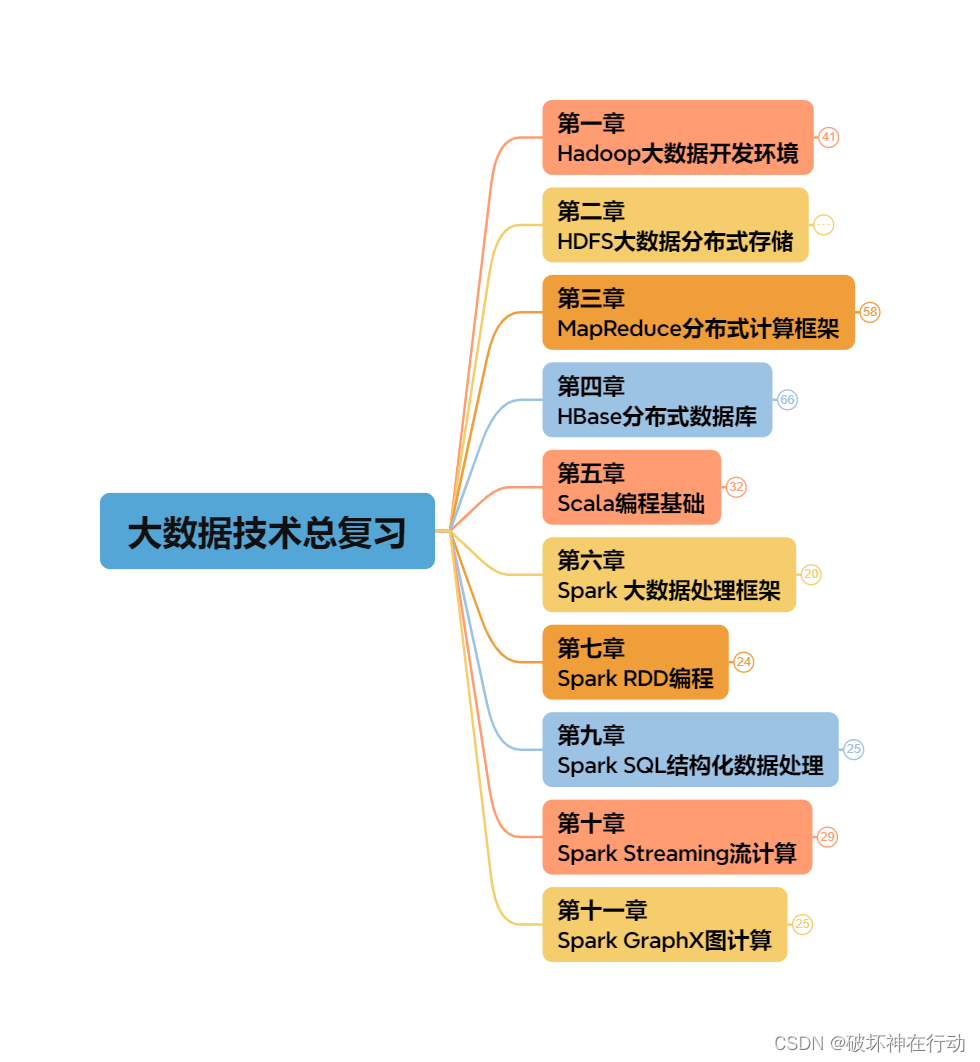
图1 Hadoop开发环境
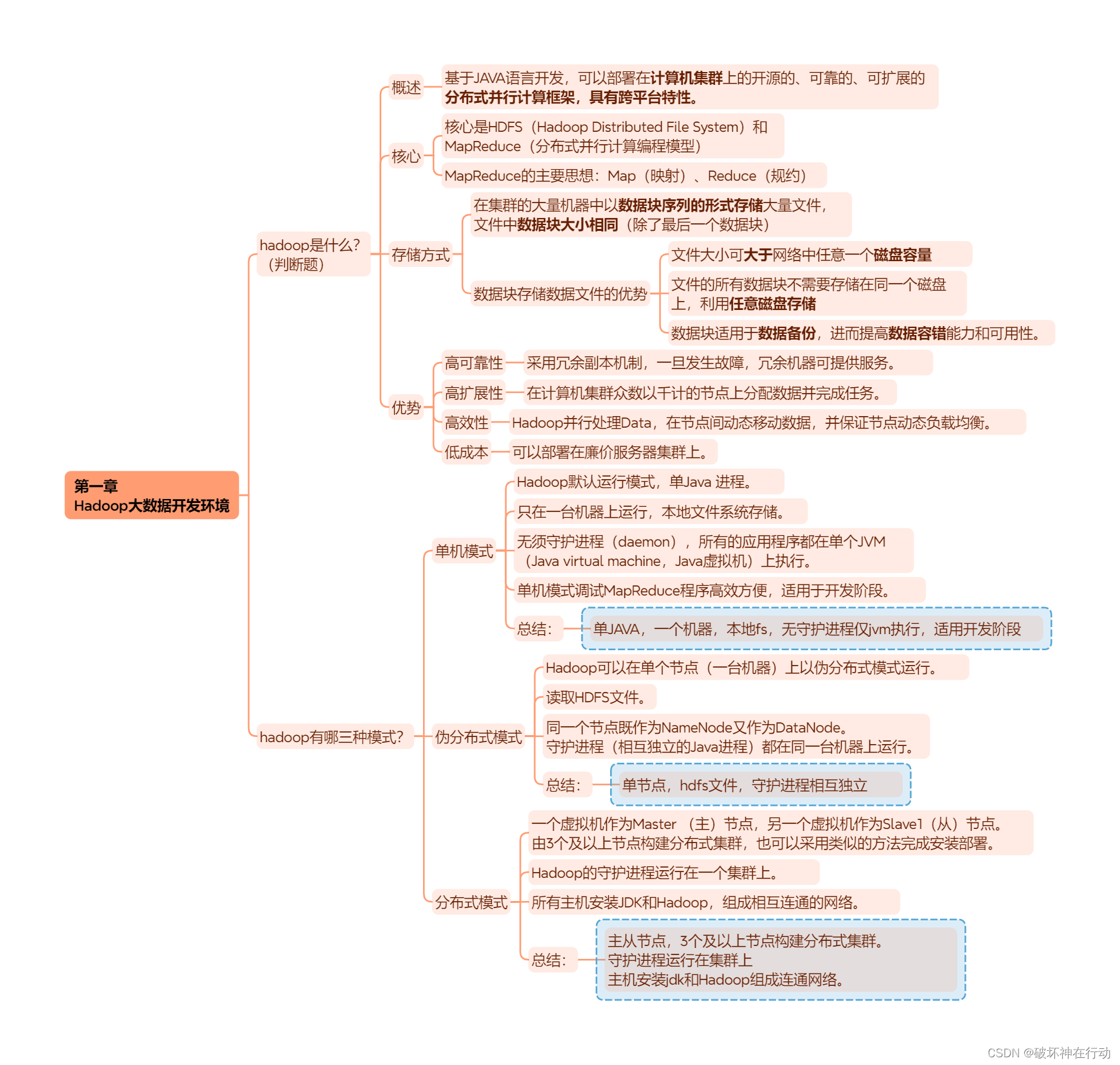
图2 HDFS

图3 MapReduce

图4 HBase

图5 Scala

图6 Spark

图7 Spark RDD

图8 (不考)
图9 Spark SQL

图10 Spark Streaming

图11 Spark GraphX

第一章 Hadoop大数据开发环境
hadoop是什么? (判断题)
概述
- 基于JAVA语言开发,可以部署在计算机集群上的开源的、可靠的、可扩展的分布式并行计算框架,具有跨平台特性。
核心
- 核心是HDFS(Hadoop Distributed File System)和MapReduce(分布式并行计算编程模型)
- MapReduce的主要思想:Map(映射)、Reduce(规约)
存储方式
- 在集群的大量机器中以数据块序列的形式存储大量文件,文件中数据块大小相同(除了最后一个数据块)
数据块存储数据文件的优势
- 文件大小可大于网络中任意一个磁盘容量
- 文件的所有数据块不需要存储在同一个磁盘上,利用任意磁盘存储
- 数据块适用于数据备份,进而提高数据容错能力和可用性。
优势
- 高可靠性:采用冗余副本机制,一旦发生故障,冗余机器可提供服务。
- 高扩展性:在计算机集群众数以千计的节点上分配数据并完成任务。
- 高效性:Hadoop并行处理Data,在节点间动态移动数据,并保证节点动态负载均衡。
- 低成本:可以部署在廉价服务器集群上。
hadoop有哪三种模式?
单机模式
- Hadoop默认运行模式,单Java 进程。
- 只在一台机器上运行,本地文件系统存储。
- 无须守护进程(daemon),所有的应用程序都在单个JVM(Java virtual machine,Java虚拟机)上执行。
- 单机模式调试MapReduce程序高效方便,适用于开发阶段。
总结:
单JAVA,一个机器,本地fs,无守护进程仅jvm执行,适用开发阶段
伪分布式模式
- Hadoop可以在单个节点(一台机器)上以伪分布式模式运行。
- 读取HDFS文件。
- 同一个节点既作为NameNode又作为DataNode。 守护进程(相互独立的Java进程)都在同一台机器上运行。
总结:
单节点,hdfs文件,守护进程相互独立
分布式模式
- 一个虚拟机作为Master (主)节点,另一个虚拟机作为Slave1(从)节点。 由3个及以上节点构建分布式集群,也可以采用类似的方法完成安装部署。
- Hadoop的守护进程运行在一个集群上。
- 所有主机安装JDK和Hadoop,组成相互连通的网络。
总结:
主从节点,3个及以上节点构建分布式集群。
守护进程运行在集群上,主机安装jdk和Hadoop组成连通网络。
第二章 HDFS大数据分布式存储
HDFS的基本特征?
1.大规模数据分布存储
基于大量分布节点上的本地文件系统 构成逻辑上具有巨大容量的分布式文件系统。
2.流式访问
批量处理数据
提高数据吞吐率
3.容错
正确处理故障,确保数据处理继续进行,且不丢失数据。
4.简单的文件模型
一次写入,多次读取。
支持在文件末端追加数据,不支持在文件位置任意修改。
5.数据块存储模式
减少元数据的数量。
6.跨平台兼容性
采用JAVA语言,支持JVM的机器都可以运行HDFS。
总结:
大分存、流访、容错、简单文件、块存储、跨平台
流式且容错地访问跨平台的简单文件中有大规模数据分布存储的块存储数据。
HDFS的存储架构?(4个)
采用经典的主从架构 4个部分组成
- Client(客户端)
- DataNode(数据节点)
- NameNode(名称节点)
- SecondaryNameNode(第二名称节点)
总结:CSDN
数据块
传统FS
- 概念:为提高磁盘读写效率,一般以数据块为单位,而不是以字节为单位,数据块是磁盘读写的最小单位。
- 大小:FS的数据块大小通常是几千B,而磁盘的数据块大小通常是512B。
HDFS
- 概念:如单一磁盘文件系统中的文件,HDFS的文件被分解成数据块大小的若干数据块,独立保存在各单元。
- 大小:HDFS的数据块是一个更大的单元。 Hadoop 1.x默认数据块大小是68MB,2.x是128MB。
- 如果文件小于数据块,文件不会占据该数据块的所有存储空间。 (例:1MB的文件只使用1MB的存储空间而不是128MB)
- 使用数据块的好处:
- 文件存储不受单一磁盘大小限制。
- 集群的若干磁盘共同存储,简化存储过程。
- 数据块大小固定,计算给定磁盘上存储的数据块个数简单。
总结:
不受磁盘限制,简化存储,计算块简单。
DataNode
- 存储管理元数据,用于存储文件的数据块。
- 数据块备份:每个数据块默认3个副本,DataNode最多存储一个备份。
- 处理数据读写请求,处理数据块创建删除指令。
- 通过心跳机制定时向NameNode发送存储的数据块信息。
- 数据块操作 (创建、删除、复制)
- 不能直接通过DataNode对数据块操作, 相关位置信息在NameNode中
- 故因先访问NameNode获取位置信息, 访问指定DataNode执行相关操作, 具体文件操作由客户端进程完成而非DN。
总结:
存管元数据、数据块,处理读写请求和块命令,心跳发块信息
NameNode
- 定义:中心服务器
- 功能:
- 管理FS的命名空间和元数据
- 处理客户端的文件访问请求
- 元数据分类 (3种)
- 命名空间(目录结构)
- 映射表(数据块-文件名)
- 位置信息(数据块副本)
- 元数据信息
- 文件的owership和permission。
- 文件包含哪些数据块。
- 数据块保存在哪个DataNode(由DataNode启动时上报)上。
总结:
管理命名空间和元数据,处理文件访问请求
SecondaryNameNode
- 功能:
- 辅助名称节点,分担其工作量。
- 备份NameNode的元数据(FsImage、EditLog) 以便失效恢复。
- FsImage (文件系统镜像)
- FsImage是HDFS的命名空间的静态映像或快照。它记录了文件系统的所有文件和目录的元数据信息,包括文件的权限、所有者、副本数以及目录结构等。
- FsImage文件保存了文件系统的当前状态,是文件系统的一个静态视图。
- EditLog (编辑日志)
- EditLog是一个记录文件系统变更操作的序列化日志。每当文件系统发生变更,如文件创建、删除、重命名等操作时,这些变更会首先被写入EditLog中。
- EditLog记录了文件系统变更的详细历史。
总结:
辅助NN,备份元数据F、E
心跳消息
NameNode周期向管理的各DataNode发送心跳消息, 收到心跳消息的DataNode回复。
客户端
- 是用户和HDFS通信的渠道之一,部署的HDFS都会提供客户端。
- 为用户提供了一种与Linux中的Shell类似的方式访问 HDFS的数据。
- 支持常见操作,如打开、读取、写入等
- 通过与NameNode和DataNode的交互来访问HDFS文件。
总结:
通信渠道、类Shell命令访问HDFS数据、可操作、ND交互访问HDFS文件
HDFS的Shell操作
启动命令?
启动Hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.sh
各个命令的含义? (HDFS常用的Shell 操作)
1.创建目录——mkdir 命令
2.列出指定目录下的内容——ls命令
3.上传文件——put命令
4.从HDFS中下载文件到本地文件系统——get命令
5.复制文件——cp命令
6.查看文件内容——cat命令
7.在HDFS目录中移动文件——mv命令
8.显示文件大小——du命令
9.追加文件内容——appendToFile命令
10.从本地文件系统中复制文件到HDFS——copyFromLocal命令
11.从HDFS中复制文件到本地文件系统—copyToLocal命令
12.从HDFS中删除文件和目录——rm命令
第三章 MapReduce分布式计算框架
分布式编程的主要特征
分布
- 一个程序由若干个可独立执行的程序模块组成。
- 这些程序模块分布于一个分布式计算机系统的几台计算机上且相互关联。
通信
- 程序模块在同时执行时需要交换数据,即通信。
- 通过通信,各程序模块能协调地完成一个共同的计算任务。
总结:分布通信(若干数据模块交换数据)
MapReduce的设计理念?
“计算向数据靠拢”,而不是“数据向计算靠拢”。
大规模数据处理环境下,移动计算要比移动数据(需要大量的网络传输)更有利。
Map函数?(含义)
接受序列(如列表)及一个函数, 将函数作用于列表中的所有成员,返回结果。
Reduce函数?(含义)
接收一个列表,一个初始参数,一个函数, 将该函数作为特定组合方式,递归应用于列表所有成员,返回结果。
MapReduce
核心思想:“分而治之”
执行流程
大数据(分块)-map函数-得到中间结果-Reduce函数-最终结果
组成部分:Client、JobTracker、TaskTracker、Task
工作原理?
MapTask
6个阶段
(HDFS文件输入)(输出到本地磁盘文件)
切片——解析键值对——map映射——分区——排序——reduce规约
ReduceTask
4个阶段
Copy-Merge-Sort-Reduce



WordCount词频统计

将文件拆分为两个split,交给两个Map任务并行处理,按行分割<key1,value1>
(key1表示偏移量包括换行符,value1表示文本行)
文件1
<0,"Hello World">
起始开始算,无偏移量,故key1为0
<12,"Bye World">
第一行有11个字符,加上换行符共12个字符, 故key1的偏移量为12
文件2
<0,"Hello Hadoop">
<13,"Bye Hadoop">
<key1,value1>交给map()生成新键值对<key2,value2>
(key2表示每个单词,value2表示单词出现的词频数)
文件1
<Hello,1>
<Worlld,1>
<Bye,1>
<Worlld,1>
文件2
<Hello,1>
<Hadoop,1>
<Bye,1>
<Hadoop,1>
Mapper将<key2,value2>按照key值排序,执行Combine过程
(将key值相同的value值累加统计单词出现次数)
文件1
<Bye,1>
<Hello,1>
<Worlld,1>
<Worlld,1>
<Bye,1>
<Hello,1>
<Worlld,2>
文件2
<Bye,1>
<Hadoop,1>
<Hadoop,1>
<Hello,1>
<Bye,1>
<Hadoop,2>
<Hello,1>
Reducer对从Mapper接收的数据排序,再使用自定义的reduce()方法处理得到<key3,value3> (将value值的出现次数加入列表,再将列表中的数相加得到最后的value3)
文件1
<Bye,1>
<Hello,1>
<Worlld,2>
文件2
<Bye,1>
<Hadoop,2>
<Hello,1>
第四章 HBase分布式数据库
HBase与传统关系DB的区别?
1.数据类型方面
- 关系数据库具有丰富的数据类型,如字符串型、数值型、日期型、二进制型等。
- HBase只有字符串数据类型,数据的实际类型都是交由用户自己编写程序对字符串进行解析的。
2.数据操作方面
关系数据库包含丰富操作,如插入、删除、更新、查询等,其中还涉及各式各样的函数和连接操作。
HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的。
3.存储模式方面
关系数据库是基于行存储的,在关系数据库中读取数据时,需要顺序扫描每个元组,然后从中筛选出所需要查询的属性。
HBase是基于列存储的,HBase将列划分为若干个列族,每个列族都由几个文件保存,不同列族的文件时分离的,它的优点是:可以降低IO开销,支持大量并发用户查询,仅需要处理所要查询的列,不需要处理与查询无关的大量数据列。
4.数据维护方面
在关系数据库中,更新操作会用最新的当前值去替换元组中原来的旧值。
而HBase执行的更新操作不会删除数据旧的版本,而是添加一个新的版本,旧的版本仍然保留。
5.可伸缩性方面
HBase分布式数据库就是为了实现灵活的水平扩展而开发的,所以它能够轻松增加或减少硬件的数量来实现性能的伸缩。
而传统数据库通常需要增加中间层才能实现类似的功能,很难实现横向扩展,纵向扩展的空间也比较有限。
HBase与Hadoop中其他组件的关系

HBase作为Hadoop生态系统的一部分,
一方面它的运行依赖于Hadoop生态系统中的其他组件;
另一方面,HBase又为Hadoop生态系统的其他组件提供了强大的数据存储和处理能力。
HBase使用HDFS作为高可靠的底层存储,廉价集群提供海量数据存储。
HBase使用MapReduce处理海量数据,高性能计算。
HBase利用ZooKeeper提供协同服务,高可靠的锁服务,保证集群中机器看到的试图一致; 实现节点管理以及表数据定位。
Sqoop提供高效便捷的数据导入功能。
Pig和Hive提供高层语言支持。
HBase数据表的物理视图
在四个维度以键值对形式保存数据
1.行键(Row Key)
2.列族( Column Family)
3.列名(Column Name )
4.时间戳(Time Stamp)
如何创建表?(重点)
创建student表,列族为baseinfo和score,版本数均设为2
create 'student',{NAME=>'baseinfo',VERSION=>2},{NAME=>'score',VERSION=>2}
HBase的Shell操作(各个命令的含义/功能? )
基本命令
1.获取帮助help
2.查看服务器状态status
3.查看当前用户whoami
4.命名空间相关命令
(1)列出所有命名空间命令list_namespace
(2)创建命名空间命令create namespace
(3)查看命名空间命令describe_namespace
(4)创建表命令create
(5)列出指定命名空间下的所有表命令 list_namespace_tables
(6)使表无效命令disable
(7)删除表命令drop
(8)删除命名空间命令drop namespace
插入与更新表中的数据
给表student添加数据:行键是0001,列族名是baseInfo,列名是Sname,值是ding。
put 'student, '0001,'baseInfo:Sname','ding'
查看表中的数据
1.查询某行数据get
2.浏览表中全部数据scan
删除表中的数据
delete命令用于删除一个单元格数据
deleteall命令用于删除一行数据
truncate命令用于删除表中的所有数据
表的启用/禁用
enable和disable可以启用/禁用表
is_enabled和is_disabled来检查表是否被禁用。
修改表结构
修改表结构必须先禁用表。
disable 'student'#禁用student表
1.添加列族alter '表名',列族名'
2删除列族 alter '表名',{NAME=>'列族名',METHOD => 'delete'}
删除HBase表
第一步禁用表,第二步删除表。
disable 'student’#禁用student表
drop 'student'#删除student表
第五章 Scala编程基础
Scala的特性?
1. 面向对象:
Scala是一种完全面向对象的语言。其每一种数据类型都是一个对象,这使得它具有非常统一的模型。
2. 函数式编程:
Scala同时支持函数式编程,它拥有高阶函数、闭包、不可变数据结构、递归等函数式编程的关键特性。
3. 扩展性:
Scala的语法非常灵活,允许开发者自定义运算符和语法糖。也支持模式匹配、类型推断和匿名函数等高级特性,这些都为编写简洁、高效的代码提供了可能。此外,Scala的语法允许在单个文件中定义类、对象、函数等,使得代码组织更加灵活。
4. 并发性:
Scala支持Actor模型(处理并发的轻量级机制)。通过Actor,可以编写出线程安全的、易于管理的并发代码,有效地利用多核处理器资源。
5. 可以和Java混编:
Scala运行在Java虚拟机(JVM)上,并兼容Java的API。可以直接使用Java库,或者在Scala代码中调用Java方法,反之亦然。这为已有的Java项目提供了无缝迁移到Scala的可能,也使得Scala成为一个非常实用的工具,可以在不完全重构的情况下逐步引入新的编程范式。
总结:对象、函数式、扩展、并发、混编
阅读程序 (参考作业)
9种基本数据类型
- String位于java.lang包,其余位于Scala包
- Unit无返回值
- Nothing是任何其他类型的子类
- Any是所有其他类型的超类(父类)

循环结构 (阅读程序)
数组、列表、集合、元组、映射(‘字典’)
- 数组(Array):固定大小的集合,元素类型相同,性能较好但不支持动态修改大小。
- 列表(List):不可变的序列集合,适合于递归处理和模式匹配,但头部插入和删除效率低。
- 集合(Set):无序且不重复元素的集合,分为可变和不可变两种。
- 元组(Tuple):固定长度、不同类型的元素组合,最多支持22个元素,常用于同时携带多种类型信息。
- 映射(Map):键值对的集合,键唯一,分为可变和不可变两种,适合快速查找。
Scala函数
定义
def 函数名([参数列表]):[函数的返回值类型]={ 函数体 return[返回值表达式] }
匿名函数
也称为Lambda函数。箭头“=>”定义,箭头的左边是参数列表,箭头的右边是表达式,表达式的值即匿名函数的返回值。 在代码中直接定义的函数,没有具体的函数名。通常用于一些简单的、一次性的操作。
val sum = (x: Int, y: Int) => x + y val result = sum(3, 5) // result = 8
高阶函数
高阶函数是指使用其他函数作为参数,或者返回一个函数作为结果的函数。
val numbers = List(1, 2, 3, 4) val doubled = numbers.map(x => x * 2) // doubled = List(2, 4, 6, 8)
Scala面向对象编程
单例对象:object创建单例对象
第六章 Spark 大数据处理框架
Spark的生态系统

Spark Core
Spark生态系统的核心组件,分布式大数据处理框架
功能
任务调度、内存管理、错误恢复、与存储系统交互
RDD中的API(Application Programming Interface)应用程序编程接口
Spark SQL
操作结构化数据的核心组件,统一处理关系表和RDD
Spark Streaming
处理流数据的计算框架
特点:可伸缩、高吞吐量、容错能力强等。
Spark MLlib
(Machine Learning Library)可扩展的机器学习库,包含通用学习算法和工具。
Spark GraphX
分布式图处理框架,有图计算和图处理的API
Local、Standalone、EC2、Mesos、YARN (5种部署模式)
local本地模式,常用于开发测试
standalone:Spark自带的资源管理框架
另外三种为资源管理框架
第七章 Spark RDD编程
RDD的概念?
Resilient Distributed Dataset 弹性分布式数据集
只读分区记录的集合
是Spark对具体数据对象的一种抽象(封装)
创建RDD的方式
sc表示SparkContext对象,Spark的主要入口;
parallelize()并行化程序中的数据集。
程序中的数据集创建RDD
val arr = Array(1,2,3,4,5) val rdd = sc.Parallelize(arr)
Spark计算
RDD创建 (Create)
创建后不可以改变
转换 (Transformation)
对已有RDD转换操作后产生新RDD,有时生成中间RDD。
惰性计算机制
遇到转换操作不会立即转换,在执行行动操作时一起执行。
行动 (Action)
对已有RDD的数据进行计算产生结果,返回到驱动程序或写入外部物理存储。
RDD之间的依赖关系
窄依赖
父RDD最多被一个子RDD使用, 一个子RDD对应多个父RDD
父指一子, 一子多父
宽依赖
父RDD可被多个子RDD使用, 一个子RDD可对应所有父RDD
父有多子, 子有全父
词频统计
第九章 Spark SQL结构化数据处理
DataFrame与Dataset区别?
DataFrame
基于 Row 对象的二维表格结构,类似于关系型数据库中的表。
行和列都有明确的 Schema(模式),可以进行类型推断。
提供了丰富的操作接口,如 select、filter、group by、agg 等。
缺点: 需要在操作时进行类型转换,例如使用 col("age").cast("int") 将类型转换为 Int。
Dataset
基于特定类型的数据结构。 例如 Dataset[Student],其中 Student 是一个 case class。
相比 DataFrame,Dataset 能更方便地进行类型推断,无需显式转换。
优点: 代码更简洁,类型安全,编译器可以进行类型检查。
总结
当需要进行类型安全的操作时,Dataset 是更好的选择。
当数据结构复杂,需要进行类型转换时,DataFrame 更灵活。
创建DataFrame对象的方式
RDD创建(重点)
val list = List( ("zhang" , "18") , ("wang" , 17) , ("LI" , 20) )
val df = sc.parallelize(list).toDF("name" , "age")
DataFrame对象的常用操作 (阅读程序)
创建Dataset对象
val stuDS = spark.read.textFile("file:/home/hadoop/student.txt")
解释
val stuDS = ...: 声明一个名为 stuDS 的变量,它是一个 Dataset[String] 类型,用于存储从文件中读取的数据。Dataset 是 Spark 中用于表示数据集的抽象类型,这里表示一个包含字符串的集合。
spark.read: Spark 中读取数据的入口点。它提供了读取不同数据格式的方法。
.textFile("file:/home/hadoop/student.txt"): 指定要读取的文本文件的路径。
代码的作用:
创建一个 Spark DataFrame(用 Dataset[String] 对象表示),命名为 stuDS。
DataFrame 包含 "student.txt" 文件中每行的内容,作为独立的字符串。
第十章 Spark Streaming流计算
流数据
- 数据实时到达
- 到达次序独立,不受系统控制
- 规模宏大
- 一经处理除非特意保存否则不能再次取出处理(再提取代价高)
流计算概述
流计算概念
是一种用于实时处理连续数据流的计算模式。
实时获取来自不同数据源的海量数据,实时分析处理获得有价值信息。
区别
批处理计算通常处理静态数据集
流计算则处理持续不断的数据流,例如传感器数据、网站日志、金融交易等。
基本理念
即数据的价值随着时间的流逝而降低。
因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。
为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎。
- 需求
(1)高性能:是处理大数据的基本要求,如每秒处理几十万条数据
(2)海量式:需支持TB级甚至是PB级的数据规模
(3)实时性:要保证较低的延迟时间,达到秒级别,甚至是毫秒级别
(4)分布式:要支持大数据的基本架构,必须能够平滑扩展
(5)易用性:要能够快速进行开发和部署
(6)可靠性:要能可靠地处理流数据
第十一章 Spark GraphX图计算
创建属性图的方式?
//创建一个顶点集的RDD
val users: RDD[(VertexId ,(String,String))] = sc.parallelize(
Array(
(3L,("rxin","student")),
(7L,("jgonzal","postdoc")),
(5L,("franklin","prof")),
(2L,("istoica","prof")),
))
//创建一个边集的RDD
val relationships:RDD[Edge[String]] = sc.parallelize(
Array(
Edge(3L,7L,"collab"),
Edge(5L,3L,"advisor"),
Edge(2L,5L,"colleague"),
Edge(5L,7L,"pi"),
))
- val users: RDD[(VertexId, (String, String))]:声明一个名为 users 的 RDD,它包含顶点信息。每个顶点由一个 VertexId(长整型)和一个元组 (String, String) 表示,元组包含顶点的姓名和角色。
- val relationships:RDD[Edge[String]]:声明一个名为 relationships 的 RDD,它包含边信息。每个边由一个 Edge 对象表示,包含两个顶点 ID 和一个字符串类型的属性(关系类型)。
- sc.parallelize(Array(...)):使用 SparkContext 的 parallelize 方法将一个数组转换为 RDD。
属性图操作(顶点数?边数?出/入度?) (计算)
1. 获取边的数量
userGraph.numEdges
resl: Long = 7
2. 获取顶点的数量
userGraph.numVertices
res2:Long = 6//获取顶点的数量
3. 获取所有顶点的入度
userGraph.inDegrees.collect.foreach(println)
(4,1)
(1,1)
(5,1)
(6,2)
(3,2)
userGraph.inDegrees:获取图中所有顶点的入度,返回值类型为 VertexRDD[Int]。VertexRDD 是 GraphX 中用来表示顶点数据的 RDD。
(1,1) 表示顶点 1 的入度为 1,有一条边指向顶点1
4. 获取所有顶点的出度
userGraph.outDegrees.collect.foreach(println)
(4,1)
(1,1)
(5,1)
(2,3)
(3,1)
userGraph.outDegrees:获取图中所有顶点的出度,返回值类型为 VertexRDD[Int]。
(1,1) 表示顶点 1 的出度为 1,有一条边从顶点1 发出
5. 获取所有顶点的入度和出度之和
userGraph.degrees.collect.foreach(x => print(x + ","))
(4,2),(1,2),(5,2),(6,2),(2,3),(3,3),
userGraph.degrees:获取图中所有顶点的入度和出度之和,返回值类型为 VertexRDD[Int]。
collect:将 VertexRDD 中的元素收集到一个本地数组中。
foreach(x => print(x + ",")):遍历本地数组,并打印每个顶点及其入度和出度之和。
输出结果:每个顶点及其入度和出度之和,例如 (4,2) 表示顶点 4 的入度和出度之和为 2 + 2 = 4。