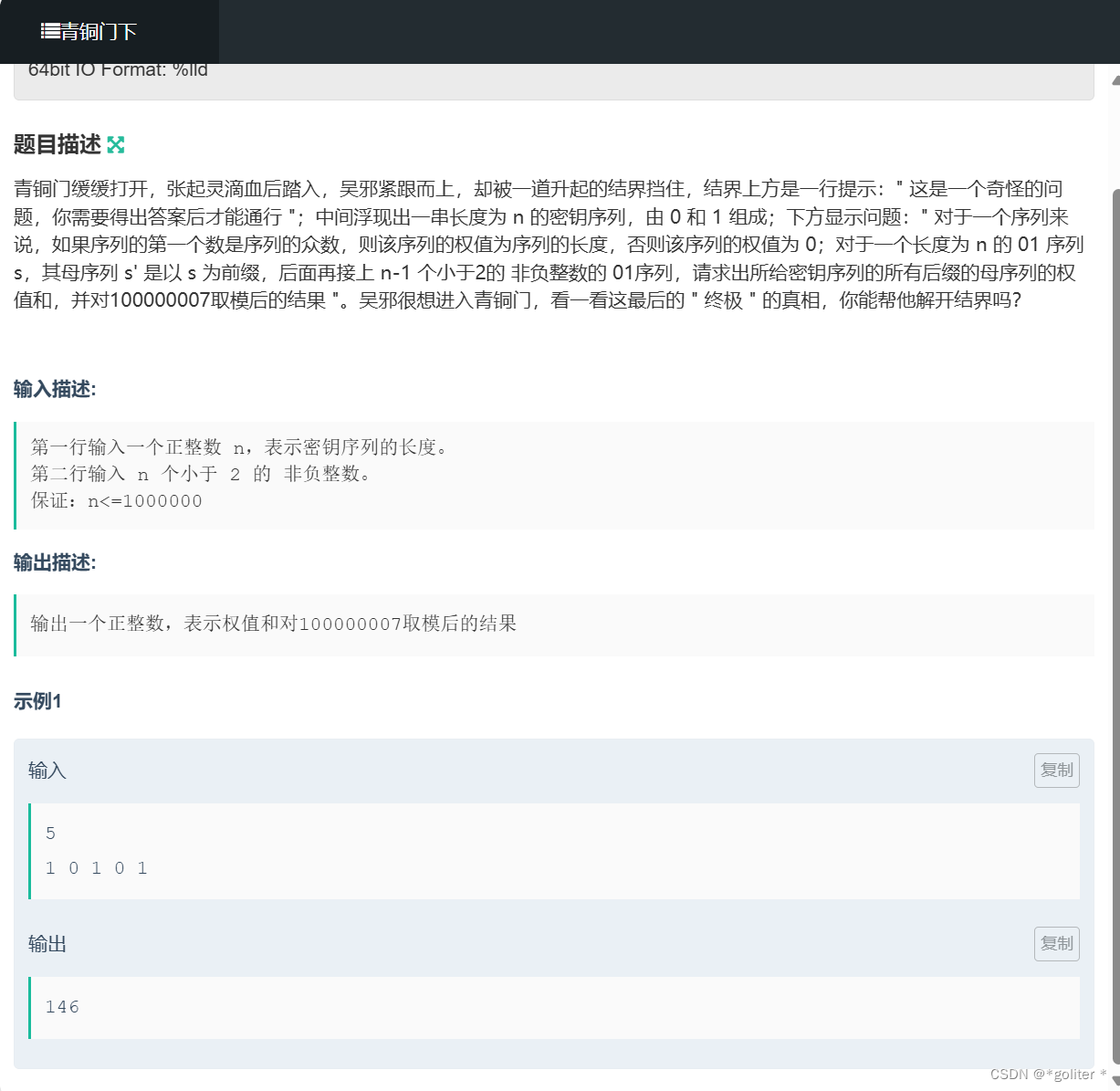
1、原理及流程
深度学习中常用的字符识别方法包括卷积神经网络(CNN)和循环神经网络(RNN)。
-
数据准备:首先需要准备包含字符的数据集,通常是手写字符、印刷字符或者印刷字体数据集。
-
数据预处理:对数据集进行预处理,包括归一化、去噪、裁剪等处理,以便更好地输入到深度学习模型中。
-
模型选择:选择合适的深度学习模型,常用的字符识别模型包括CNN和RNN。CNN主要用于图像数据的特征提取,RNN主要用于序列数据的建模。
-
模型构建:根据数据集的特点和需求构建深度学习模型,设置合适的层数、节点数和激活函数等参数。
-
模型训练:使用已标记好的数据集对模型进行训练,通过反向传播算法不断调整模型参数,使其能够更好地拟合数据集。
-
模型评估:使用未标记的数据集对训练好的模型进行评估,评估模型的准确率、召回率、F1值等指标。
-
模型优化:根据评估结果对模型进行调优,可以对模型结构、参数、数据集等方面进行优化。
-
预测与应用:使用训练好的模型对新数据进行字符识别预测,应用到实际场景中,如车牌识别、验证码识别等领域。
2、准备工作
1)无噪声拼音字符的生成
代码
function [alphabet,targets] = prprob()
letterA = [0 0 1 0 0 ...
0 1 0 1 0 ...
0 1 0 1 0 ...
1 0 0 0 1 ...
1 1 1 1 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ]';
letterB = [1 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 1 1 1 0 ]';
letterC = [0 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 1 ...
0 1 1 1 0 ]';
letterD = [1 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 1 1 1 0 ]';
letterE = [1 1 1 1 1 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 1 1 1 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 1 1 1 1 ]';
letterF = [1 1 1 1 1 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 1 1 1 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ]';
letterG = [0 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 1 1 ...
1 0 0 0 1 ...
0 1 1 1 0 ]';
letterH = [1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 1 1 1 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ]';
letterI = [0 1 1 1 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 1 1 1 0 ]';
letterJ = [1 1 1 1 1 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
1 0 1 0 0 ...
0 1 0 0 0 ]';
letterK = [1 0 0 0 1 ...
1 0 0 1 0 ...
1 0 1 0 0 ...
1 1 0 0 0 ...
1 0 1 0 0 ...
1 0 0 1 0 ...
1 0 0 0 1 ]';
letterL = [1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 1 1 1 1 ]';
letterM = [1 0 0 0 1 ...
1 1 0 1 1 ...
1 0 1 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ]';
letterN = [1 0 0 0 1 ...
1 1 0 0 1 ...
1 1 0 0 1 ...
1 0 1 0 1 ...
1 0 0 1 1 ...
1 0 0 1 1 ...
1 0 0 0 1 ]';
letterO = [0 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
0 1 1 1 0 ]';
letterP = [1 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 1 1 1 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ...
1 0 0 0 0 ]';
letterQ = [0 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 1 0 1 ...
1 0 0 1 0 ...
0 1 1 0 1 ]';
letterR = [1 1 1 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 1 1 1 0 ...
1 0 1 0 0 ...
1 0 0 1 0 ...
1 0 0 0 1 ]';
letterS = [0 1 1 1 0 ...
1 0 0 0 1 ...
0 1 0 0 0 ...
0 0 1 0 0 ...
0 0 0 1 0 ...
1 0 0 0 1 ...
0 1 1 1 0 ]';
letterT = [1 1 1 1 1 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ]';
letterU = [1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
0 1 1 1 0 ]';
letterV = [1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
0 1 0 1 0 ...
0 0 1 0 0 ]';
letterW = [1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 0 0 1 ...
1 0 1 0 1 ...
1 1 0 1 1 ...
1 0 0 0 1 ]';
letterX = [1 0 0 0 1 ...
1 0 0 0 1 ...
0 1 0 1 0 ...
0 0 1 0 0 ...
0 1 0 1 0 ...
1 0 0 0 1 ...
1 0 0 0 1 ]';
letterY = [1 0 0 0 1 ...
1 0 0 0 1 ...
0 1 0 1 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ...
0 0 1 0 0 ]';
letterZ = [1 1 1 1 1 ...
0 0 0 0 1 ...
0 0 0 1 0 ...
0 0 1 0 0 ...
0 1 0 0 0 ...
1 0 0 0 0 ...
1 1 1 1 1 ]';
alphabet = [letterA,letterB,letterC,letterD,letterE,letterF,letterG,letterH,...
letterI,letterJ,letterK,letterL,letterM,letterN,letterO,letterP,...
letterQ,letterR,letterS,letterT,letterU,letterV,letterW,letterX,...
letterY,letterZ];
targets = eye(26);试图效果
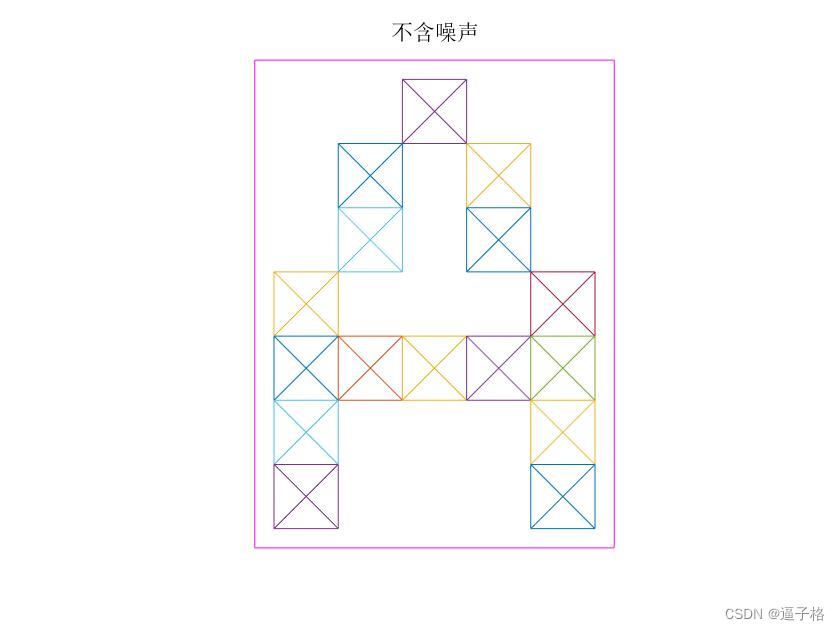
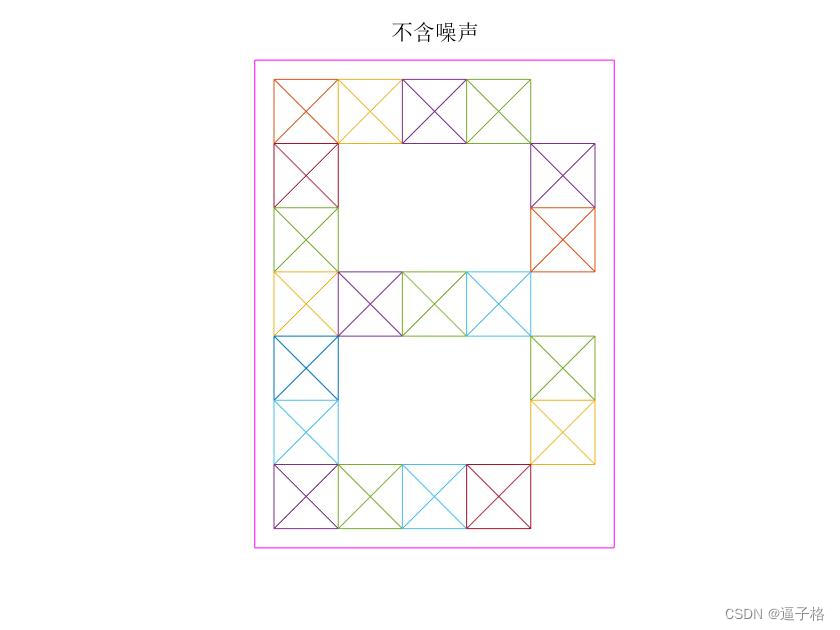
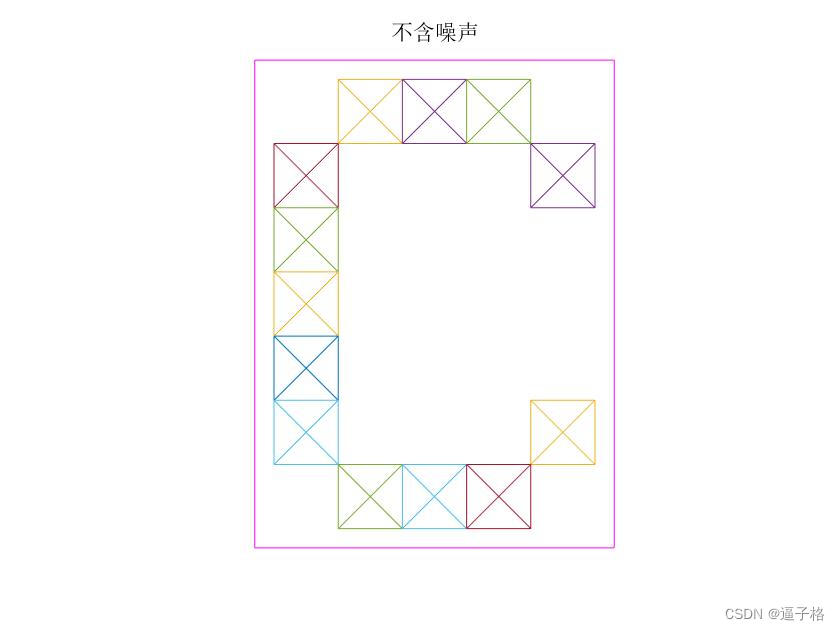
无噪声A B C X Y Z视图

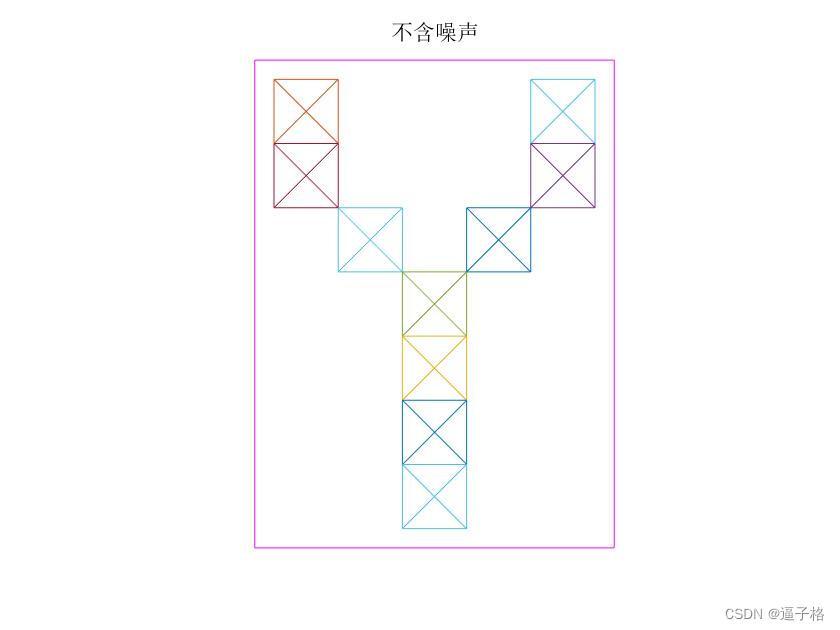
2)有噪声拼音字符的生成
代码
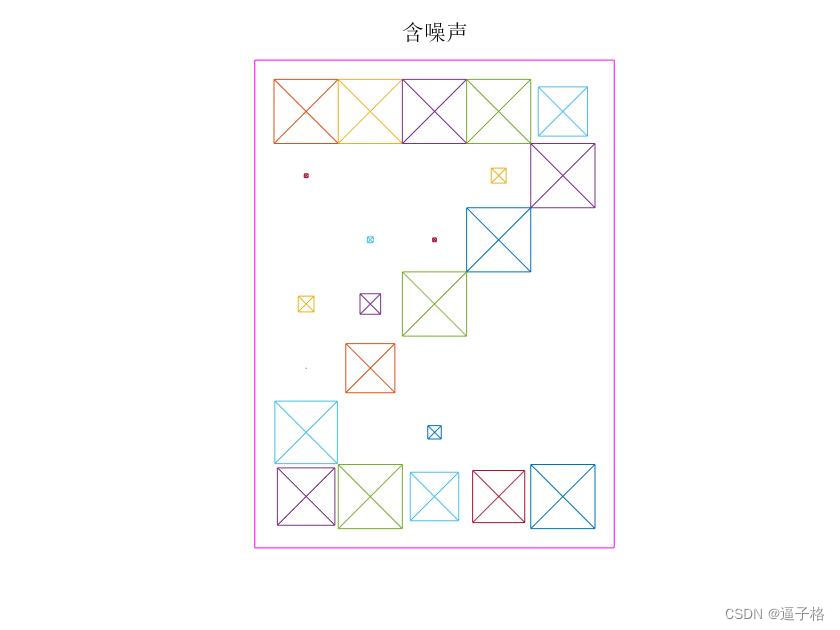
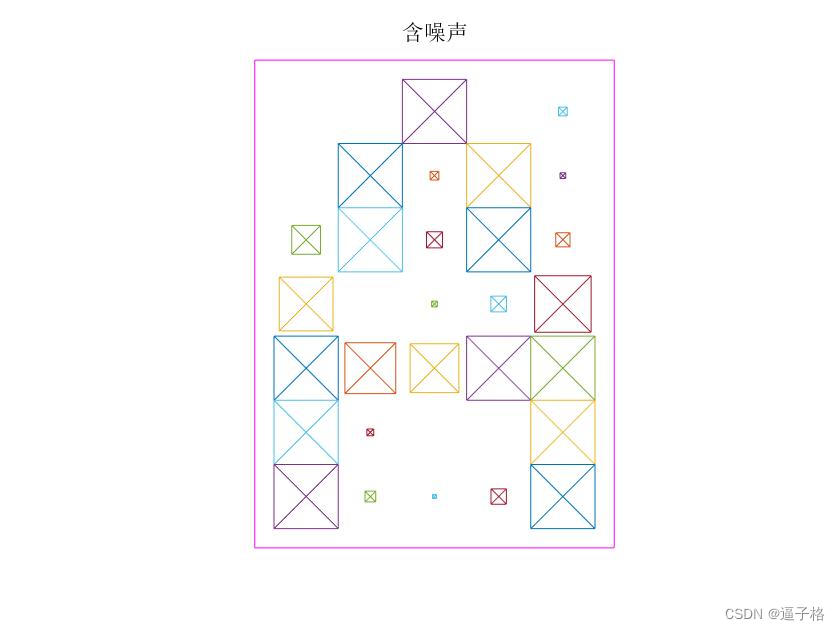
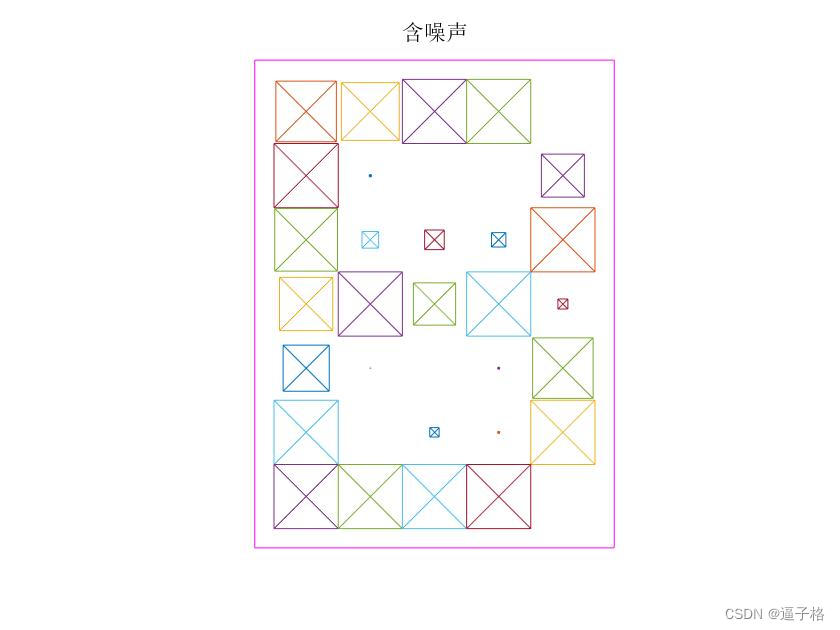
有噪声A B C X Y Z视图
numNoise = 30;
Xn = min(max(repmat(X,1,numNoise)+randn(35,26*numNoise)*0.2,0),1);
Tn = repmat(T,1,numNoise);视图效果
3、 创建第一个神经网络
说明
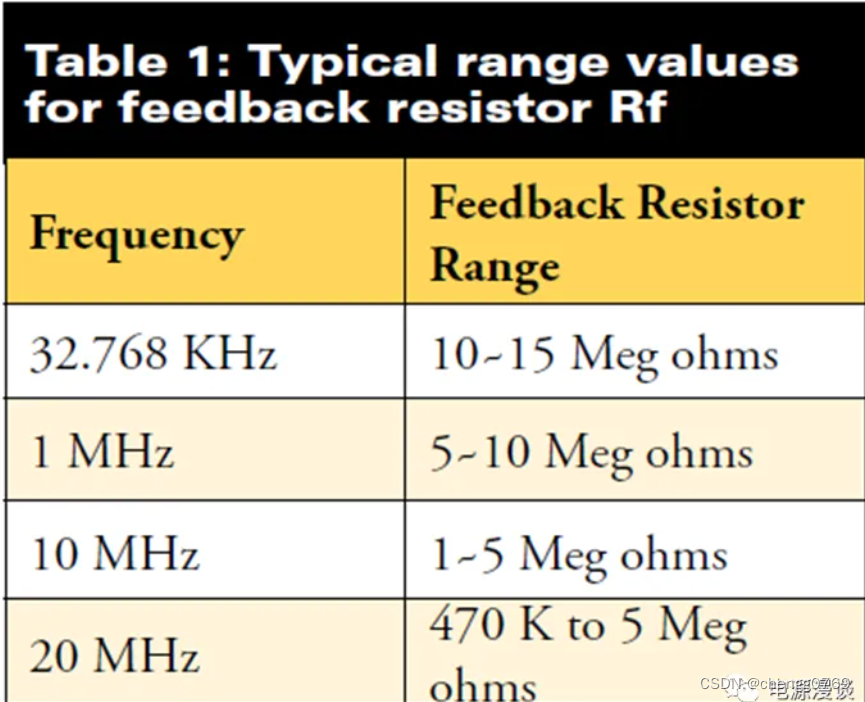
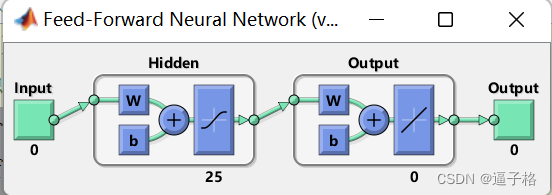
针对模式识别建立的具有 25 个隐藏神经元的前馈神经网络。
由于神经网络以随机初始权重进行初始化,因此每次运行该示例进行训练后的结果都略有不同。
代码
%25 个隐藏神经元的前馈神经网络。
setdemorandstream(pi);
net1 = feedforwardnet(25);
%显示网络
view(net1);视图效果
4、 训练第一个神经网络
说明
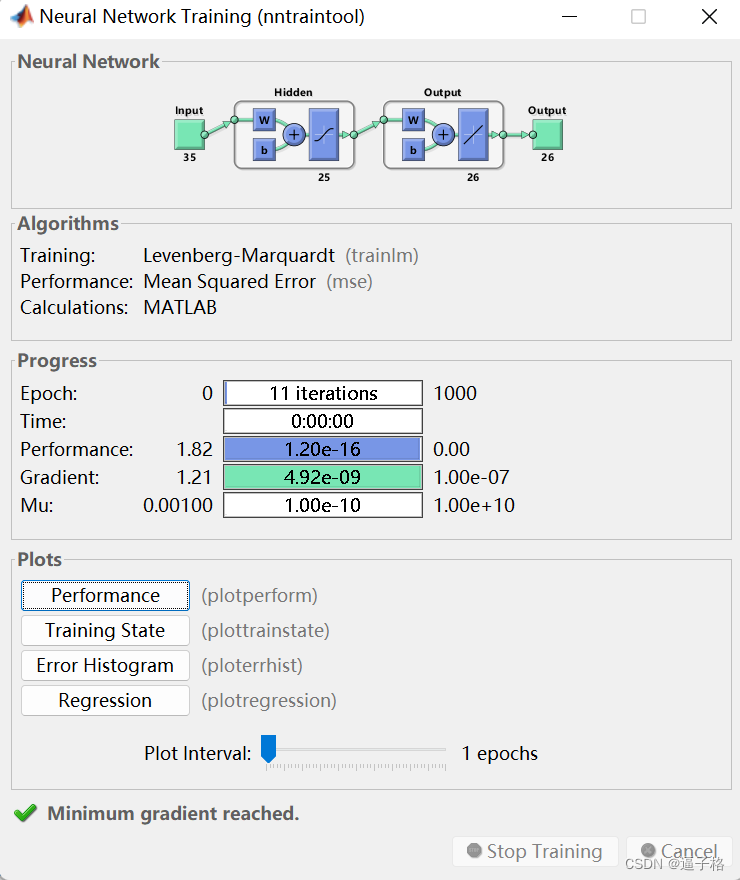
无噪声拼音字符数据集进行训练,当网络针对训练集或验证集不再可能有改善时,训练停止。
函数 train 将数据划分为训练集、验证集和测试集。验证集和测试集。训练集用于更新网络,验证集用于在网络过拟合训练数据之前停止网络,从而保持良好的泛化。测试集用作完全独立的测量手段,用于衡量网络针对新样本的预期表现。
代码
%当网络针对训练集或验证集不再可能有改善时,训练停止。
net1.divideFcn = '';
%函数 train 将数据划分为训练集、验证集和测试集。
%验证集和测试集。训练集用于更新网络,验证集用于在网络过拟合训练数据之前停止网络,从而保持良好的泛化。测试集用作完全独立的测量手段,用于衡量网络针对新样本的预期表现。
net1 = train(net1,X,T,nnMATLAB);视图结果
5、 训练第二个神经网络
说明
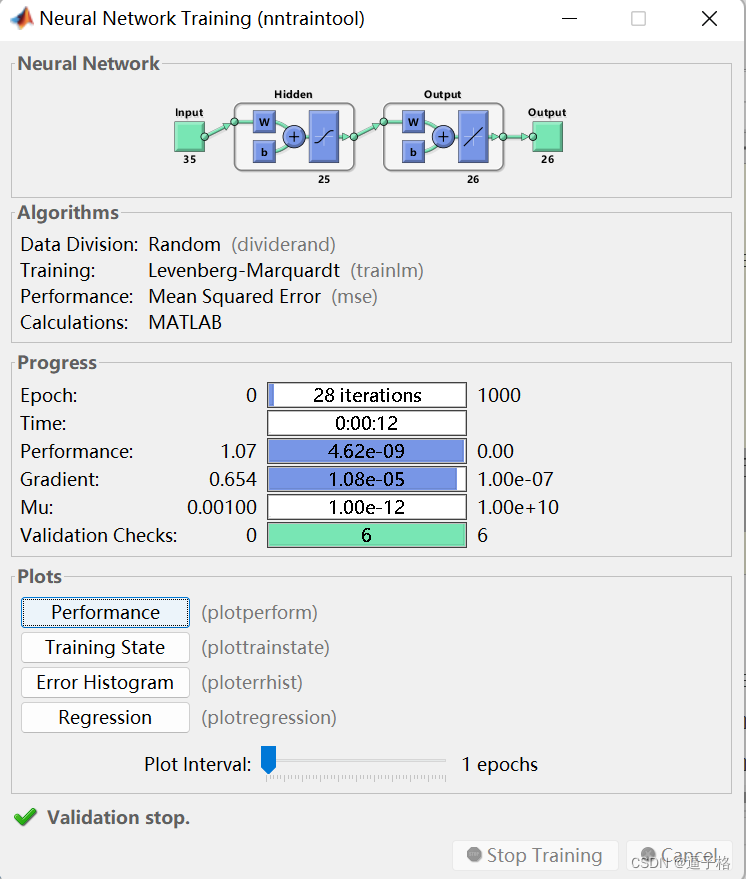
针对含噪数据训练第二个网络,并将其泛化能力与第一个网络进行比较。
代码
net2 = feedforwardnet(25);
net2 = train(net2,Xn,Tn,nnMATLAB);视图效果
6、测试两个神经网络
说明
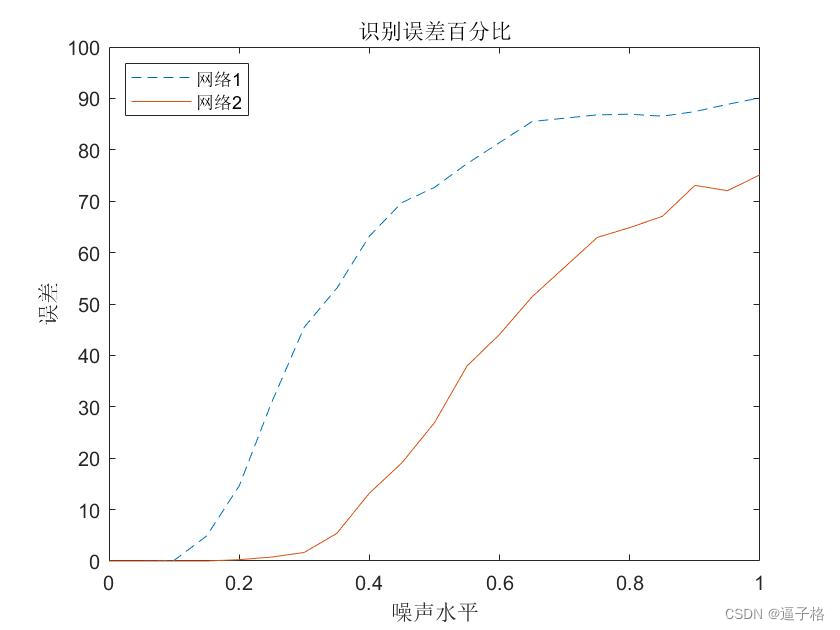
用测试数据集对训练好的网络1和网络2进行测试,X轴表示噪声强度Y轴表示误差百分比
代码
noiseLevels = 0:.05:1;
numLevels = length(noiseLevels);
percError1 = zeros(1,numLevels);
percError2 = zeros(1,numLevels);
for i = 1:numLevels
Xtest = min(max(repmat(X,1,numNoise)+randn(35,26*numNoise)*noiseLevels(i),0),1);
Y1 = net1(Xtest);
percError1(i) = sum(sum(abs(Tn-compet(Y1))))/(26*numNoise*2);
Y2 = net2(Xtest);
percError2(i) = sum(sum(abs(Tn-compet(Y2))))/(26*numNoise*2);
end
figure(3)
plot(noiseLevels,percError1*100,'--',noiseLevels,percError2*100);
title('识别误差百分比');
xlabel('噪声水平');
ylabel('误差');
legend('网络1','网络2','Location','NorthWest')试图效果
7、总结
基于深度学习的拼音字符识别在MATLAB中的总体流程如下:
-
数据集准备:收集包含拼音字符的数据集,可以是经过标记的拼音字符图片或者声音数据。
-
数据预处理:对数据集进行预处理,包括图像去噪、裁剪、归一化等处理,或者对声音数据进行特征提取、转换为图像数据等处理。
-
构建深度学习模型:选择适合拼音字符识别任务的深度学习模型,可以选择卷积神经网络(CNN)、循环神经网络(RNN)或者组合模型等。
-
模型训练:使用数据集对构建好的深度学习模型进行训练,调整模型参数使其能够更好地拟合数据。
-
模型评估:使用未标记的数据集对训练好的模型进行评估,评估模型的准确率、召回率、F1值等指标。
-
模型优化:根据评估结果对模型进行调优,可以调整模型结构、超参数,增加数据增强等方式来提高模型性能。
-
模型应用:将训练好的深度学习模型用于拼音字符识别任务,可以将其应用到实际场景中,如语音识别、文字转换等任务中。
以上是基于MATLAB的深度学习拼音字符识别的总体流程,具体实现细节可以根据具体需求和数据集的特点进行调整和优化。
主程序代码
%% 字符识别
%prprob 定义了一个包含 26 列的矩阵 X,每列对应一个字母。定义一个字母的 5×7 位图。
[X,T] = prprob;
%plotchar第三个字母 C 绘制为一个位图。
% figure(1)
% plotchar(X(:,3))
% title('不含噪声')
%% 创建第一个神经网络
%25 个隐藏神经元的前馈神经网络。
setdemorandstream(pi);
net1 = feedforwardnet(25);
%显示网络
view(net1);
%% 训练第一个神经网络
%当网络针对训练集或验证集不再可能有改善时,训练停止。
net1.divideFcn = '';
%函数 train 将数据划分为训练集、验证集和测试集。
%验证集和测试集。训练集用于更新网络,验证集用于在网络过拟合训练数据之前停止网络,从而保持良好的泛化。测试集用作完全独立的测量手段,用于衡量网络针对新样本的预期表现。
net1 = train(net1,X,T,nnMATLAB);
%% 训练第二个神经网络
%针对含噪数据训练第二个网络,并将其泛化能力与第一个网络进行比较。
%数据集加噪声
numNoise = 30;
Xn = min(max(repmat(X,1,numNoise)+randn(35,26*numNoise)*0.2,0),1);
Tn = repmat(T,1,numNoise);
figure(2)
plotchar(Xn(:,3))
title('含噪声')
%创建并训练第二个网络。
net2 = feedforwardnet(25);
net2 = train(net2,Xn,Tn,nnMATLAB);
%% 测试两个神经网络
noiseLevels = 0:.05:1;
numLevels = length(noiseLevels);
percError1 = zeros(1,numLevels);
percError2 = zeros(1,numLevels);
for i = 1:numLevels
Xtest = min(max(repmat(X,1,numNoise)+randn(35,26*numNoise)*noiseLevels(i),0),1);
Y1 = net1(Xtest);
percError1(i) = sum(sum(abs(Tn-compet(Y1))))/(26*numNoise*2);
Y2 = net2(Xtest);
percError2(i) = sum(sum(abs(Tn-compet(Y2))))/(26*numNoise*2);
end
figure(3)
plot(noiseLevels,percError1*100,'--',noiseLevels,percError2*100);
title('识别误差百分比');
xlabel('噪声水平');
ylabel('误差');
legend('网络1','网络2','Location','NorthWest')