每一个不曾起舞的日子都是对生命的辜负

模板进阶
- 模板进阶
- 一. 非类型模板参数
- 1.1 引出场景
- 1.2 非类型模板参数
- 1.3 其他例子
- 二.array类
- 2.1 array类的介绍
- 2.2 array的价值
- 三.模板的特化
- 3.1 概念
- 3.2 函数模板的特化
- 3.3 类模板的特化
- 3.3.1 全特化
- 3.3.2 偏特化
- 四.模板分离编译
- 4.1 什么是分离编译
- 4.2 模板的分离编译
- 4.3 解决方法
- 五.模板总结
模板进阶
一. 非类型模板参数
1.1 引出场景
在一个有静态数组为成员变量的类中,我们用模板泛型化:
#define N 10
template<class T>
class Array
{
private:
T _a[N];
};
那当利用Array类的时候会是这样:
int main()
{
Array<int> a1;
Array<double> a2;
return 0;
}
这两段代码合在一起是毫无问题的,但如果我们新增一个需求,让对象a1的静态数组的大小为10,对象a2的静态数组大小为100,即使两个对象的静态数组的大小不同,这样的需求上面的的代码是无法实现的,此时,就需要非类型模板参数来完成这个要求。
1.2 非类型模板参数
- 模板参数分为类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。这就是之前我们所学的,参数为变量的类型,如:int、double、char等等。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。我们接下来就以这种方式解决上述遇到的问题。
在上面的场景中要求到,a1静态数组大小为10,a2静态数组大小为100,了解了非类型形参之后,就可以解决这个问题了:
//静态数组
//非类型模板参数 -- 常量:灵活赋值
template<class T, size_t N>
class Array
{
private:
T _a[N];
};
int main()
{
Array<int, 10> a;
Array<int, 100> a2;
return 0;
}
这样,就可以完成上述的要求,也就是非类型模板参数。顾名思义非类型的模板参数就是不是类型的参数,通过之前学习的内容,我们知道对于类型模板参数,通常是用class或者typename来修饰。
1.3 其他例子
对于这样的非类型模板参数,不仅仅类可以这样,函数也可以:
template<class T, size_t N>
void Func(const T& x)
{
cout << N << endl;
cout << x << endl;
}
int main()
{
Func<int, 100>(1);
return 0;
}

注意:
- 浮点数、类对象以及字符串是不允许作为非类型模板参数的。
- 非类型的模板参数必须在编译期就能确认结果。(即下面这样是不行的)

二.array类
既然上述提到了Array类的特征,那么就趁机了解一下内部类的array,这个标题和模板没有关系。
2.1 array类的介绍
array的文档说明
头文件当然是:#include<array>
与vector、list类似,都属于内部类,而上述我们自己写的Array类就是这个类的简化,只不过只有成员变量而没有别的东西。array对标的也不是vector,而是C语言中的静态数组例如array<int, 20> a 对标int a[N],他们的数据都在栈上,只是前者是自定义类型,后者是内置类型
通过查看文档,发现array不支持插入,但有运算符重载:operator[],因此就可以直接通过下标进行访问。
2.2 array的价值
既然有了array替代静态数组,那么它的优势是什么?最主要的不是封装,而是对于越界的检查。之前学过C语言,对于一个普通内置类型的数组,一旦发生越界访问,就会有这么两种情况:
- 越界读,不检查
- 越界写,抽查
顾名思义,C语言学习的过程中,数组越界是一个很敏感并且容易出错的问题,越界了的数组可能会发生意想不到的错误,比如产生随机值造成数据失效等等。那我们就来看看C语言中上述的这两种情况的现象:
第一种越界读的情况:
int main()
{
int a1[10];
cout << a1[10] << endl;//越界读
cout << a1[11] << endl;//越界读
return 0;
}
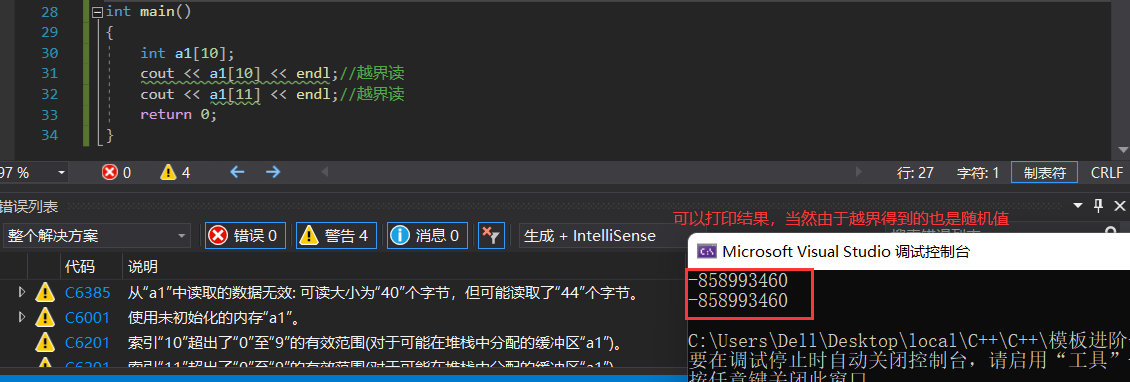
读的时候即便越界,由于不会检查,因此也不会报错。这就是正常的内置类型带来的弊端。
第二种越界写的情况:
int main()
{
int a1[10];
a1[10] = 0;//越界写
a1[15] = 0;//越界写
return 0;
}
越界写本身就是错误的。由于是抽查,因此不同平台的抽查的方式也不一样,查的时候一定报错,不查的时候可能只有警告。而对于vs2019来说,这两个是都能查到的。
由于内置类型对于越界检查的不严谨的行为,array就防止了上述越界的错误,即一旦越界无论读写都报错。
#include<iostream>
#include<array>
using namespace std;
int main()
{
//数组对于越界的检查:越界读不检查,越界写抽查。Array严格检查
//C++11的array
array<int, 10> a3;
cout << a3[11] << endl;//报错
a3[15] = 0;//报错
return 0;
}
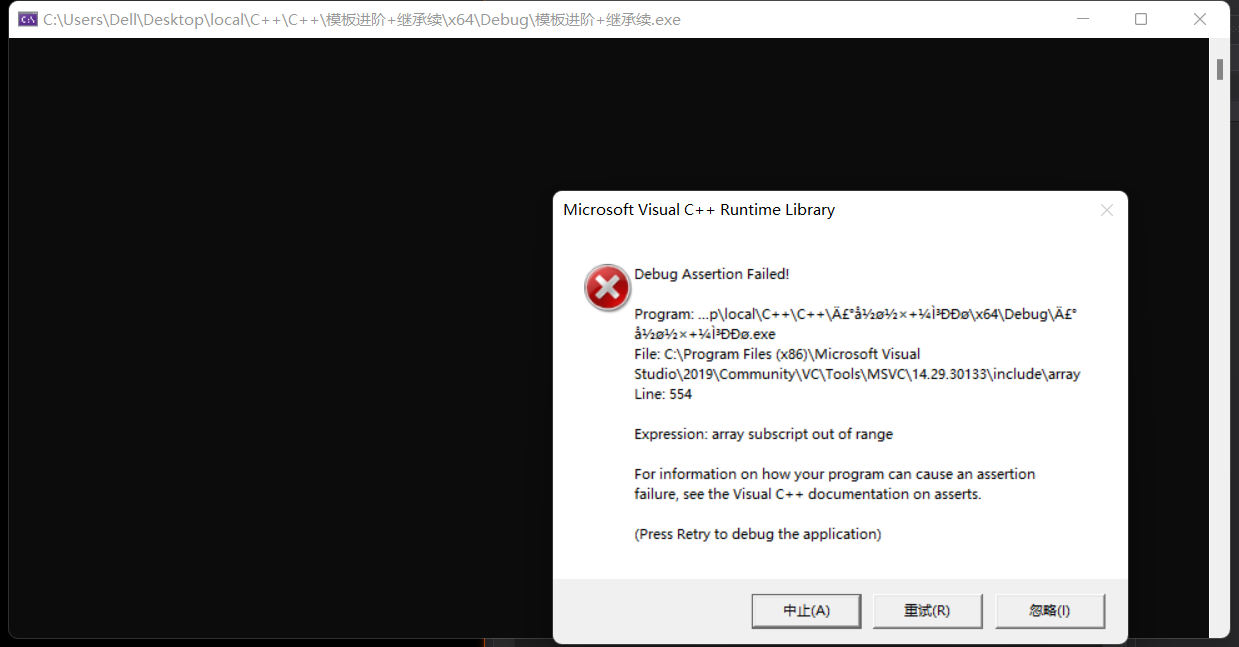
通过这个现象可以看出array越界检查的底层,就是在读和写时有assert判断是否越界。
三.模板的特化
3.1 概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板。(和函数重载一个道理)
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
friend ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
private:
int _year;
int _month;
int _day;
};
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
}
可以看到,Less绝对多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。
此时,就需要对模板进行特化。即:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。模板特化中分为函数模板特化与类模板特化。
3.2 函数模板的特化
为了解决上面Date*比较的问题,就需要将Date*的模板进行特化,即正如模板的性质:优先找到匹配的进行转换。
函数模板的特化步骤:
- 必须要先有一个基础的函数模板
- 关键字template后面接一对空的尖括号<>
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型
- 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
friend ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
private:
int _year;
int _month;
int _day;
};
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
//针对某些类型进行特殊处理
template<>
bool Less<Date*>(Date* left, Date* right)//这个就是模板的特化
{
return *left < *right;
}
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2022, 7, 7);
Date d2(2022, 7, 8);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
}
对于这种特化,并不是写了两个模板,仍是上一个模板的演化。实际上,这个特殊的Date*也不用刻意写成模板的特化,直接写成函数的重载也是对的,如:
那如果这两个同时使用,则会优先调用函数重载也就是这张图里的函数,因为模板需要进行匹配然后演化,重载则不需要,因此编译器会优先选择代价小的方式,我们可以验证一下: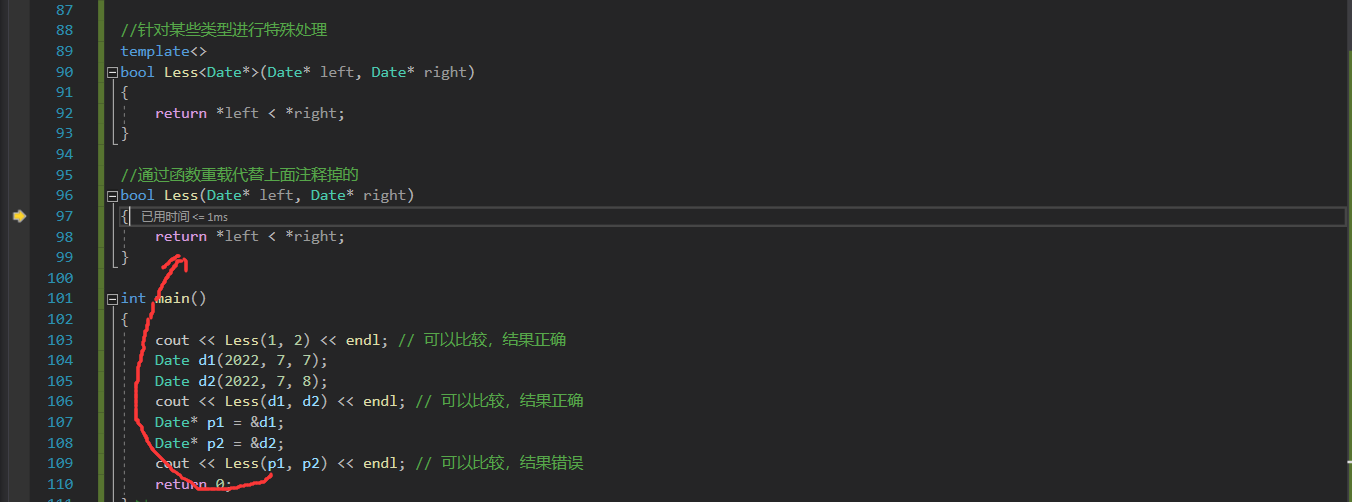
但这种函数重载的方式只对函数模板的特化有用,对于类模板是不可用的,因为类不像函数一样有重载的性质。
————————————————————————————————————————————————————————————
注意:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
bool Less(Date* left, Date* right)
{
return *left < *right;
}
该种实现简单明了,代码的可读性高,容易书写,因为对于一些参数类型复杂的函数模板,特化时特别给出,因此函数模板不建议特化,重载更好。
3.3 类模板的特化
和函数模板的特化的风格一样。
3.3.1 全特化
就是全部的参数进行特化。
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
template<>
class Data<int, char>
{
public:
Data() { cout << "Data<int, char>" << endl; }
private:
int _d1;
char _d2;
};
void TestVector()
{
Data<int, int> d1;
Data<int, char> d2;
}
int main()
{
TestVector();
return 0;
}
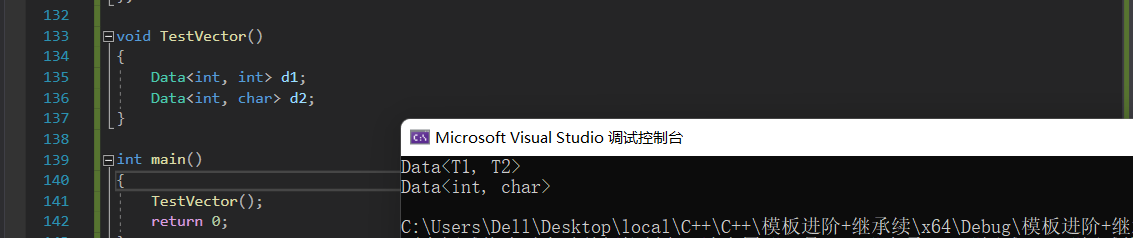
对于上一篇的
Date*的比较,我们采用了仿函数的方式,但学习了类模板的特化,同样可以采用这种方式代替仿函数:(但需要注意不产生冲突,不调用库中的greater,注意命名空间,否则特化不会被调用。(这里了解即可,主要还是知道类模板实例化的方式))增加特化:
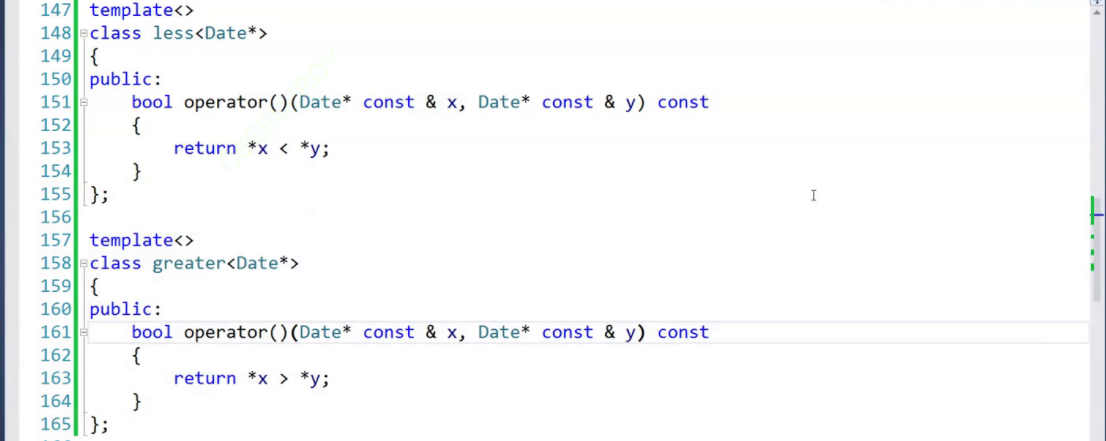
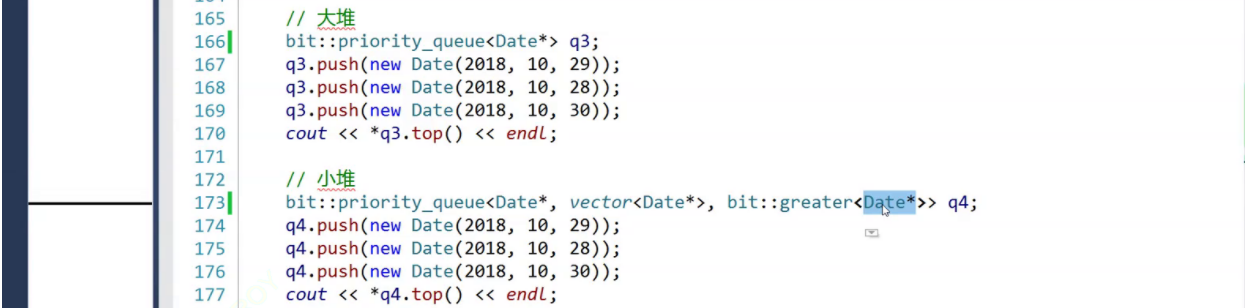
3.3.2 偏特化
只对部分参数进行特化。
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//半特化、偏特化
template<class T1>
class Data<T1, char>
{
public:
Data() { cout << "偏特化Data<T1, char>" << endl; }
private:
T1 _d1;
char _d2;
};
void TestVector()
{
Data<int, int> d1;
Data<int, char> d2;
}
int main()
{
TestVector();
return 0;
}
只要没有全特化,只要偏特化有对应的相同,结果就是优先调用偏特化。如果有全特化并且一一对应,一定优先调用全特化,因为会节省掉部分演化从而提高性能。
那为什么叫做偏特化呢,目的不是单纯的特化部分参数,而是对参数类型的进一步限制。
class Data<T1*, T2*>
{
public:
Data()
{
cout << "Data<T1*, T2*>" << endl;
}
};
这种方式也是对参数类型的进一步限制,因此这种方式也叫做偏特化。只要是指针类型,就会优先调用此特化的类。当然,除了指针还有引用,引用和指针如出一辙。
特化的本质体现的是编译器的匹配原则:有现成的用现成的,没有现成的用半成品,没有半成品再新造一个。
四.模板分离编译
4.1 什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
4.2 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
分析:
4.3 解决方法
- 将声明和定义放到一个文件 “xxx.hpp” 里面或者xxx.h其实也是可以的。推荐使用这种。
- 模板定义的位置显式实例化。这种方法不实用,不推荐使用。
【分离编译扩展阅读】 http://blog.csdn.net/pongba/article/details/19130
五.模板总结
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
- 增强了代码的灵活性
【缺陷】
- 模板会导致代码膨胀问题,也会导致编译时间变长
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误