Brief Intro
今年暑假,在科研和工业界之间,我选择在国内工业界找一份实习,参与到百模大战的浪潮中,主要的意向是知名的LLM领域的独角兽,期望能避免做Dirty Work,在实习过程中也能被重视,做一些有趣的事情。长远来看,我更倾向于做VLM和Agent(RAG),前者代表未来的趋势,后者代表更加经济的ToC模式。
在今年,我投了很多简历,也收到了很多面试邀请,主要的方式是通过**朋友圈、北大未名bbs、北邮人(感谢朋友给的账号)、NLPJOB、牛客网,**通过这样的方式,可以更大程度让技术组长看到你的简历,避免在简历上被HR因为非研究生等因素筛掉。
本篇文章旨在凝练自己20多场面试经验,为本科生找到算法实习生岗位提供样本和自信(在一开始,我自己其实不是很自信,投的都是一些规模偏小的公司,后面越来越有自信,也发现自己的能力确实能够匹配要求),为想找实习的朋友提供一定的经验,如果内容对大家有用,是我莫大的荣幸。
*所有观点仅代表我自己。*
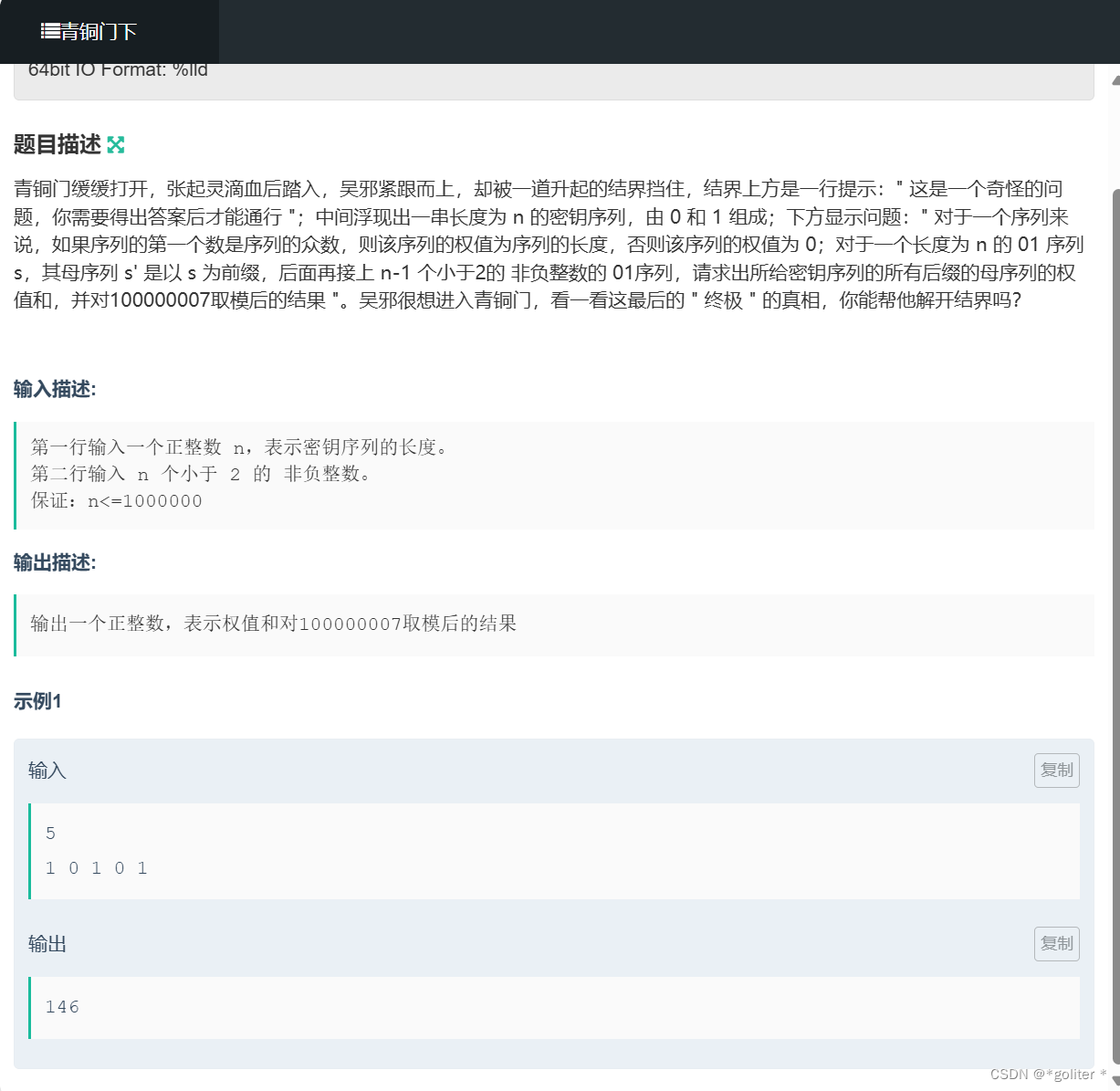
背景
25届转学本科生 (某211 -> 美本top53),去年暑假在THUNLP做RA,也在面壁智能实习,主要做AI Infra训练一块,有ACL在投,有语音顶会ICASSP,有一些高星开源项目,做的东西比较杂,MLSys和NLP都懂一些,从Arch到Sys到LLM以及VLM的全生命周期都有了解,最近在捣鼓Agent和RAG。
当然,有些东西太杂了也不好,被一位很好的面试官告知了修改简历的建议,要求突出重点,受益良多。
情况
Offer: 新旦科技xDAN、JINA AI、滴滴、智源、联想研究院、零一万物、商汤科技、腾讯AI Lab、上海AI Lab。
面试Rej:米哈游NLP二面拒、百度文心二面拒(可能要避雷,我这次面的是Eval组,做Alignment,简而言之就是标数据集,聊不到一块)。
给了面试但是因为时间原因没面:字节AML、腾讯云、地平线、旷视、百度大数据、Oneflow、360、小红书。
不给面试,直接拒:阿里云(众所周知)、阿里Qwen(需要多篇顶会一作)、华为全系(避雷,不是硕士 = 智障)。
面经
综合
我之前有一些NLP & MLSys的项目(前ChatGPT时代和后ChatGPT时代都有),包括但不限于:
- ASC22:训练YUAN-1.0中文预训练大模型
- NanoGPT:使用Pytorch 2.0 重写 NanoGPT
- Creator:GPT2微调的新闻标题摘要生成模型
- 代码生成:使用AST增强代码模型的功能
- 某分布式训练Pip库:高效易用的LLM Infra训练工具
这次面试的岗位大多数是预训练、少部分是垂类LLM、Agent相关,因此我主要参考了一些简单的八股,简单的Leetcode(后面发现用到的不多)
下面是按照时间顺序整理的一些各公司经验,为了尊重公司的隐私,我尽量使用更加广泛的概念描述,另外有一些细节我也记不太清了,还望海涵。
另外,一点小私货,我个人对于现在的国内LLM公司排行大概是:
Tier 0:阿里Qwen
Tier 1:Minimax、零一万物Yi、百度文心一言、月之暗面Moonshot、GLM、百川智能Baichuan、科大讯飞
Tier 1.5:商汤、腾讯混元、字节大模型、上海AI Lab InternLM
Tier 2:面壁(小模型)、360、XVERSE、昆仑天工大模型
Tier x:其他
新旦智能xDAN、JINA AI、联想研究院
都是比较早期面的了,也都是一面过,基本上和技术负责人聊得很好,主要聊项目。
滴滴
疯狂拷打项目,问了关于很多ZeRO、Megatron的问题,对于Activation、vLLM Decoding这块也问的比较深入,同时也问了下有关BLIP-2对齐方式、LLAVA如何实现模态对齐这些方面,问了LLAMA2特殊的点在哪里(类似SwiGLU激活函数、用了RoPE这块,分别又问深了一些),总体来说聊得还是比较愉快,学到了很多。给了一道写Self Attention和Multihead Attention的题。
百度文心一言
一面拷打项目,同样是问了很多关于MegatronLM的一些内容,也问了transformer的演化,对于我这边有关代码LLM的项目比较感兴趣,问了很多;提出了很多场景让我提供解决方案,经常问如果变一下会怎么样,总体而言面试体验良好。
二面的话就不对劲了,基本上没问简历上面的项目,问了我一堆WordPiece、BPE分词的操作,问Python的一些特性和函数是什么意思,给了一道很离谱的算法题(估计是拒),然后最后给我说要做Alignment,有没有数据标注的经验,感觉还是比较逆天的,考虑到进去之后要用Paddle这么折磨的工具,决定双向不奔赴了。
零一万物
一面拷打项目,两位面试官,问的东西很玄乎,主要问绕在并行计算方面的一些优化点,最后给了一道两数之和的题目来做,莫名奇妙地就过了,对于Yi这边还是我最后补充才问了一点,这家也是唯一一家提供远程机会的公司,产品质量都非常地高,抱着学习的目的,决定先做一做。
商汤科技
一面拷打项目,面试官对于AI Infra的了解非常深刻,也指出了我在前司这边做的项目的一些问题,告诉我可以优化的方向,给出了一些场景,让我给出解决方案,同时也是代码智能这边的Leader,给了一些代码补全的特殊场景的一些优化,考察了一些对于SFT的应用和知识,考了GLM和LLAMA2架构的区别。
二面简介完直接让我打开Megatron讲源码,非常硬核,最后是业务的讲解,比较动容的一句话是:我们商汤要恢复四小龙曾经的荣光,个人感觉做的项目也比较有意思,给的资源也很多,商汤是唯一一家在算力、数据、算法层面上都有丰富资源的地方,最后也决定来这边了。
米哈游NLP
一面快乐聊天聊业务,面试官是这个岗位的Leader,面试官这边感觉比较匹配,也跟面试官沟通了工作可能会做到的细节、对于当前的难点有什么比较好的解决思路。
二面画风突转,面试官是THU这边和上段实习比较熟的博后,问的问题相当深入,一面基本上我都在说主动多轮对话、Agent这边的一些经验,二面这边拷打我预训练的内容,感觉米哈游这边做的东西就比较奇怪,我个人觉得没有给我很好的发挥空间(主要是我这边也有些细节有点遗忘,离上次做已经有快5个月了),最后结果也拖了几天,脆拒了。
整体下来感觉有点割裂,大家各聊各的,对于预训练的点互相Care的也有点不一样,米哈游NLP这边给人的感觉有点奇怪(主观感受)。
腾讯AI Lab
游戏推理方向,偏RL + Infra,RL这边问的多的是PPO和DPO(当然这也是我仅会的),更偏向多智能体应用,Infra这边主要问推理,主要问的多一点的是Flash Decoding,训练这边也问了一些GQA的内容,比较友好,两面都给了一道很简单的Leetcode,今年看上去是真的回暖了一点。
上海AI Lab
Eval方向,一面问的是LLM的全生命周期,让我讲一遍(InstructGPT),问了些GPT4 Technical Report的内容,问的比较细,还是和米哈游那边一样,PLM这一块的内容有所生疏了,问论文实现方式,问掩码推理的一些细节,写MultiHead Attention。
二面这边流程差不多,用Numpy手写Softmax,细节也是比较到位的。
总结
达到了自己的目的,最终也是决定暑假去商汤,感觉在那边还是比较受重视的,资源也很多,待遇这边也很有诚意,总的来说,还是得对自己的项目比较熟悉(当然可能得先有项目),我自己的话是从大一上前ChatGPT时代就开始做LLM了,所以也是赶上了时代的潮流,什么都懂一点可能会改变自己思考问题的一些方式(也方便跑路),所以建议大家也学点其他方面的内容,在Github上面Follow一些有意思的人。
如果要强行归结一条公式,就是更多的高质量相关开源项目+相关高质量Paper(不是说发了多少篇)+实际工作经验(也许学历也占一部分因素,但是也只是够进面),我这边感觉应该是沾了点刘导和THUNLP的光,所以还是很感谢去年THUNLP能够把我收了(如果今年没找到满意的,可能也会回去)。
对于找工作而言,我觉得比自己合适的更重要一些,不要为了所谓大厂的Title做一些不情愿的事情,也希望大家能够对于一些食物保持怯魅的心态。
比较后悔的点是去年末期一边上班一边准备语言考试,对于收尾阶段的工作有些不上心,也对不起Mentor,在今年的面试上也受到了反噬,在后续的规划中,还是打算在工作这边更加上心,学有所得。
我寻获的每一枚符文,都是我们多活了一日的证明。
资源分享
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。