大家好
某种程度来说大模型训练的核心算法就是300到400行代码,如果真正理解了并不难。下面我将带大家分析常规大模型训练有几个阶段以及在训练中一般会用到哪些方法。

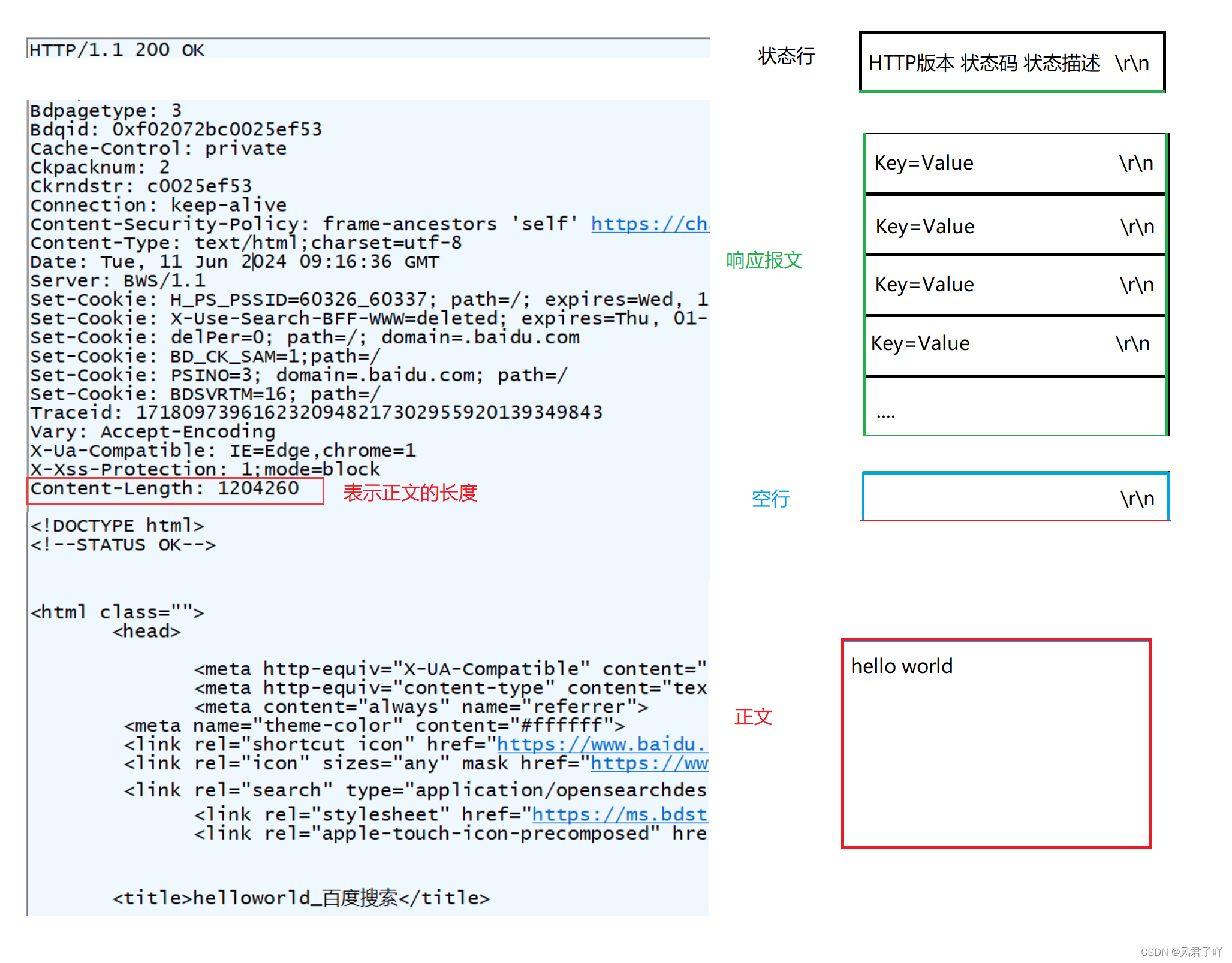
由上图可以看出,大模型训练主要有四个阶段:预训练、有监督微调、奖励建模、强化学习。开始的第一个阶段是预训练阶段。这个阶段在这个图中有点特殊,因为这个图没有按比例缩放。实际上预训练消耗的时间占据了整个训练pipeline的99%。
因此,这个阶段就是我们在超级计算机中使用数千个GPU以及数月的训练来处理互联网规模数据集的地方。
其他三个阶段是微调阶段,更多地遵循少量GPU和数小时或数天的路线。
那么首先让我们来看看预训练阶段用到了哪些方法。
1.数据分布
首先做预训练需要收集大量数据,那么数据分布大致需要满足什么条件呢?

由上图可以看出,这是Meta发布了关于Llama基础模型训练时候的数据分布。大约1.4T的tokens,包含github、Wikeipedia等数据。
我们都知道大模型需要大量的高质量的训练数据,在目前这个Transformer为主导的背景下,算法其实差不多都固化了。市面上有关大模型的公司,投入人力物力最大的地方除了算力就是数据这一块了。如何高效获取数据、清洗数据、标注数据、质检数据以及如何平衡各类别数据占比等等问题是否解决,决定了这个大模型是否work。
数据问题解决后,接下来面对的问题是:机器只知道01二进制,如何把这些数据转化成机器能够看懂的语言?
2.标记化(tokenization)
实际训练这些数据之前,我们需要再经过一个预处理步骤,即标记化(tokenization)。

如上图所示tokenization分为两个阶段,第一阶段将原始文本转化成tokens,请注意并不是说一个单词就是一个token,这与你采用的tokenization算法相关。第二阶段,将tokenization之后的tokens,去词表中查找对应的ids,输出得到一个很长的整数列表。
举个例子,下面我以GPT2为例,展示如何使用tiktoken这个python包来实现tokenization。
代码:
import tiktoken
input = "The GPT family of models process text using tokens, which are commonsequences of characters found in text. The models understand thestatistical relationships between these tokens, and excel at producingthe next token in asequence of tokens.You can use the tool below to understand how a piece of text would betokenized by the API, and the total count of tokens in that piece oftext."
enc = tiktoken.encoding_for_model("gpt2")
enc_output = enc.encode(input)
print("输入文字:"+str(input))
print("编码后的token:"+str(enc_output))
for token in enc_output:
print("将token:"+str(token)+" 变成文本:"+str(enc.decode_single_token_bytes(token)))
#输入文字:The GPT family of models process text using tokens, which are commonsequences of characters found in text. The models understand thestatistical relationships between these tokens, and excel at producingthe next token in asequence of tokens.You can use the tool below to understand how a piece of text would betokenized by the API, and the total count of tokens in that piece oftext.
#编码后的token:[464, 402, 11571, 1641, 286, 4981, 1429, 2420, 1262, 16326, 11, 543, 389, 2219, 3107, 3007, 286, 3435, 1043, 287, 2420, 13, 383, 4981, 1833, 262, 14269, 19929, 6958, 1022, 777, 16326, 11, 290, 27336, 379, 9194, 1169, 1306, 11241, 287, 257, 43167, 286, 16326, 13, 1639, 460, 779, 262, 2891, 2174, 284, 1833, 703, 257, 3704, 286, 2420, 561, 731, 4233, 1143, 416, 262, 7824, 11, 290, 262, 2472, 954, 286, 16326, 287, 326, 3704, 286, 5239, 13]
上面说的是GPT2的tokenization,GPT-3.5和GPT-4 等较新的模型使用与以前的模型不同的tokenization,并且将为相同的输入文本生成不同的tokens。
如果你想体验GPT-3.5和GPT-4的tokenization,只需更换成如下代码即可。
enc = tiktoken.encoding_for_model("cl100k_base")
3.嵌入化(embedding)
介绍embedding时,首先要弄明白几个名词:
- dim:embedding后的向量长度
- vocab_size:词表的长度
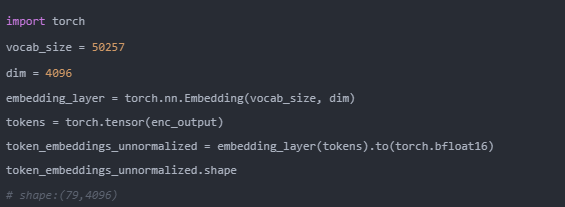
通过2.tokenization编码后得到tokens:[464, 402, 11571, …,13],共计79个数字。
通过embedding层,即权重为[vocab_size, dim]的矩阵。
所以我们的 [79x1] tokens通过embedding层,输出是 [79x4096],即79个长度为4096的向量(每个token一个)
代码实现如下:
4.batch思想

我们将embedding后的数组输入Transformer,不可能全部一次性输入,需要用batch思想分批导入。
在此批量大小是B,T是最大上下文长度。
在上面这个图中,长度T只有10,实际工作这可能是2000、4000 等等,在llama3中,T可达到8192。
除此之外,图中也提到<|endoftext|> 这样一个特殊字符。在GPT-2中,它表示文本的结束。在llama3中,就不用<|endoftext|> ,采用<|begin_of_text|>,<|end_of_text|>等特殊字符。
5.归一化(Normalization)
输出embedding后,我们还需做归一化。做归一化的原因有很多:1、同一量纲;2、加速收敛;3、提高模型性能等等。很多解释都是实验结果导向,实验做好了,自然有很多故事来解释它。下面我们来解释大模型训练中常用到的一些归一化方法。
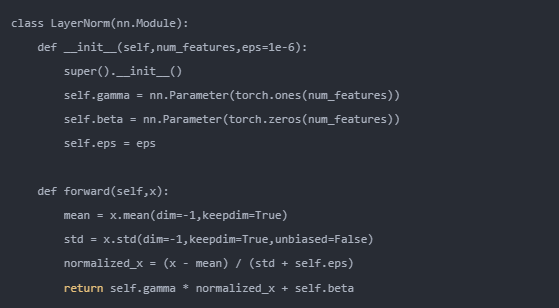
首先需要理解LayerNorm
Layer Normalization (LayerNorm) 是一种归一化技术,常用于深度学习模型中,特别是在 Transformer 模型中。
与 Batch Normalization 不同,Layer Normalization 是在特征维度上进行标准化的,而不是在数据批次维度上。
Layer normalization 的计算可以分为两步。
(1)计算均值和方差。
在本文章的例子中,“The”这个token可以表示成一个4096维度的向量。需计算这个向量中所有元素的均值与方差。
(2)标准化和重新缩放
利用(1)中计算得到的均值与方差,将该向量标准化。并且设置两个可学习的参数,重新缩放和偏移。
总结一句话:LayerNorm就是将每个token对应向量的数据分布通过线性变换转化成正态分布。
代码如下:
RMS Norm
RMS Norm是LayerNorm的一种变体,LLaMA最新开源的LLaMA3也使用到了RMS Norm。
相比普通正则化,它的计算效率更高,并且原论文的实验结果显示这种简化并没有对模型的训练速度和性能产生明显影响。
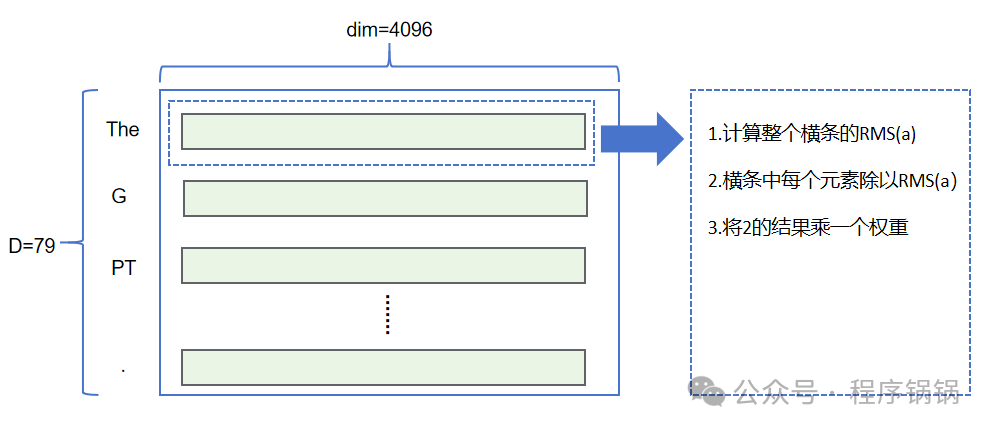
具体RMS Norm计算过程如上所示,我们使用RMS Norm对embedding输出进行归一化,计算公式如下。
其中为输入,如果dim=4096,即i=0,1,2…,4095。
为输出,同理,i=0,1,2…,4095:

RMS Norm代码实现如下:
def rms_norm(tensor, norm_weights):
return (tensor * torch.rsqrt(tensor.pow(2).mean(-1, keepdim=True) + norm_eps)) * norm_weights
为什么要用Layer Norm不用Batch Norm
很多图像识别方面的任务都是采用Batch Norm,为什么在文本大模型这一块一般不使用Batch Norm而是使用Layer Norm呢?
首先,Transformer中的输入序列长度可变,不同样本的序列长度不同,具体实现的时候需要通过pad来满足序列长度的统一。在这样的情况下,Batch Norm计算每个batch的均值和方差不太合理,而LayerNorm在每个样本内部做归一化,不受batch size影响。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。