日志及审计 01:日志
以下内容是来自于我的知识星球:《PostgreSQL 小课》专栏,有需要可以关注一下
PostgreSQL 提供了非常丰富的日志基础设施。能够检查日志是每个 DBA 的关键技能——日志提供了关于集群过去的操作、当前正在进行的操作以及发生了什么的提示和信息。本章将介绍 PostgreSQL 日志配置的基础知识,为我们提供如何配置日志机制以获取有关集群活动的所需信息的说明。日志可以手动分析,但 DBA 通常还会利用自动化工具,以洞察更广泛的集群活动。与日志相关的话题是审计,它是跟踪谁对哪些数据做了什么的能力。一个良好的审计系统也可以帮助管理员识别数据库中发生了什么。
在本章中,我们将介绍如下主题:
- 日志介绍
- 使用 pgBadger 抽取日志信息
日志介绍
就像许多其他服务和数据库一样,PostgreSQL 提供了自己的日志基础设施,以便管理员可以检查守护进程正在做什么以及数据库系统的当前状态。虽然日志对于数据和数据库活动并不是必不可少的,但它们代表了关于整个系统中发生的事情的非常重要的部分,并且通过日志提供的重要线索,可以帮助管理员采取相应的动作。
PostgreSQL 有一个非常灵活和可配置的日志基础设施,允许不同的日志配置、轮转、归档和后续分析。
日志以文本形式存储,以便可以使用常见的日志分析工具进行分析,包括操作系统实用程序,如 grep,sed 和文本编辑器。
在默认的安装中,日志被包含在 PGDATA 目录的特定子文件夹中,但正如我们将在以下小节中看到的,我们可以自由地将日志移动到操作系统下面的任何位置。
在数据库中发生的每个事件都会在日志中的单独一行文本中记录下来,这是一个重要且有用的方面,特别是当我们想要使用基于行的工具(例如常见的 Unix 命令grep)来分析日志时。当然,将大量信息写入日志也有缺点;它需要系统资源,并且可能填满存放日志的存储空间。因此,根据集群的目的,管理日志基础设施非常重要,只记录可以用于后续分析的最少信息量即可。
[!WARNING]
如果我们配置日志的方式不正确,日志可能会迅速填满我们的磁盘存储空间,因此我们应该确保集群产生的日志不应超过系统的处理能力。
遵循常见的 Unix 哲学,PostgreSQL 允许我们将日志发送到一个名为 syslog 的外部组件。另外一个方式是 PostgreSQL 也有自己的组件,称为“日志收集器”,用于存储日志。
实际上,在负载较重的情况下,Syslog 集中收集器可能会丢弃日志条目,而 PostgreSQL 日志收集器明确设计为不丢失任何一条日志信息。因此,通常情况下,PostgreSQL 附带的日志收集器是跟踪日志的首选方式,这样一旦我们开始分析日志,我们就可以确保集群产生的所有信息都不会丢失。
PostgreSQL 的日志记录是通过主集群配置中的可调参数进行配置的,即 postgresqlconf 文件。在接下来的小节中,我们将了解到 PostgreSQL 的日志配置,并且我们将看到如何调整日志以满足我们的需求。
日志存放哪里
配置日志系统的第一步是决定在哪里以及如何存储文本日志。控制日志系统的主要参数是 log_destination,它可以取以下一个或多个值:
stderr意味着集群日志将被发送到 postmaster 进程的标准错误输出,通常意味着它们将出现在启动集群的控制台上。syslog意味着日志将被发送到外部的 syslog 组件。csvlog意味着日志将以逗号分隔的形式存储,有助于日志的自动分析(稍后详细介绍)。jsonlog意味着日志将以 JSON 格式的形式存储,这是另一种非常适用于日志自动分析的格式(稍后会详细介绍)。eventlog是仅在 Windows 平台上可用的特定组件,用于收集大量服务的日志。
可以设置多个日志目标,以便存储不同目的地及类型的日志。
另一个日志基础设施的重要设置是 log_collector,它是一个布尔值,会触发一个进程(称为日志收集器),该进程会捕获所有发送到标准错误的日志并将其存储在我们想要的位置。简而言之,设置 log_destination = stderr 将强制 PostgreSQL 将所有日志消息发送到标准错误,这是启动服务的控制台。由于守护程序在后台启动,因此不会附加控制台,而且很少有人愿意保持控制台打开以查看屏幕上滚动的日志消息。因此,logging_collector = on 启用了 PostgreSQL 日志捕获进程,该进程旨在读取所有在标准错误上产生的消息并将其发送到适当的目标位置。通常,目标位置可以是文本文件、CSV 文件或其他类型文件。因此,log_destination 决定了 PostgreSQL 将在哪里输出日志消息,而 logging_collector 则会启动一个特定进程来捕获这些已发出的日志并将其发送到其他地方。需要注意的是,一些日志目标也需要启用 logging_collector:cvslog 和 jsonlog 需要启用 logging_collector。
前面的两个参数有些相互依赖:我们需要选择将 PostgreSQL 产生的日志发送到哪里(log_destination),并且如果我们需要将它们发送到标准错误或自定义格式(如 csvlog),则需要启用一个专用进程(logging_collector 值)来捕获任何日志条目并将其存储在磁盘上。那么我们的日志配置通常要配置以下内容:
log_destination = 'stderr'
logging_collector = on
这里,第一行告诉集群将产生的日志发送到标准错误,它们将由一个专用进程——日志收集器进行管理和存储。
在本节的其余部分中,我们将集中讨论日志收集器的配置。日志收集器可以配置为将日志放置在我们所需的目录中,按我们的要求命名日志文件,并自动进行日志轮转。日志轮转是每个日志系统中非常常见的功能,意味着一旦单个日志文件增长到指定大小,或者经过足够的时间,该文件日志将被关闭,然后创建一个新的(具有不同名称的)日志文件。例如,我们可以决定在单个文件达到 100 MB 或每 2 天时自动轮转我们的日志文件:第一个条件发生时触发轮转,以便 PostgreSQL 至少每 2 天或每 100 MB 的文本信息生成一个不同的日志文件。
[!TIP]
日志轮转很有用,因为它允许我们生成较小的日志文件,可以限定在特定的时间段内。一方面,这会将日志分散到多个(可能很小的)文件中;另一方面,它不会生成一个可能难以分析的单个(可能很大的)日志文件。
一旦我们启用了日志收集器,我们必须配置它以按我们的要求和位置存储日志。我们可以通过在 PostgreSQL 配置文件中为以下参数设置正确的值来配置日志收集器进程:
-
log_directory:存储日志文件的目录。它可以是相对路径,相对于 PGDATA 环境变量,也可以是绝对路径(进程必须能够写入)。
-
log_filename:用于指定日志文件(在日志目录中)的名称。该模式可以按照 strftime(3) 的格式来指定,以日期和时间进行格式化。例如,值
postgresql-%Y-%m-%d.log将生成一个带有日期(分别是年、月和日)的日志文件名,例如 postgresql-2024-05-21.log。# 可以通过如下命令来查看 strftime 的帮助 $ man 3 strftime -
log_rotation_age:表示日志多长时间进行轮转一次。例如,1d 表示 1 天,指定日志每天轮换一次。
-
log_rotation_size: 日志文件达到多大时将发生轮转。如 50MB 意味着日志大小达到 50MB 时将发生轮转。
-
log_truncate_on_rotation: 该参数是一个布尔值,用于是否开启日志轮转。如果开启,则日志到了指定的时间或文件大小,PostgreSQL 则会强制截断(即清空并重新开始)现有文件。
所有与轮转相关的设置需要打开 logging_collector 配置。在 postgresql.conf 配置文件中关于日志的配置如下:
logging_collector = on
log_destination = 'stderr,csvlog,jsonlog'
log_directory = 'log'
log_filename = 'postgresql-%Y-%m-%d.log'
log_rotation_age = '1d'
log_rotation_size = '50MB'
根据上述设置,集群将使用日志收集器在日志目录(相对于 PGDATA)中为每一天(或 50MB 的大小)生成一个新的日志文件,并且每个日志文件都会标明它创建的年份、月份和日期。请注意,例如,系统将同时生成文本、JSON 和 CSV 格式的日志;对于后两种格式,PostgreSQL 会智能地更改日志文件的扩展名分别为json 和 csv。
假如我们配置了上述配置,则会在日志目录产生如下的日志文件:
$ ls -l $PGDATA/log
total 24
-rw------- 1 postgres postgres 1241 May 21 10:35 postgresql-2024-05-21.csv
-rw------- 1 postgres postgres 1976 May 21 10:35 postgresql-2024-05-21.json
-rw------- 1 postgres postgres 697 May 21 10:35 postgresql-2024-05-21.log
...
何时记录日志
前面我们介绍了把日志记录到哪里,那么接下来的问题是何时记录日志?什么操作都需记录还是发生了特定的操作才需要记录?日志记录的级别是什么?
最常见的日志级别依次为 info、notice、warning、error、log、fatal 和 panic,其中 info 是最低值,fatal 是最高值。
[!TIP]
工作见到很多开发同事喜欢使用 DEBUG 级别的日志,这在开发阶段固然很方便,有时上生产时忘记修改日志级别,把 OS 的磁盘沾满的例子有很多。这里的 info 类似 Spring 框架中的 DEBUG。
如果我们决定将 warning 作为我们要接受的最低阈值,那么所有低于该阈值的日志事件(例如 info 和 notice)将不会被写入到日志中。还有最低级别的 debug1 到 debug5,用于获取有关进程执行的开发信息和内部细节(通常在与 PostgreSQL 开发时使用)。
因此,集群将在不同时间产生不同的日志事件,且具有不同的优先级,这些日志将根据我们配置的阈值写入到日志中。
有两个参数可以用来调整日志阈值:log_min_messages 和 client_min_messages。前者 log_min_messages 决定了日志系统的阈值,而后者决定了每个新用户连接的阈值。它们有什么不同?
log_min_messages 告诉集群在不考虑传入用户连接或其设置的情况下要写入日志的内容。而 client_min_messages 决定客户端在连接期间向用户报告哪些日志事件。这两个设置都可以从前面的阈值列表中选择一个值。
开发或测试环境的典型用例如下:
log_min_messages = 'info'
client_min_messages = 'debug1'
设置阈值并不是唯一的方法来决定何时触发日志写入:还有另外一些设置可以用来处理语句执行的持续时间。
如果我们对客户执行的语句(如查询语句)感兴趣,我们可以调整以下日志记录参数:
- log_min_duration_statement 是一个表示毫秒数的整数值。超过阈值的语句都将被记录。将此值设置为 0 意味着系统中的每个语句都将被记录到日志中。
- log_min_duration_sample 和 log_statement_sample_rate 两个参数需要配合使用。log_min_duration_sample 表示仅记录运行时间超过该毫秒值的语句。它类似于 log_min_duration_statement,但不是记录每个语句,而是仅记录其中一部分。要记录的语句比例由 log_statement_sample_rate 决定,它处理一个介于 0 和 1 之间的值。
- log_transaction_sample_rate 是一个介于 0 和 1 之间的值,表示有多少个事务将被完全记录(即事务的每个语句都会出现在日志中),而不考虑语句的持续时间。
取样(sample)参数背后的思想是减少日志记录活动量(和大小),同时仍提供有关集群有用的信息。为了更好地理解上述参数,我们看下以下配置:
log_min_duration_statement = 500
log_min_duration_sample = 100
log_statement_sample_rate = 0.8
log_transaction_sample_rate = 0.5
以上配置将记录每个运行时间超过 500 毫秒(log_min_duration_statement)的语句,以及每个运行时间超过 100 毫秒的语句的 80%(log_min_duration_sample 和 log_statement_sample_rate)。最后,它将记录每两个事务中的一个(log_transaction_sample_rate)。
修改上述参数后,需要重启一下 PostgreSQL 服务。接下来我们使用以下语句来测试上述内容:
forumdb=> BEGIN;
BEGIN
forumdb=*> SELECT 'transaction 1';
?column?
═══════════════
transaction 1
(1 row)
forumdb=*> ROLLBACK;
ROLLBACK
forumdb=> BEGIN;
BEGIN
forumdb=*> SELECT 'transaction 2';
?column?
═══════════════
transaction 2
(1 row)
forumdb=*> ROLLBACK;
forumdb=> SELECT pg_sleep( 2 );
pg_sleep
══════════
(1 row)
forumdb=> BEGIN;
BEGIN
forumdb=*> SELECT pg_sleep( 0.120 ); -- 重复执行该语句 10 次
pg_sleep
══════════
(1 row)
forumdb=*> ROLLBACK;
ROLLBACK
接下来我们去看下日志:
$ cat $PGDATA/log/postgresql-2024-05-21.log
2024-05-21 11:50:00.202 CST [2952] LOG: duration: 0.115 ms statement: BEGIN;
2024-05-21 11:50:11.570 CST [2952] LOG: duration: 0.042 ms statement: SAVEPOINT pg_psql_temporary_savepoint
2024-05-21 11:50:11.571 CST [2952] LOG: duration: 0.505 ms statement: SELECT 'transaction 1';
2024-05-21 11:50:11.571 CST [2952] LOG: duration: 0.082 ms statement: RELEASE pg_psql_temporary_savepoint
2024-05-21 11:50:22.258 CST [2952] LOG: duration: 0.028 ms statement: SAVEPOINT pg_psql_temporary_savepoint
2024-05-21 11:50:22.259 CST [2952] LOG: duration: 0.095 ms statement: ROLLBACK;
2024-05-21 11:51:39.789 CST [2952] LOG: duration: 2003.138 ms statement: SELECT pg_sleep(2);
2024-05-21 11:52:22.770 CST [2952] LOG: duration: 0.070 ms statement: BEGIN;
2024-05-21 11:52:39.683 CST [2952] LOG: duration: 0.027 ms statement: SAVEPOINT pg_psql_temporary_savepoint
2024-05-21 11:59:27.031 CST [3038] LOG: duration: 121.052 ms statement: select pg_sleep(0.120);
2024-05-21 11:59:28.432 CST [3038] LOG: duration: 122.209 ms statement: select pg_sleep(0.120);
2024-05-21 11:59:28.951 CST [3038] LOG: duration: 121.911 ms statement: select pg_sleep(0.120);
2024-05-21 11:59:29.494 CST [3038] LOG: duration: 121.198 ms statement: select pg_sleep(0.120);
2024-05-21 11:59:30.062 CST [3038] LOG: duration: 121.041 ms statement: select pg_sleep(0.120);
2024-05-21 11:59:31.198 CST [3038] LOG: duration: 121.797 ms statement: select pg_sleep(0.120);
2024-05-21 11:59:31.863 CST [3038] LOG: duration: 122.299 ms statement: select pg_sleep(0.120);
根据 log_transaction_sample 参数,仅记录了两者中的一个事务。另请注意,插入 pg_sleep(2) 是因为它花费的时间超过 500 毫秒 (log_min_duration_statement),并且插入了 10 次对 pg_sleep(0.120 ) 的调用中有 7 次是因为 log_transaction_sample_rate 设置为 0.8(即 80% 的正在运行的事务)。我们可以注意到 log_transaction_sample_rate 并不是一个确切的值:即使告诉 PostgreSQL 需要记录 80% 的查询,而本次系统却记录了 70%。
需要记录什么
日志记录是通过一组丰富的参数进行配置的,通常是布尔值,用于调整特定事件的记录开启或关闭。
一个非常常用且容易被滥用的设置是 log_statement:如果打开,它将记录每个连接对集群执行的每个语句。有时它会很有用,因为它允许我们记录数据库执行的操作以及使用的语句,但另一方面,它也可能非常危险。记录每个语句可能会使私密或敏感数据出现在日志中,可能会被未经授权的人访问。此外,特别是在集群负载重、并发性高的情况下,记录所有语句可能会迅速占用存储。
[!TIP]
通常,将 log_min_duration_statement 设置配置为仅记录慢查询语句,而不是记录所有语句。
可以微调要通过 log_statement 记录的语句类别:该设置的值可以为 off、ddl、mod 或 all。off 和 all 的含义很容易理解,但 ddl 表示记录所有数据定义语言语句(例如,CREATE TABLE、ALTER TABLE 等),而 mod 表示记录所有数据操作语句(例如,INSERT、UPDATE 和 DELETE)。日志类别都是前一个类别的超集,因此 mod 也包括 ddl,而 all 都包括前一个,并且还允许记录 SELECT 类型语句。值得注意的是,如果语句包含语法错误,则无论如何配置,都不会通过log_statement 记录该语句。
日志的记录也由 log_line_prefix 参数确定。log_line_prefix 是一个模式字符串,用于定义在每个日志行的开头插入的内容,因此可用于详细说明所记录的事件。该模式是用几个占位符创建的,其方式与 sprintf(3) 相同。
# 关于 sprintf 的说明,可以通过如下命令查看帮助手册
$ man 3 sprintf
下面是最常见的占位符:
%a表示应用程序的名称(如 psql)。%u表示连接集群的用户名(角色名)。%d表示发生事件的数据库。%p表示操作系统的进程 ID(PID)。%h表示连接集群的远程主机。%l表示会话行号,是一个自增计数器,用于帮助我们理解交互式会话中每个语句的顺序。%t表示事件发生时的时间戳。
例如,以下配置将生成一个日志行,该日志行以事件的时间戳开头,后跟后端进程的进程标识符,然后是会话中命令的计数器,然后是用于从远程主机连接到群集的用户、数据库和应用程序:
log_line_prefix = '%t [%p]: [%l] user=%u,db=%d,app=%a,client=%h '
我们可以修改一下 postgresql.conf 文件,修改完成后记得重启一下服务。接下来我们做一些查询操作,之后看下日志文件中的内容。
首先,登录数据库做些操作:
$ psql -h localhost -U forum forumdb
Password for user forum:
psql (16.2)
Type "help" for help.
forumdb=> \l
List of databases
Name │ Owner │ Encoding │ Locale Provider │ Collate │ Ctype │ ICU Locale │ ICU Rules │ Access privileges
═══════════╪══════════╪══════════╪═════════════════╪═════════════╪═════════════╪════════════╪═══════════╪═══════════════════════
forumdb │ forum │ UTF8 │ libc │ en_US.UTF-8 │ en_US.UTF-8 │ │ │
postgres │ postgres │ UTF8 │ libc │ en_US.UTF-8 │ en_US.UTF-8 │ │ │
template0 │ postgres │ UTF8 │ libc │ en_US.UTF-8 │ en_US.UTF-8 │ │ │ =c/postgres ↵
│ │ │ │ │ │ │ │ postgres=CTc/postgres
template1 │ postgres │ UTF8 │ libc │ en_US.UTF-8 │ en_US.UTF-8 │ │ │ =c/postgres ↵
│ │ │ │ │ │ │ │ postgres=CTc/postgres
(4 rows)
forumdb=> table categories;
pk │ title │ description
════╪═══════════════════════╪══════════════════════════════════
5 │ Software engineering │ Software engineering discussions
1 │ Database │ Database related discussions
2 │ Unix │ Unix and Linux discussions
3 │ Programming Languages │ All about programming languages
4 │ A.I │ Machine Learning discussions
(5 rows)
forumdb=> quit
然后,查看一下日志文件的内容:
$ tail $PGDATA/log/postgresql-2024-05-21.log
2024-05-21 13:58:26 CST [3743]: [1] user=forum,db=forumdb,app=psql,client=::1 LOG: duration: 2.484 ms statement: SELECT c.relname, NULL::pg_catalog.text FROM pg_catalog.pg_class c WHERE c.relkind IN ('r', 'S', 'v', 'm', 'f', 'p') AND (c.relname) LIKE 'ca%' AND pg_catalog.pg_table_is_visible(c.oid) AND c.relnamespace <> (SELECT oid FROM pg_catalog.pg_namespace WHERE nspname = 'pg_catalog')
UNION ALL
SELECT NULL::pg_catalog.text, n.nspname FROM pg_catalog.pg_namespace n WHERE n.nspname LIKE 'ca%' AND n.nspname NOT LIKE E'pg\\_%'
LIMIT 1000
从上面的输出中可以看出来我们的配置已经生效了:
2024-05-21 13:58:26 CST [3743]: [1] user=forum,db=forumdb,app=psql,client=::1
多亏了 log_line_prefix,可以在每个日志条目中插入有关与事件相关的用户和数据库的信息,这可以帮助我们更好地了解和分析集群中发生的事情。
还有一些特殊事件可以触发日志写入,这些事件是通过以下参数配置:
- log_connections 和 log_disconnections:这些布尔值告诉 PostgreSQL 是否必须在每次打开或关闭用户连接时在日志中写入记录。
- log_checkpoints:此布尔设置告诉 PostgreSQL 记录有关检查点的信息(有关详细信息,请参见前面“事务、MVCC、WAL 和检查点”章节)。
- log_temp_files:此参数是一个 KB 为单位的整数值,用于保存临时文件的大小。每当 PostgreSQL 创建的临时文件大于所表示的大小时,都会生成一个日志记录。将此参数设置为 0 意味着每次 PostgreSQL 使用临时文件时,都会追加一个日志记录。
- log_lock_waits: 此布尔参数表示每当用户会话等待太长时间以获取锁时,都应创建一个日志记录。阈值是配置参数 deadlock_timeout。
现在我们已经学习了有关日志记录的所有内容,接下来我们将使用一个特殊的工具 pgBadger,从 日志中提取信息。
使用 pgBadger 抽取日志信息
由于日志中可以包含丰富的信息,因此可以自动化日志信息分析和提取。有几种旨在实现此目的的工具,其中最流行且功能最完整的之一是 pgBadger。
pgBadger 是一个自包含的 Perl 5 应用程序,它 从 PostgreSQL 日志中提取信息,生成一个包含日志中所有找到的信息摘要的 Web 仪表板。该应用程序的目的是为我们提供更有用的日志洞察,而无需手动搜索特定信息。
安装 pgBadger
pgBadger 要求在运行它的系统上安装 Perl 5,这是它唯一的依赖项。我们可以在运行 PostgreSQL 集群的同一主机上运行 pgBadger,也可以在远程系统上运行 pgBadger(将在后面的小节中显示)。在本节中,我们将假设 pgBadger 将在运行 PostgreSQL 集群的同一台机器上安装和执行。
最简单的方式是通过操作的包管理工具进行安装,如下:
# Debian 系列的安装命令如下
$ sudo apt install pgbadger
# RHEL 系列的安装命令如下
# yum -y install pgbadger
当然也可以采用编译安装。如果采用源码编译安装,则步骤如下:
$ wget https://github.com/darold/pgbadger/archive/v12.0.tar.gz
$ tar xzvf v12.0.tar.gz
$ cd pgbadger-12.0
$ perl Makefile.PL
$ make
$ sudo make install
一旦编译完成,可以简单地进行验证:
$ pgbadger --version
pgBadger version 12.0
一切看起来正常,接下来我们配置 PostgreSQL,然后使用 pgBadger 进行日志的抽取(提取)。
配置 PostgreSQL 以使用 pgBadger
一般情况下 pgBadger 足够智能,能够在许多情况下理解 PostgreSQL 日志,但在某些情况下,我们需要指定一些配置选项,以便让 PostgreSQL 生成更易理解的日志。
首先,pgBadger 需要访问 PostgreSQL 日志,这意味着我们应该使用 logging_collector 来生成日志。如果我们更改了 log_line_prefix,我们应该将相同的配置设置传递给 pgBadger,以便它能够正确解析日志前缀。最后,我们应该尽可能启用多个日志上下文。
以下是使 PostgreSQL 生成 pgBadger 可以正确理解的日志的配置参数示例:
logging_collector = on
log_destination = 'stderr,csvlog,jsonlog'
log_directory = 'log'
log_filename = 'postgresql-%Y-%m-%d.log'
log_rotation_age = '1d'
log_rotation_size = '50MB'
log_min_duration_sample = 100
log_statement_sample_rate = 0.8
log_transaction_sample_rate = 0.5
log_min_duration_statement = 0
配置完成 postgresql.conf 后记得重启服务,接下来就可以使用 pgBadger。
使用 pgBadger
一旦 PostgreSQL 开始生成日志,我们就可以使用 pgBadger 分析结果。在运行 pgBadger 之前,特别是在测试系统上,我们应该生成(或等待)一些流量和语句(以及事务),否则 pgBadger 生成的 Dashboard 将为空。
在开始使用 pgBadger 之前,创建一个放置报告和相关内容的位置。这不是强制性的,但在以后需要保留报告时,可以简化维护和归档。让我们创建一个目录,并将运行集群的相同 postgres 用户分配为该目录的所有者(这不是强制性的,但可以简化工作流程):
$ sudo mkdir -pv /data/pg_report
$ sudo chown postgres. /data/pg_report
It is now time to launch pgBadger for the first time:
$ pgbadger -o /data/pg_report/first_report.html $PGDATA/log/postgresql-2024-05-21.log
[========================>] Parsed 10834 bytes of 10834 (100.00%), queries: 48, events: 6
LOG: Ok, generating html report...
第一个参数 -o 指定要存储报表的文件的名称。pgBadger 每次运行只生成一个文件,因此如果要在不覆盖现有报告的情况下生成另一个报告,则需要更改文件名。
第二个参数是要分析的 PostgreSQL 日志文件;我们还可以指定 JSON 或 CSV 文件,pgBadger 将相应地解析它们。
该程序运行几秒钟或几分钟,主要取决于日志文件的大小,并报告有关它在日志文件上找到的内容的一些统计信息。我们可以非常轻松地检查生成的报告文件:
[!TIP]
如果我们要分析大型日志文件,或者有很多日志文件,我们可以使用 pgBadger 的并行模式,使用
-j选项后跟要启动的并行进程数。例如,传递-j 4意味着每个日志文件将被分成四个部分,每个部分由一个单独的进程分析。通过并行性,我们可以利用机器的所有核心,更快地获取大量日志的结果。
$ ls -1s /data/pg_report/first_report.html
908 /data/pg_report/first_report.html
一旦有了报告,我们可以在本地文件上打开我们的网络浏览器(或通过 Web 服务器提供结果)。我们将看到以下报告。该报告提供了对集群活动的一瞥,包括语句数量、为这些语句提供服务的时间以及显示一段时间内语句流量的图表。
进到我们的日志报表目录,并临时启动一个 Web 服务。操作如下:
$ cd /data/pg_report/
# 如果操作系统上的 Python 版本为 3.x,则执行如下命令
$ python -m http.server
# 如果操作系统上的 Python 版本为 2.x,则执行如下命令
$ python -m SimpleHTTPServer
执行完成上述命令后,就会有如下提示:
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
表示我们已经在 8000 端口运行了一个 Web 服务。看下本机的 IP 地址,获取到 IP 后,我们就可以通过浏览器进行查看报告:
$ ifconfig ens192
ens192: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.56.143 netmask 255.255.255.0 broadcast 192.168.56.255
inet6 fe80::20c:29ff:fec0:7e80 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:c0:7e:80 txqueuelen 1000 (Ethernet)
RX packets 8305 bytes 673422 (657.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 7516 bytes 2067937 (1.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
大家的 IP 可能与我的不一样,根据实际情况进行查看或使用。通过浏览器打开后的界面如下:

在网页的顶部,有一个菜单栏,其中包含多个菜单,可让我们查看不同的图表和仪表板。

例如,Connections 菜单允许我们获取有关我们拥有多少个并发连接的信息,如以下示例所示:
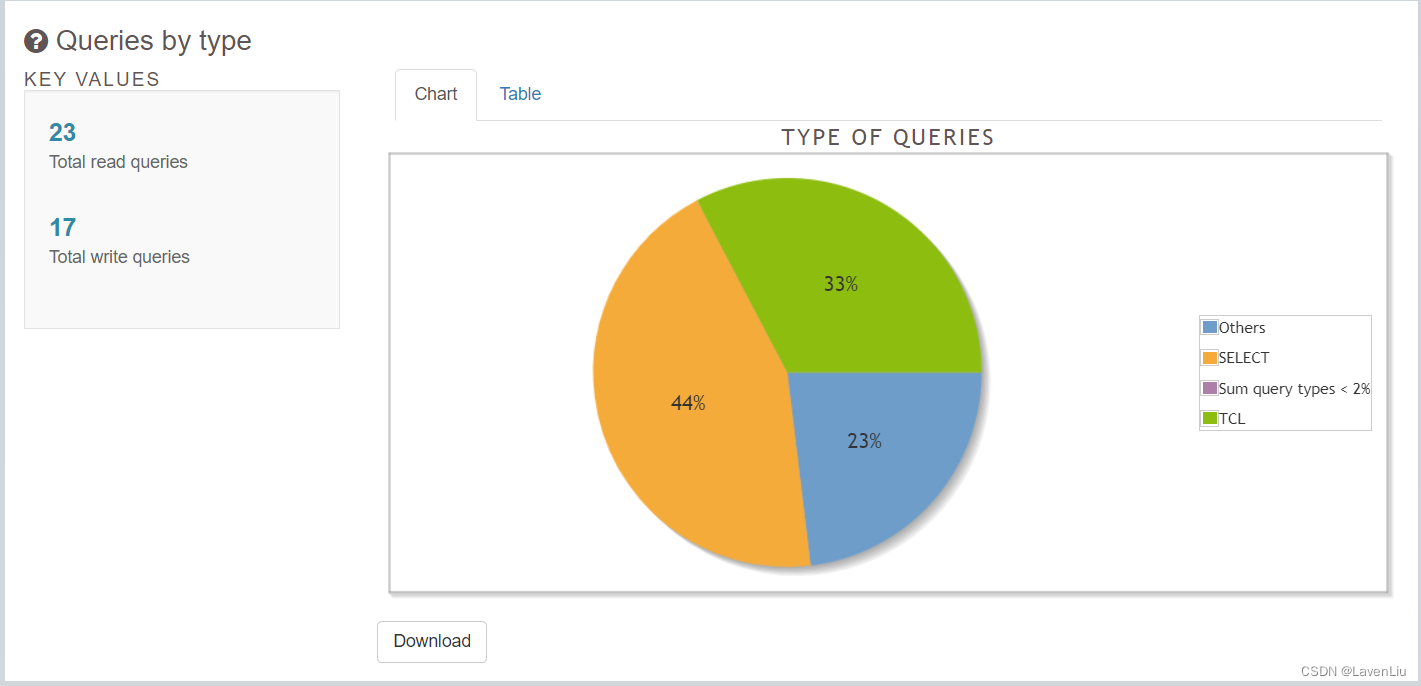
**Queries **菜单允许我们获取有关语句类型和频率的信息,如下所示的屏幕截图,其中查询的主要百分比是 SELECT 类型。
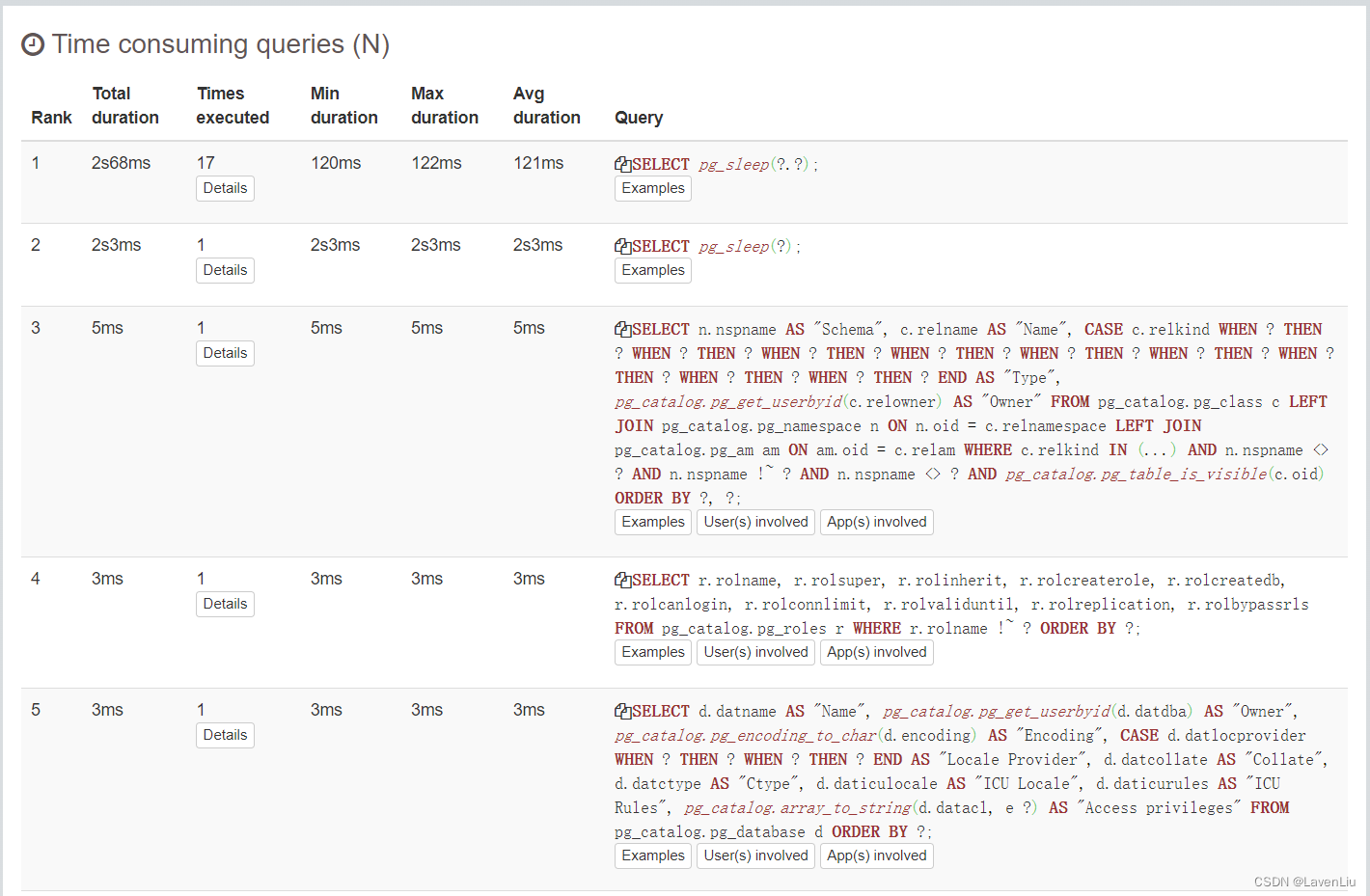
“Top” 菜单允许我们查看 TOP N 排行,例如最慢的查询和最耗时的查询,分别在以下截图中显示:
讨论 pgBadger 的所有功能和仪表板超出了本专栏的范围,但请参阅官方文档以获取更多详细信息。
定时执行 pgBadger
pgBadger 可以按计划方式使用,以便在指定的时间段内持续生成准确的报告。这是因为 pgBadger 包含了增量功能,可以在每小时生成报告和每周汇总报告,而不会每次都覆盖之前的报告。
这很方便,因为我们可以使用例如 cron(1) 来安排 pgbadger 的执行。现在让我们首先看看 pgBadger 如何在增量模式下运行:
$ pgbadger -I --outdir /data/pg_report -f stderr $PGDATA/log/postgresql-2024-*.log
[========================>] Parsed 28797 bytes of 28797 (100.00%), queries: 88, events: 12
LOG: Ok, generating HTML daily report into /data/pg_report/2024/05/21/...
LOG: Ok, generating HTML weekly report into /data/pg_report/2024/week-21/...
LOG: Ok, generating global index to access incremental reports...
-I 参数指定增量模式,因此 pgBadger 将为每小时和每周报告生成单独的文件。请注意,不是指定输出文件,而是使用 --outdir 选项来指定放置文件的目录。-f 选项告诉 pgBadger 它正在管理哪种类型的日志;在这个示例中,是普通文本文件。最后,表示为一个 shell 通配符(postgresql-2024-*log)。
最终结果,是生成了一个类似以下的目录树:
$ ls -R /data/pg_report/
/data/pg_report/:
2024 first_report.html index.html LAST_PARSED
/data/pg_report/2024:
05 week-21
/data/pg_report/2024/05:
21
/data/pg_report/2024/05/21:
2024-05-21-2268.bin index.html
/data/pg_report/2024/week-21:
index.html
主 index.html 文件是整个增量报告的入口点。然后有一个目录树,其中包含了一个 2024 年的目录,一个 05 月的目录,以及一个 21 日的目录,以及该日的index.html 文件。
目录树的一部分还会收集本周的数据;在这种情况下,是第 21 周。因此,随着更多的天数,目录树将会扩展。特殊的 LAST_PARSED 文件被 pgBadger 用来记住它停止解析的时间,从而允许它在下一次增量调用时从那里开始。
如果我们将网络浏览器指向主索引文件,我们将会看到一个类似以下截图的日历,我们可以选择月份和日期来查看每日报告。
点击特定日期,我们将被重定向到每日报告,其中显示了已经讨论过的相同仪表板。显然,我们不能点击尚未生成报告或在 PostgreSQL 日志中没有相应活动的日期。
由于增量方法,我们现在可以在我们自己的调度程序中安排执行;例如,在 cron(1) 中,我们可以新增以下行:
# 大家根据实际情况修改一下具体的日志路径
# 我这里以环境变量代替了
# 下面的定时任务表示:每天的 23:59 执行生成报告的动作
59 23 * * * pgbadger -I --outdir /data/pg_report/ -f stderr $PGDATA/log/postgresql-`date +'%Y-%m-%d'`.log
这基本上是与前面那个命令行相同,只是当前日期会自动计算。
最后,我们可以从远程主机运行 pgBadger,以便将所有报告和信息集中在一个地方。实际上,pgBadger 接受一个 URI 参数,该参数是日志目录(或文件)的远程位置,可以通过 FTP 或更安全且推荐的 SSH 访问。
这是相同的命令行,以增量模式从名为 pg.lavenliu.cn 的远程 PostgreSQL 主机中提取日志。
$ pgbadger -I --outdir /data/pg_report ssh://postgres@pg.lavenliu.cn//postgres/16/data/log/postgresql-`date +'%Y-%m-%d'`.pgbadger.log
[========================>] Parsed 313252 bytes of 313252 (100.00%), queries: 841, events: 34
请注意,日志文件是通过 SSH URL 指定的。强烈建议使用有权访问日志的远程用户并通过 SSH 密钥以免密码的方式在主机之间登录。
现在我们知道了如何使用日志,我们将继续讨论另一种查看任务的方式 - 审计。
总结
PostgreSQL 为日志提供了可靠且灵活的基础设施,允许数据库管理员监控集群在最近及过去所做的操作。由于其灵活性,日志可以配置为允许外部工具(如 pgBadger)进行集群分析。此外,相同的日志基础设施还可以用于执行审计,这是等保及安全经常要求的一种方式。
在本章中,我们已经学会了如何配置 PostgreSQL 日志系统以满足我们的需求,如何通过 pgBadger 提供的 Web 仪表板监控我们的集群以及如何对我们的用户和应用程序进行审计。
在下一章,我们将要介绍备份与恢复。