数据挖掘,计算机网络、操作系统刷题笔记37
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记37
- @[TOC](文章目录)
- 数据挖掘
- 可视化直方图
- 可视化分析:箱线图
- 折线图
- 饼图:seaborn没有,只有matplotlib才有
- 以下 TCP 原语,中,哪一个是属于客户端的:
- 资源子网又被称为边缘网络,通信网络又被称为核心网络。
- 在曼切斯特编码中,从高到低跳变表示"1",从低到高跳变代表"0"
- RIP协议是基于( )UDP
- 为了减少路由记录需要把多部门的网络地址进行汇聚,166.100.32.0/22可以汇聚的网段有( )
- 列协议或应用,哪些是只使用TCP,而不使用UDP的?
- 在发送数据的过程中,在封装过程中,加入的地址信息是指( )。
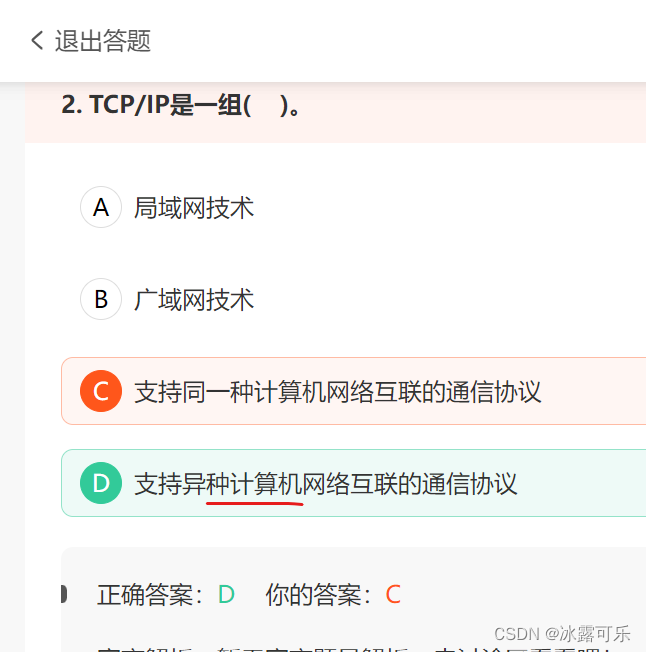
- TCP/IP是一组( )。
- 打开文件操作时的主要工作是 ()
- 以下关于进程死锁的表述,错误的是( )
- 中断可分为可屏蔽中断和不可屏蔽中断。
- 对换技术主要是为了提高内存的利用率。
- A 每按键一次,或鼠标点击一次,都产生一个中断,称为按键中断,执行中断响应程序,操作系统将按键消息加入消息队列
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记37
- @[TOC](文章目录)
- 数据挖掘
- 可视化直方图
- 可视化分析:箱线图
- 折线图
- 饼图:seaborn没有,只有matplotlib才有
- 以下 TCP 原语,中,哪一个是属于客户端的:
- 资源子网又被称为边缘网络,通信网络又被称为核心网络。
- 在曼切斯特编码中,从高到低跳变表示"1",从低到高跳变代表"0"
- RIP协议是基于( )UDP
- 为了减少路由记录需要把多部门的网络地址进行汇聚,166.100.32.0/22可以汇聚的网段有( )
- 列协议或应用,哪些是只使用TCP,而不使用UDP的?
- 在发送数据的过程中,在封装过程中,加入的地址信息是指( )。
- TCP/IP是一组( )。
- 打开文件操作时的主要工作是 ()
- 以下关于进程死锁的表述,错误的是( )
- 中断可分为可屏蔽中断和不可屏蔽中断。
- 对换技术主要是为了提高内存的利用率。
- A 每按键一次,或鼠标点击一次,都产生一个中断,称为按键中断,执行中断响应程序,操作系统将按键消息加入消息队列
- 总结
数据挖掘
可视化直方图
def f3():
df = pd.read_csv('HR_comma_sep.csv')
# 直方图
f = plt.figure() # 建立图的句柄
f.add_subplot(1, 3, 1)
sb.distplot(df['satisfaction_level'], bins=10) # 给画直方图
plt.show()
if __name__ == '__main__':
f3()
这个产生的是归一化的分布图
内涵直方图
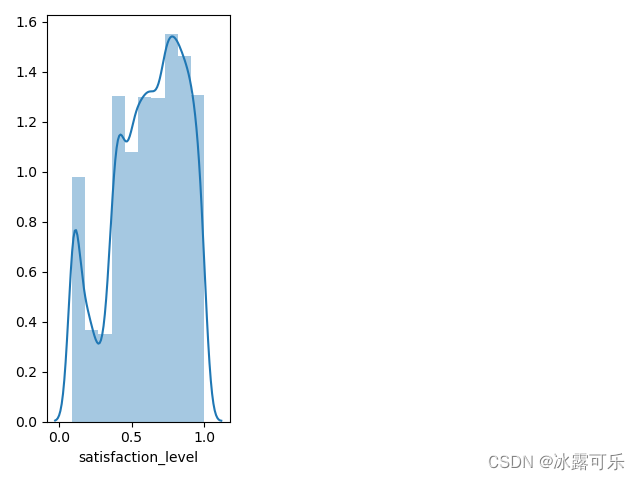
单独看直方图,那就去掉分布
kde
sb.distplot(df['satisfaction_level'], bins=10, kde=False) # 给画直方图
plt.show()
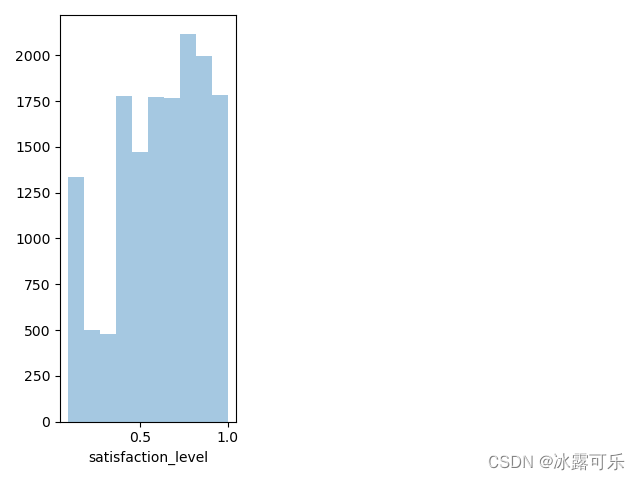
这样的话,就直接看统计分布,不同数据的个数
单独看直方图的分布,那就去掉直方图,
hist
sb.distplot(df['satisfaction_level'], bins=10, hist=False) # 给画直方图
plt.show()
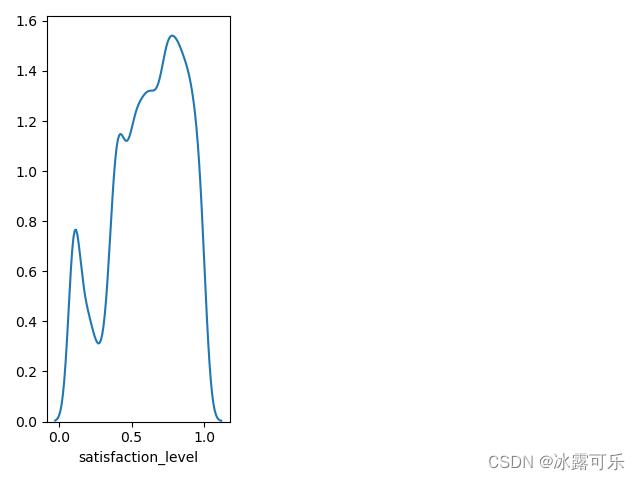
这样就没有直方图了
美滋滋
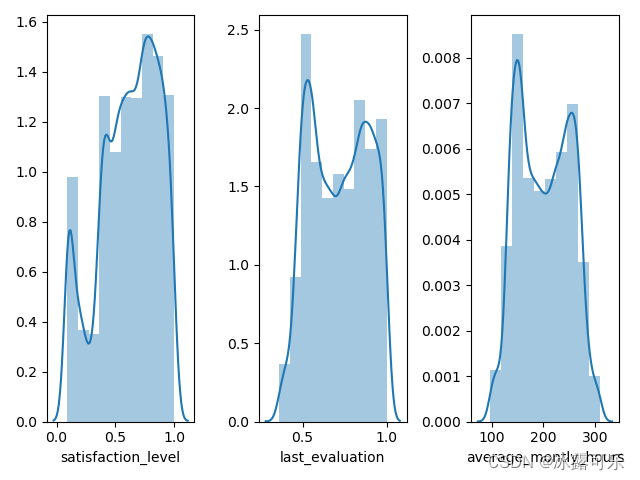
再加俩子图,我们可以看看别的字段直方图
def f3():
df = pd.read_csv('HR_comma_sep.csv')
# 直方图
f = plt.figure() # 建立图的句柄
f.add_subplot(1, 3, 1)
sb.distplot(df['satisfaction_level'], bins=10) # 给画直方图
# sb.distplot(df['satisfaction_level'], bins=10, kde=False) # 给画直方图
# sb.distplot(df['satisfaction_level'], bins=10, hist=False) # 给画直方图
# 加一个子图
f.add_subplot(1, 3, 2) # 1*3张图 绘制第二个图
sb.distplot(df['last_evaluation'], bins=10)
# 加一个子图
f.add_subplot(1, 3, 3) # 1*3张图 绘制第3个图
sb.distplot(df['average_montly_hours'], bins=10)
plt.show()
if __name__ == '__main__':
f3()
可视化分析:箱线图
def f4():
df = pd.read_csv('HR_comma_sep.csv')
# box plot
sb.boxplot(y=df['time_spend_company'])
plt.show()
if __name__ == '__main__':
f4()
箱线图就是看上下四分位数极其上下界
还有异常值和离群点
你看看下面上四分位数和下四分位数是4,3
而上下界是5.几
下界是2.多
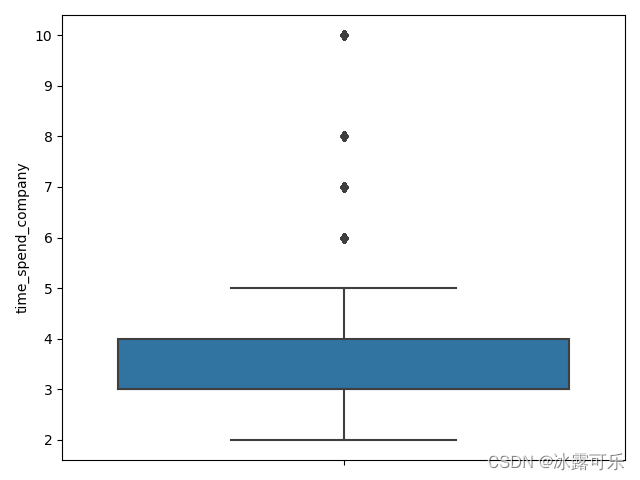
而有几个6,7,8,10
为离群点
去官网看
seaborn的api里面的boxplot
里面的参数
saturation float, optional
Proportion of the original saturation to draw colors at. Large patches often look better with slightly desaturated colors, but set this to 1 if you want the plot colors to perfectly match the input color.
这saturation就是方框的边界,上下四分位数构成的方框的上边界
一般默认是0.75
whis就是上下分位数计算方法的那个k
上一个文章我说过哦
xy是看看你要把坐标放在y轴,还是x轴
def boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,
orient=None, color=None, palette=None, saturation=.75,
width=.8, dodge=True, fliersize=5, linewidth=None,
whis=1.5, ax=None, **kwargs):
sb.boxplot(x=df['time_spend_company'], saturation=0.75, whis=3) #默认值你可以去看看
plt.show()
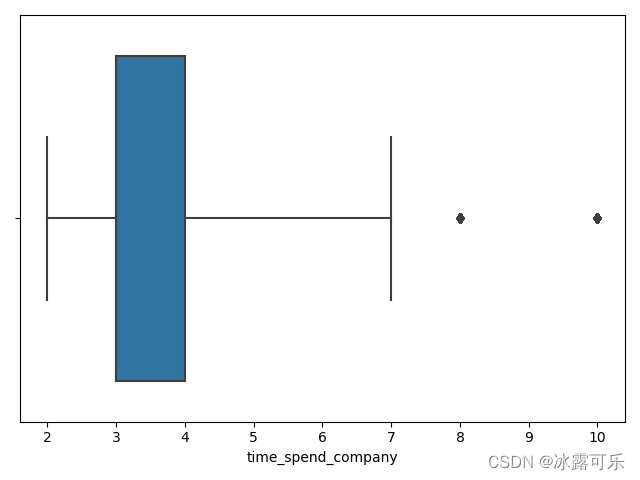
这就是箱线图
折线图
好说
def f5():
df = pd.read_csv('HR_comma_sep.csv')
# line plot
subdf = df.groupby(['time_spend_company']).mean() # 分组求平均
# 这个表的话,就是按照时长来分组了,其他数据平均
# 然后咱们时长做横坐标,然后打印离职率
sb.pointplot(subdf.index, subdf['left']) # 只看subdf了
plt.show()
if __name__ == '__main__':
f5()
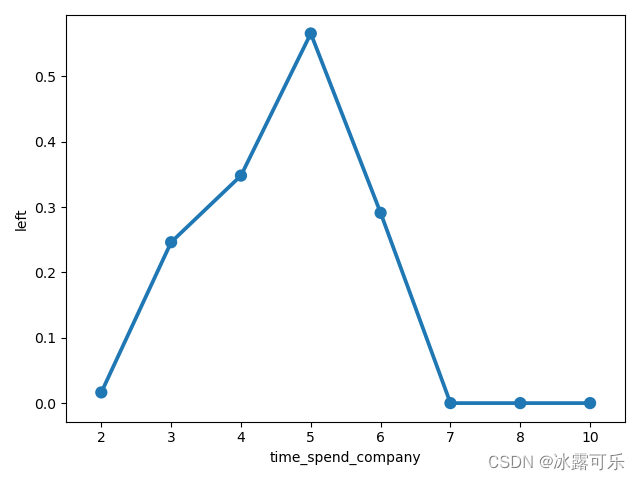
根据这个时长分分组后
平均离职的率就有一个综合的感官
大概5年是一个坎
5年时大家都离职了
越往后走很难再有人说离职
34年后离职的人也不少
还能这样玩
sb.pointplot(x=df['time_spend_company'], y=df['left'], data=df)
# 根据这个表,横坐标是时长,纵坐标是平均离职率,用的data是df
# 这样它才会去给你计算分组均值
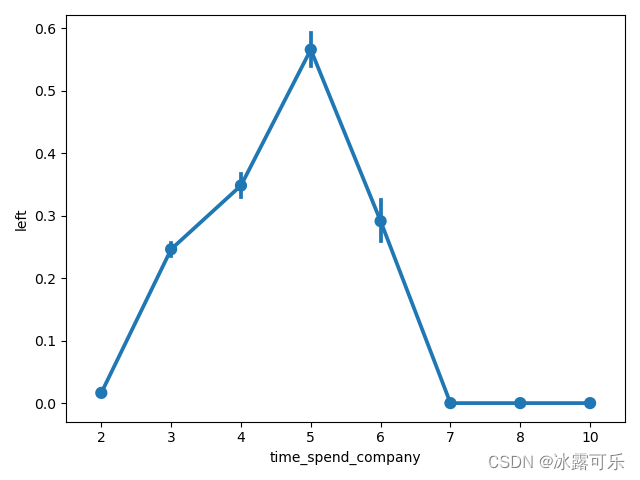
这样得到的这个数据表它还有范围呢
饼图:seaborn没有,只有matplotlib才有
def f6():
df = pd.read_csv('HR_comma_sep.csv')
# pie plot
lbs = df['department'].value_counts().index # 这个index就是不同部门,做label
# autopct是指定pie的百分号格式,一般取%1.1f%%
plt.pie(df['department'].value_counts(normalize=True), labels=lbs, autopct="%1.1f%%")
# 统计department的个数,然后将其归一化,放入饼图
plt.show()
if __name__ == '__main__':
f6()
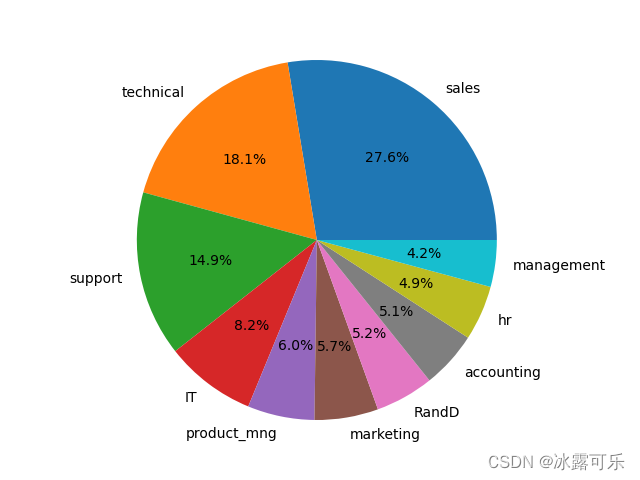
帅不帅
你可以拿着label去遍历,看看需不需要着重强调拿个标签的饼
def f6():
df = pd.read_csv('HR_comma_sep.csv')
# pie plot
lbs = df['department'].value_counts().index # 这个index就是不同部门,做label
# autopct是指定pie的百分号格式,一般取%1.1f%%
# plt.pie(df['department'].value_counts(normalize=True), labels=lbs, autopct="%1.1f%%")
# 统计department的个数,然后将其归一化,放入饼图
# 需要强调哪个部门?
expld = [0.1 if i=='sales' else 0 for i in lbs] # 间距
plt.pie(df['department'].value_counts(normalize=True), explode=expld, labels=lbs, autopct="%1.1f%%")
plt.show()
if __name__ == '__main__':
f6()
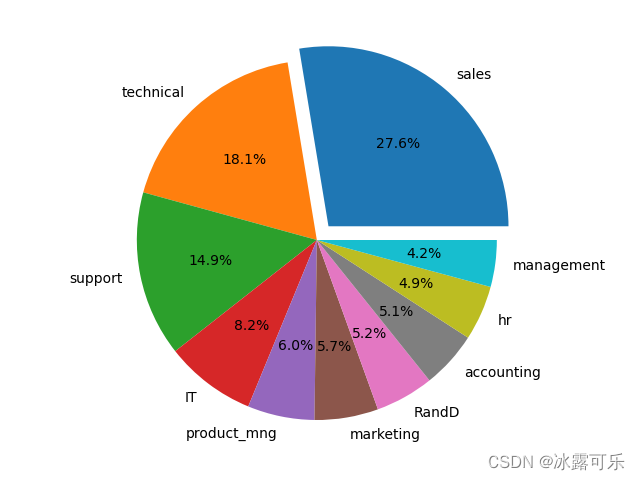
怎么样,逼格够不够,效果好不好
美滋滋吧
其他的,你也可以看
小结一波:
图表的种类好多呢
反正可以死去官网查一波就行
探索性数据分析的这些工作,我们就到此为止了
你不光要看看数据,还要看数据的对比,能起到啥含义
然后才能得出你想要的更合理的决策
以下 TCP 原语,中,哪一个是属于客户端的:
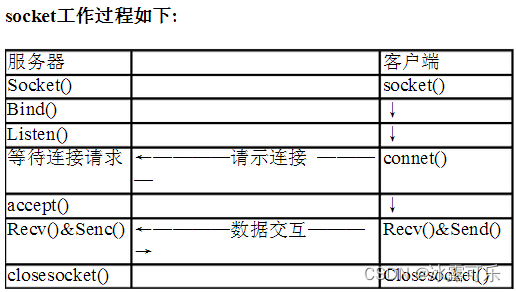
客户端要做的就是connect
其他都是服务器在监听,接受
资源子网又被称为边缘网络,通信网络又被称为核心网络。
A是资源子网,BCD是通信子网。
在曼切斯特编码中,从高到低跳变表示"1",从低到高跳变代表"0"

RIP协议是基于( )UDP
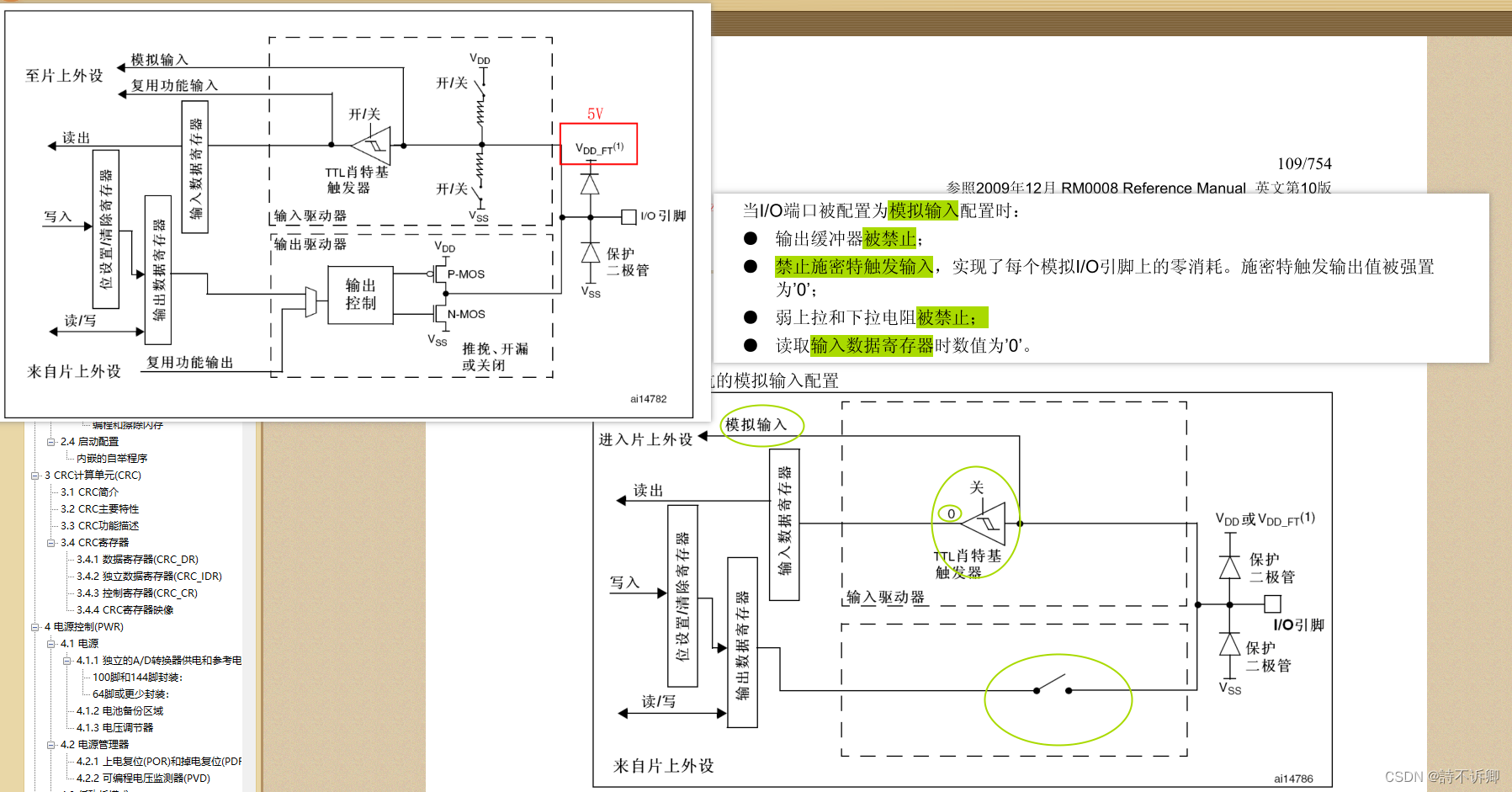
RIP协议是一种内部网关协议(IGP),是一种动态路由选择协议,用于自治系统(AS)内的路由信息的传递。RIP协议基于距离矢量算法(DistanceVectorAlgorithms),使用“跳数”(即metric)来衡量到达目标地址的路由距离。 RIP协议采用距离向量算法,在实际使用中已经较少适用。在默认情况下,RIP使用一种非常简单的度量制度:距离就是通往目的站点所需经过的链路数,取值为1~15,数值16表示无穷大。RIP进程使用UDP的520端口来发送和接收RIP分组。RIP分组每隔30s以广播的形式发送一次,为了防止出现“广播风暴”,其后续的的分组将做随机延时后发送。在RIP中,如果一个路由在180s内未被刷,则相应的距离就被设定成无穷大,并从路由表中删除该表项。RIP分组分为两种:请求分组和响应分组。
你妈,不是多选吗
操
为了减少路由记录需要把多部门的网络地址进行汇聚,166.100.32.0/22可以汇聚的网段有( )
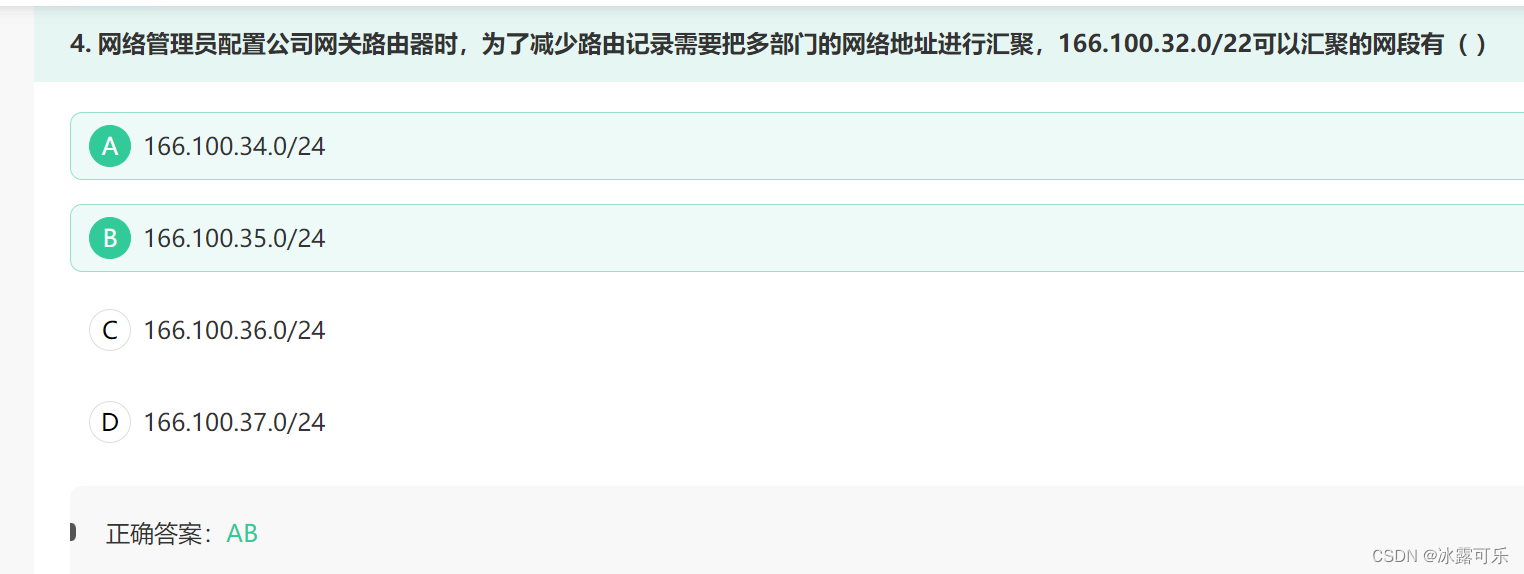
22位之前是001000
后面的可以是00
01
10
11
这样就是32+1,2,3
其余的都不行

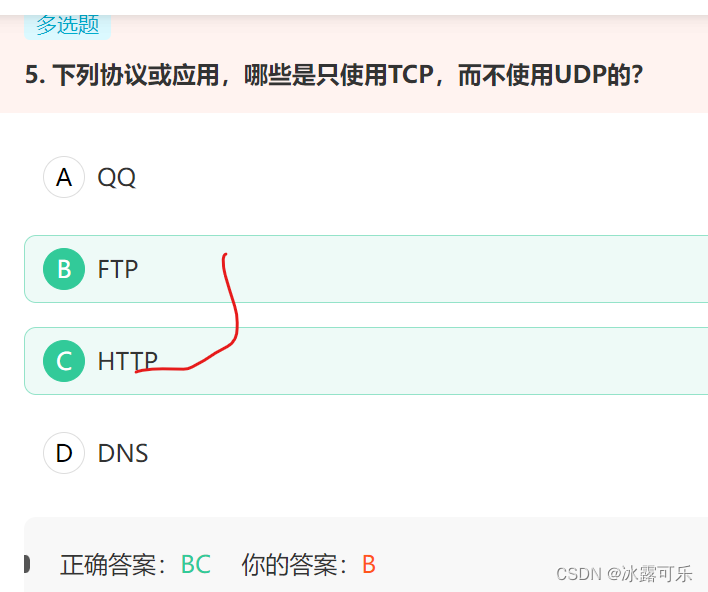
列协议或应用,哪些是只使用TCP,而不使用UDP的?
链接:https://www.nowcoder.com/questionTerminal/68ac10200a024c29b544e6788d23a199
来源:牛客网
使用UDP的服务:
DNS(域名解析)
TFTP(简单文件传送协议)
RIP(路由信息协议)
DHCP(动态主机配置协议)
SNMP(简单网络管理协议)
NFS(网络文件系统)
IP电话
流式多媒体通信
IGMP(网际组管理协议)
使用TCP的协议或应用:
SMTP
TELNET(远程终端协议)
HTTP
FTP
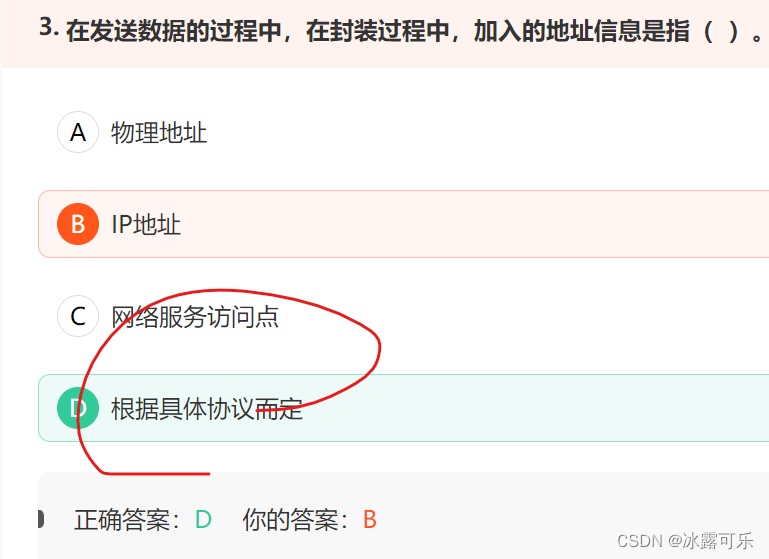
在发送数据的过程中,在封装过程中,加入的地址信息是指( )。
链接:https://www.nowcoder.com/questionTerminal/a17096dbe85c409ca1d2f14a39eca859
来源:牛客网
服务访问点就是邻层实体之间的逻辑接口。
从物理层开始,每一层都向上层提供服务访问点。
在连接因特网的普通微机上,
物理层的服务访问点就是网卡接口,
数据链路层的服务访问点是MAC地址,
网络层的服务访问点是IP地址,
传输层的服务访问点是端口号,
应用层提供的服务访问点是用户界面。
TCP/IP是一组( )。
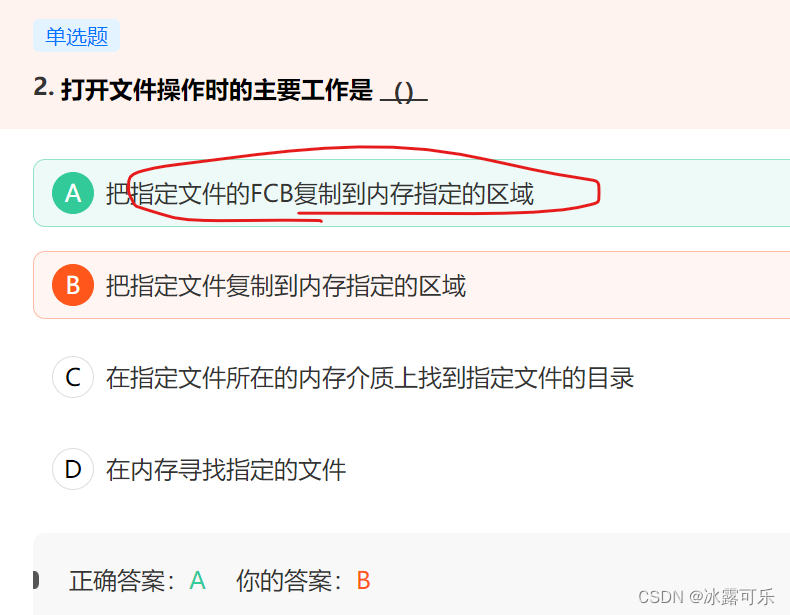
打开文件操作时的主要工作是 ()
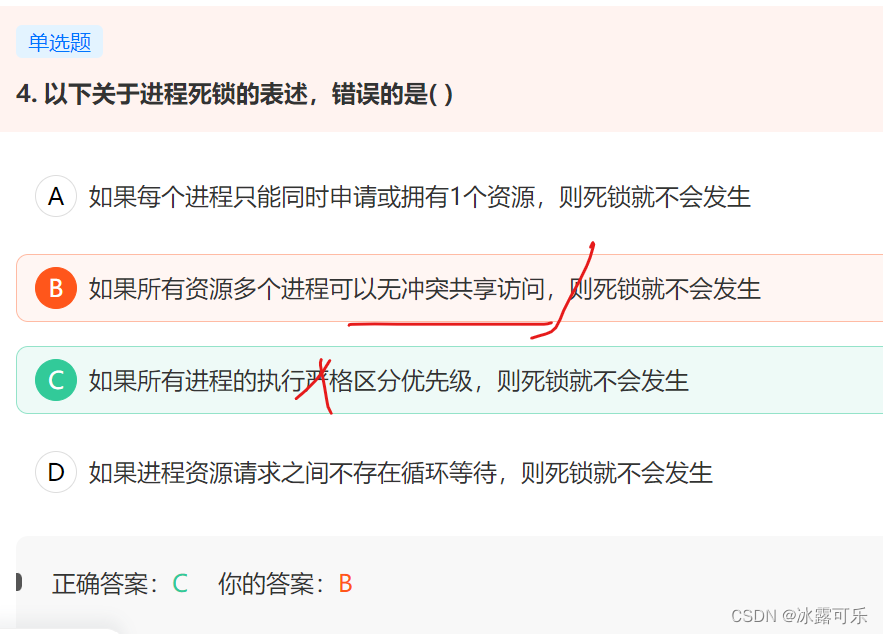
以下关于进程死锁的表述,错误的是( )
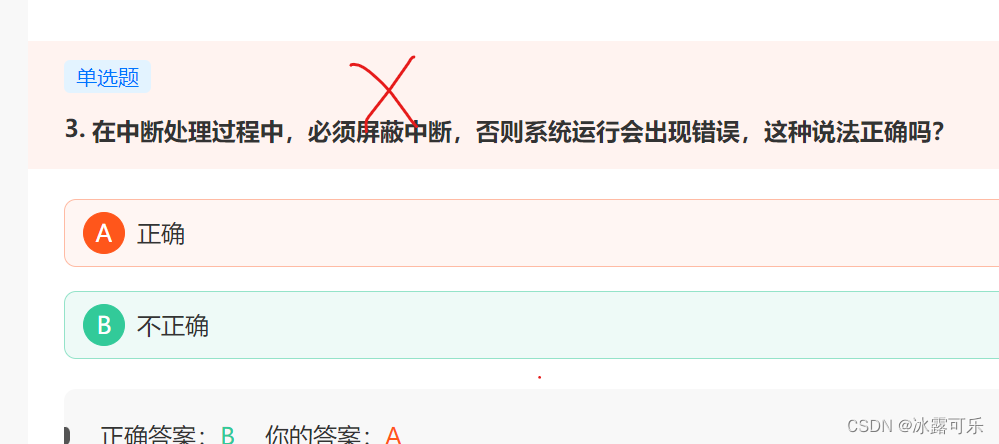
中断可分为可屏蔽中断和不可屏蔽中断。
可屏蔽中断 :可被CPU通过指令限制某些设备发出中断请求的中断
不可屏蔽中断:不允许屏蔽的中断如电源掉电
对换技术主要是为了提高内存的利用率。
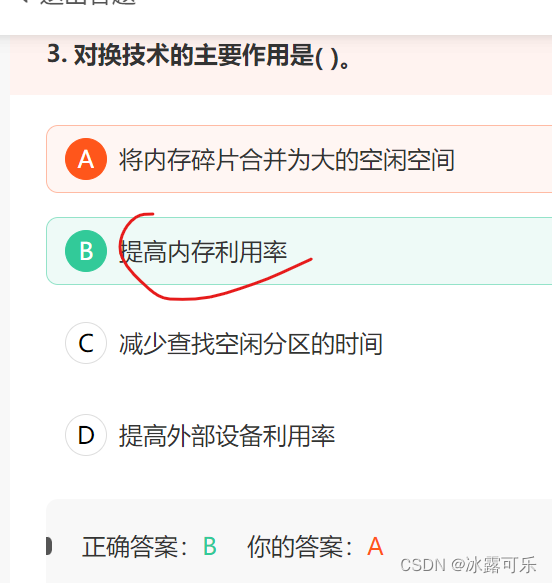
对换分为整体对换和页面对换。它时把内存中暂时不能运行的进程或暂时不用的程序或数据,调出到外存上,以便腾出足够的内存空间,再把具备运行条件的进程或进程所需要的程序和数据调入内存。所以对换技术主要是为了提高内存的利用率。
A 每按键一次,或鼠标点击一次,都产生一个中断,称为按键中断,执行中断响应程序,操作系统将按键消息加入消息队列
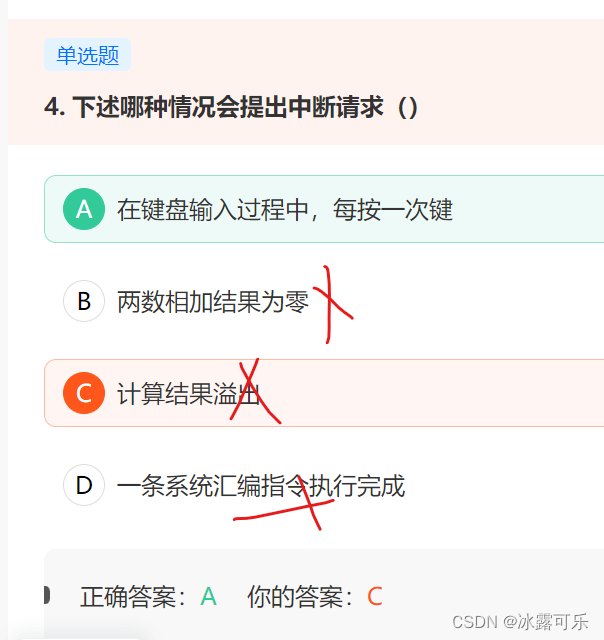
C. 应该属于运算结果溢出那就是内中断也就是异常(感觉是玩文字游戏,这里可能认为中断请求只能是外中断)
狗逼
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。