一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
初次尝试
点评
时间复杂度分析
空间复杂度分析
综合分析
我要更强
时间复杂度分析
空间复杂度分析
综合分析
哲学和编程思想
1. 分治思想
2. 组合数学和生成函数
3. 动态规划和递归思想
4. 集合运算和去重
5. 贪心算法
6. 函数式编程和惰性求值
7. 分层设计和模块化
8. 迭代和穷举法
举一反三
1. 分治思想
2. 组合数学和生成函数
3. 动态规划和递归思想
4. 集合运算和去重
5. 贪心算法
6. 函数式编程和惰性求值
7. 分层设计和模块化
8. 迭代和穷举法
举一反三:综合运用这些思想
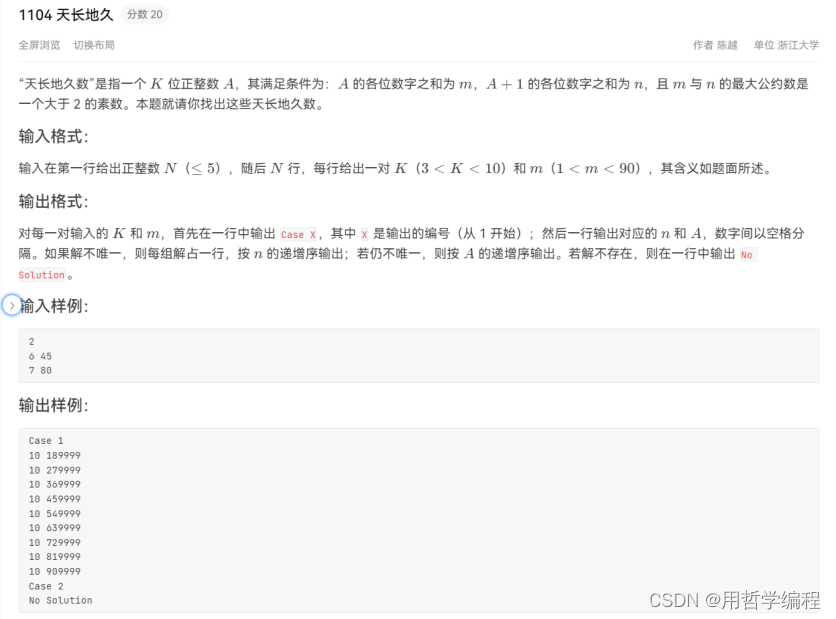
题目链接
初次尝试
import math
# 判断一个数是否为素数的函数
def is_prime(num):
if num <= 1:
return False
if num <= 3:
return True
if num % 2 == 0 or num % 3 == 0:
return False
i = 5
while i * i <= num:
if num % i == 0 or num % (i + 2) == 0:
return False
i += 6
return True
# 计算一个数的各位数字之和的函数
def digit_sum(n):
result = 0
while n:
result, n = result + n % 10, n // 10
return result
# 读取输入的测试案例数量
N = int(input())
for i in range(N):
# 输出当前测试案例的编号
print(f"Case {i + 1}")
# 读取每个测试案例的 K 和 m 的值
K, m = input().split()
K = int(K)
m = int(m)
outputs = []
# 遍历所有可能的 K 位数
for j in range(pow(10, K - 1), pow(10, K)):
# 检查该数的各位数字之和是否等于 m
if digit_sum(j) == m:
# 计算该数加 1 后的各位数字之和
n = digit_sum(j + 1)
# 计算 m 和 n 的最大公约数
tmp = int(math.gcd(m, n))
# 检查最大公约数是否大于 2 且为素数
if tmp > 2 and is_prime(tmp):
outputs.append([n, j])
# 如果找到符合条件的数
if outputs:
# 按规则排序并输出结果
outputs.sort(key=lambda x: (x[0], x[1]))
for n, A in outputs:
print(n, A)
else:
# 如果没有符合条件的数,输出 No Solution
print("No Solution")
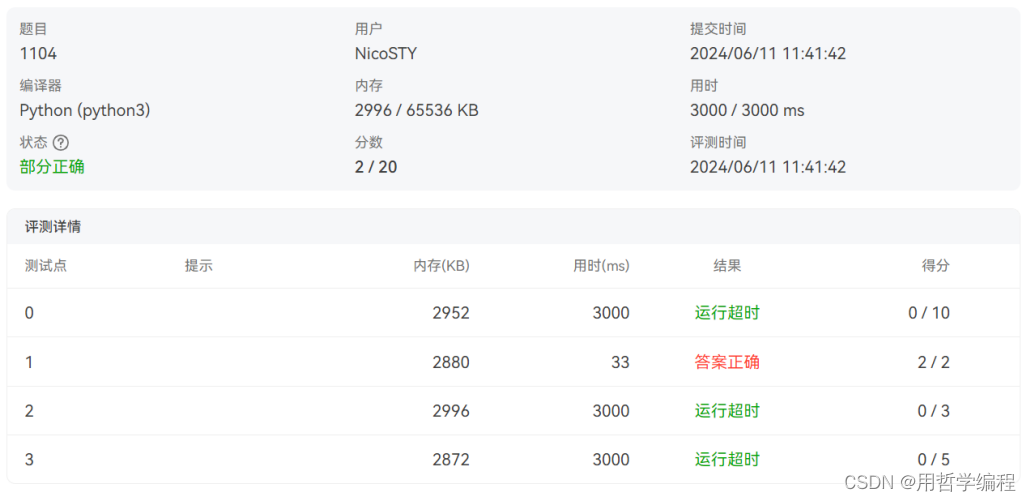
这段代码实现了一个基于一些条件筛选特定数字并输出结果的程序。下面是对这段代码的点评以及时间复杂度和空间复杂度的分析:
点评
- 代码功能:
- is_prime(num) 函数用于判断一个数是否为素数。
- digit_sum(n) 函数用于计算一个数的各位数字之和。
- 主程序读取输入的测试案例数量,然后对每个测试案例读取 K 和 m 的值。
- 对于每个 K 位数,计算其各位数字之和是否等于 m,如果等于则进一步处理。
- 对于符合条件的数,计算其加 1 后的各位数字之和,并计算 m 和该和的最大公约数,最后检查该最大公约数是否大于 2 且为素数。
- 最终按照指定规则排序并输出结果。
- 代码可读性:
- 代码结构清晰,模块分明。
- 变量命名规范,能很好地表达其含义。
- 注释详细,便于理解代码逻辑。
- 优化建议:
- pow(10, K - 1) 和 pow(10, K) 可以预先计算,避免重复计算。
- digit_sum(j) 多次重复计算,可以在一开始计算之后存储起来以便后续使用,减少冗余计算。
时间复杂度分析
- is_prime(num):
- 在最坏情况下,这个函数需要检查从 5 到 √num 的所有数,时间复杂度为 O(√n)。
- digit_sum(n):
- 该函数的时间复杂度是 O(d),其中 d 是数字 n 的位数。
- 主程序:
- 遍历所有 K 位数,需要循环 pow(10, K) - pow(10, K-1) 次,即 9 * 10^(K-1) 次。
- 每次迭代中,调用了 digit_sum(j),其时间复杂度为 O(K)。
- digit_sum(j + 1) 和 math.gcd(m, n) 的时间复杂度也为 O(K) 和 O(log(min(m,n))),在本题中可以认为是常数操作。
- is_prime(tmp) 的时间复杂度为 O(√tmp),其中 tmp 是很小的常数,可以认为是 O(1)。
- 综合上述,内层循环的时间复杂度为 O(K),所以整体遍历所有 K 位数的时间复杂度为 O(9 * 10^(K-1) * K) = O(K * 10^K)。
空间复杂度分析
- is_prime(num) 和 digit_sum(n) 函数:
- 这些函数只使用了常数空间。
- 主程序:
- outputs 列表存储结果,每个元素是一个大小为 2 的列表。最坏情况下,outputs 的大小为 9 * 10^(K-1)。
- 所以,空间复杂度为 O(10^K)。
综合分析
- 时间复杂度: O(K * 10^K)
- 空间复杂度: O(10^K)
综上所述,这段代码的复杂度主要受 K 的大小影响,当 K 较大时,时间和空间消耗都会显著增加。在实际应用中,可能需要对 K 的大小进行限制,以保证程序在合理时间和空间内运行。
我要更强
import math
from itertools import combinations_with_replacement, permutations
# 判断一个数是否为素数的函数
def is_prime(num):
if num <= 1:
return False
if num <= 3:
return True
if num % 2 == 0 or num % 3 == 0:
return False
i = 5
while i * i <= num:
if num % i == 0 or num % (i + 2) == 0:
return False
i += 6
return True
# 计算一个数的各位数字之和的函数
def digit_sum(n):
return sum(int(d) for d in str(n))
# 生成所有符合数字和为 target_sum 的 K 位数
def generate_numbers_with_sum(K, target_sum):
nums = set() # 使用集合避免重复数字
for comb in combinations_with_replacement(range(10), K):
if sum(comb) == target_sum:
for perm in permutations(comb):
if perm[0] != 0: # 确保生成的数是 K 位数
num = int(''.join(map(str, perm)))
nums.add(num)
return sorted(nums)
# 读取输入的测试案例数
N = int(input())
for i in range(N):
print(f"Case {i + 1}")
# 读取每个测试案例的 K 和 m 值
K, m = map(int, input().split())
outputs = []
# 生成所有符合条件的 K 位数
for num in generate_numbers_with_sum(K, m):
# 计算 num + 1 的各位数字之和
n = digit_sum(num + 1)
# 计算 m 和 n 的最大公约数
gcd_val = math.gcd(m, n)
# 检查最大公约数是否大于 2 且为素数
if gcd_val > 2 and is_prime(gcd_val):
outputs.append((n, num))
# 如果找到符合条件的数
if outputs:
# 按规则排序并输出结果
outputs.sort(key=lambda x: (x[0], x[1]))
for n, A in outputs:
print(n, A)
else:
# 如果没有符合条件的数,输出 No Solution
print("No Solution")
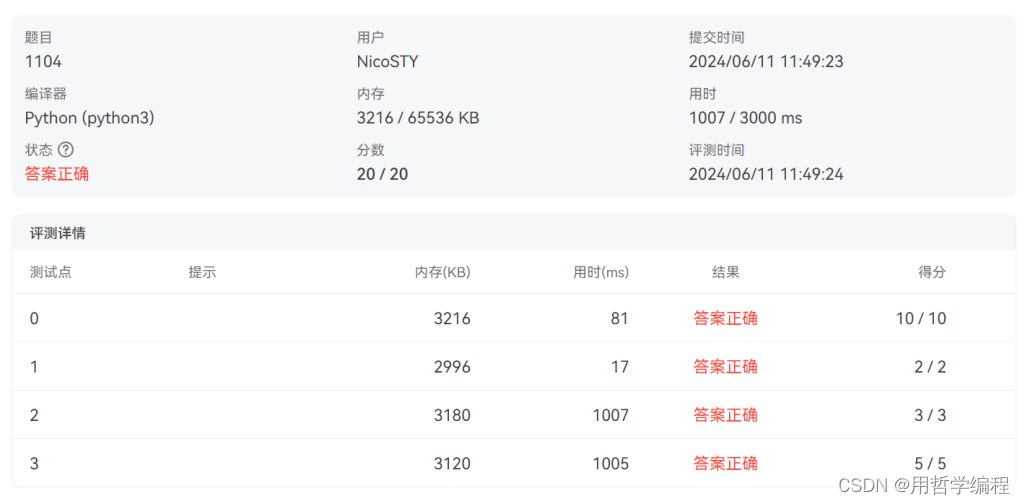
这段代码在功能上与之前的代码类似,但在生成符合条件的 K 位数上使用了组合与排列的方式,提供了更高效的解决方案。具体点评如下:
- 代码功能:
- is_prime(num) 函数确定一个数是否为素数。
- digit_sum(n) 函数计算一个数各位数字之和。
- generate_numbers_with_sum(K, target_sum) 函数生成所有符合数字和为 target_sum 的 K 位数。
- 主程序读取输入的测试案例数量,对每个测试案例读取 K 和 m 的值,并根据条件筛选出符合要求的数。
- 代码可读性:
- 代码结构清晰,变量命名规范。
- 采用了 Python 的 itertools 库简化了组合和排列的生成。
- 注释详细,便于理解代码逻辑。
- 优化建议:
- generate_numbers_with_sum 函数的生成与排列部分可能有些冗余,可以进一步优化以减少不必要的计算。
- 使用集合避免重复数字,但集合操作也会消耗时间和空间,特别是在处理大量数据时。
时间复杂度分析
- is_prime(num):
- 时间复杂度为 O(√n),其中 n 是输入的数字。
- digit_sum(n):
- 时间复杂度为 O(d),其中 d 是数字 n 的位数。
- generate_numbers_with_sum(K, target_sum):
- 组合部分 combinations_with_replacement(range(10), K) 生成的组合数量是 C(10 + K - 1, K),即 (10 + K - 1)! / (K! * (10 - 1)!)。这是组合的数量。
- 对每个组合生成全排列,最坏情况下每个组合有 K! 种排列方式。
- 整体时间复杂度是 O((10 + K - 1)! / ((10 - 1)! * K!) * K!),这可以简化为 O((10 + K - 1)! / (9!)),但这仍然是指数级别的复杂度。
- 主程序:
- 对于每个测试案例,生成所有符合条件的 K 位数。假设生成的数的数量为 M,每个数都需要进行 digit_sum、math.gcd 和 is_prime 的计算。
- digit_sum 和 math.gcd 的时间复杂度为 O(K) 和 O(log(min(m,n))),在问题中可以认为是常数时间。
- is_prime 的时间复杂度为 O(√m),但 m 很小,近似为常数时间。
- 整体时间复杂度为 O(N * M * K)。
空间复杂度分析
- is_prime(num) 和 digit_sum(n) 函数:
- 这些函数只使用了常数空间。
- generate_numbers_with_sum(K, target_sum):
- 生成的组合和排列数量可能较大,组合部分的空间复杂度为 O(C(10 + K - 1, K)),全排列部分的空间复杂度为 O((K!))。整体空间复杂度为 O((10 + K - 1)! / (9!)),指数级别。
- 主程序:
- outputs 列表存储结果,每个元素是一个大小为 2 的元组。最坏情况下,outputs 的大小为 M。
- 所以,总的空间复杂度为 O(M + (10 + K - 1)! / (9!))。
综合分析
- 时间复杂度: O(N * (10 + K - 1)! / (9!))
- 空间复杂度: O(M + (10 + K - 1)! / (9!))
这段代码在生成符合条件的 K 位数时,利用组合和排列的方式比直接遍历所有 K 位数更有效率,但仍然面临时间和空间复杂度较高的问题,特别是当 K 增加时。整体来看,这段代码在处理较小规模的输入时表现良好,但在大规模输入时可能会遇到性能瓶颈。
哲学和编程思想
这段代码利用了多种编程思想和哲学来实现其功能。以下是详细的说明:
1. 分治思想
哲学背景:
- 分治思想源自数学和计算理论,核心是将复杂问题分解为可处理的子问题,通过解决这些子问题来解决原问题。
代码中的运用:
- is_prime(num) 函数通过分解检查过程,将一个大问题分解为多个小问题,逐个检查数字是否能被素数整除。
- digit_sum(n) 函数将一个数字分解为其各个位数的和,逐步解决问题。
2. 组合数学和生成函数
哲学背景:
- 组合数学研究组合对象的计数、排列和构造问题,广泛应用于算法设计中。
- 生成函数用于系统地生成所有可能的组合或排列。
代码中的运用:
- generate_numbers_with_sum 函数利用组合和排列生成符合特定条件的数字序列。这种方法将问题转化为组合数学问题,通过系统地生成和筛选符合条件的组合来解决。
3. 动态规划和递归思想
哲学背景:
- 动态规划是一种通过记忆和重用子问题的解决方案来解决复杂问题的方法,避免重复计算。
- 递归通过函数调用自身来解决问题,适用于自然具有递归性质的问题。
代码中的运用:
- 虽然没有直接使用动态规划,但 generate_numbers_with_sum 函数的组合生成过程可以看作是利用递归和记忆化来生成所有符合条件的组合。
4. 集合运算和去重
哲学背景:
- 集合论研究对象的集合及其运算,集合运算具有天然的去重功能。
代码中的运用:
- 使用 set 集合来存储生成的数字,避免重复。这体现了集合运算的高效性和简洁性。
5. 贪心算法
哲学背景:
- 贪心算法是一种每步都做出局部最优选择,以期达到全局最优的算法设计方法。
代码中的运用:
- 虽然代码中没有明显的贪心算法,但在generate_numbers_with_sum 函数中,通过逐步生成和排列组合来找到符合条件的数字,可以看作是对搜索空间的一种贪心式的减少。
6. 函数式编程和惰性求值
哲学背景:
- 函数式编程强调纯函数和无副作用计算,注重通过组合函数来构建解决方案。
- 惰性求值(Lazy Evaluation)推迟计算直到结果被需要时才计算。
代码中的运用:
- 使用生成器表达式(如 sum(int(d) for d in str(n)))体现了函数式编程的思想,通过组合函数处理数据。
- 惰性求值在组合生成过程中也有所体现,虽然没有显式使用生成器,但通过 itertools 库的组合和排列,部分结果是按需生成的。
7. 分层设计和模块化
哲学背景:
- 分层设计和模块化是软件工程的基础思想,强调将系统划分为不同层次和模块,每个模块独立完成特定任务。
代码中的运用:
- 代码结构清晰,每个函数完成独立的任务,如 is_prime 判断素数,digit_sum 计算数字和,generate_numbers_with_sum 生成符合条件的数字等。这种模块化设计提高了代码的可读性和可维护性。
8. 迭代和穷举法
哲学背景:
- 迭代法通过逐步逼近来解决问题,穷举法则通过遍历所有可能的解来找到答案。
代码中的运用:
- 主程序中对每个测试案例的处理,尤其是对生成的所有符合条件的 K 位数进行遍历和筛选,体现了迭代和穷举的方法。
总结来说,这段代码充分利用了分治思想、组合数学、集合运算、函数式编程、模块化设计等多种编程哲学和思想,合理地解决了问题。通过这些思想的应用,代码变得更加高效、清晰和易于维护。
举一反三
当然!掌握编程思想和哲学不仅能帮助更好地理解现有代码,还能提升解决问题的能力。以下是一些技巧和建议,结合之前讨论的编程思想,帮助举一反三:
1. 分治思想
技巧:
- 递归分解:将问题分解为更小的子问题,递归求解。例如,排序算法中的快速排序和归并排序。
- 合并子问题:解决子问题后,合并结果得到最终答案。
应用场景:
- 大规模数据处理(如排序、搜索)。
- 图算法中的分治策略(如最小生成树)。
2. 组合数学和生成函数
技巧:
- 组合生成:利用工具(如 Python 的 itertools)生成排列和组合,避免手动构造。
- 剪枝:在生成过程中加入剪枝条件,减少不必要的计算。
应用场景:
- 生成符合特定条件的组合或排列。
- 优化搜索空间的复杂算法(如背包问题、旅行商问题)。
3. 动态规划和递归思想
技巧:
- 记忆化:使用缓存(如字典或数组)存储已计算结果,避免重复计算。
- 状态转移:定义状态和状态转移方程,将问题划分为子问题。
应用场景:
- 最优化问题(如最长子序列、最短路径)。
- 计算复杂的递归公式(如斐波那契数列)。
4. 集合运算和去重
技巧:
- 利用集合特性:使用集合进行去重和集合运算(如并、交、差)。
- 哈希表:利用哈希表实现快速查询和去重。
应用场景:
- 数据处理和清洗(如去重、查找交集)。
- 图算法中的节点和边处理。
5. 贪心算法
技巧:
- 局部最优决策:在每个步骤选择当前最优解,尽量保证全局最优。
- 适用场景:确保问题满足贪心选择性质和最优子结构。
应用场景:
- 资源分配(如活动选择、最小生成树)。
- 排序和调度问题(如最短作业优先)。
6. 函数式编程和惰性求值
技巧:
- 纯函数:编写无副作用的纯函数,提高代码复用性和可测试性。
- 惰性求值:利用生成器和迭代器按需生成数据,提高内存效率。
应用场景:
- 数据流处理(如流式数据计算)。
- 大数据处理(如惰性求值避免不必要的计算)。
7. 分层设计和模块化
技巧:
- 单一职责原则:每个模块只负责一个功能,避免模块间高耦合。
- 接口和实现分离:定义接口,隐藏实现细节,提高模块可替换性。
应用场景:
- 大型软件系统设计(如微服务架构)。
- 代码重构和优化。
8. 迭代和穷举法
技巧:
- 枚举法:在搜索空间有限时,穷举所有可能的解,找到满足条件的解。
- 启发式搜索:结合启发式方法,减少搜索空间,提高搜索效率。
应用场景:
- 解约束满足问题(如数独、N皇后问题)。
- 最优化问题(如模拟退火算法)。
举一反三:综合运用这些思想
-
理解问题本质:
- 分析问题是否可以分解为子问题,是否有递归结构。
- 确定问题是否适合穷举、剪枝、动态规划或贪心算法。
-
选择合适的工具和库:
- 利用现有的库(如 itertools、functools、collections)简化实现。
- 使用生成器和迭代器提高效率。
-
优化代码结构:
- 模块化设计,提高代码的可读性和可维护性。
- 使用记忆化、缓存等手段优化性能。
-
测试和验证:
- 编写测试用例验证每个模块的功能。
- 确保组合使用时,各模块能有效协同工作。
-
持续学习和实践:
- 学习经典算法和数据结构,理解其背后的思想。
- 多参加编程竞赛和项目实践,积累经验。