想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
LLVM 后端实践笔记
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?pwd=vd6s 提取码: vd6s
在这一章,我们会在 Cpu0 后端中增加对子过程/函数调用的翻译功能,会添加大量代码。这一章首先会介绍 Mips 的栈帧结构,我们的 Cpu0 也会借用 Mips 的栈帧设计,大多数 RISC 机器的栈帧设计都是类似的,如果你对这块的背景知识有困惑,需要先查阅其他书籍,比如《深入理解计算机系统》这类计算机体系结构的书。
目录
1. 尾调用优化
1.1 什么是尾调用?
1.2 尾调用能做什么优化呢?
1.3 尾递归
2. Stack Overflow Exception
3. 修改的文件
3.1 Cpu0ISelLowering.cpp
3.1.1 LowerFormalArgument()
3.1.2 LowerCall()
3.1.3 LowerCall()中的尾调用
3.2 Cpu0MachineFunctionInfo.cpp
3.3 Cpu0SEISelLowering.cpp
3.4 Cpu0FrameLowering.cpp/.h
3.5 Cpu0InstrInfo.td
3.6 Cpu0InstrInfo.cpp
3.7 Cpu0MCInstLower.cpp/.h
3.8 Cpu0MachineFunctionInfo.cpp/.h
3.9 Cpu0SEFrameLowering.cpp/.h
3.10 MCTargetDesc/Cpu0AsmBackend.cpp
3.11 MCTargetDesc/Cpu0ELFObjectWriter.cpp
3.12 MCTargetDesc/Cpu0Fixupkinds.h
3.13 MCTargetDesc/Cpu0MCCodeEmitter.cpp
4. 结果
4.1 普通参数
4.2 结构体参数
4.3 字符串参数
4.4 浮点运算
4.5 尾调用优化
1. 尾调用优化
在这一章我们会添加一个跟尾调用优化有关系的函数,虽然这不是本章的重点,但是尾调用优化是编译器后端较重要的一个优化点,这里简单展开介绍一下。
1.1 什么是尾调用?
int f(int x) {
return g(x);
}
int m(int x) {
if (x > 0)
return m(x);
return n(x);
}上述的两个函数都属于尾调用。
int f(int x) {
int a = g(x);
return a;
}
int m(int x) {
return g(x) + 1;
}上述两个函数都不属于尾调用。
尾调用就是指某个函数的最后一步是调用另一个函数,注意到这里的最后一步,上两个函数在调用之后都有别的操作,因此不满足尾调用。而且要注意这里的最后一步指的是程序执行上的最后一步,并不是说一定要写在最后。
1.2 尾调用能做什么优化呢?
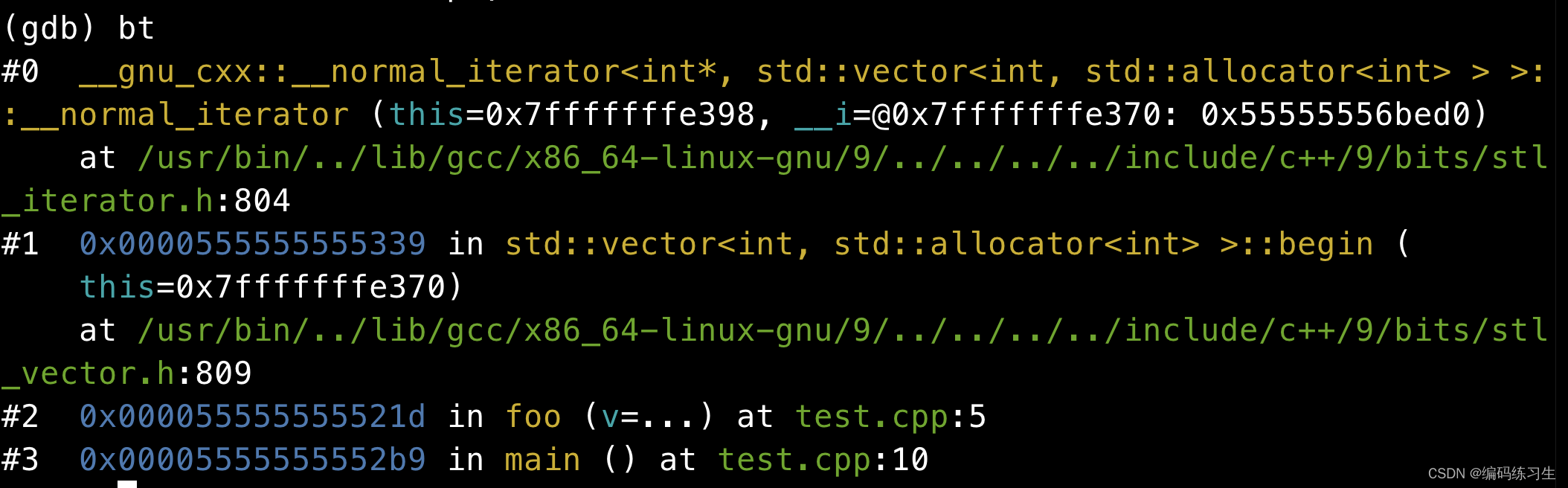
函数调用的时候会在内存形成一个调用记录:调用栈,保存调用位置和内部变量等信息。如果函数main调用了函数foo,那么在main的调用记录上方会形成一个foo的调用记录。等到程序foo运行结束将结果返回给main,foo的调用记录才会消失。如果函数foo的内部还调用了函数begin,那么函数foo的上部还有一个begin的调用记录,以此类推。所以的调用记录会形成一个调用栈,在gdb调试的时候,我们bt就可以打印出来当前状态下的调用栈。
尾调用特殊的地方是他是一个函数执行的最后一步,如果说begin函数是foo函数内的尾调用,那么在begin函数结束的时候foo函数也会直接结束,这里就有一点可以优化的地方了。是不是说明在尾调用的时候就不需要外层函数的栈桢了呢?begin函数结束之后可以直接返回到上上层函数也就是main函数中了,因为begin之后foo函数内不会有别的操作了,这就是尾调用的一个优化点,能够缓解栈桢的压力。
1.3 尾递归
int f(int x, int total) {
if (n == 1)
return total;
return f(n - 1, n * total);
}这里一个递归计算阶乘的操作,尾调用自己的话就属于尾递归。我们知道在,正常的递归操作是非常占内存的,因为递归深度可能有成百上千的,而且很容易发生Stack Overflow Exception(栈溢出)。但是对于上例中的尾调用来说,在进入调用函数的时候,我们就不需要上层函数的调用栈了,这样的话我们永远只需要维护当前执行的一个函数的调用栈就可以,大大减轻了栈桢的压力。
同时尾递归还可以优化成循环迭代,参考下边4.5章节。
2. Stack Overflow Exception
上边提到了递归过深容易发生Stack Overflow Exception,Stack Overflow Exception算是异常里边最特殊的一个了,这里简单介绍一下。
我们程序的栈桢的空间肯定是有限的,当我们使用的栈空间超过了我们栈的范围时,就应该正确抛出Stack Overflow Exception异常。这里我说正确抛出,有些人可能会有个疑问,不就抛个异常吗,有什么难的?
对于Stack Overflow Exception这个异常来说还真有一点儿难。因为这个时候我们的栈已经不够用了,然而抛异常我们还需要调用执行对应的异常函数,执行函数又需要栈,这就与我们当前的问题相茅盾了。我们的栈已经不够用了,还支持我们抛出异常吗?这就是我说Stack Overflow Exception是最特殊的异常的原因。
所以,我们想要正确抛出Stack Overflow Exception异常的话一定要做一些特殊的措施:
- 我们可以提前预留一部分栈,用于抛出Stack Overflow Exception异常。
- 我们也可以在发生Stack Overflow Exception异常的时候撤回一部分栈,能让我们抛出异常。
我们能够看到正确抛出Stack Overflow Exception异常不是那么容易的。
3. 修改的文件
Cpu0 函数调用的第一件事是设计好如何使用栈帧,比如在调用函数时,如何保存参数。
具体如下表所示,保存函数参数有两种设计,第一种是将所有参数都保存在栈帧上,第二种是选出一部分寄存器,将部分参数先保存在这些寄存器中,如果参数过多,超出的那些再保存在栈帧上。比如 Mips 设计中,将前 4 个参数保存在寄存器 $a0, $a1, $a2, $a3 中,然后再把多余的其他参数保存在栈帧。
3.1 Cpu0ISelLowering.cpp
3.1.1 LowerFormalArgument()
ISelLowering 中实现了几个重要的函数。其中之一就是 LowerFormalArgument(),LowerFormalArgument()的作用是实现在被调用函数内部将参数传递到被调用函数。回顾一下之前全局变量的实现代码,当时实现了 LowerGlobalAddress() 函数,然后在 td 文件中实现指令选择模板,当代码中存在全局变量的访问时,LLVM 就会访问这个函数。LowerFormalArgument() 也是同样的道理,会在函数被调用时被访问。它从 CCInfo 对象中获取输入参数的信息,比如 ArgLocs.size() 就是传入参数的数量,而每个参数的内容就放在 ArgLocs[i] 中,当 VA.isRegLoc() 为 true 时,表示参数放到寄存器中传递,而 VA.isMemLoc() 为 true 时,就表示参数放到栈上传递,在访问参数时,根据这个值,就可以根据实际情况来做处理加载参数的过程。它内部有一个 for 循环,来依次处理每个参数的情况。
当访问寄存器时,它会先激活寄存器(Live-in),然后拷贝其中的值,当使用内存传递参数时,它会创建栈的偏移对象,然后使用 load 节点来加载值。编译参数 -cpu0-s32-calls=false 时,它会选择将前两个参数从寄存器中读取,否则,所有参数都从栈中 load 出来。在加载参数前,会先调用 analyzeFormalArguments() 函数,在内部使用 fixedArgFn 来返回函数指针 CC_Cpu0O32 或 CC_Cpu0S32,这两个函数分别是处理两种不同的参数加载方式,即前两个参数从寄存器读取还是全部都从栈上加载。
ArgFlags.isByVal 用于处理结构体指针的关键信息,在遇到结构体指针时,会返回 true。当 -cpu0-s32-calls=false 时,栈帧偏移从 8 开始,这就是为了保证前两个从寄存器传递的参数有可能 spill 的情况,当编译参数为 true 时,栈帧偏移就从 0 开始了。传递结构体参数比较特殊,在函数结尾前,有一个和前边一样的 for 循环,再一次遍历所有的参数,并判断如果这个参数存在一个 SRet 标记,就将对应参数的值拷贝到以一个 SRet 寄存器为 base 的栈的偏移中,通过调用 getSRetReturnReg() 获取 SRet 寄存器,通常为 $2。我们还需要一些辅助的函数,比如 loadRegFromStackSlot() 函数,用来将参数从栈帧 load 到寄存器中。
3.1.2 LowerCall()
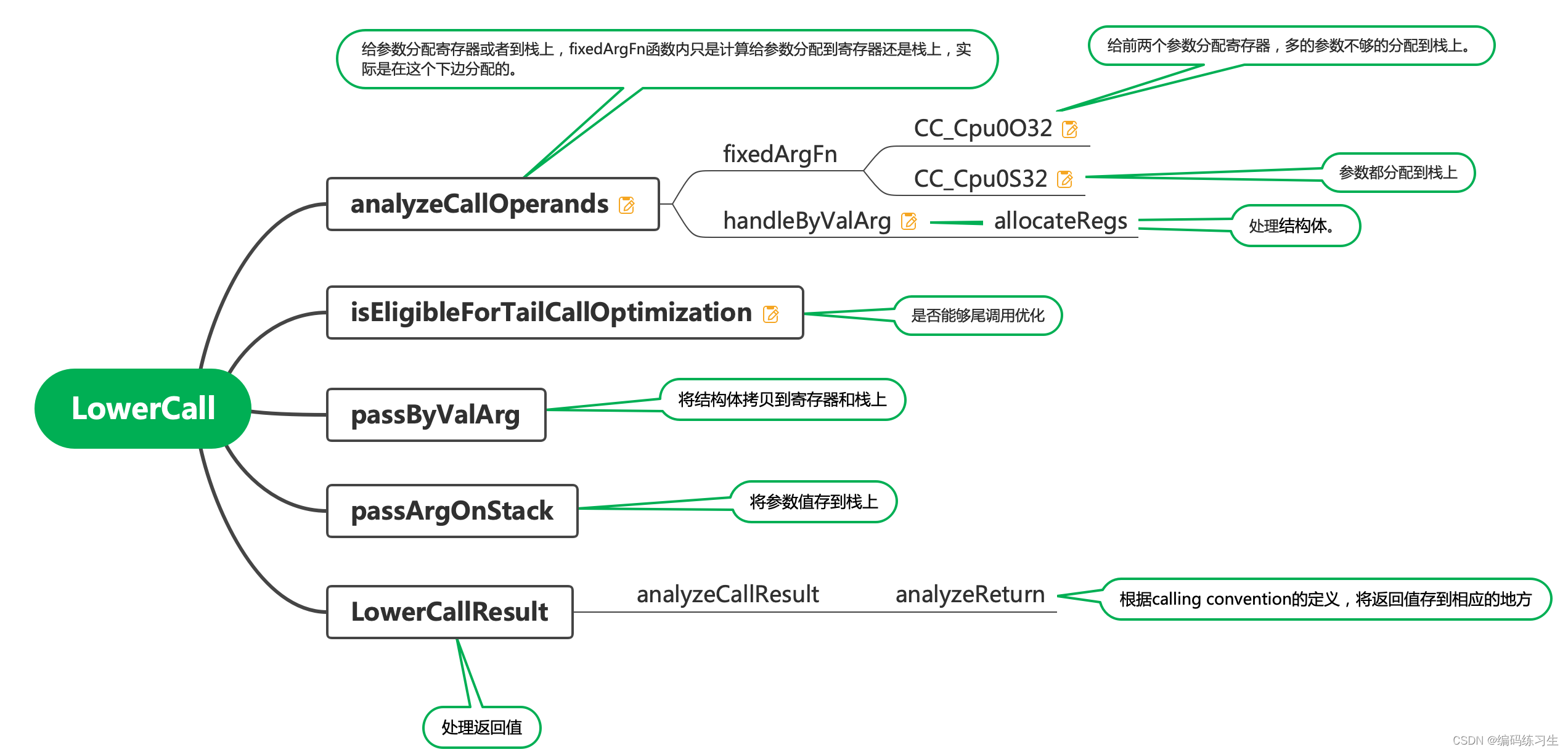
LowerCall()实现在函数调用时将实参传入栈,以及如何将函数执行结束后的返回值传递回调用函数。在 LowerCall() 函数中,前边先调用了 analyzeCallOperands() 函数,分析 call 操作的操作数,为之后分配地址空间做准备。然后会调用尾调用优化函数 isEligibleForTailCallOptimization(),这里做这样的优化,可以避免尾递归情况下函数频繁开栈空间的问题。通常支持递归的栈式处理器程序都需要对尾调用做额外处理。
之后,插入 CALLSEQ_START 节点,标记进入 call 的输出过程。内部使用一个大循环,对所有参数做遍历,将需要通过寄存器传递的参数 push_back 到 RegsToPass 中,调用了 passByValArg() 函数生成存入寄存器的行为节点链。并在参数大小不满足调用约定的参数做 promote。然后对于通过栈传递的参数,将其加入到 MemOpChains 中,调用了 passArgOnStack() 函数来生成存入栈的行为节点链。
可以展开来看 passByValArg() 函数和 passArgOnStack() 函数的内部实现。如果被调用函数是一个外部函数,包括全局函数(基本都满足这种情况),需要生成一个外部符号加载,这里需要创建一个 TargetGlobalAddress 或 TargetExternalSymbol 节点,从而避免合法化阶段去操作它。其他部分的代码会将这里的节点转换成 load 外部符号的指令并发射。
之后将所有 call 节点参数(所有节点参数,包括实参、返回值、chain 等)使用 getOpndList()汇总起来做处理,在这个函数中,针对不同的参数类型和属性,分别创建不同的操作方式,比如对于需要通过寄存器传递的实参,创建一系列的 copy to reg 操作。最后把所有操作都打包到 `Ops` 中返回。
如果是 PIC 模式,编译器会生成一条 load 重定位的 call 符号的地址 + 一条 jarl;如果不是,则会生成 jsub + 符号地址;PIC 模式会留给链接器之后再去重定位。
最后,生成一条跳转节点 Cpu0ISD::JmpLink,跳转到被调用函数的符号地址,Ops 作为 call 节点参数被引入。对于尾调用,需要额外生成 Cpu0ISD::TailCall 节点。插入 CALLSEQ_END 节点,标记结束 call 动作。
最后会调用 LowerCallResult() 函数处理调用结束返回时的动作。其中调用了 analyzeCallResult 分析返回 call 的参数,并处理所有返回参数,还原 caller saved register。如果是一个 struct 传值的返回值,Flags.isByVal 是为 true,就会将结构体的值依次存入栈中。
需要提及的是,我们在 Cpu0CallConv.td 中定义的 caller register 和 callee register 会在这里参与指导流程,我们通过调用 Cpu0CCInfo 对象来访问这些配置化的属性。
定义了一个统计参数 NumTailCalls,用来计数 case 中尾调用的数量。
3.1.3 LowerCall()中的尾调用
在 LowerCall() 函数中,检查是否可以进行尾调用优化。这个状态是 Clang 给出的,Clang 在前端就可以分析是否满足尾调用特征,并在开优化的情况下生成 tail call 的 IR。如果是尾调用优化,就不必再发射 callseq_start 到 callseq_end 的这段代码了。取而代之的是在指令选择时选择到伪代码 TAILCALL,并在指令发射时展开成 JMP 指令。
新增代码到 Cpu0AsmPrinter.cpp 中,在 EmitInstruction() 中的指令循环时,插入如果满足 emitPseudoExpansionLowering() 时做调用,后者是由 tablegen 自动生成的一个函数,在 Cpu0GenMCPseudoLowering.inc 文件中定义。
尾调用优化是 Clang 支持的一种优化,需要使能至少 O1 优化级别。递归调用层次太深,即使使用了尾调用优化,但依然需要频繁的访问栈。使用循环来替代递归是一种不错的解决问题的方式,Clang 支持这种优化,会分析在尾调用满足循环替代递归的特性时做变换。
3.2 Cpu0MachineFunctionInfo.cpp
增加获取MachinePointerInfo的接口。
3.3 Cpu0SEISelLowering.cpp
继承一个isEligibleForTailCallOptimization函数,判断是否能做尾调用优化。
3.4 Cpu0FrameLowering.cpp/.h
这里实现了一个消除 call frame 伪指令 .cpload 和 .cprestore 的函数 eliminateCallFramePseudoInstr(),因为没有额外的事情要做,所以这里就直接 MBB.erase(I) 就可以了。
3.5 Cpu0InstrInfo.td
加入了一条链接并跳转指令 jalr 和 jsub,两者的差别是前者是将跳转地址保存到寄存器,后者是直接通过 label 传递。增加CALLSEQ_START和CALLSEQ_END。
CALLSEQ_START: 这个指令标志着函数调用序列的开始。它通常包含有关函数调用的信息,例如调用约定、参数传递方式等。CALLSEQ_START指令的存在可以帮助编译器在生成代码时正确地处理函数调用的相关信息。
CALLSEQ_END: 这个指令标志着函数调用序列的结束。它通常用于指示编译器在函数调用结束时应该执行的清理操作,例如恢复寄存器状态、处理返回值等。CALLSEQ_END指令的存在有助于编译器正确地结束函数调用序列并进行必要的清理工作。
3.6 Cpu0InstrInfo.cpp
将伪指令 ADJCALLSTACKDOWN, ADJCALLSTACKUP 注册到 Cpu0GenInstrInfo 对象中。
3.7 Cpu0MCInstLower.cpp/.h
这里定义了编译器输出的 call 的符号类型,新增了 Cpu0MCExpr::CEK_GOT_CALL。还增加了外部符号 MO_ExternalSymbol 的计算方式,全局符号 MO_GlobalSymbol 的代码已经在之前章节添加。
3.8 Cpu0MachineFunctionInfo.cpp/.h
新增了一些辅助函数和属性,这些函数和属性是继承自 TargetMachineFunction,我们希望在其他代码中调用到这些属性来辅助生成正确的代码。
3.9 Cpu0SEFrameLowering.cpp/.h
实现了一个函数 spillCalleeSavedRegisters(),用来定义 callee saved register 的 spill 动作,里边比较简单,就是遍历所有 callee saved register 并调用 storeRegToStackSlot() 函数将他们存入栈。需要注意 $lr 寄存器如果保存了返回地址,则不需要 spill。
3.10 MCTargetDesc/Cpu0AsmBackend.cpp
新建一个重定位类型 fixup_Cpu0_CALL16。
3.11 MCTargetDesc/Cpu0ELFObjectWriter.cpp
新建重定位类型的 Type,ELF::R_CPU0_CALL16。
3.12 MCTargetDesc/Cpu0Fixupkinds.h
还是这个重定位类型的声明。
3.13 MCTargetDesc/Cpu0MCCodeEmitter.cpp
修改 getJumpTargetOpValue(),对于 JSUB 指令,也发射重定位信息。
4. 结果
4.1 普通参数
int gI = 100;
int sum_i(int x1, int x2, int x3, int x4, int x5, int x6)
{
int sum = gI + x1 + x2 + x3 + x4 + x5 + x6;
return sum;
}
int main()
{
int a = sum_i(1, 2, 3, 4, 5, 6);
return a;
}sum_i:
...
addiu $sp, $sp, -8
lui $2, %got_hi(gI)
addu $2, $2, $gp
ld $2, %got_lo(gI)($2) # 加载全局变量
ld $2, 0($2)
ld $3, 8($sp) # 第一个参数
addu $2, $2, $3
ld $3, 12($sp) # 第二个参数
addu $2, $2, $3
ld $3, 16($sp) # 第三个参数
addu $2, $2, $3
ld $3, 20($sp) # 第四个参数
addu $2, $2, $3
ld $3, 24($sp) # 第五个参数
addu $2, $2, $3
ld $3, 28($sp) # 最后一个参数
addu $2, $2, $3
st $2, 4($sp)
ld $2, 4($sp) # 计算结果存入 $2
addiu $sp, $sp, 8
ret $lr
nop
...
main:
...
addiu $sp, $sp, -40
st $lr, 36($sp) # 调用 main 的返回地址
addiu $2, $zero, 0
st $2, 32($sp)
addiu $2, $zero, 6
st $2, 20($sp)
addiu $2, $zero, 5
st $2, 16($sp)
addiu $2, $zero, 4
st $2, 12($sp)
addiu $2, $zero, 3
st $2, 8($sp)
addiu $2, $zero, 2
st $2, 4($sp)
addiu $2, $zero, 1
st $2, 0($sp) # 保存这 6 个实参到栈
ld $6, %call16(sum_i)($gp)
jalr $6 # 这条指令会更新 $lr 并跳转到 $6 地址处
nop
st $2, 28($sp) # 从 $2 中取出 sum_i 的计算结果,存入 main 的栈
ld $2, 28($sp) # 再次取出计算结果存入 $2,因为 main 也是将计算结果直接返回
ld $lr, 36($sp) # 4-byte Folded Reload
addiu $sp, $sp, 40
ret $lr
nopllc -march=cpu0 -mcpu=cpu032I -cpu0-s32-calls=true -relocation-model=pic -filetype=asm ch8_1.ll -o ch8_1.s第二个要测试的参数是 -relocation-model=static,因为我们对于 PIC 模式和静态模式处理全局符号/外部符号的方式是不一样的。如果我们以静态模式编译得到的汇编中使用jsub代替了ld+jalr,其他都是类似的。
4.2 结构体参数
struct Date {
int year;
int month;
int day;
int hour;
int minute;
int second;
};
static struct Date gDate = {2021, 6, 18, 1, 2, 3};
struct Time {
int hour;
int minute;
int second;
};
static struct Time gTime = {2, 20, 30};
static struct Date getDate() {
return gDate;
}
static struct Date copyDateByVal(struct Date date) {
return date;
}
static struct Date* copyDateByAddr(struct Date* date) {
return date;
}
static struct Time copyTimeByVal(struct Time time) {
return time;
}
static struct Time* copyTimeByAddr(struct Time* time) {
return time;
}
int test_func_arg_struct() {
struct Time time1 = {1, 10, 12};
struct Date date1 = getDate();
struct Date date2 = copyDateByVal(date1);
struct Date *date3 = copyDateByAddr(&date1);
struct Time time2 = copyTimeByVal(time1);
struct Time *time3 = copyTimeByAddr(&time1);
return 0;
}test_func_arg_struct:
...
addiu $9, $sp, 80 # 调用函数中先设定 SRet
st $9, 0($sp)
ld $2, %got(getDate)($gp)
ori $6, $2, %lo(getDate)
jalr $6
nop
... # @copyDateByVal
copyDateByVal:
...
addiu $sp, $sp, -24
ld $2, 24($sp)
ld $3, 48($sp)
ld $4, 44($sp)
ld $5, 40($sp)
ld $6, 36($sp)
ld $7, 32($sp)
ld $8, 28($sp)
st $8, 0($sp)
st $7, 4($sp)
st $6, 8($sp)
st $5, 12($sp)
st $4, 16($sp)
st $3, 20($sp)
ld $3, 20($sp)
st $3, 20($2)
ld $3, 16($sp)
st $3, 16($2)
ld $3, 12($sp)
st $3, 12($2)
ld $3, 8($sp)
st $3, 8($2)
ld $3, 4($sp)
st $3, 4($2)
ld $3, 0($sp)
st $3, 0($2)
addiu $sp, $sp, 24
ret $lr
nop
...
copyDateByAddr:
...
ld $2, 0($sp)
ret $lr # 传指针的方式就非常简单了
nop4.3 字符串参数
int main() {
char str[81] = "Hello world";
char s[6] = "Hello";
return 0;
}我们还可以测试一下字符串初始化代码,因为一般情况下,LLVM 会为字符串初始化生成一条 memcpy 动作,在执行时需要配合 C 库中的 memcpy 完成初始化。不过 LLVM 为我们提供了一条优化,可以在字符串比较短时,使用 ld+st 来替代 call 一个 memcpy。
main:
...
addiu $sp, $sp, -120
st $lr, 116($sp) # 4-byte Folded Spill
st $9, 112($sp) # 4-byte Folded Spill
addiu $9, $zero, 0
st $9, 108($sp)
addiu $2, $zero, 81
st $2, 8($sp)
ld $2, %got($__const.main.str)($gp)
ori $2, $2, %lo($__const.main.str)
st $2, 4($sp)
addiu $2, $sp, 24
st $2, 0($sp)
ld $6, %call16(memcpy)($gp) # 调用memcpy进行字符串赋值
jalr $6
nop
ld $2, %got($__const.main.s)($gp)
ori $2, $2, %lo($__const.main.s) # s较短就可以将memcpy优化掉
lbu $3, 5($2)
lbu $4, 4($2)
shl $4, $4, 8
or $3, $4, $3
sh $3, 20($sp)
lbu $3, 3($2)
lbu $4, 2($2)
shl $4, $4, 8
or $3, $4, $3
lbu $4, 1($2)
lbu $2, 0($2)
shl $2, $2, 8
or $2, $2, $4
shl $2, $2, 16
or $2, $2, $3
st $2, 16($sp)
addu $2, $zero, $9
ld $9, 112($sp) # 4-byte Folded Reload
ld $lr, 116($sp) # 4-byte Folded Reload
addiu $sp, $sp, 120
ret $lr
nop4.4 浮点运算
int tryFloat() {
float a, b, c;
c = a + b;
return (int)c;
}
int tryDouble() {
double a, b, c;
c = a + b;
return (int)c;
}tryFloat:
...
addiu $sp, $sp, -24
st $lr, 20($sp) # 4-byte Folded Spill
ld $2, 16($sp)
ld $3, 12($sp)
st $3, 4($sp)
st $2, 0($sp)
jsub __addsf3 # double 类型浮点加法
nop
st $2, 8($sp)
ld $2, 8($sp)
st $2, 0($sp)
jsub __fixsfsi # double 类型浮点转 int
nop
ld $lr, 20($sp) # 4-byte Folded Reload
addiu $sp, $sp, 24
ret $lr
nop
...
tryDouble:
...
addiu $sp, $sp, -48
st $lr, 44($sp) # 4-byte Folded Spill
ld $2, 32($sp)
ld $3, 36($sp)
ld $4, 24($sp)
ld $5, 28($sp)
st $5, 12($sp)
st $4, 8($sp)
st $3, 4($sp)
st $2, 0($sp)
jsub __adddf3 # float 类型浮点加法
nop
st $3, 20($sp)
st $2, 16($sp)
ld $2, 16($sp)
ld $3, 20($sp)
st $3, 4($sp)
st $2, 0($sp)
jsub __fixdfsi # float 类型浮点转 int
nop
ld $lr, 44($sp) # 4-byte Folded Reload
addiu $sp, $sp, 48
ret $lr这里是编的静态重定位模式,pic模式也是类似的。我们现在还没有支持函数库,所以这里没有办法进一步做链接。
4.5 尾调用优化
int factorial(int x, int total) {
if (x == 1)
return total;
return factorial(x - 1, x * total);
}
int test_tailcall(int a) {
return factorial(a, 1);
}clang -target mips-unknown-linux-gnu -O1 -S -emit-llvm ch8_tailcall.c -o ch8_tailcall.ll
llc -march=cpu0 -mcpu=cpu032I -relocation-model=static -filetype=asm -enable-cpu0-tail-calls -stats ch8_tailcall.ll -o ch8_tailcall.s触发尾调用优化后,会生成 jmp 指令来调用被调用函数,jmp 指令只会跳转,而不会生成 jsub 指令。jmp 跳转到被调用函数后,被调用函数采用循环展开替代递归调用,并在递归结束后,直接返回到调用函数的 $lr,也就是直接返回调用函数应该返回的地方。因为我们还设置了一个统计参数,所以还可以查看打印的统计数据。
当clang使用O2以上优化级别时,我们能够看到递归调用直接被优化成了循环迭代了,这也是尾调用的一个优化方案。
define dso_local i32 @factorial(i32 signext %0, i32 signext %1) local_unnamed_addr #0 {
%3 = icmp eq i32 %0, 1
br i1 %3, label %10, label %4
4: ; preds = %2, %4
%5 = phi i32 [ %8, %4 ], [ %1, %2 ]
%6 = phi i32 [ %7, %4 ], [ %0, %2 ]
%7 = add nsw i32 %6, -1
%8 = mul nsw i32 %5, %6
%9 = icmp eq i32 %7, 1
br i1 %9, label %10, label %4
10: ; preds = %4, %2
%11 = phi i32 [ %1, %2 ], [ %8, %4 ]
ret i32 %11
}