Shuffle 复用
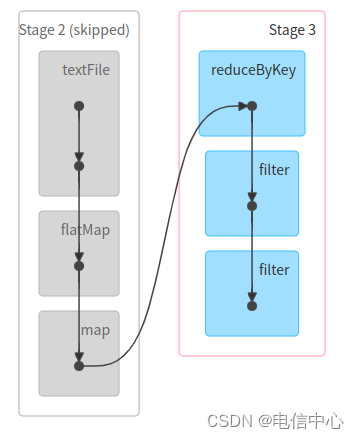
# 1.以下操作会复用的shuffle结果,只会读一遍数据源
val rdd1 = sc.textFile("hdfs://zjyprc-hadoop/tmp/hive-site.xml")
.flatMap(_.split(" "))
.map(x => (x,1))
.reduceByKey(_ + _)
.filter(_._2 > 1)
rdd1.count()
rdd1.filter(_._2 > 10).count()
# 2.以下操作每次需要重新执行整个操作,会读两遍数据源
sc.textFile("hdfs://zjyprc-hadoop/tmp/hive-site.xml")
.flatMap(_.split(" "))
.map(x => (x,1))
.reduceByKey(_ + _)
.filter(_._2 > 1)
.count()
sc.textFile("hdfs://zjyprc-hadoop/tmp/hive-site.xml")
.flatMap(_.split(" "))
.map(x => (x,1))
.reduceByKey(_ + _)
.filter(_._2 > 1)
.filter(_._2 > 10).count()
在第一个示例中,rdd1.count() 触发了计算,并且结果被存储,后续的 filter 和 count 操作都是在这个已经计算好的结果上进行的。而在第二个示例中,每次 count() 都是一个新的触发点,导致每次都需要重新计算。
并行度设置
shuffle并行度
如下图所示,作业中可能不止一个Job,shuffle数据只有几十mb,但是并行度设置了2000:
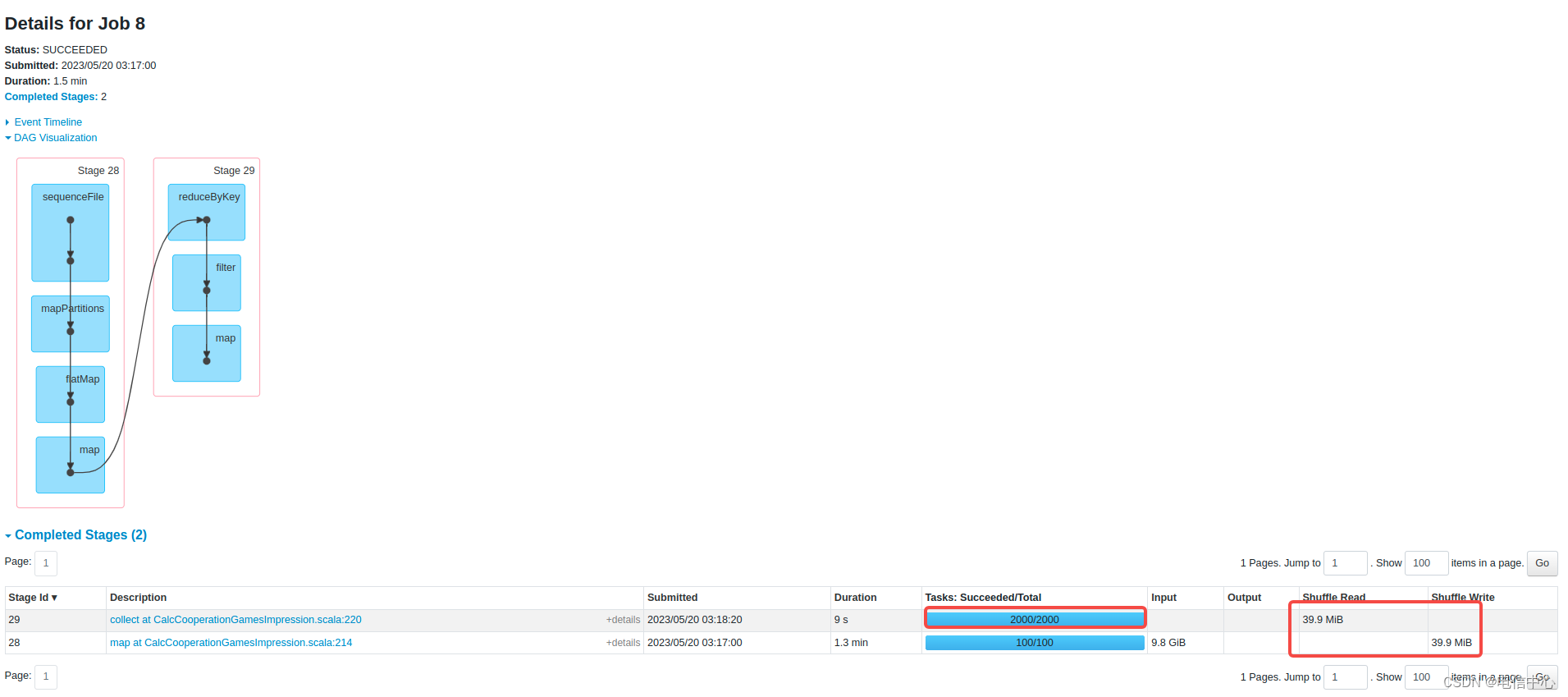
设置2000可能只是为了让作业中的一个Job的瓶颈更小:
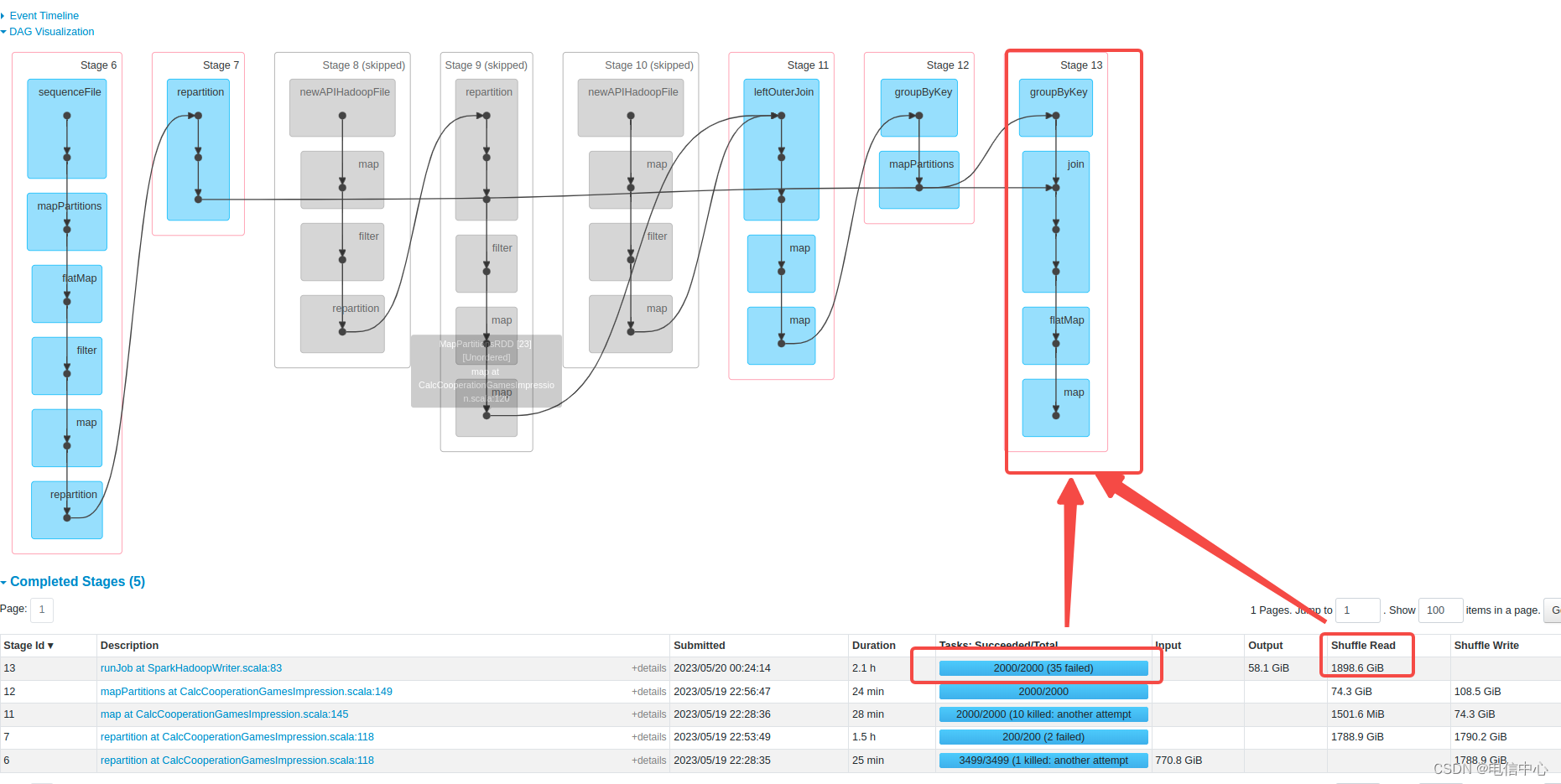
rdd程序其实控制能力极强的,常见的瓶颈算子都可以直接单独设置并行度的。
例如上述图中的算子可以由 rdd.reduceByKey(keyName) 改为 rdd.reduceByKey(keyName,3000)
scan file并行度
如果从hadoop输入的数据在后续的stage计算可能出现了内存瓶颈(gc时间比较长)时,可以考虑减少数据每个分区的大小,提高并行度:
-
DataSource读法,特指使用SparkSession.read这种,默认128:
spark.files.maxPartitionBytes=268435456 -
使用rdd直接读的,例如HDFSIO.thriftSequence、直接使用rdd hadoop api等,默认256(注意这个没有合并小文件功能):
spark.hadoop.mapred.max.split.size=268435456
REPARTITION 之后JOIN
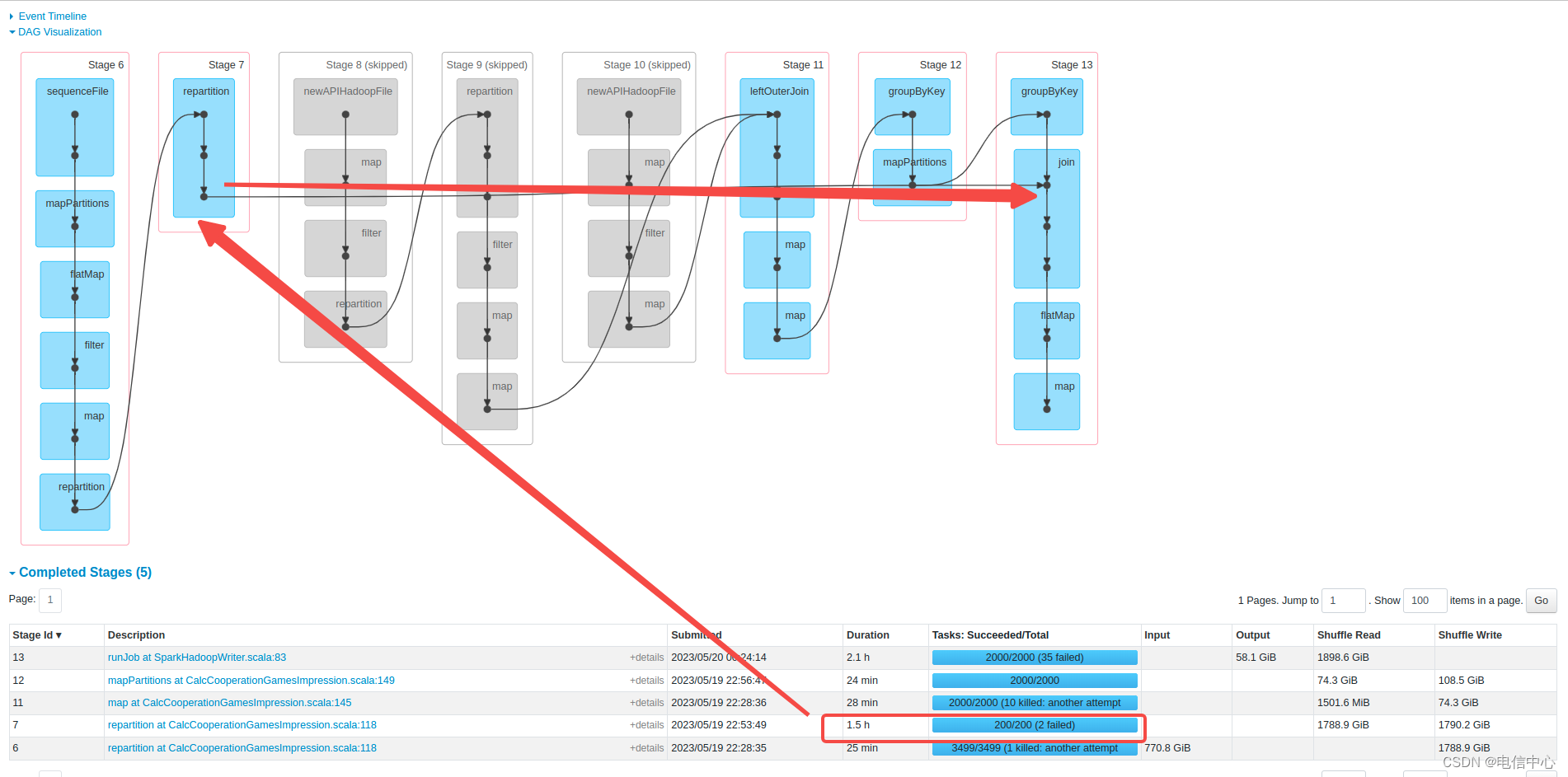
- 首先repartition是用来做什么的?
改变下游stage的并行度。 - 什么时候改变下游并行度是有用的?
- 下游是一个迭代计算,输入数据很少但是可能迭代所需资源很大,那么多并行度可以上每个task的输入数据变少。
- 输出文件后通过改变并行度,控制小文件。
- 为什么说上面的repartition基本无效?
因为repartition之后,没有任何操作,就进行shuffle,将数据shuffle输入给下游的join了。join需要根据join的key进行hash分布到不同的join的task中,上游这个repartition基本没任何意义了。
SQL中可能造成性能瓶颈的算子
Get json object
尤其是连续对一个json解析多个字段,如下图,效率很低:
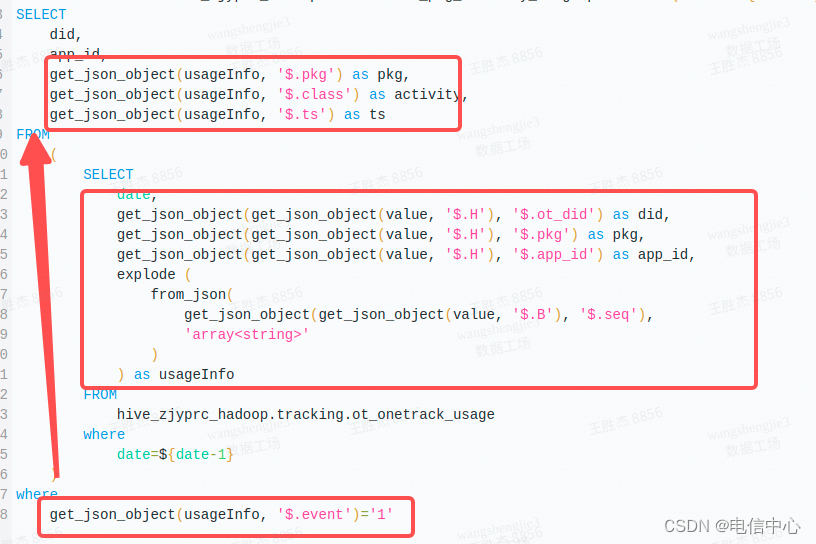
优化方式:
批量解析用json_tuple替换get_json_object,通常是更加高效的
问题原因:
--- t1 构建的测试数据
with t1 as (
SELECT properties
FROM VALUES ('{"a":1, "b":2, "c":3}') tab(properties)
)
--- 实际执行properties会被解析3次,效率较低
--- 期望只解析一次,复用解析后的结果,得到a,b, c
select
properties,
get_json_object(properties, '$.a') as a,
get_json_object(properties, '$.b') as b,
get_json_object(properties, '$.c') as c
from t1
优化方法:
--- t1 构建的测试数据
with t1 as (
SELECT properties
FROM VALUES ('{"a":1, "b":2, "c":3}') tab (properties)
)
--- 写法1(推荐)
--- 1.使用json_tuple指定要解析出来的字段 'a', 'b', 'c'
--- 2.将'a', 'b', 'c'中的'替换为`,作为别名
select
properties,
json_tuple(properties, 'a', 'b', 'c') as (`a`,`b`,`c`)
from t1
--- 写法2
--- 1.使用lateral view json_tuple指定要解析出来的字段 'a', 'b', 'c'
--- 2.将'a', 'b', 'c'中的'替换为`,作为别名
--- 3.直接指定select tb.*
--- select properties, tb.*
--- from t1
--- lateral view json_tuple(properties, 'a', 'b', 'c') tb as `a`,`b`,`c`
array_union
这个算子会对array的对象去重,涉及到排序等操作,可能某些array比较大就会非常慢。
count(distinct()) group by 替换 size(collect_set() partition by)
窗口函数中collect_set是一种执行很慢的操作。
重复缓存数据
在算子内部或者分区内部不断重复缓存元素,导致内存占用
rdd.map(ele => {
val list = ele.getList
val set = list.toSet
val result = list.map( *** )
})
rdd.foreachPartition(partition => {
val result = new HashMap<String, String>
while(partition.hashNext) {
val next = partition.next
result.put(next.key, next.value)
}
dealWithResult(result)
})
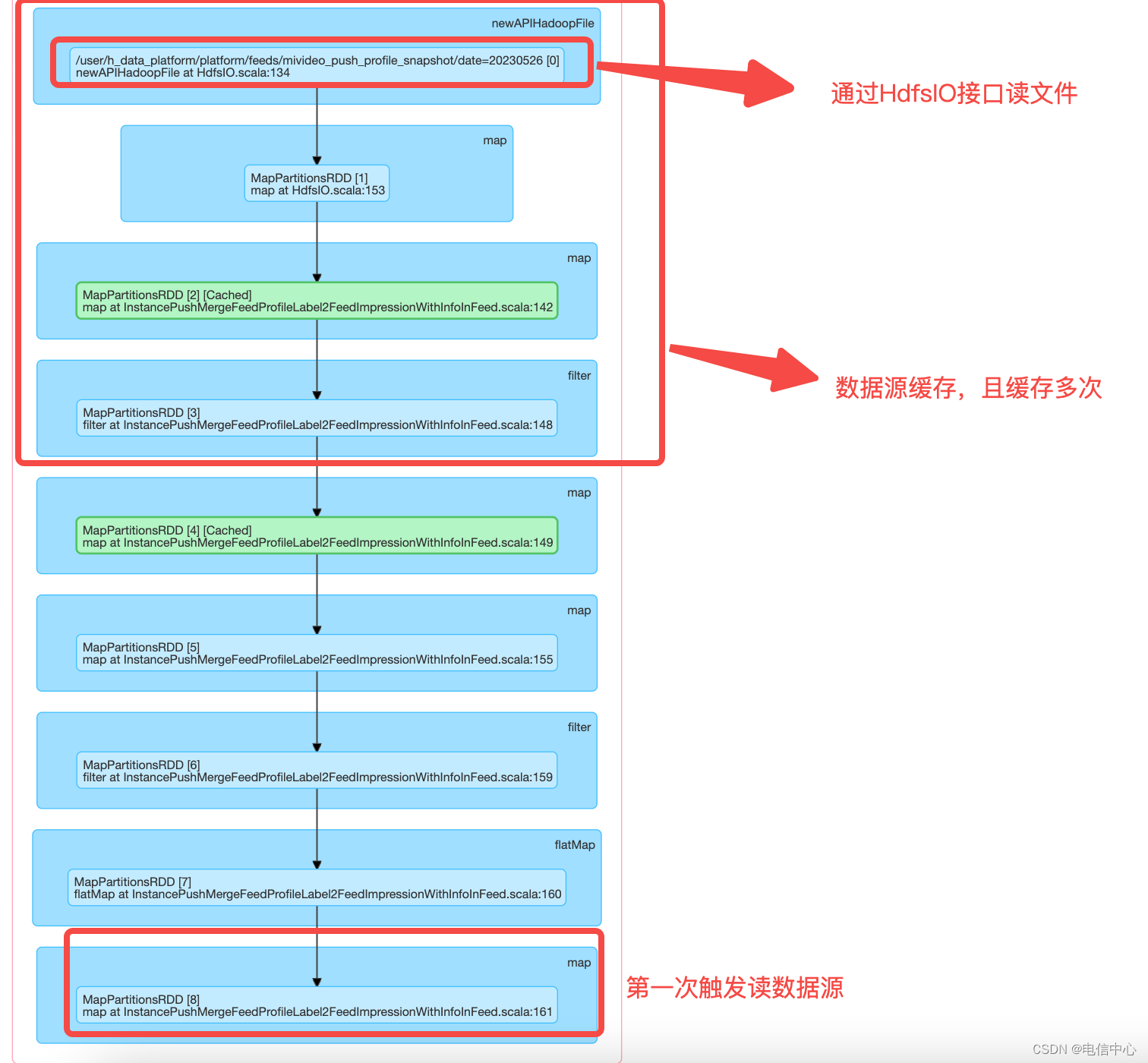
Cache 不合理
stage0:
stage3:
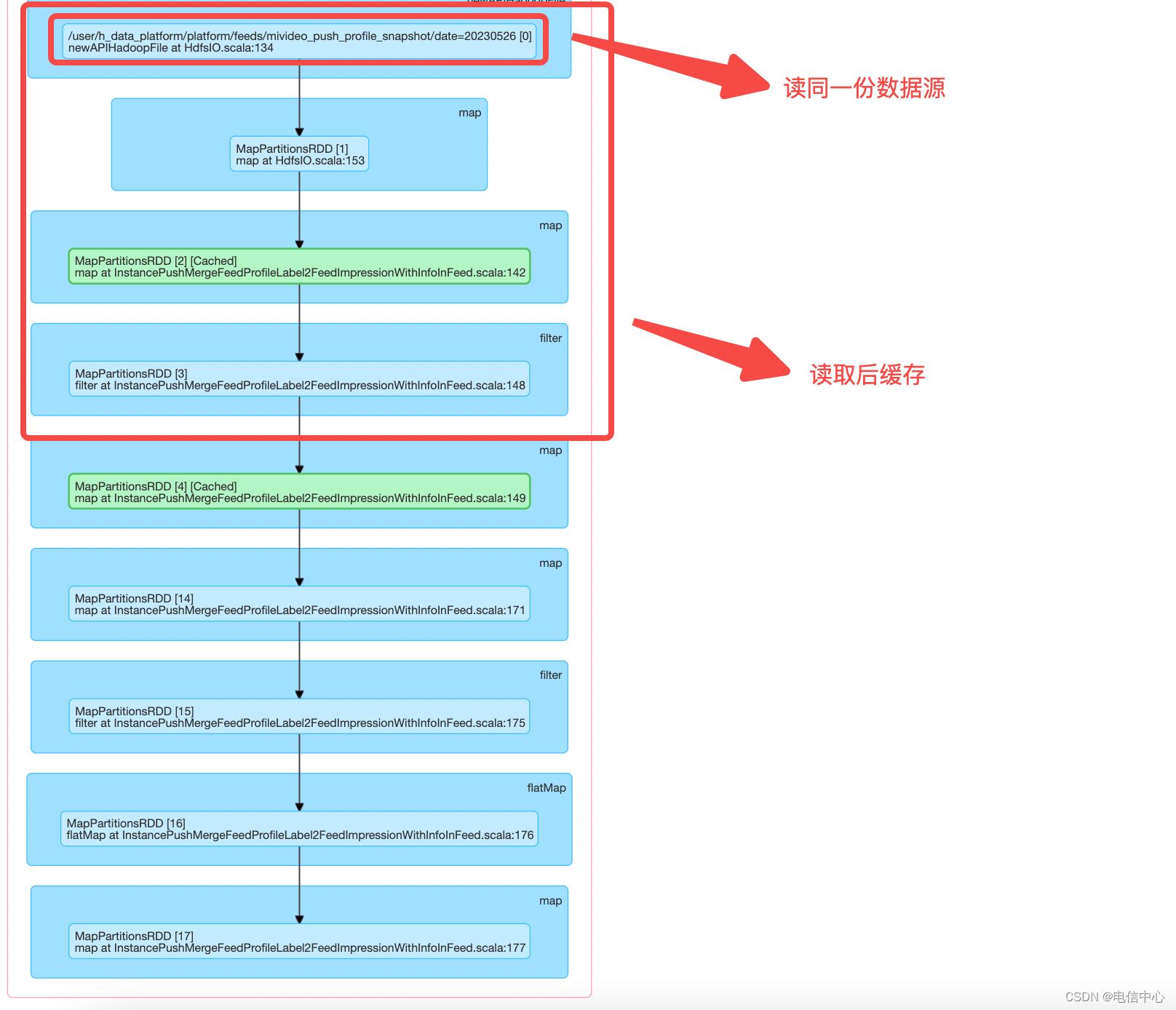
多次触发读相同的数据源,并且在同一个pipeline上使用了多次cache,但是并没有用上。
对比stage0和stage3, 在InstancePushMergeFeedProfileLabel2FeedImpressionWithInfoInFeed类第148行之前的逻辑是一致的。缓存应该对InstancePushMergeFeedProfileLabel2FeedImpressionWithInfoInFeed 148行的filter结果做缓存,后续使用缓存结果,避免重复读数据源。