主题建模:基于 LDA 实现
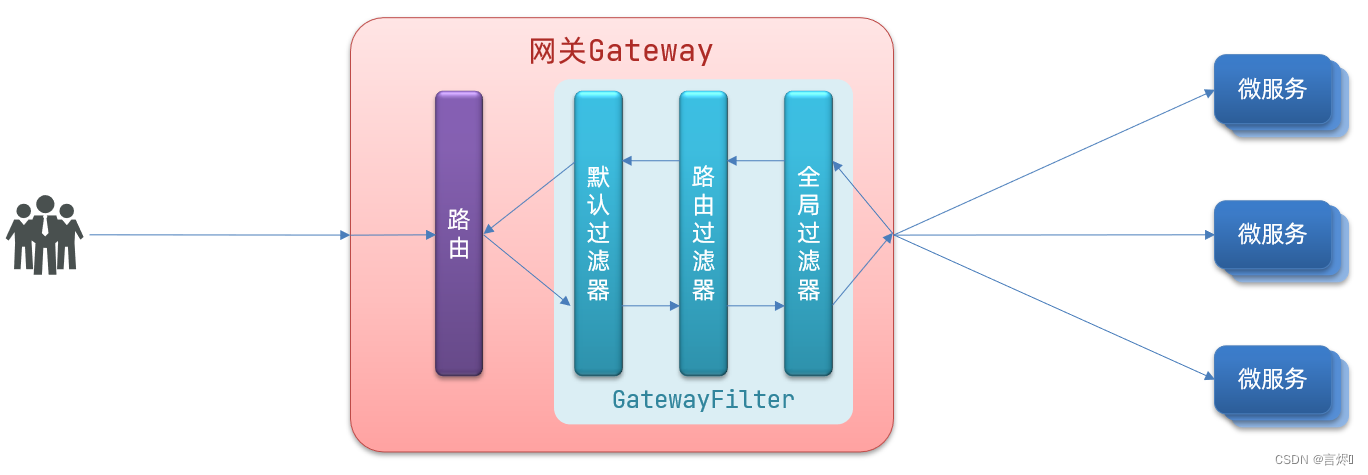
主题建模是一种常见的自然语言处理任务。隐含的狄利克雷分布(Latent Dirichlet Allocation,LDA)是其中一种实现算法,其核心思想如下图所示。

主题建模的方法也比较多,除了本文提到的 LDA,还有 LSA、pLSA、NMF、BERTopic、Top2Vec 等。后续我会针对这几种主题建模方法出一篇博客,进行一个详细的对比。
本文代码已上传至 我的GitHub,需要可自行下载。
1.数据准备
import warnings
warnings.filterwarnings('ignore')
import sys
sys.path.append("..") # Adds higher directory to python modules path.
from NLPmoviereviews.data import load_data_sent
X_train, y_train, X_test, y_test = load_data_sent(percentage_of_sentences=10)
import pandas as pd
data = pd.DataFrame(X_train)
data.columns = ['text']
data.head()

data.shape

2.数据预处理
from NLPmoviereviews.utilities import preprocessing
data['clean_text'] = data.text.apply(preprocessing)
data

preprocessing 的具体实现如下,还是利用了 NLTK 提供的内置方法。
import string
from nltk.corpus import stopwords
from nltk import word_tokenize
from nltk.stem import WordNetLemmatizer
def preprocessing(sentence):
"""
Use NLTK to clean text: remove numbers, stop words, and lemmatize verbs and nouns
"""
# Basic cleaning
sentence = sentence.strip() # remove whitespaces
sentence = sentence.lower() # lowercasing
sentence = ''.join(char for char in sentence if not char.isdigit()) # removing numbers
# Advanced cleaning
for punctuation in string.punctuation:
sentence = sentence.replace(punctuation, '') # removing punctuation
tokenized_sentence = word_tokenize(sentence) # tokenizing
stop_words = set(stopwords.words('english')) # defining stopwords
tokenized_sentence_cleaned = [w for w in tokenized_sentence
if not w in stop_words] # remove stopwords
# 1 - Lemmatizing the verbs
verb_lemmatized = [WordNetLemmatizer().lemmatize(word, pos = "v") # v --> verbs
for word in tokenized_sentence_cleaned]
# 2 - Lemmatizing the nouns
noun_lemmatized = [WordNetLemmatizer().lemmatize(word, pos = "n") # n --> nouns
for word in verb_lemmatized]
cleaned_sentence = ' '.join(w for w in noun_lemmatized)
return cleaned_sentence
3.LDA 建模
一般的主题建模实现会用 Gensim,其提供了多种建模方法。但本文利用 sklearn.decomposition 提供的 LatentDirichletAllocation 实现 LDA。
首先利用 TfidfVectorizer 对文本进行向量化表示。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
vectorizer = TfidfVectorizer()
vectorized_text = vectorizer.fit_transform(data.clean_text) # 等价于先 fit 后 transform, 返回文档-词语矩阵
vectorized_text = pd.DataFrame(vectorized_text.toarray(), columns=vectorizer.get_feature_names())
vectorized_text
vectorized_text 对应的是前文图中的 文档 - 词语 矩阵。

初始化 LDA 模型。因为是非监督模型,所以要事先指定聚类数目(n_components)。
# Instantiating the LDA
n_components = 5
lda_model = LatentDirichletAllocation(n_components=n_components, max_iter = 100)
text_topics = lda_model.fit_transform(vectorized_text)
pd.DataFrame(text_topics)
text_topics 对应前文图中的 文档 - 主题 矩阵。

topic_mixture = pd.DataFrame(lda_model.components_, columns = vectorizer.get_feature_names())
topic_mixture
topic_mixture 对应前文图中的 主题 - 词语 矩阵。

def print_topics(model, vectorizer):
topic_mixture = pd.DataFrame(lda_model.components_, columns = vectorizer.get_feature_names())
for idx, topic in enumerate(model.components_):
print("Topic %d:" % (idx))
topic_df = topic_mixture.iloc[idx].sort_values(ascending = False).head(3)
print(round(topic_df,3))
print("-"*25)
print(print_topics(lda_model,vectorizer))
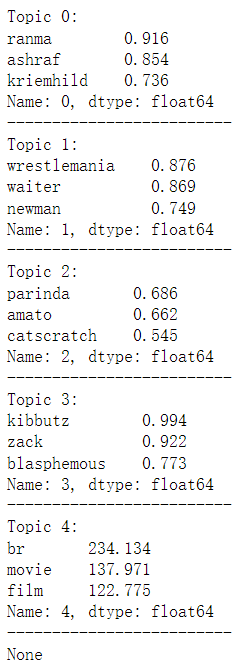
4.预测
example = ["My team performed poorly last season. Their best player was out injured and only played one game"]
clean_example = preprocessing(example[0])
vectorized_example = vectorizer.transform([clean_example])
lda_model.transform(vectorized_example) # 根据拟合模型转换数据 X
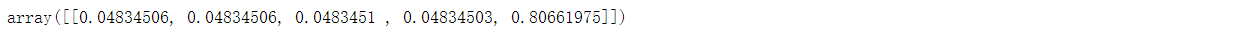
可以看到,新文本应该是属于 Topic 4。