前面简单爬取了某Top250电影的一些信息。本文,来尝试搞到每个电影的简介信息。
目录:
- 1. 获取电影简介信息
- 1.1 第一步:配对每个电影对应的简介信息:
- First:包含电影简介信息url的获取
- Second:爬虫文件的更改
- Third:编写get_detail()函数
- 注意:特例的处理
- 1.2 第二步:把每个电影的简介信息存储到对应的电影信息里:
- ①按习惯性的思路:步骤如下
- ②习惯性思维不行,Scrapy框架设计者肯定也考虑到这种问题了—引入meta参数解决,如下:
- 1.3 会发现可以很完美的搞到我们所想要的数据:
1. 获取电影简介信息
1.1 第一步:配对每个电影对应的简介信息:
First:包含电影简介信息url的获取
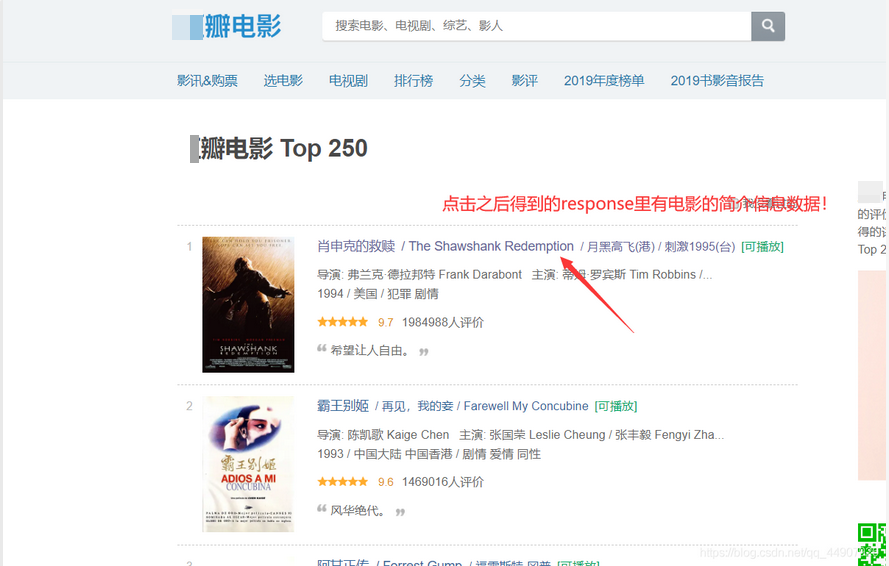
- 观察网页可知,我们要想获取到每个电影的简介信息。首先要获取到每个电影的包含它简介信息的url。
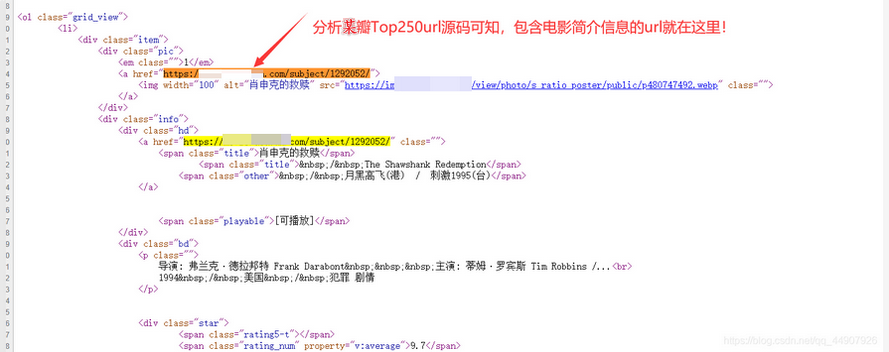
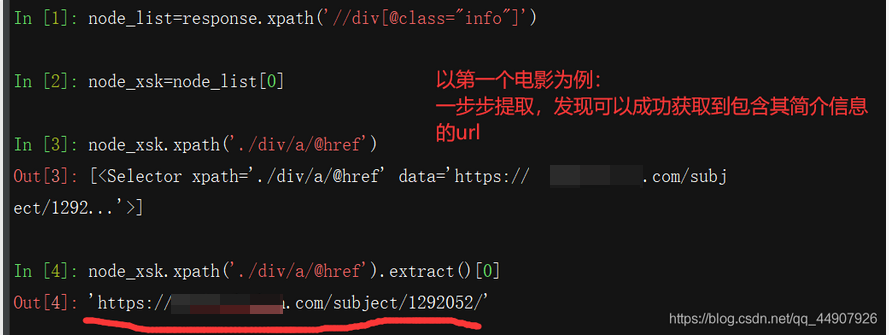
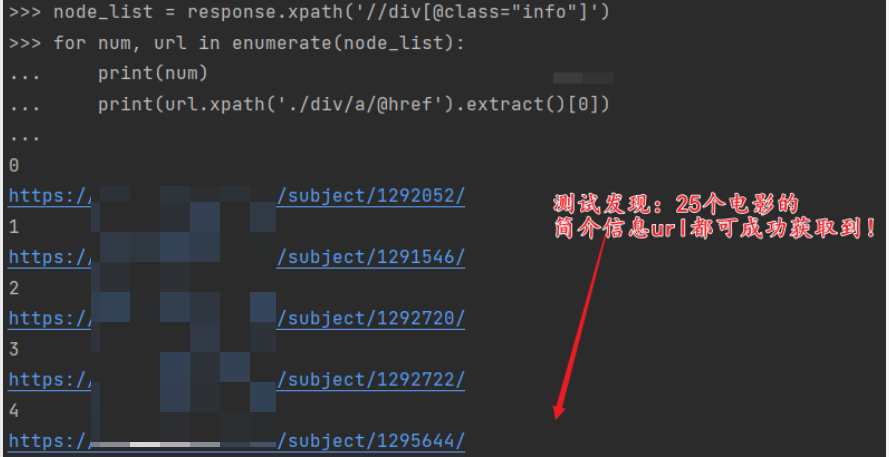
Second:爬虫文件的更改
- 在爬虫文件中加入此成功的代码,并且,我们所获取到的是request请求,而Scrapy框架里一切请求都要交给引擎,所以我们要将此request请求yield返回给引擎,让引擎进行一系列处理。最后,引擎处理完之后,要将处理过后的数据再交给爬虫文件进行数据解析及获取,而这就需要我们在爬虫文件中定义一个专门解析与获取电影简介信息的函数(注意:这个函数一定要包含response参数用于接收引擎交给爬虫文件的数据)
#将下面代码加到爬虫文件中parse函数的循环的最下面:
detail_url=node.xpath('./div/a/@href').extract()[0]
yield scrapy.Request(detail_url,callback=self.get_detail)
#将下面函数加入爬虫文件:
def get_detail(self,response):
pass
Third:编写get_detail()函数
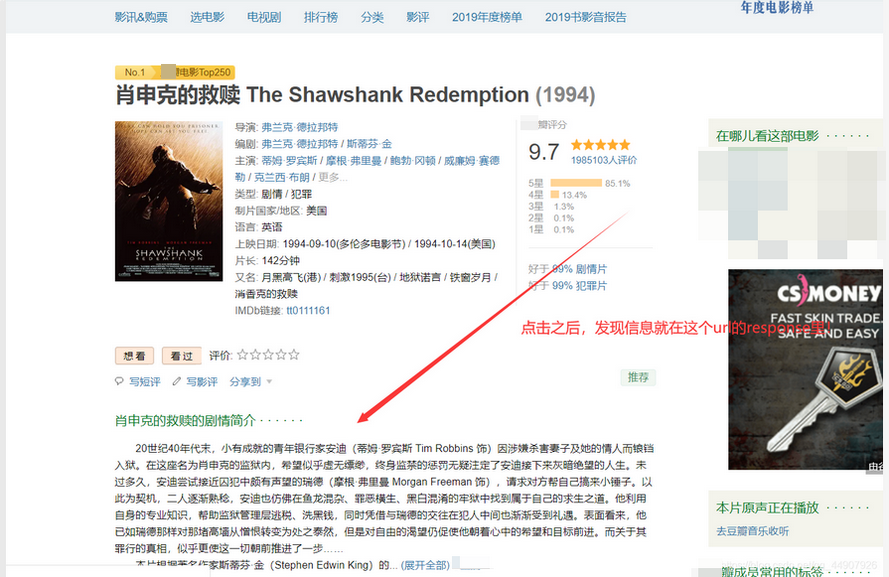
- 现在,我们就要使用我们自定义的函数get_detail()处理引擎处理过后交给我们的response了。这给咱的是个response,咱继续分析这个response的网页源码,使用xpath匹配到我们所需的电影的简介信息即可!

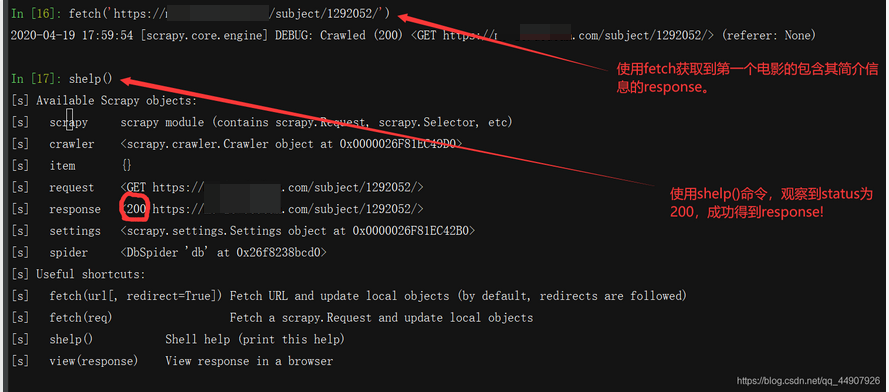

将此代码加入到我们写的get_detail()函数里即可:
def get_detail(self,response):
#获取电影简介信息
description=response.xpath('//div[@id="link-report-intra"]/span/span[@property="v:summary"]/text()').extract()[0].strip()
注意:特例的处理
- 在测试的时候,发现有个电影的简介信息是个特例,它放的标签结构与众不同,所以咱改下爬虫文件中的get_detail()函数:
def get_detail(self,response):
#获取电影简介信息
description=response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0].strip()

1.2 第二步:把每个电影的简介信息存储到对应的电影信息里:
①按习惯性的思路:步骤如下
(1)首先:在items.py文件中创建一个用于存储电影简介信息的字段
description=scrapy.Field()
(2)settings.py文件中开启管道;并设置延时
(3)在爬虫文件中将电影简介信息对应到字段里,并将其返回给管道pipelines.py文件。
def get_detail(self,response):
#获取电影简介信息
item=DoubanItem()
description=response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0].strip()
item['description']=description
yield item
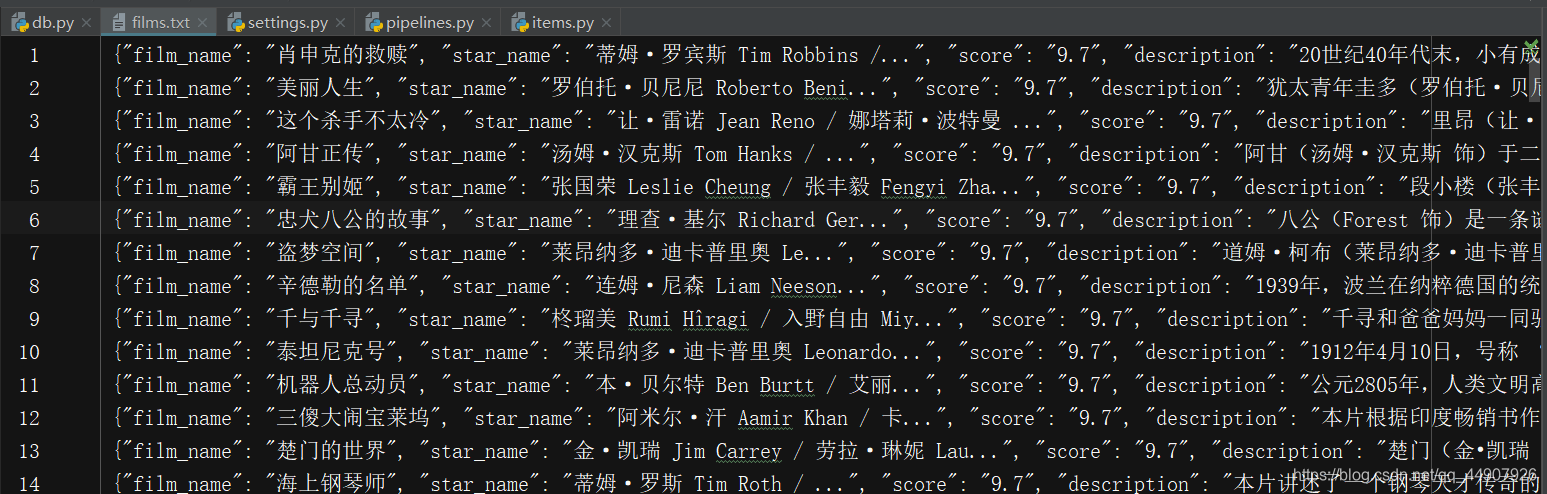
设置爬取首页25个电影的信息,运行爬虫之后,观察所获取到的数据:
 会发现,电影信息和其简介信息非但没有放在一起,而且更严重的是,由于scrapy框架采取的是异步方式,所以底下得到的这25个电影的简介信息也是毫无顺序的。这就很头疼了!
会发现,电影信息和其简介信息非但没有放在一起,而且更严重的是,由于scrapy框架采取的是异步方式,所以底下得到的这25个电影的简介信息也是毫无顺序的。这就很头疼了!
②习惯性思维不行,Scrapy框架设计者肯定也考虑到这种问题了—引入meta参数解决,如下:
注意:这个参数贼牛。那咱如何来理解这个参数的作用:
- 在爬虫文件将包含电影简介信息的url请求发送给引擎的同时,会把meta里的参数也携带着;
- 在引擎处理完这个url请求之后会将处理后的response返回给爬虫文件中我们指定的callback=self.get_detail函数里的response参数,并且同时会携带着这个meta参数。
牛皮之处可见一斑,这不就是变相的将电影基本信息数据和电影简介信息给拼接到了一起了!!!
#修改爬虫文件里的parse函数中对应的代码:
yield scrapy.Request(detail_url,callback=self.get_detail,meta={"info":item})
修改爬虫文件中的解析电影简介信息的函数get_detail()
def get_detail(self,response):
item=DoubanItem()
#获取电影简介信息
#1.meta会跟随response一块返回 2.可以通过response.meta接收 3.通过updata可以添加到新的item对象
info = response.meta["info"] #接收电影的基本信息
item.update(info) #把电影基本信息的字段加进去
#将电影简介信息加入相应的字段里
description=response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0].strip()
item['description']=description
yield item
1.3 会发现可以很完美的搞到我们所想要的数据: