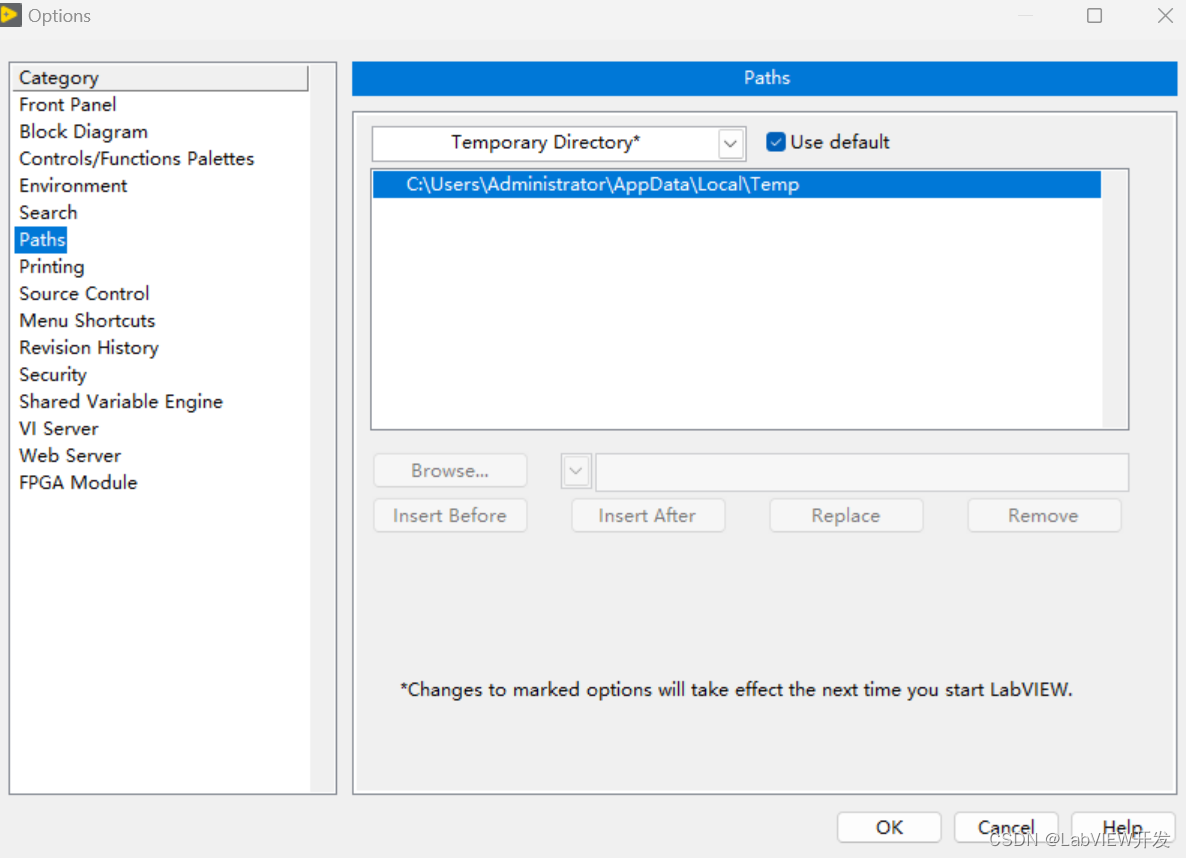
单一文件下,相关主题的共128张字段结构相似的表,对一种需求用Excel手工编辑相当麻烦,下面介绍一种python做自动化报表示例及代码流程。
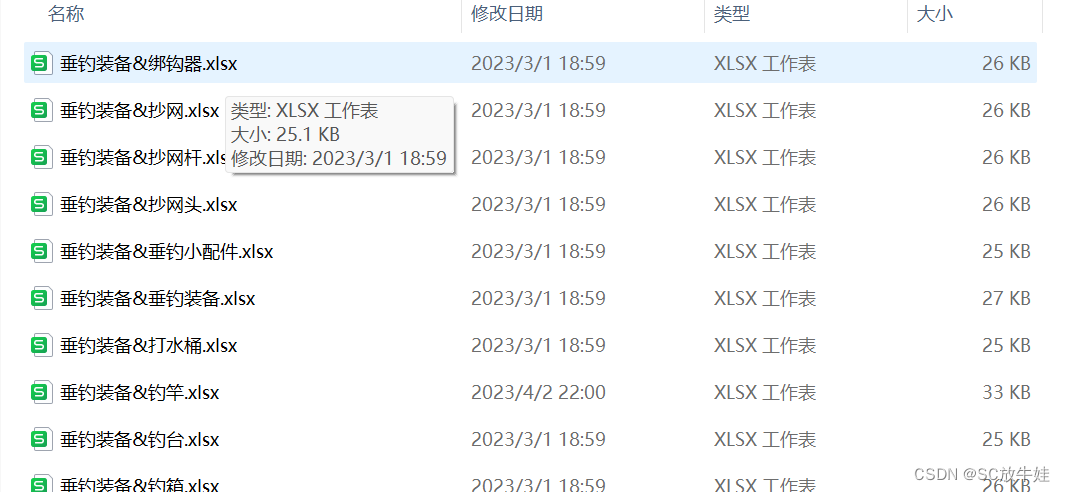
每张表均有相同的字段结构,因此可对该文件下所有表格同时操作,大大提高了计算效率。
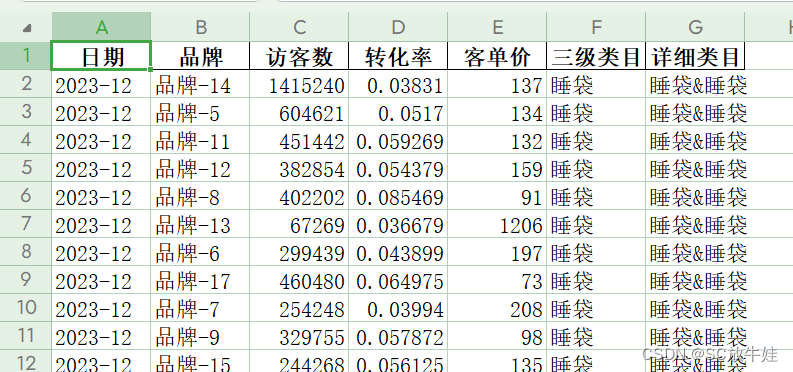
报表案例
import pandas as pd
import os1、 案例背景
筛选出2023年销售额总额的品牌以及对应的销售额。
专注于户外运动的巨头公司。公司旗下有20个品牌,每个品牌都涉及128个类目(行业)。
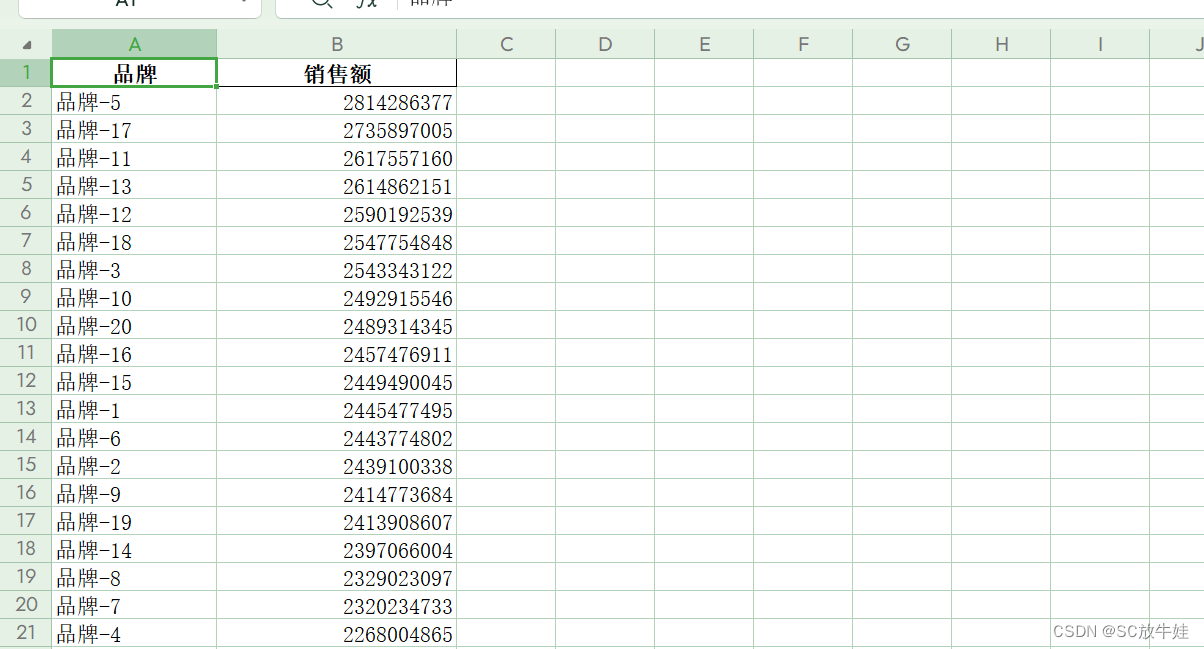
做一张汇总报表,包含2023年销售总额排名前五的品牌以及对应的销售额。
业务部门的同事总共发来了128张表。
每张表里是一个细分行业的数据。
每张表都以月的维度,从2022年1月到2023年12月,时间跨度为2年,记录着每个品牌的日期、访客数、客单价、转化率、所属类目(细分行业)等数据。
2、 单个表格
导入并预览数据
name = '睡袋&睡袋.xlsx'
data_dir = '/root/data/'
df = pd.read_excel(data_dir+name,parse_dates=[0])
df.head()日期筛选
# 转换为时间列
df['日期']= pd.to_datetime(df['日期'])
df.info()
# 提取2023年数据
df['年份'] = df['日期'].dt.year
df_2023 = df[df['年份']==2023]
df_2023数据计算
# 计算每个表的销售额
df_2023['销售额'] = df_2023['访客数']*df_2023['转化率']*df_2023['客单价']
# 统计每个品牌的全年销售额
df_sum = df_2023.groupby('品牌')['销售额'].sum().reset_index()
# name ='睡袋睡袋,xlsx'
df_sum['行业']=name.replace( '.xlsx','')3、批量处理(总代码块)
# 导包
import pandas as pd
import os
# 定义路径
data_dir ='D:/Yuanman/day01/02_代码/data/report/'
# 创建一个空白的DF用来保存结果
result_df = pd.DataFrame()
# 循环遍历文件夹
for name in os.listdir(data_dir):
# 读取文件
df = pd.read_excel(data_dir + name,parse_dates=[0])
# 转化为日期格式
df['日期']= pd.to_datetime(df['日期'])
# 提取年份添加为新列
df['年份']= df['日期'].dt.year
# 提取2023年的数据
df_2023 = df[df['年份']==2023]
# 计算每个表的销售额
df_2023['销售额'] = df_2023['访客数']*df_2023['转化率']*df_2023['客单价']
# 统计每个品牌的全年销售额
df_sum = df_2023.groupby('品牌')['销售额'].sum().reset_index()
#name ='睡袋睡袋,xlsx'
df_sum['行业']=name.replace( '.xlsx','')
# 拼接表作为结果表
result_df = pd.concat([result_df,df_sum])
# 将结果表再次按品牌分类求总销售额 并降序
final_df = result_df.groupby('品牌')['销售额'].sum().reset_index().sort_values('销售额',ascending= False)
# 保存到某位置
final_df.to_excel('G:/卧槽.xlsx',index=False)运行后则会在指定路径下创建128张结果合并后的表,也可以实现指定路径,在结尾调用即可。

对应结果显示以各品牌分组的销售总额,如下图显示。