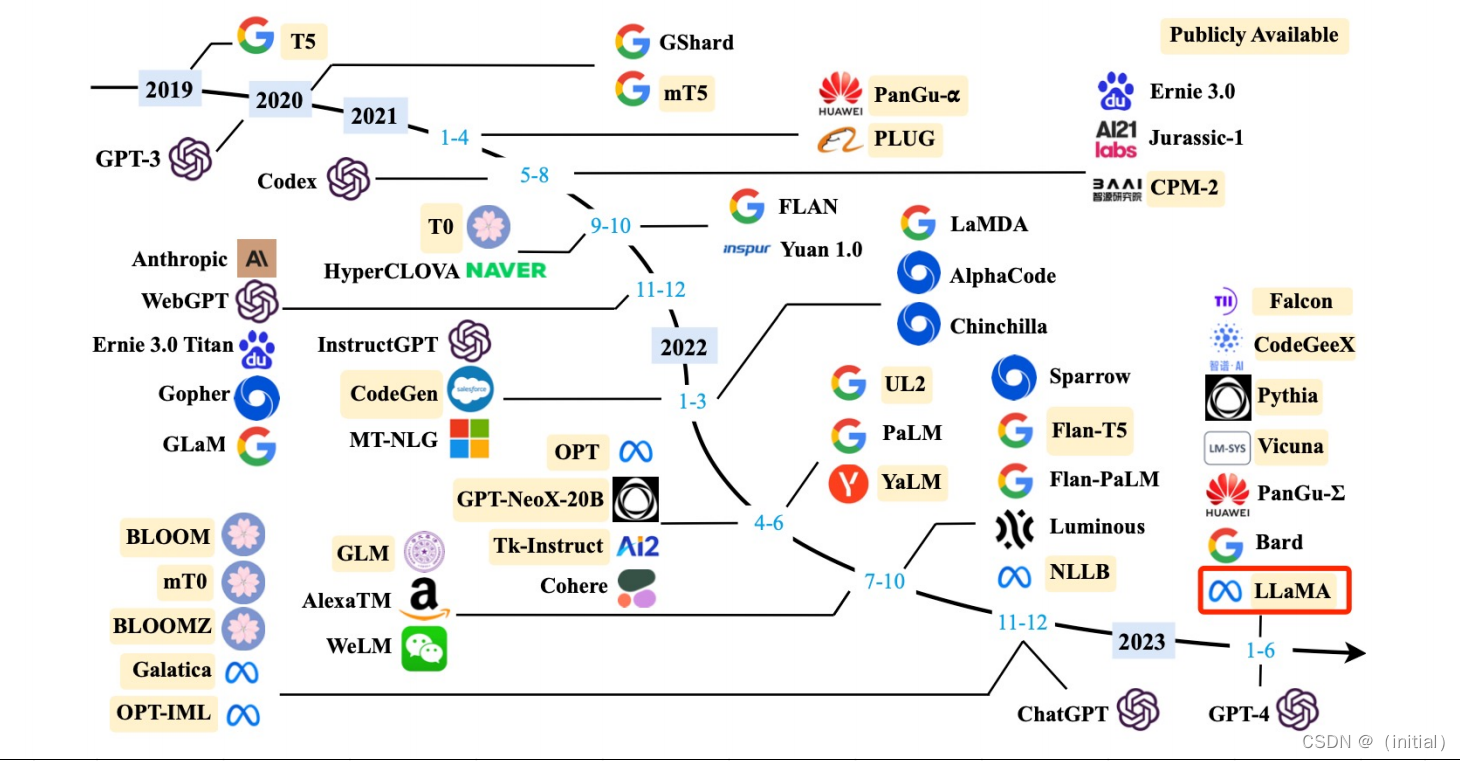
大模型 (>10B) 发布时间线
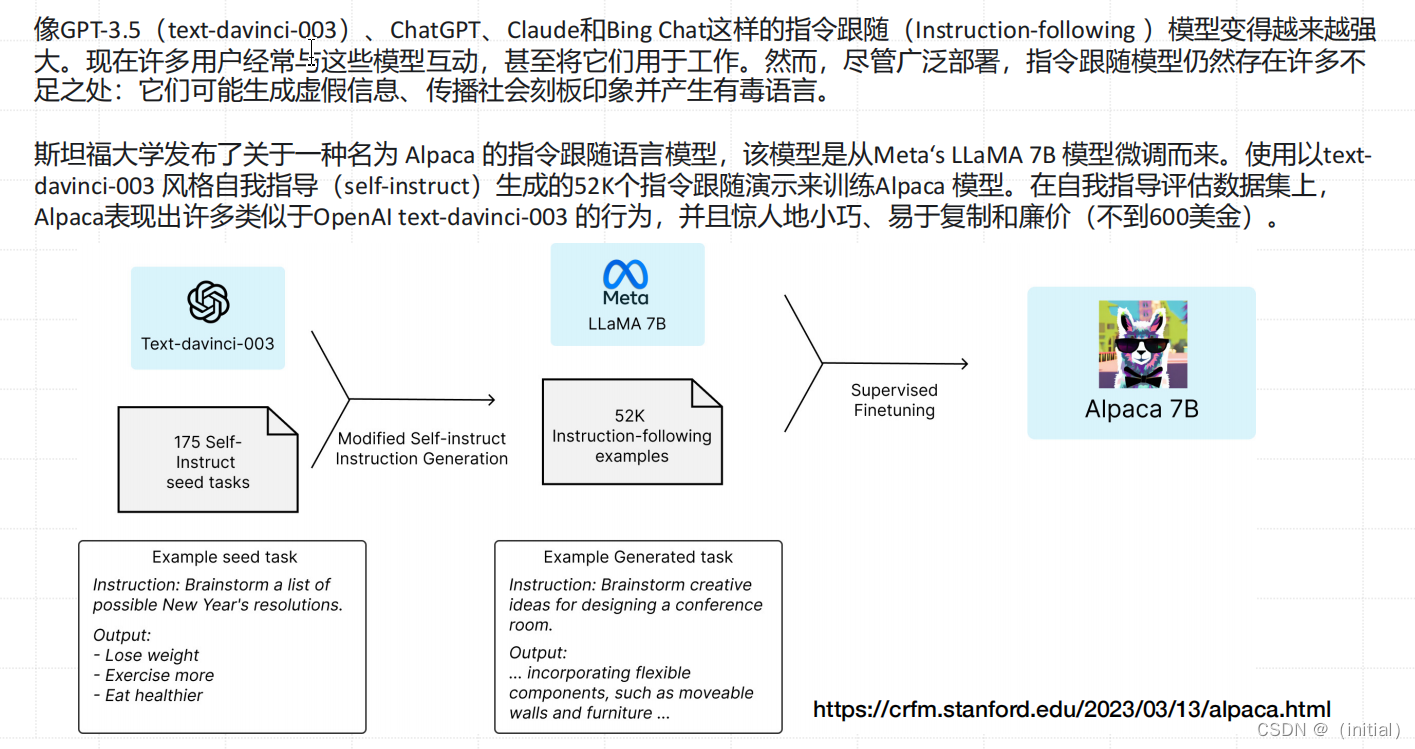
Alpaca-7B 大模型
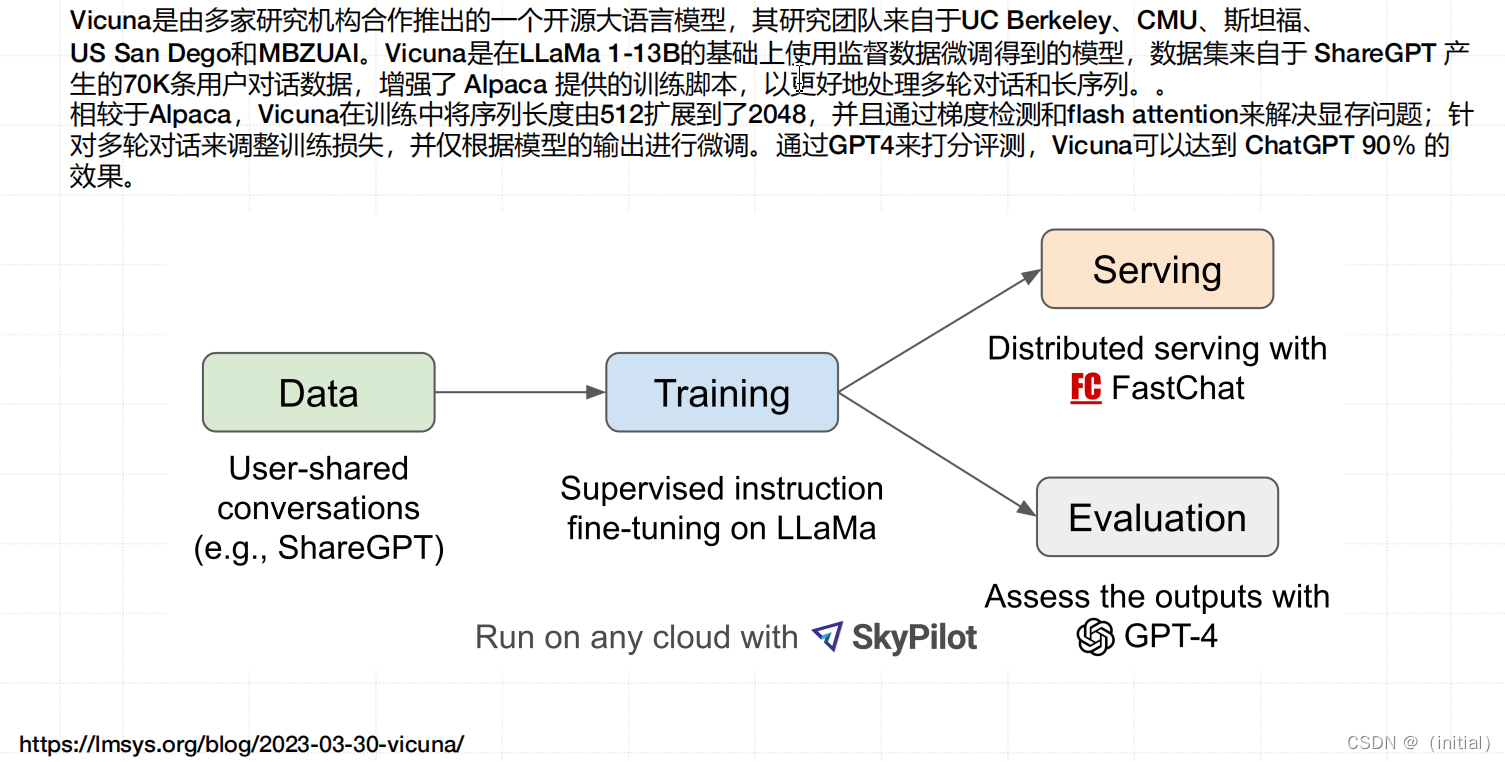
Vicuna-13B 大模型
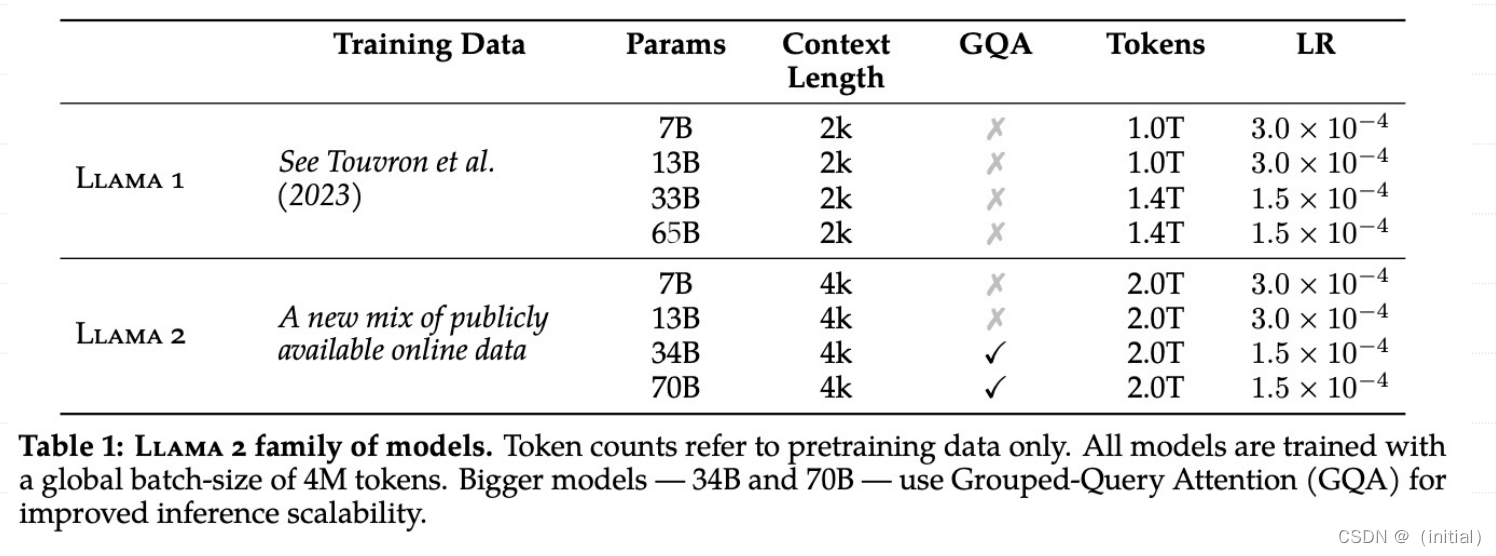
LLaMA 2
LLaMA 2 vs LLaMA 1
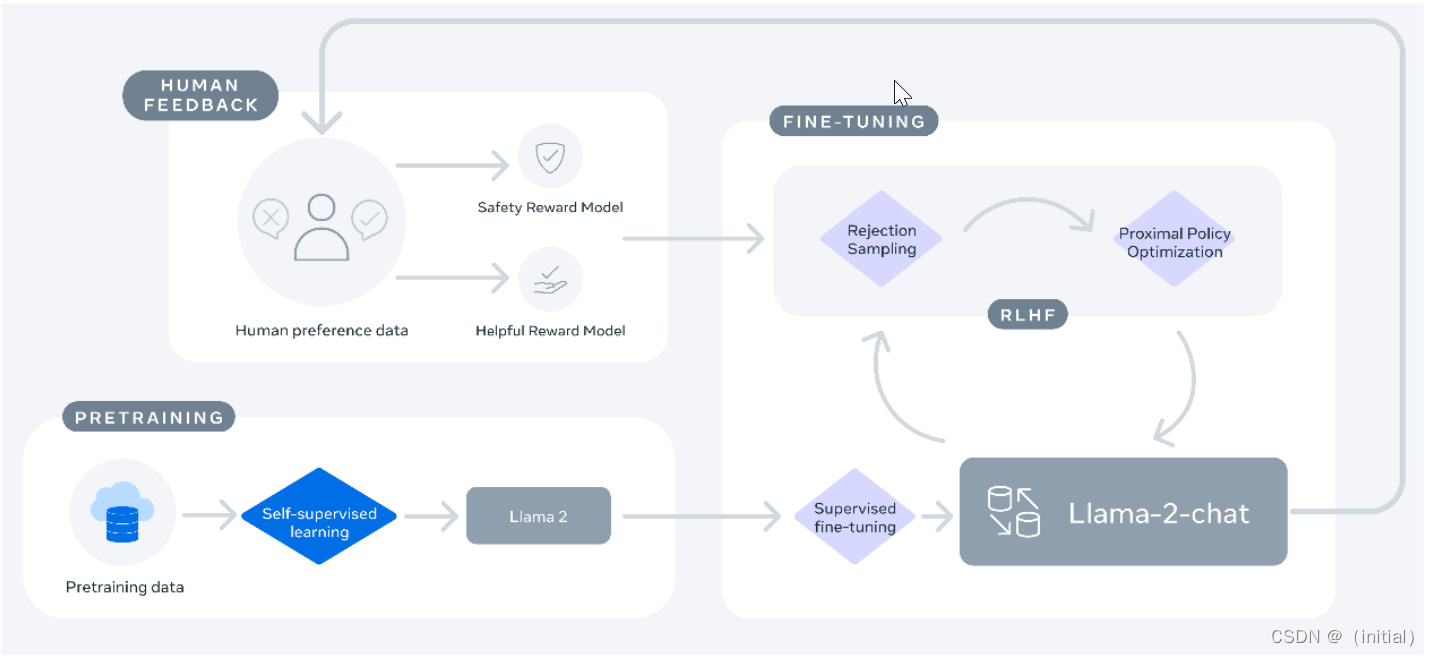
LLaMA 2-chat 模型训练方法
Llama 2 基座模型是在 2 万亿 tokens 上预训练得到的。
然后,在 100 万人类标记数据上 进行 RLHF 训练得到 LLaMA 2-Chat 模型。
型是在 2 万亿 tokens 上预训练得到的。
然后,在 100 万人类标记数据上 进行 RLHF 训练得到 LLaMA 2-Chat 模型。