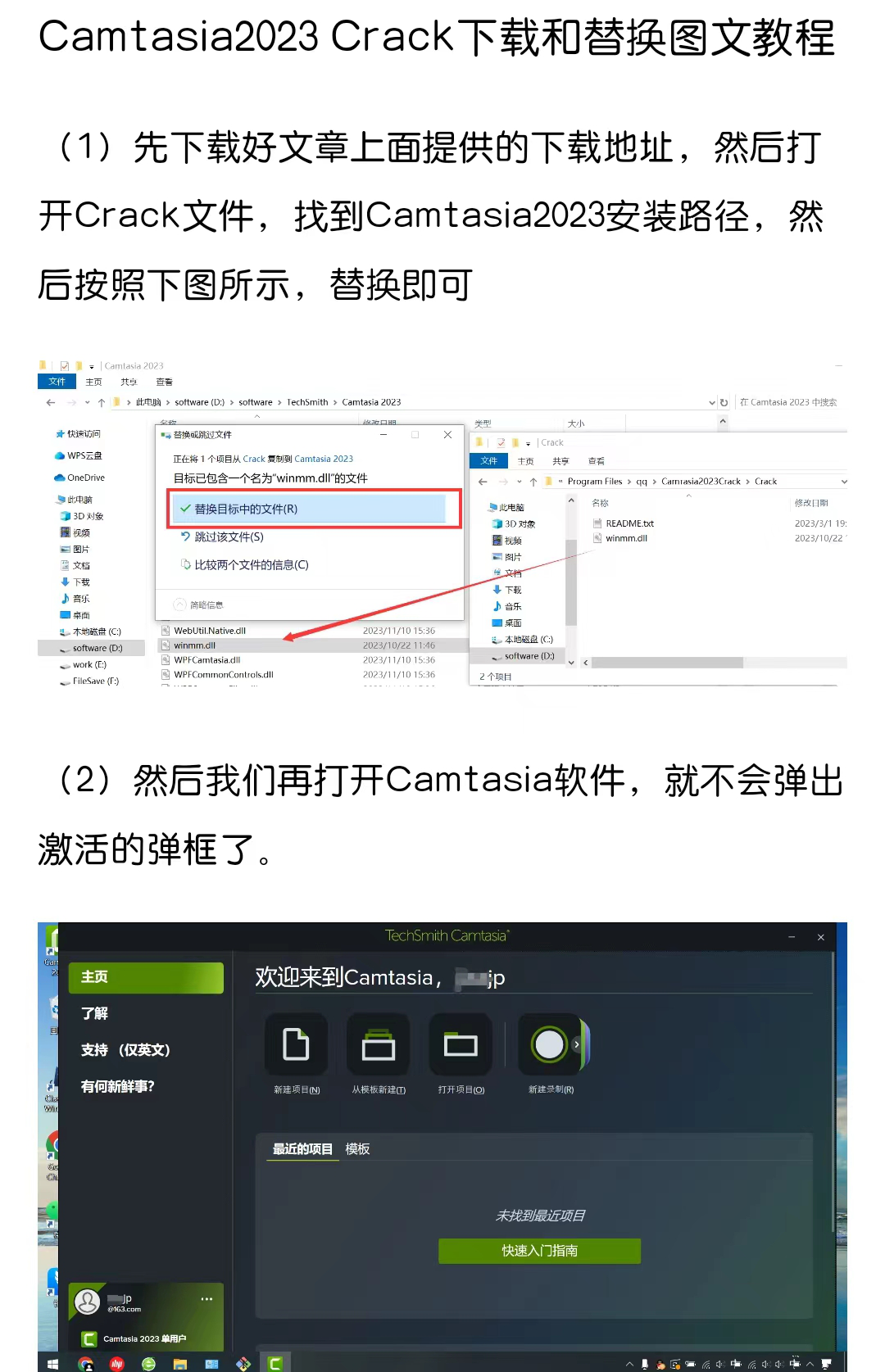
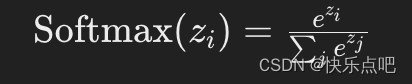引言
在人工智能模型的开发旅程中,选择正确的机器学习开发框架是一项至关重要的决策。历史上,众多库都曾竞相争夺“人工智能开发者首选框架”这一令人垂涎的称号。(你是否还记得 Caffe 和 Theano?)在过去的几年里,TensorFlow 以其对高效率、基于图的计算的重视,似乎已经成为了领头羊(这是根据作者对学术论文提及次数和社区支持力度的观察得出的结论)。而在近十年的转折点上,PyTorch 以其对用户友好的 Python 风格接口的强调,似乎已经稳坐了霸主之位。但是,近年来,一个新兴的竞争者迅速崛起,其受欢迎程度已经到了不容忽视的地步。JAX 以其对提升人工智能模型训练和推理性能的追求,同时不牺牲用户体验,正逐步向顶尖位置发起挑战。
在本文[1]中,我们将对这个新兴框架进行评估,展示其应用,并分享我们对其优势和不足的一些个人见解。虽然我们的焦点将集中在人工智能模型的训练上,但也应当注意,JAX 在人工智能/机器学习领域乃至更广的范围内都有着广泛的应用。目前,已有多个高级机器学习库基于 JAX 构建。在本文中,我们将使用 Flax,据本文撰写时的观察,它似乎是最受欢迎的选择。
JAX 幕后花絮 — XLA 编译
JAX 的强大之处在于它利用了 XLA 编译技术。JAX 所展现出的卓越运行性能,归功于 XLA 提供的硬件特定优化。而许多与 JAX 紧密相关的功能,比如即时编译(JIT)和“函数式编程”范式,实际上都是 XLA 的衍生物。实际上,XLA 编译并非 JAX 独有,TensorFlow 和 PyTorch 也都提供了使用 XLA 的选项。不过,与其它流行框架相比,JAX 从设计之初就全面拥抱了 XLA。这使得 JIT 编译、自动微分、向量化、并行化、分片处理以及其他特性与 XLA 库的底层设计和实现紧密相连,这些特性都值得我们高度尊重。
XLA JIT 编译器会对模型的计算图进行全面分析,将连续的张量操作合并为单一内核,剔除冗余的图组件,并生成最适合底层硬件加速器的机器代码。这不仅减少了每次训练步骤所需的总体机器级操作数,也降低了主机与加速器之间的通信开销,减少了内存占用,提高了专用加速器引擎的利用率。
除了运行时性能的优化,XLA 的另一个关键特性是其可扩展的基础设施,它允许扩展对更多 AI 加速器的支持。XLA 是 OpenXLA 项目的一部分,由 ML 领域的多个参与者共同开发。
依赖 XLA 也带来了一些局限性和潜在问题。特别是,许多 AI 模型,包括那些具有动态张量形状的模型,在 XLA 中可能无法达到最佳运行效果。需要特别注意避免图断裂和重新编译的问题。同时,你也应该考虑到这对你的代码调试可能带来的影响。
JAX 实际应用
在本节内容中,我们将展示如何在 JAX 环境下利用单个 GPU 来训练一个简单的人工智能模型,并对它与 PyTorch 的性能进行对比。目前,存在许多提供多种机器学习框架后端支持的高级机器学习开发平台,这使我们能够对 JAX 的性能进行横向比较。
本节中,我们将利用 HuggingFace 的 Transformers 库,该库为许多常见的基于 Transformer 架构的模型提供了 PyTorch 和 JAX 的实现版本。具体来说,我们将定义一个基于 Vision Transformer(ViT)的图像分类模型,分别使用 PyTorch 的 ViTForImageClassification 和 JAX 的 FlaxViTForImageClassification 模块来实现。
下面的代码示例展示了模型的定义过程。
import torch
import jax, flax, optax
import jax.numpy as jnp
def get_model(use_jax=False):
from transformers import ViTConfig
if use_jax:
from transformers import FlaxViTForImageClassification as ViTModel
else:
from transformers import ViTForImageClassification as ViTModel
vit_config = ViTConfig(
num_labels = 1000,
_attn_implementation = 'eager' # this disables flash attention
)
return ViTModel(vit_config)
请注意,我们决定不使用 "flash-attention" 功能,因为据我们所知,这项优化目前只适用于 PyTorch 模型(至少在本文撰写时是这样)。
鉴于本文关注的是运行时性能,我们选择在一个随机生成的数据集上训练我们的模型。我们利用了 JAX 支持 PyTorch 数据加载器的特性:
def get_data_loader(batch_size, use_jax=False):
from torch.utils.data import Dataset, DataLoader, default_collate
# create dataset of random image and label data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
if use_jax: # use nhwc
rand_image = torch.randn([224, 224, 3], dtype=torch.float32)
else: # use nchw
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
ds = FakeDataset()
if use_jax: # convert torch tensors to numpy arrays
def numpy_collate(batch):
from jax.tree_util import tree_map
import jax.numpy as jnp
return tree_map(jnp.asarray, default_collate(batch))
collate_fn = numpy_collate
else:
collate_fn = default_collate
ds = FakeDataset()
dl = DataLoader(ds, batch_size=batch_size,
collate_fn=collate_fn)
return dl
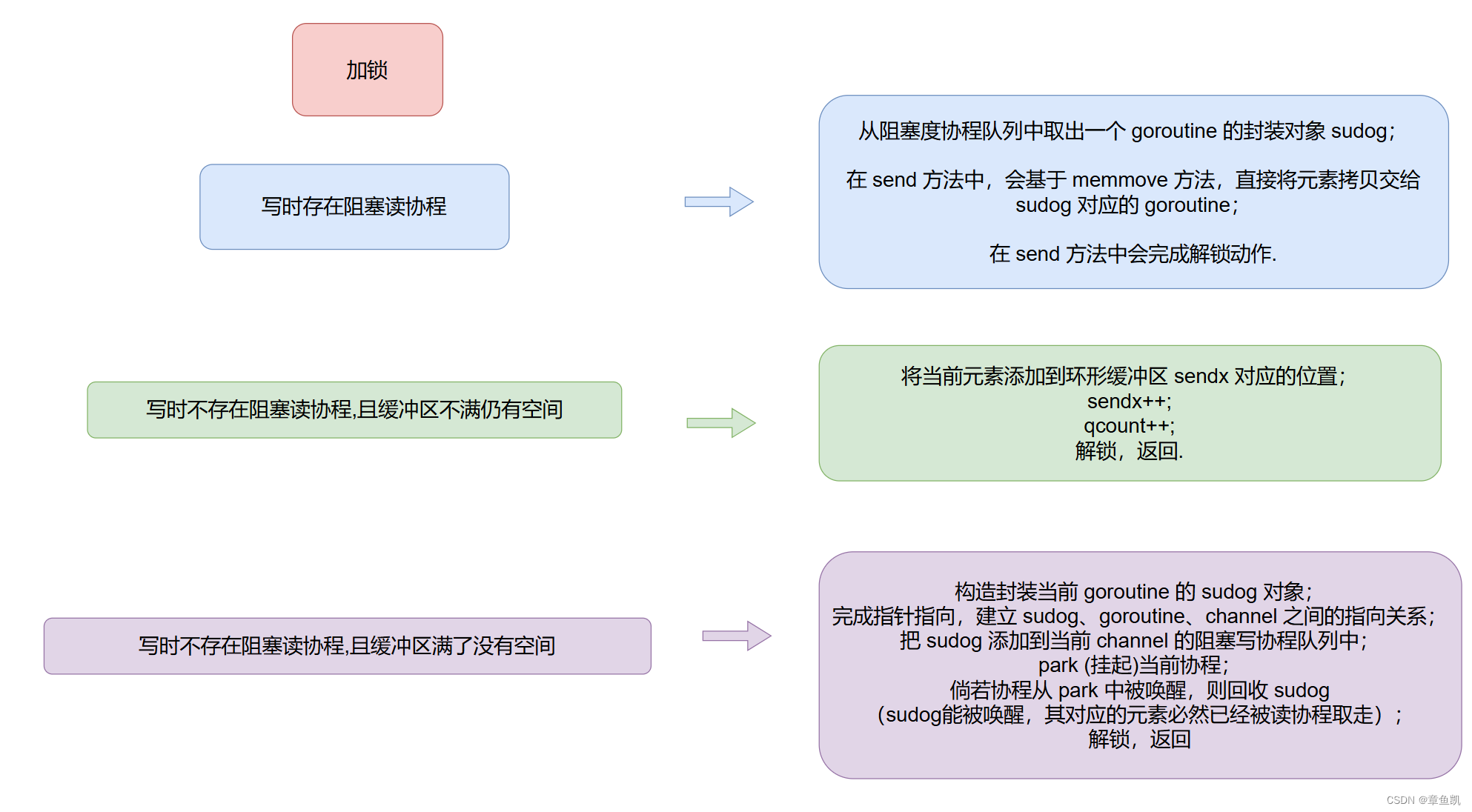
接下来,我们定义 PyTorch 和 JAX 训练循环。 JAX 训练循环依赖于 Flax TrainState 对象,其定义遵循在 Flax 中训练 ML 模型的基本教程:
@jax.jit
def train_step_jax(train_state, batch):
with jax.default_matmul_precision('tensorfloat32'):
def forward(params):
logits = train_state.apply_fn({'params': params}, batch[0])
loss = optax.softmax_cross_entropy(
logits=logits.logits, labels=batch[1]).mean()
return loss
grad_fn = jax.grad(forward)
grads = grad_fn(train_state.params)
train_state = train_state.apply_gradients(grads=grads)
return train_state
def train_step_torch(batch, model, optimizer, loss_fn, device):
inputs = batch[0].to(device=device, non_blocking=True)
label = batch[1].squeeze(-1).to(device=device, non_blocking=True)
outputs = model(inputs)
loss = loss_fn(outputs.logits, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
现在让我们把所有东西放在一起。在下面的脚本中,我们包含了使用 PyTorch 基于图形的 JIT 编译选项的控件,使用 torch.compile 和 torch_xla:
def train(batch_size, mode, compile_model):
print(f"Mode: {mode} \n"
f"Batch size: {batch_size} \n"
f"Compile model: {compile_model}")
# init model and data loader
use_jax = mode == 'jax'
use_torch_xla = mode == 'torch_xla'
model = get_model(use_jax)
train_loader = get_data_loader(batch_size, use_jax)
if use_jax:
# init jax settings
from flax.training import train_state
params = model.module.init(jax.random.key(0),
jnp.ones([1, 224, 224, 3]))['params']
optimizer = optax.sgd(learning_rate=1e-3)
state = train_state.TrainState.create(apply_fn=model.module.apply,
params=params, tx=optimizer)
else:
if use_torch_xla:
import torch_xla
import torch_xla.core.xla_model as xm
import torch_xla.distributed.parallel_loader as pl
torch_xla._XLAC._xla_set_use_full_mat_mul_precision(
use_full_mat_mul_precision=False)
device = xm.xla_device()
backend = 'openxla'
# wrap data loader
train_loader = pl.MpDeviceLoader(train_loader, device)
else:
device = torch.device('cuda')
backend = 'inductor'
model = model.to(device)
if compile_model:
model = torch.compile(model, backend=backend)
model.train()
optimizer = torch.optim.SGD(model.parameters())
loss_fn = torch.nn.CrossEntropyLoss()
import time
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
if use_jax:
state = train_step_jax(state, data)
else:
train_step_torch(data, model, optimizer, loss_fn, device)
# capture step time
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 50:
break
print(f'average step time: {summ / count}')
if __name__ == '__main__':
import argparse
torch.set_float32_matmul_precision('high')
parser = argparse.ArgumentParser(description='Toy Training Script.')
parser.add_argument('--batch-size', type=int, default=32,
help='input batch size for training (default: 2)')
parser.add_argument('--mode', choices=['pytorch', 'jax', 'torch_xla'],
default='jax',
help='choose training mode')
parser.add_argument('--compile-model', action='store_true', default=False,
help='whether to apply torch.compile to the model')
args = parser.parse_args()
train(**vars(args))
性能基准测试
在进行基准测试对比分析时,我们务必要非常谨慎和严格,仔细审视测试的执行方式。这一点在人工智能模型开发领域尤为重要,因为如果基于不准确的数据做出决策,可能会导致极其严重的后果。在评估训练模型的运行时性能时,有几个关键因素可能会极大地影响我们的测量结果,例如浮点数的精度、矩阵乘法的精度、数据加载方式,以及是否采用了 flash/fused 注意力机制等。举例来说,如果 PyTorch 默认的矩阵乘法精度是 float32,而 JAX 使用的是 tensorfloat32,那么单纯比较它们的性能可能不会给我们带来太多有价值的信息。这些精度设置可以通过相应的 API 进行调整,例如使用 jax.default_matmul_precision 和 torch.set_float32_matmul_precision。在我们的脚本中,我们已经尽力去识别并排除这些可能的问题,但我们无法保证我们的尝试一定能够完全成功。
测试结果
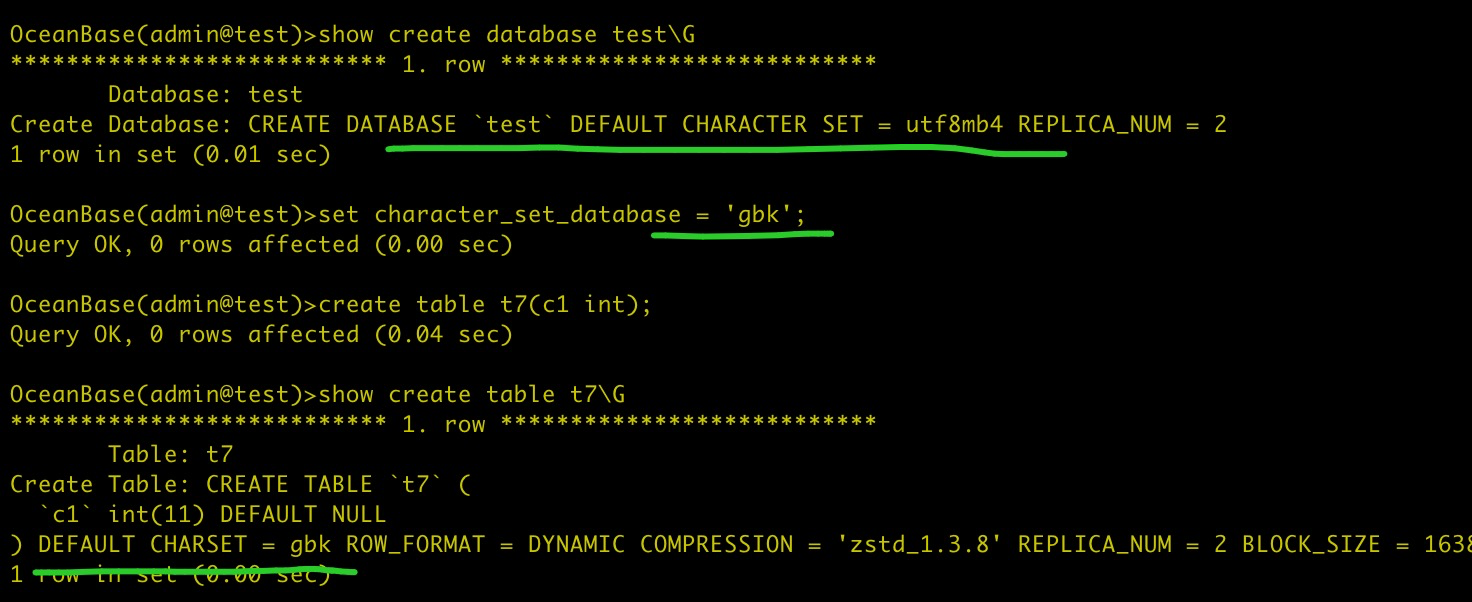
我们在 Google Cloud 的两台虚拟机上执行了训练脚本,一台配置为 g2-standard-16(配备了一块 NVIDIA L4 GPU),另一台是 a2-highgpu-1g(配备了一块 NVIDIA A100 GPU)。无论哪种情况,我们都选用了专为深度学习定制的虚拟机镜像(common-cu121-v20240514-ubuntu-2204-py310),并预装了 PyTorch(版本 2.3.0)、PyTorch/XLA(版本 2.3.0)、JAX(版本 0.4.28)、Flax(版本 0.8.4)、Optax(版本 0.2.2)以及 HuggingFace 的 Transformers 库(版本 4.41.1)。
以下表格汇总了多项实验的运行时间数据。需要提醒的是,模型架构和运行环境的不同可能会导致性能比较结果有显著差异。同时,代码中的一些细微调整也可能对这些结果产生显著影响。


尽管 JAX 在 L4 GPU 上展现出了明显超越其他选项的性能,但在 A100 GPU 上,它与 PyTorch/XLA 的表现却旗鼓相当。这种情况并不出人意料,因为它们共享了 XLA 后端。理论上,JAX 生成的任何 XLA(高级线性优化)图都应该能够被 PyTorch/XLA 同样实现。在这两种平台上,torch.compile 功能的表现都不尽如人意。考虑到我们选择了全精度浮点数进行计算,这种情况在一定程度上是可以预见的。
那么为什么要使用 JAX?
-
性能优化
JAX 训练的一个主要吸引力在于 JIT 编译可能带来的运行时性能提升。然而,随着 PyTorch 新增的 JIT 编译功能(PyTorch/XLA)以及更进一步的 torch.compile 选项,JAX 的这一优势可能遭到质疑。实际上,考虑到 PyTorch 背后庞大的开发者社区,以及 PyTorch 所原生支持而 JAX/FLAX 尚未涵盖的众多特性(例如自动混合精度、先进的注意力机制层,至少在本文撰写时),有人可能会强烈主张没有必要投入时间去掌握 JAX。除了可能的性能提升之外,还有一些其他的动力因素:
-
XLA友好性
与 PyTorch 后来通过 PyTorch/XLA 实现的“函数化”不同,JAX 从设计之初就内嵌了 XLA 的支持。这表明在 PyTorch/XLA 中可能显得复杂或混乱的操作,在 JAX 中可以更加简洁优雅地实现。例如,在训练过程中混合使用 JIT 和非 JIT 函数,在 JAX 中是直接可行的,而在 PyTorch/XLA 中可能需要一些巧妙的技巧。
正如之前提到的,理论上,PyTorch/XLA 和 TensorFlow 都能够生成与 JAX 相同的 XLA(高级线性优化)图,从而实现同等的性能。然而,在实际操作中,生成的图的优劣取决于框架实现如何转化为 XLA 代码。更高效的转换将带来更佳的运行时性能。由于 JAX 原生支持 XLA,它可能在与其他框架的竞争中占据优势。
JAX 对 XLA 的友好性使其对专用 AI 加速器的开发人员尤其有吸引力,例如 Google Cloud TPU、Intel Gaudi 和 AWS Trainium 芯片,这些加速器通常被称为“XLA 设备”。特别是在 TPU 上进行训练的团队可能会发现 JAX 的支持生态系统比 PyTorch/XLA 更先进。
-
高级特性
近年来,JAX 中发布了许多高级功能,远远早于同行。例如,SPMD 是一种先进的设备并行技术,提供最先进的模型分片机会,几年前在 JAX 中引入,最近才被转移到 PyTorch。另一个例子是 Pallas(终于)能够为 XLA 设备构建自定义内核。
开源模型
随着 JAX 框架的日益普及,越来越多的开源 AI 模型正在 JAX 中发布。一些经典的例子是 Google 的开源 MaxText (LLM) 和 AlphaFold v2(蛋白质结构预测)模型。要充分利用此类模型,您需要学习 JAX,或者承担将其移植到另一种语言的重要任务。
总结
本文我们深入探讨了正在崛起的 JAX 机器学习开发框架。我们阐述了它依托于 XLA 编译器,并在一个示例中演示了其应用。虽然 JAX 常因其快速的运行时执行速度而备受瞩目,但 PyTorch 的 JIT 编译功能(包括 torch.compile 和 PyTorch/XLA)同样具备性能优化的巨大潜力。每种选择的性能表现,将极大程度上依赖于模型的具体细节和运行环境。
值得注意的是,每个机器学习开发框架都可能拥有其独到的特性(例如,截至本文撰写时,JAX 的 SPMD 自动分片和 PyTorch 的 SDPA 注意力机制),这些特性可能在性能比较中起到关键作用。因此,选择最佳框架的决定因素可能是你的模型能够多大程度上利用这些特性。
Source: https://towardsdatascience.com/ai-model-training-with-jax-6e407a7d2dc8
本文由 mdnice 多平台发布