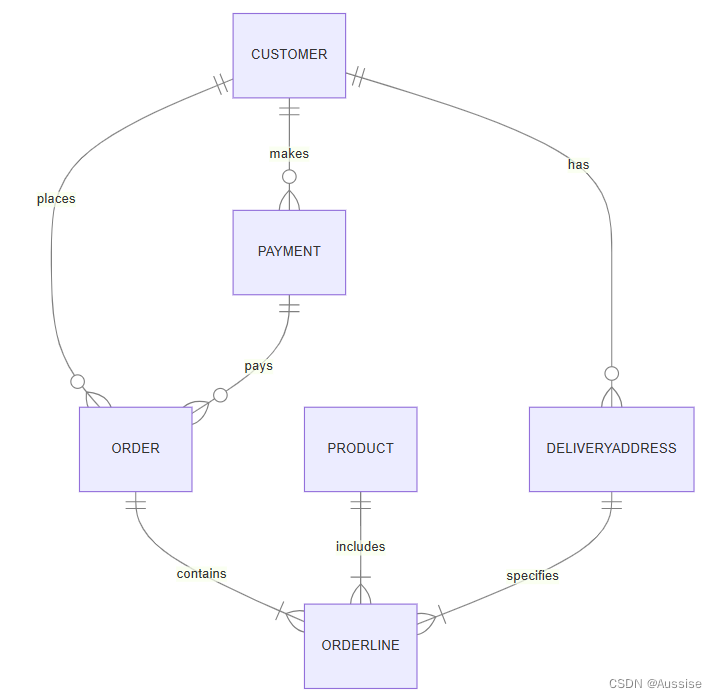
概述
我们都知道,递归代码的时间复杂度分析起来很麻烦。在《排序(下)》哪里讲过,如何用递推公式,求解归并排序、快速排序的时间复杂度,但是有些情况,比如快排的平均时间复杂度的分析,用递推公式的话,会设计非常复杂的数据推到。
除了用递推公式这种比较复杂的分析方法,有没有更简单的方法呢?本章就来学习另外一种方法,借助递归树来分析递归算法的时间复杂度。
递归树与时间复杂度分析
之前即讲过,递归的思想是,将大问题分为小问题来求解,然后再将小问题分解为小小问题。这样一层一层地分解,直到问题的数据规模被分解得足够小,不用继续递归分解为止。
如果我们把这一层一层的分解过程画成图,它其实就是一棵树。我们个这棵树起一个名字,叫做递归树。下面画了一颗斐波那契数列的递归树,你可以看看。节点里的数字表示数据的规模,一个节点的求解可以分解为左右子节点两个问题的求解。
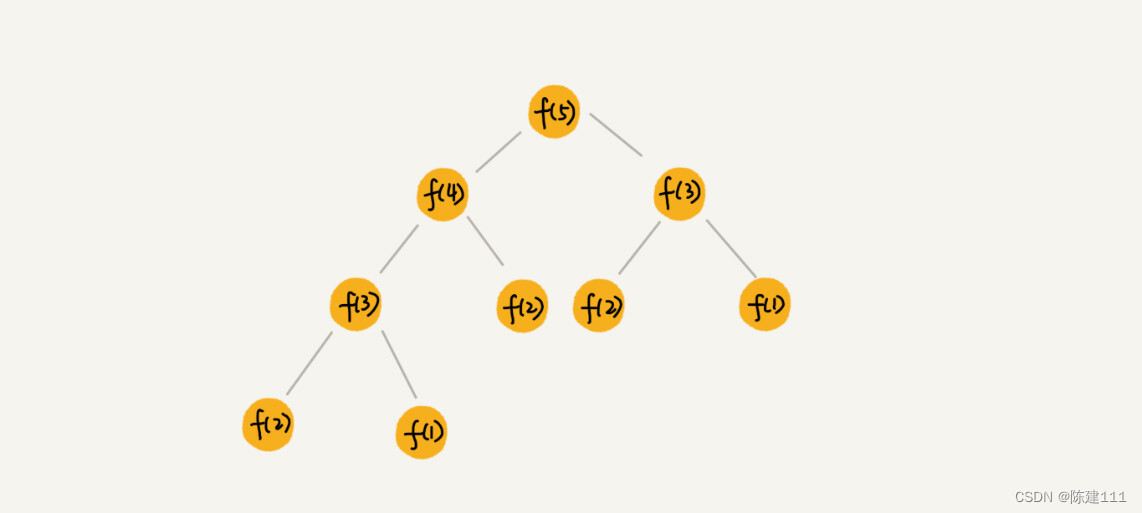
通过这个例子,你对递归树的样子应该有一个感性的认识了,看起来并不复杂。现在,我们就来看,如何用递归树来求解时间复杂度。
归并排序算法你还记得把?它的递归实现代码非常简洁。现在我们就借助排序来看看,如何用递归树,来分析递归代码的时间复杂度。
归并排序算法的原理这里就不介绍了。归并排序每次会将数据规模一分为二。我们把归并排序画成递归树,就是下面的样子。
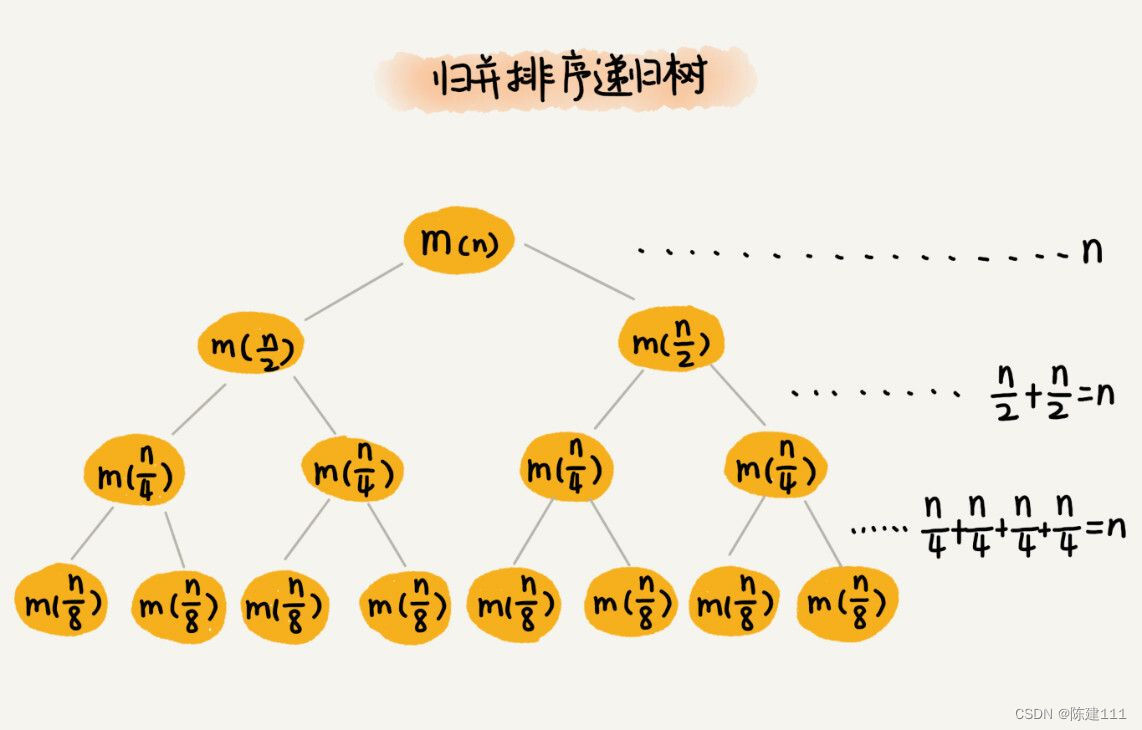
因为每次分解都是一分为二,所以代价很低,我们把时间上的消耗记作常量 1。归并算法中,比较耗时的操作是归并操作,也就是把两个子数组合并为大数组。从图中我们可以看出,每一层归并曹邹的耗时的时间综合都是一样的,跟要排序的数据规模有关。我们把每一层归并操作消耗的事件记作 n。
现在,只需要知道这棵树的高度 h,用高度 h 乘以每一层的时间消耗 n,就可以得到总的时间复杂度 O ( n ∗ h ) O(n*h) O(n∗h)。
从归并排序的原理和递归树,可以看出来,归并排序递归树是一个满二叉树。前面两篇文章讲到,慢二叉树的高度是 l o g 2 n log_2 n log2n,所以,归并排序算法的高度就是 O ( n l o g n ) O(nlogn) O(nlogn)。这里的时间复杂度都是估算的,对树的高度的计算也没有那么精确,但是这并不影响复杂度的计算结果。
利用递归的时间复杂度分析方法并不难理解,关键还是在实战,所以,接下来会通过三个事件的递归算法,带你实战一下递归的复杂度分析。学完本章后,你应该就能真正掌握递归代码的复杂度分析。
实战一:分析快速排序的时间复杂度
在用递归树推到这钱,先来回忆一下用递归公式的分析方法。回想一下,当时,为什么说用递推公式求解平均时间复杂度非常复杂?
快速排序在最好情况下,每次分区都能一分为二,这个时候用递推公式 T ( n ) = 2 T ( n 2 ) + n T(n)=2T(\frac n 2) + n T(n)=2T(2n)+n 很容易就能推导出时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn)。但是,我们并不可能每次分区都这么幸运,正好一分为二。
假设平均情况下,每次分区之后,两个分区的大小比例为 1:k。当 k = 9 时,如果用递归公式的方法来求解时间复杂度的话,递推公式就写成
T
(
n
)
=
T
(
n
10
)
+
T
(
9
n
10
)
+
n
T(n)=T(\frac n {10}) + T(\frac {9n} {10}) + n
T(n)=T(10n)+T(109n)+n。
这个公式可以推导出时间复杂度,但是肯定推到过程非常复杂。那我们来看看,用递归树来分析快速排序的平均情况时间复杂度,是不是比较简单呢?
还是取 k 等于 9,也就是说,每次分区都很不平均,一个分区是另一个分区的 9 倍。如果我们把递归分析的过程画成递归树,就是下面的样子:
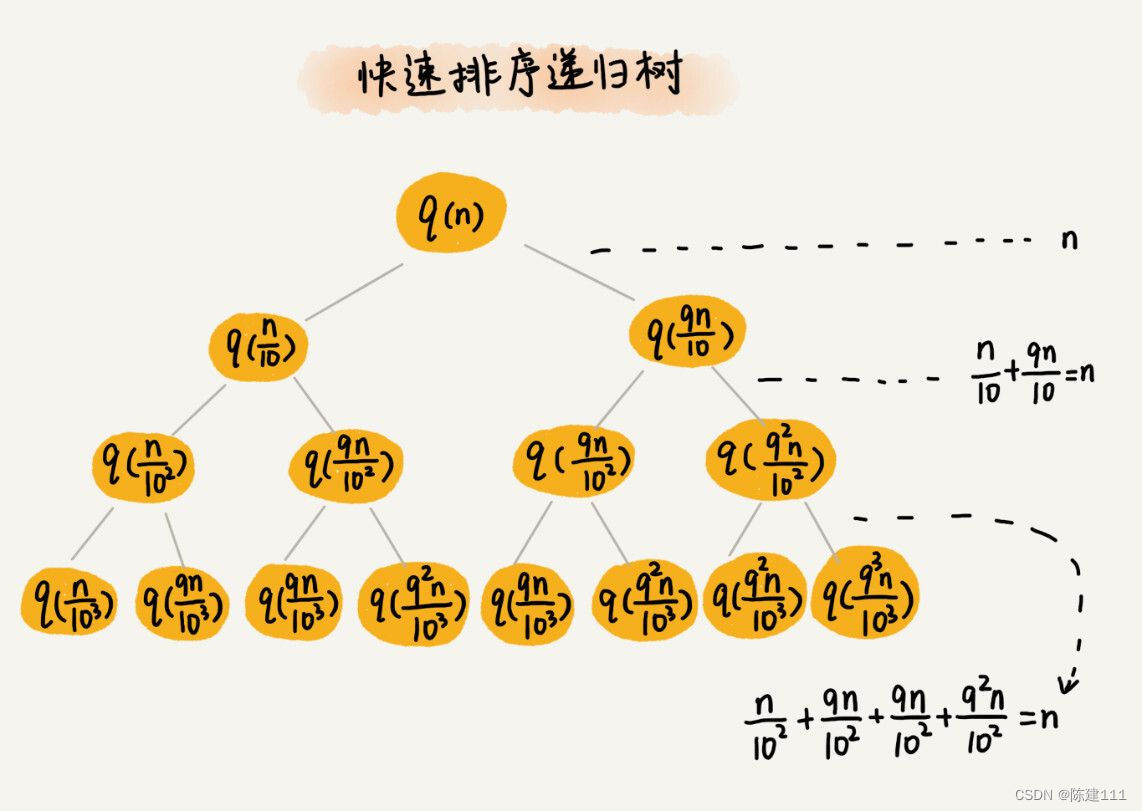
快速排序的过程中,每次分区都要遍历带分区区间的所有数据,所以,每一层分区操作所遍历的数据的个数之和就是 n。我们现在只要求出递归树的高度 h,这个快速排序过程遍历的数据个数就是 h * n,也就是说时间复杂度就是 O ( h ∗ n ) O(h*n) O(h∗n)。
因为每次并不是均匀地一分为二,所以递归树不是满二叉树。这样一个递归树的高度是多少呢?
我们知道,快速排序结束的条件就是排序的小区近,大小为 1,也就是说叶子节点里的数据规模是 1.从根节点 n 到叶子节点 1 ,递归树中最短的一个路径每次都乘以 1 10 \frac 1 {10} 101,最长一个路径每次都乘以 9 10 \frac 9 {10} 109。通过计算,可以得到,从根节点到叶子节点的最短路径是 l o g 10 n log_{10}n log10n,最长路径是 l o g 10 9 n log_{\frac {10} 9}n log910n。
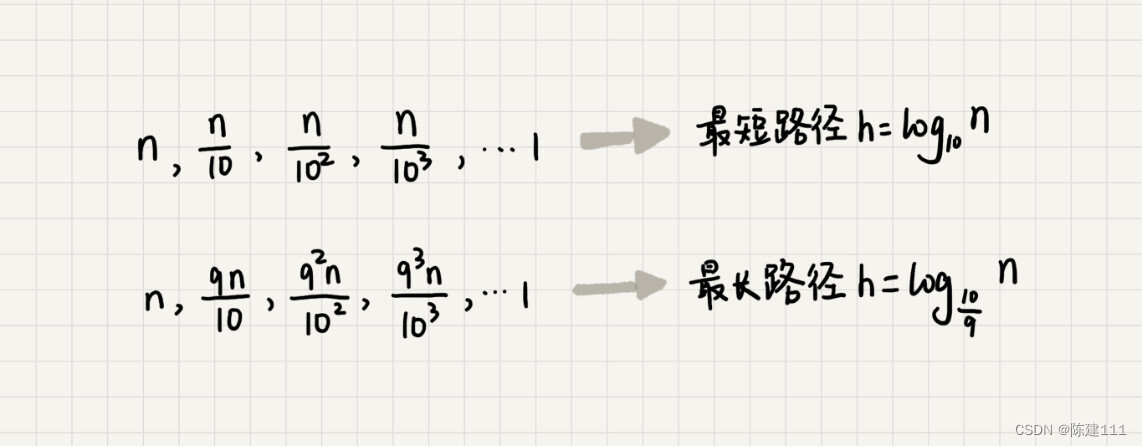
所以,遍历数据的个数综合就介于
l
o
g
10
n
log_{10}n
log10n 和
l
o
g
10
9
n
log_{\frac {10} 9}n
log910n 之间。根据复杂度的大 O 表示法,对数复杂的底数不管是多少,我们统一写成
l
o
g
n
logn
logn,所以,当分区发小比例是 1:9 时,快速哦爱旭的时间复杂度仍然是
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)。
刚刚假设的是 k=9,那如果 k=99,也就是说,每次分区极不平均,两个区间大小是 1:99 ,这个时候的时间复杂度是多少呢?
可以类比上面的 k=9 的分析过程。当 k=99 时,树的最短路径就是
l
o
g
100
n
log_{100}n
log100n,最长路径是
l
o
g
100
99
n
log_{\frac {100} {99}}n
log99100n,所以总遍历数据个数介于
l
o
g
100
n
log_{100}n
log100n 和
l
o
g
100
99
n
log_{\frac {100} {99}}n
log99100n 之间。尽管底数变量,但是时间复杂度仍然是
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)。
也就是说,对于 k 等于 9,99,甚至是 99,…, 只要 k 的值不随 n 变化,是一个实现确定的常量,那快排的时间复杂度就是 O ( n l o g n ) O(nlogn) O(nlogn)。所以,从概率论的角度来说,快排的平均时间复杂度就是 O ( n l o g n ) O(nlogn) O(nlogn)。
实战二:分析斐波那契数列的时间复杂度
在递归那篇文章,我们举了一个跨台阶的例子,你还记得吗?那个例子实际上就是斐波那契数列。放了方便你回忆,我把它的代码实现贴在这里。
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n - 1) + f(n - 2);
}
这样一段代码的时间复杂度是多少呢?
先把上面的递归代码画成递归树,就是下面这个样子。
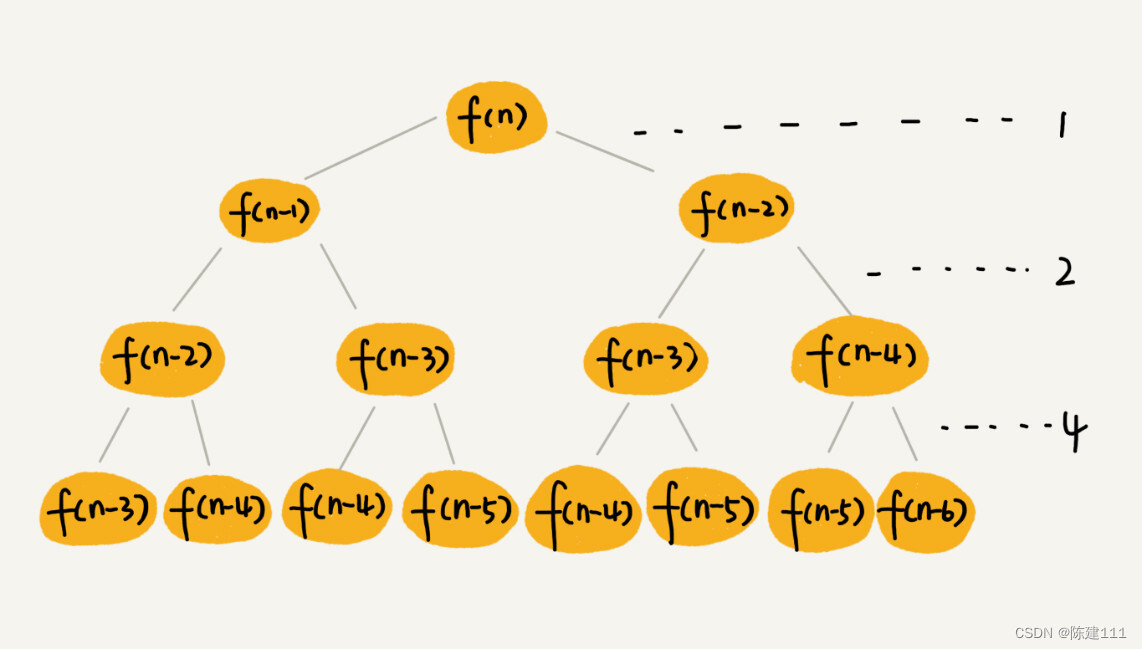
这棵树的高度是多少呢?
f(n) 分解为 f(n-1) 和 f(n-2),每次数据规模都是 -1 或 -2,叶子节点的数据规模是 1 或者 2.所以,从根节点到叶子节点,每条路径的长短都是不一样的。如果每次都是 -1。最大路径长度就是 n;如果每层都是 -1,最短路径大约就是
n
2
\frac n 2
2n。
每次分解之后的合并操作,只需要一次加法运算,我们把这次加法运算的时间消耗记作 1。所以,从上往下,第一层的总时间消耗是 1,第二层的总时间消耗是 2,第三层的总时间消耗是 2 2 2^2 22。以此类推,第 k 层的数据消耗是 2 k − 1 2^{k-1} 2k−1,整个算法的总时间消耗就是每一层时间消耗之和。
如果路径长度为 n,那这个总和就是
2
n
−
1
2^n-1
2n−1。
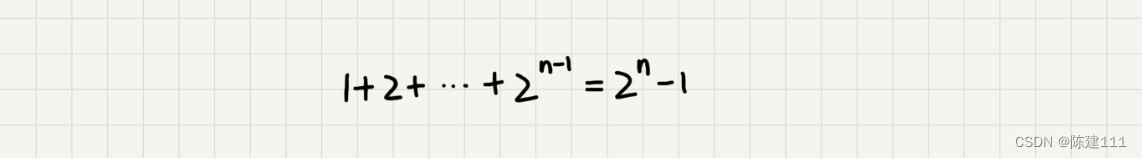
如果路径长度都是 n 2 \frac n 2 2n,那整个算法的总的时间消耗就是 2 n 2 − 1 2^{\frac n 2}-1 22n−1。
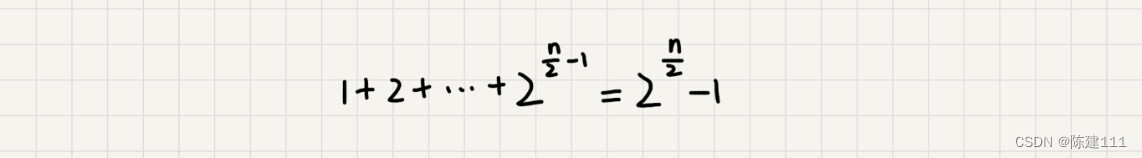
所以,这个算法的时间复杂度就介于 O ( 2 n ) O(2^n) O(2n) 和 O ( 2 n 2 ) O(2^{\frac n 2}) O(22n)。虽然这样得到的结果还不够精确,只是一个范围,但是我们也基本上知道了上面的时间复杂度是指数级的,非常高。
实战三:分析全排列的时间复杂度
前面两个复杂度分析哦度比较简单,再来看一个稍微复杂的。
在高中时都学过排列组合。“如何把 n 个数据的所有排列都找出来”,这就是全排列的问题。
比如,1,2,3 这样三个数据,有下面几种不同的排列:
1,2,3
1,3,2
2,1,3
2,3,1
3,1,2
3,2,1
如何编程打印一组数据的所有排列呢?这里就可以用递归来实现。
若我们确定了最后一位数据,那就变成了求解剩下 n-1 哥数据的排列问题。而最后一位数可以是 n 个数据中的任意一个,因此它的取值就有 n 种情况。所以,“n 个数据的排列” 问题,就可以分解成 n 个 “n-1 个数据排列” 的子问题。
如果写成递推公式,就是下面这个样子:
假设数组中存储的是 1,2,3,…,n。
f(1,2,…,n) = {最后一位是 1, f(n-1)} + {最后一位是 2, f(n-1)} + … + {最后一位是 n, f(n-1)}
如果把递推公式写成代码,就是下面这个样子:
// 调用方式
// int[] a = a={1, 2, 3, 4}; printPermutations(1,4,5);
// k 表示要处理的子数组的数据个数
public void printPermutations(int[] data, int n, int k) {
if (k == 1) {
for (int i = 0; i < n; i++) {
System.out.print(data[i] + " ");
}
System.out.println();
}
for (int i=0; i < k; i++) {
int tmp = data[i];
data[i] = data[k-1];
data[k-1] = tmp;
printPermutations(data, n, k - 1);
tmp = data[i];
data[i] = data[k-1];
data[k-1] = tmp;
}
}
如果不用前面讲的递归树分析法,这个递归代码的时间复杂度会比较难分析。现在,我们来看下,如何借助递归树,轻松分析出这个代码的时间复杂度。
首先,还是画出递归树。不过,现在的递归树已经不是标准的二叉树了。
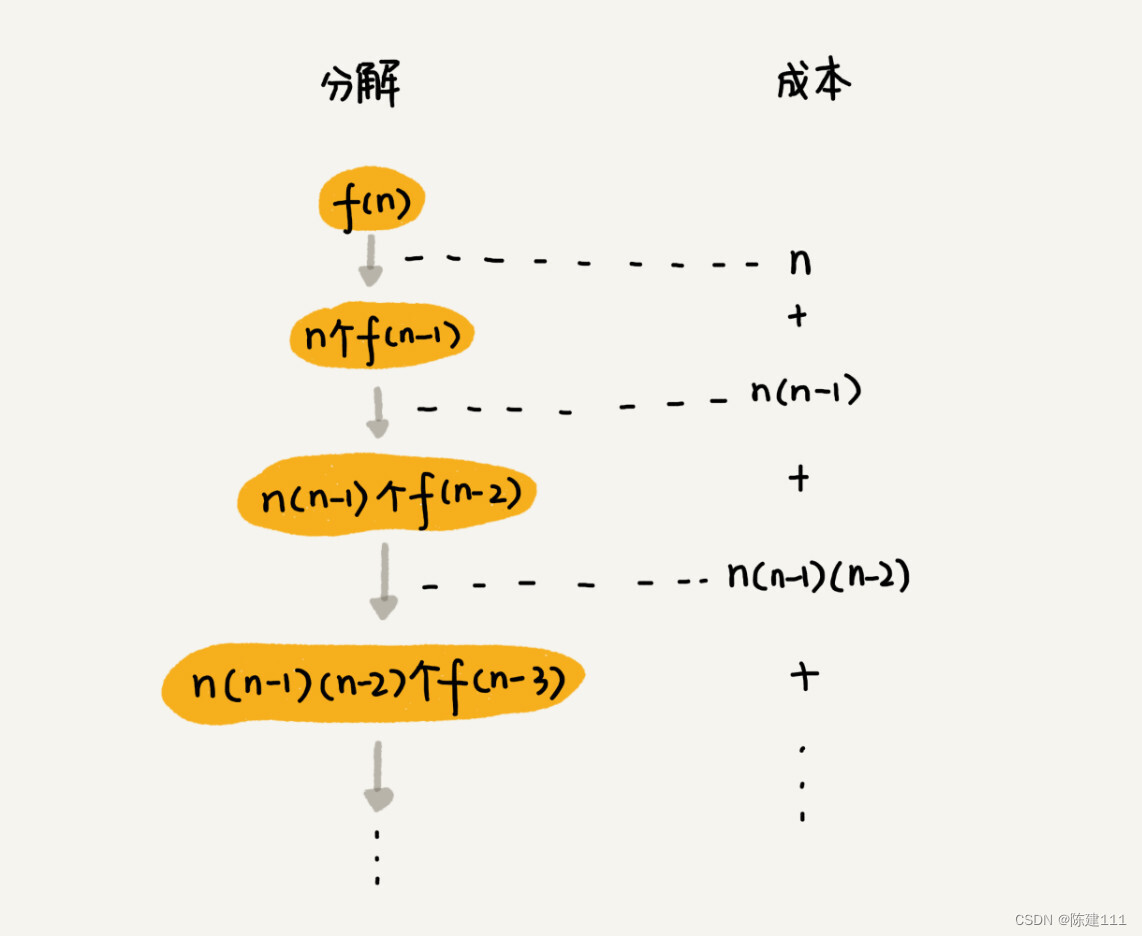
第一次分解有 n 次交换操作,第二层有 n 个节点,每个节点有 n - 1 次交换,所以,第二层总的交换次数是 n*(n-1)。第三层有 n*(n-1) 个节点,每个节点分解需要 n - 2 次交换,所以第三层的总交换次数是 n*(n-1)*(n-2)。
以此类推,第 k 层总的交换次数为 n*(n-1)*(n-2)*...*(n-k+1)。最后一次交换就是 n*(n-1)*(n-2)*...*2*1。每层交换之和就是总交换次数。
n + (n-1) + n*(n-1)*(n-2) + ...+ n*(n-1)*(n-2)*...*2*1
这个公式的求和比较复杂,我们看最后一个数, n*(n-1)*(n-2)*...*2*1 等于 n!。也就是说,全排列的递归算法的时间复杂大远大于
O
(
n
!
)
O(n!)
O(n!) 小于
O
(
n
∗
n
!
)
O(n*n!)
O(n∗n!),虽然没法知道非常精确的时间复杂度,但是这样一个范围已经让我们知道,全排列的时间复杂度是非常高的。
掌握分析的方法很重要,思路不是重点,不要纠结于精确的时间复杂度到底是多少。
小结
本章,用递归树分析了递归代码的时间复杂度。假设我们在排序那一章讲到的递推公式的时间复杂度分析法,我们已经学习了两种递归代码的时间复杂度分析方法了。
有些代码比较适合用递推公式来分析,比如归并排序的时间复杂度、快速排序的最好情况时间复杂度;有些适合采用递归树来分析,比如快速排序的平均时间复杂度。而有些可能两个都不怎么适合使用,比如二叉树的递归前中后序遍历。
时间复杂度分析的理论知识并不多,也不复杂,掌握起来也不难,但是,在我们平时的工作、学习中,面对的代码千差万别,能够灵活应用学到的复杂度分析法,来分析现有的代码的,并不是件简单的事情,所以,平时要多实战、多分析,只有这样,面对任何代码的时间复杂度分析,才能做到游刃有余、毫不畏惧。