人工智能对聊天机器人训练数据的“淘金热”可能会耗尽人类编写的文本
 像ChatGPT这样的人工智能系统可能很快就会耗尽让它们变得更聪明的东西——人们在网上写下和分享的数万亿字。
像ChatGPT这样的人工智能系统可能很快就会耗尽让它们变得更聪明的东西——人们在网上写下和分享的数万亿字。
Epoch AI研究集团发布的一项新研究预计,科技公司将在大约十年之交——2026年至2032年之间的某个时候——耗尽人工智能语言模型公开可用的训练数据。
该研究的作者之一塔梅·贝西罗格鲁(Tamay Besiroglu)将其与耗尽有限自然资源的“字面上的淘金热”相提并论,他表示,一旦人工智能领域耗尽了人类生成的文字储备,它可能会面临保持目前发展速度的挑战。
在短期内,像chatgpt制造商OpenAI和谷歌这样的科技公司正在竞相获得高质量的数据源,有时还会花钱购买它们的人工智能大型语言模型——例如,通过签署协议,利用来自Reddit论坛和新闻媒体的稳定的句子流。
从长期来看,不会有足够多的新博客、新闻文章和社交媒体评论来维持目前的人工智能发展轨迹,这将给企业带来压力,迫使它们利用现在被视为私人的敏感数据——比如电子邮件或短信——或者依赖聊天机器人自己提供的不太可靠的“合成数据”。
Besiroglu说:“这是一个严重的瓶颈。“如果你开始触及数据量的限制,那么你就不能再有效地扩展你的模型了。扩大模型规模可能是扩大其能力和提高产出质量的最重要方式。
”两年前,在ChatGPT首次亮相之前不久,研究人员在一份工作论文中首次做出了他们的预测,预测高质量文本数据将于2026年即将停止。自那以后,很多事情都发生了变化,包括新技术使人工智能研究人员能够更好地利用他们已有的数据,有时还会对同一来源进行多次“过度训练”。
但也有限制,经过进一步的研究,Epoch现在预计在未来两到八年的某个时候,公共文本数据将会耗尽。
该团队的最新研究经过同行评审,并将于今年夏天在奥地利维也纳举行的国际机器学习会议上发表。Epoch是一家非营利机构,由总部位于旧金山的Rethink Priorities主办,由有效利他主义的支持者资助。有效利他主义是一个慈善运动,为减轻人工智能最坏的风险投入了大量资金。
Besiroglu说,人工智能研究人员在十多年前就意识到,积极扩展两个关键因素——计算能力和大量互联网数据存储——可以显著提高人工智能系统的性能。
LLM训练数据集正在增长
自2017年以来,用于训练关键机器学习模型的数据集的规模迅速增加。
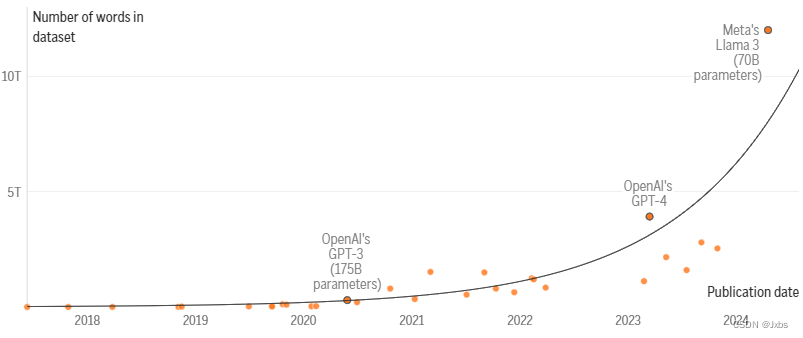
根据Epoch的研究,输入人工智能语言模型的文本数据量每年增长约2.5倍,而计算量每年增长约4倍。Facebook的母公司Meta平台最近声称,他们即将推出的最大版本的羊驼3模型(尚未发布)已经接受了多达15万亿个代币的训练,每个代币可以代表一个单词的一部分。
但是数据瓶颈到底有多少值得担心,这是有争议的。
“我认为重要的是要记住,我们不一定需要训练越来越大的模型,”多伦多大学(University of Toronto)计算机工程助理教授、非营利组织矢量人工智能研究所(Vector Institute for Artificial Intelligence)研究员尼古拉斯·佩珀诺特(Nicolas Papernot)说。
Papernot没有参与Epoch的研究,他说,构建更熟练的人工智能系统也可以来自于更专门于特定任务的训练模型。但他担心,在生成式人工智能系统正在产生的相同输出上进行训练,会导致性能下降,被称为“模型崩溃”。
在人工智能生成的数据上进行训练“就像你复印一张纸,然后再复印一份复印件。你丢失了一些信息,”Papernot说。不仅如此,Papernot的研究还发现,它可以进一步编码已经融入信息生态系统的错误、偏见和不公平。
如果真正的人工句子仍然是一个关键的人工智能数据源,那么那些最受欢迎的数据库——像Reddit和维基百科这样的网站,以及新闻和图书出版商——的管理者们就不得不认真思考它们是如何被使用的。
运营维基百科的维基媒体基金会(Wikimedia Foundation)首席产品和技术官赛琳娜•德克尔曼(Selena Deckelmann)开玩笑说:“也许你不会砍掉每座山的山顶。”“现在,我们正在就人类创造的数据进行自然资源对话,这是一个有趣的问题。我不应该嘲笑它,但我确实觉得它有点神奇。”
虽然有些人试图将他们的数据与人工智能训练隔离开来——通常是在这些数据已经被无偿获取之后——但维基百科对人工智能公司如何使用其志愿者撰写的条目几乎没有限制。尽管如此,Deckelmann表示,她希望继续有激励人们继续贡献,特别是在大量廉价和自动生成的“垃圾内容”开始污染互联网的情况下。
她说,人工智能公司应该“关注人类生成的内容如何继续存在,以及如何继续被访问”。
Epoch的研究表明,从人工智能开发者的角度来看,雇佣数百万人来生成人工智能模型所需的文本,“不太可能是”提高技术性能的“经济方式”。
随着OpenAI开始训练下一代GPT大型语言模型,该公司首席执行官萨姆·奥特曼(Sam Altman)上个月在联合国的一次活动上告诉听众,该公司已经在进行“生成大量合成数据”的试验。
“我认为你需要的是高质量的数据。有低质量的合成数据。有低质量的人类数据,”奥特曼说。但他也对过度依赖合成数据而不是其他技术方法来改进人工智能模型持保留态度。
奥特曼说:“如果训练一个模型的最好方法是生成一千万亿的合成数据,然后把它们反馈进去,那就太奇怪了。”“从某种程度上说,这似乎效率低下。”