换了新项目组,技术相对老些,于是用boot框架简单记录下!
安装
下载路径:https://solr.apache.org/downloads.html
Windows环境
下载solr-8.2.0.zip包并解压缩,以管理员身份打开cmd,执行 solr cmd 命令启动solr
访问地址:ip:8983/

Linux环境
下载solr-8.2.0.tgz包 并执行以下命令
#1.解压缩
cd /opt
tar -xvf solr-8.2.0.tgz#2.编辑sh脚本
cd solr-8.2.0/bin
vim solr.in.sh
补充内容:
SOLR_ULIMIT_CHECKS=false
#3.启动
./solr start -force
访问地址:ip:8983/
常用概念
核心(索引/表)
核心core:和数据库中的表一个意思,只是术语不同。可以看到页面上有个Core Admin,这个就是管理core的。
文档 doc
文档doc:相当于数据库中的一行数据。一个core由多条doc组成。
结构 schema
结构schema:相当于数据库的表结构。常见结构schema:字段、字段类型、唯一键
分词
分词:就是将搜索内容拆分成一个个的词组。这个和以往数据库模糊匹配还不一样。
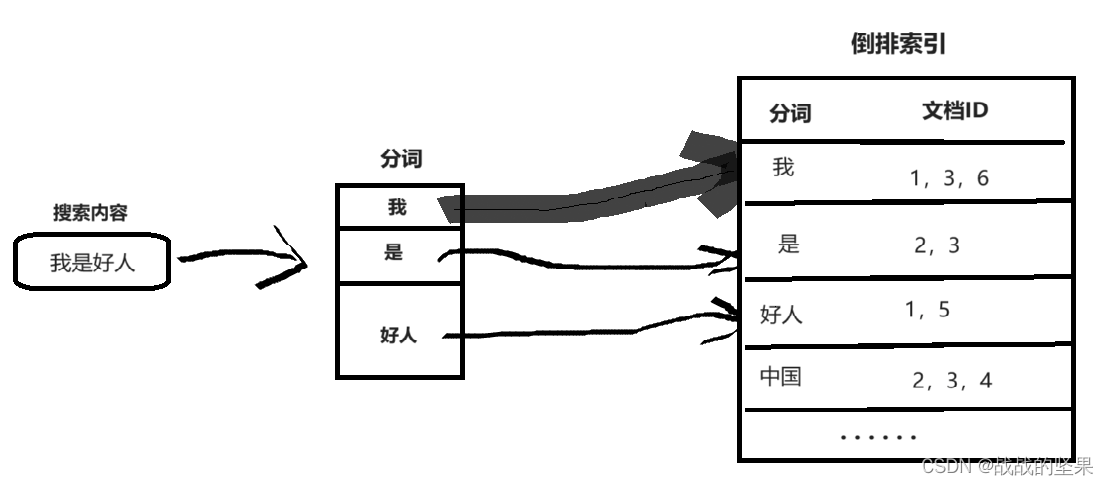
例如 在百度搜索时,搜索“我是好人”,会将搜索内容分成 我,是,好人。然后判断这几个分词在索引库中的出现次数,根据权重返回匹配信息。若用传统数据库mysql或oracle这种,直接会去用“我是好人”去模糊查询数据库,最后查询出的结果只能是 %我是好人% 这种数据。
但是搜索引擎会匹配出 %我%是%好人% 的数据。
倒排索引(反向索引)
说到倒排索引,提下正向索引。例如搜索“我是好人”,于是将分词 我,是,好人 分别去遍历每个文档,看是否有匹配数据。
倒排索引是 以分词为主键,文档ID为值的结构存储方式,其中文档ID升序存储,逗号分隔记录,节省了很大存储空间。当有搜索内容,只需分词后去匹配已倒排索引的数据得出最终的文档ID。
field标签常用属性
字段名称 name
字段类型 type
支持字段类型:
string 字符串
int, long 整数
float, double 浮点数
date 日期时间
bool 布尔类型
text 文本类型
binary 二进制类型
是否创建索引 indexed
indexed:当前字段是否创建索引,默认是true。创建索引后,可支持对该字段的搜索和过滤。
是否存储 sorted
sorted:当前字段是否存储到solr本身的存储库中,默认是true。此时不需要再次查询数据源显示数据。
是否启用点列存储 docValues
docValues:是否启用点列存储,默认是false。若需要做排序或者聚合查询处理都需要设置为true
是否多值 multiValues
multiValues:是否存储多个值,默认是false。若类型是数组,则需要设置为true。
安装ik中文分词器
版本与solr保持一致
下载地址:https://central.sonatype.com/artifact/com.github.magese/ik-analyzer
1.将ik-analyzer-8.2.0.jar包传输到/opt/solr-8.2.0/server/solr-webapp/webapp/WEB-INF/lib目录下
2.managed-schema文件补充 分词字段定义
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>将需要分词的字段类型调整为 text_ik
<field name="remarks" type="text_ik" indexed="true" stored="true" />3.重启solr
./bin/solr stop -all
./bin/solr start -force
查看结果
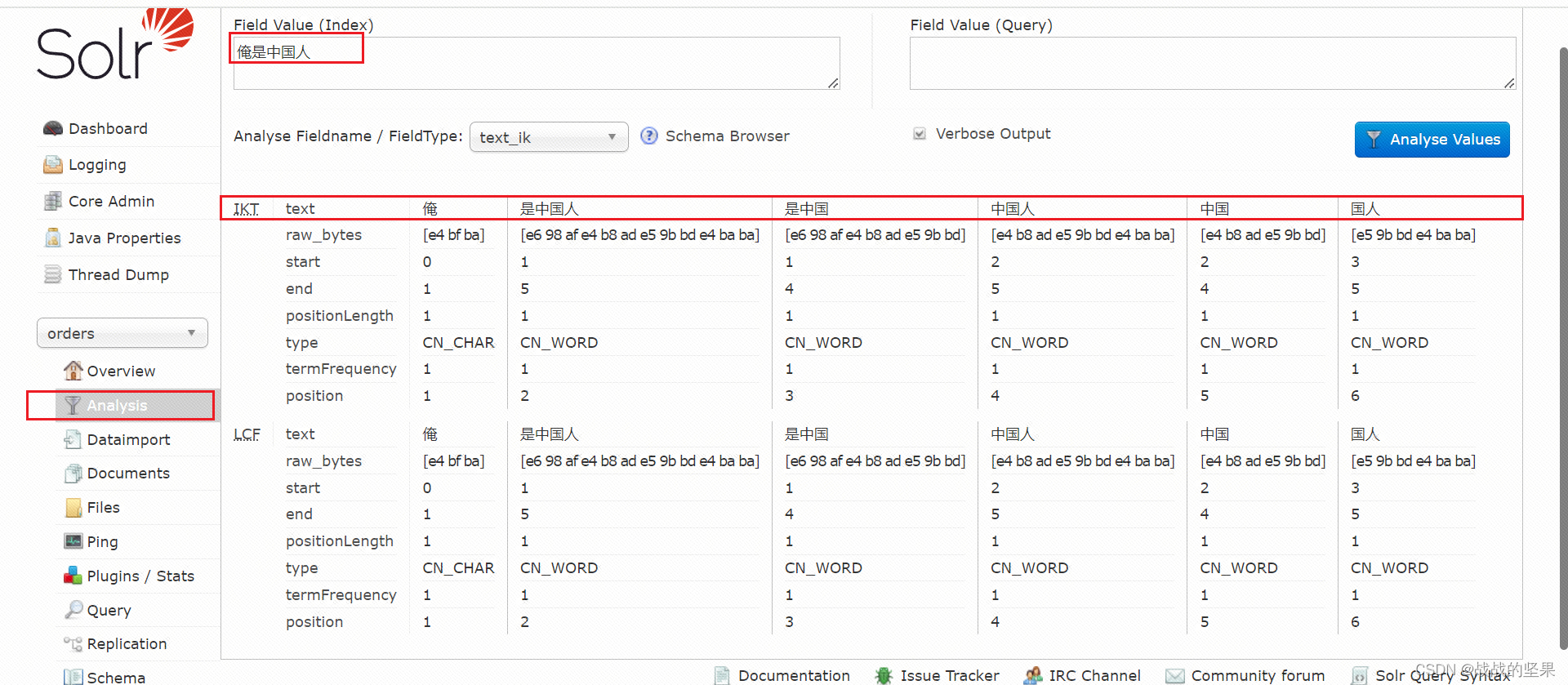
修改分词器后,需要将索引删除后重新加载,solr重启后导入数据,方可根据分词器查询。
常用查询
通配符
?匹配单个字符;
* 匹配任意个字符;
连接符
&& 条件且;
|| 条件或;
查询
value值用"",表示该值是精确查询;
例如remark:"备注" ;查询remark字段只为备注的文档
NOT查询
value值用(* NOT "value1" NOT "value2"),表示不查询value值为value1和value2;
例如remark:(* NOT"送货") ;查询remark字段不为送货的文档
范围查询
value值用[v1 TO v2] 表示范围查询,[]表示包含,{}表示不包含;
例如id:[1 TO 2} 查询1<=id<2的文档
创建索引
在/opt/solr-8.2.0/server/solr目录下创建文件夹person
#1.创建文件夹
mkdir person
#2.将自带文件复制到该目录下
cp -R solr-8.2.0/server/solr/configsets/_default/conf/* solr-8.2.0/server/solr/person
修改managed-schema文件
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="default-config" version="1.6">
<!-- 默认字段,不需要的可以删除 -->
<field name="id" type="long" indexed="true" stored="true" required="true" multiValued="false" />
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- 定义字段 根据情况补充 -->
<field name="p_no" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="p_name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="create_time" type="date" indexed="true" stored="true" required="true" multiValued="false" />
<field name="create_user" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="remarks" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
<field name="loves" type="string" indexed="true" stored="false" required="true" multiValued="true" />
<uniqueKey>id</uniqueKey>
<!-- 要声明使用的type -->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<!-- 保留 -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- 中文分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema>修改solrconfig.xml文件
将所有调用及配置的add-schema-fields删除
solr设置账号密码
详情可见 前辈文章,下面也有记录
/opt/solr-8.2.0/server/etc目录
新建verify.properties文件,内容为
# 用户名 密码 权限
solr: solr,admin/opt/solr-8.2.0/server/contexts 目录
补充solr-jetty-context.xml文件,内容为
<!--添加配置权限认证:在文件configure中添加获取用户文件的配置,内容如下:-->
<Get name="securityHandler">
<Set name="loginService">
<New class="org.eclipse.jetty.security.HashLoginService">
<Set name="name">verify—name</Set>
<Set name="config"><SystemProperty name="jetty.home" default="."/>/etc/verify.properties</Set>
</New>
</Set>
</Get>/opt/solr-8.2.0/server/solr-webapp/webapp/WEB-INF目录
补充web.xml文件,内容为
<!--重新配置 security-resource-collection (删除之前的security-constraint,会导致登录的配置无效)-->
<security-constraint>
<web-resource-collection>
<web-resource-name>Solr</web-resource-name>
<url-pattern>/</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>verify-name</realm-name>
</login-config>重启solr,账号密码为solr/solr
boot整合
pom.xml文件补充依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>application.yml文件补充配置
spring:
data:
solr:
host: http://192.168.28.196:8983/solr # solr 服务地址
username: solr #用户名
password: solr #密码
connectionTimeout: 10000 #连接超时
socketTimeout: 3000 #读取超时启动类开启solr配置
@EnableSolrRepositories(basePackages="com.example.demo.repository")solr配置
package com.example.demo.config;
import org.apache.http.HttpHost;
import org.apache.http.HttpRequest;
import org.apache.http.HttpRequestInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.AuthState;
import org.apache.http.auth.Credentials;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.impl.auth.BasicScheme;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.protocol.HttpContext;
import org.apache.http.protocol.HttpCoreContext;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.net.URI;
/**
* @Auther: lr
* @Date: 2024/6/6 16:57
* @Description:
*/
@Configuration
public class SolrConfig {
@Value("${spring.data.solr.username}")
private String username;
@Value("${spring.data.solr.password}")
private String password;
@Value("${spring.data.solr.host}")
private String url;
@Value("${spring.data.solr.connectionTimeout}")
private Integer connectionTimeout;
@Value("${spring.data.solr.socketTimeout}")
private Integer socketTimeout;
@Bean
public HttpSolrClient solrClient(){
//solr无账号密码
// return new HttpSolrClient.Builder(url)
// .withConnectionTimeout(connectionTimeout)
// .withSocketTimeout(socketTimeout)
// .build();
//solr有账号密码 认证信息拦截
CredentialsProvider provider = new BasicCredentialsProvider();
final URI uri = URI.create(this.url);
provider.setCredentials(new AuthScope(uri.getHost(), uri.getPort()),
new UsernamePasswordCredentials(this.username, this.password));
HttpClientBuilder builder = HttpClientBuilder.create();
// 指定拦截器,用于设置认证信息
builder.addInterceptorFirst(new SolrAuthInterceptor());
builder.setDefaultCredentialsProvider(provider);
CloseableHttpClient httpClient = builder.build();
return new HttpSolrClient.Builder(this.url)
.withHttpClient(httpClient)
.withConnectionTimeout(connectionTimeout)
.withSocketTimeout(socketTimeout)
.build();
}
public static class SolrAuthInterceptor implements HttpRequestInterceptor {
@Override
public void process(final HttpRequest request, final HttpContext context) {
AuthState authState = (AuthState) context.getAttribute(HttpClientContext.TARGET_AUTH_STATE);
if (authState.getAuthScheme() == null) {
CredentialsProvider provider =
(CredentialsProvider) context.getAttribute(HttpClientContext.CREDS_PROVIDER);
HttpHost httpHost = (HttpHost) context.getAttribute(HttpCoreContext.HTTP_TARGET_HOST);
AuthScope scope = new AuthScope(httpHost.getHostName(), httpHost.getPort());
Credentials credentials = provider.getCredentials(scope);
authState.update(new BasicScheme(), credentials);
}
}
}
}实体类
package com.example.demo.entity;
import lombok.Data;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.annotation.Id;
import org.springframework.data.solr.core.mapping.Indexed;
import org.springframework.data.solr.core.mapping.SolrDocument;
import java.util.Date;
import java.util.List;
/**
* @Auther: lr
* @Date: 2024/6/7 14:52
* @Description:
*/
@Data
@SolrDocument(collection = "person")
public class Person {
@Id
@Indexed(name = "id", type = "long")
@Field("id")
private Long id;
@Indexed(name = "p_no", type = "string")
@Field("p_no") //@Field 用于solr结果转实体类对象
private String pNo;
@Indexed(name = "p_name", type = "string")
@Field("p_name")
private String pName;
@Indexed(name = "create_time", type = "date")
@Field("create_time")
private Date createTime;
@Indexed(name = "create_user", type = "string")
@Field("create_user")
private String createUser;
@Indexed(name = "remarks", type = "text_ik")
@Field("remarks")
private String remarks;
@Indexed(name = "loves", type = "string")
@Field("loves")
private List<String> loves;
}
dao层
package com.example.demo.repository;
import com.example.demo.entity.Person;
import org.springframework.data.solr.repository.SolrCrudRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @Auther: lr
* @Date: 2024/6/7 11:28
* @Description:
*/
@Repository
public interface PersonRepository extends SolrCrudRepository<Person, Long> {
List<Person> findAll();
List<Person> findByRemarks(String remarks);
}
controller类
package com.example.demo.controller;
import com.example.demo.entity.Person;
import com.example.demo.repository.PersonRepository;
import org.apache.commons.lang3.StringUtils;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
/**
* @Auther: lr
* @Date: 2024/6/7 9:42
* @Description:
*/
@RestController
@RequestMapping("/person")
public class SolrController {
@Autowired
PersonRepository repository;
@PostMapping("/addData")
public void addData(@RequestBody Person person) throws Exception{
repository.save(person);
}
@GetMapping("/queryAll")
public List<Person> search() throws SolrServerException, IOException {
List<Person> list = repository.findAll();
return list;
}
@GetMapping("/queryByRemarks")
public List<Person> search(@RequestParam("remarks") String remarks) throws SolrServerException, IOException {
List<Person> list = repository.findByRemarks(remarks);
return list;
}
@Autowired
HttpSolrClient solrClient;
@GetMapping("queryByLoves")
public List<Person> queryByLoves(@RequestParam("love") String love) throws IOException, SolrServerException {
//设置查询条件
SolrQuery query = new SolrQuery();
if (!StringUtils.isEmpty(love)) {
query.setQuery("loves:" + love);
}
if(StringUtils.isEmpty(query.getQuery())){
query.setQuery("*:*");
}
query.setStart(0);
query.setRows(5);
QueryResponse response = solrClient.query("person",query);
List<Person> list = response.getBeans(Person.class);
return list;
}
}
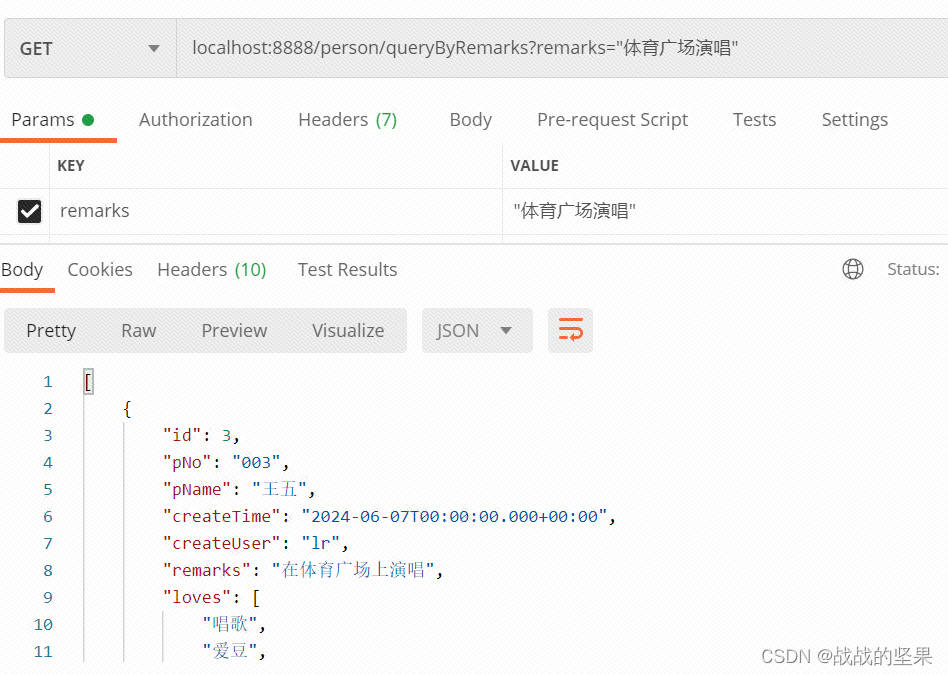
接口调用测试
在索引写文档信息
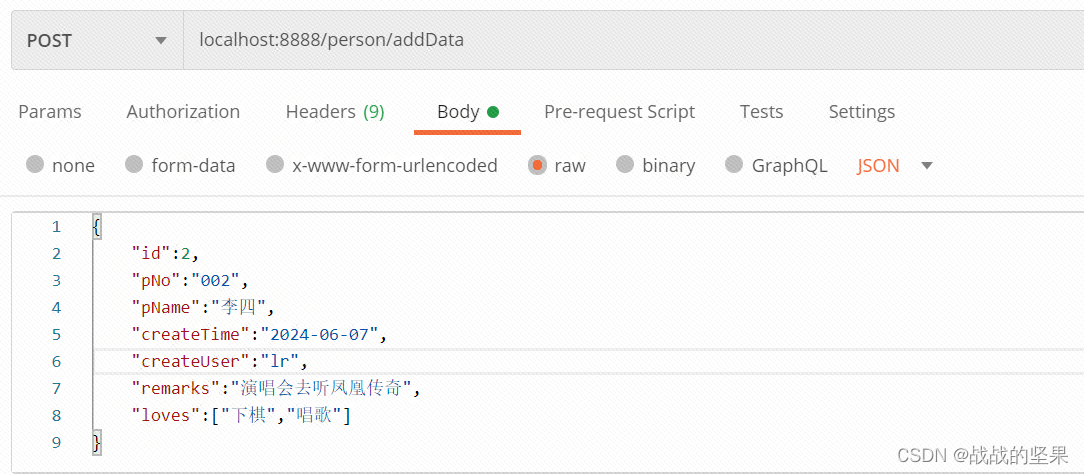
在索引查询文档信息
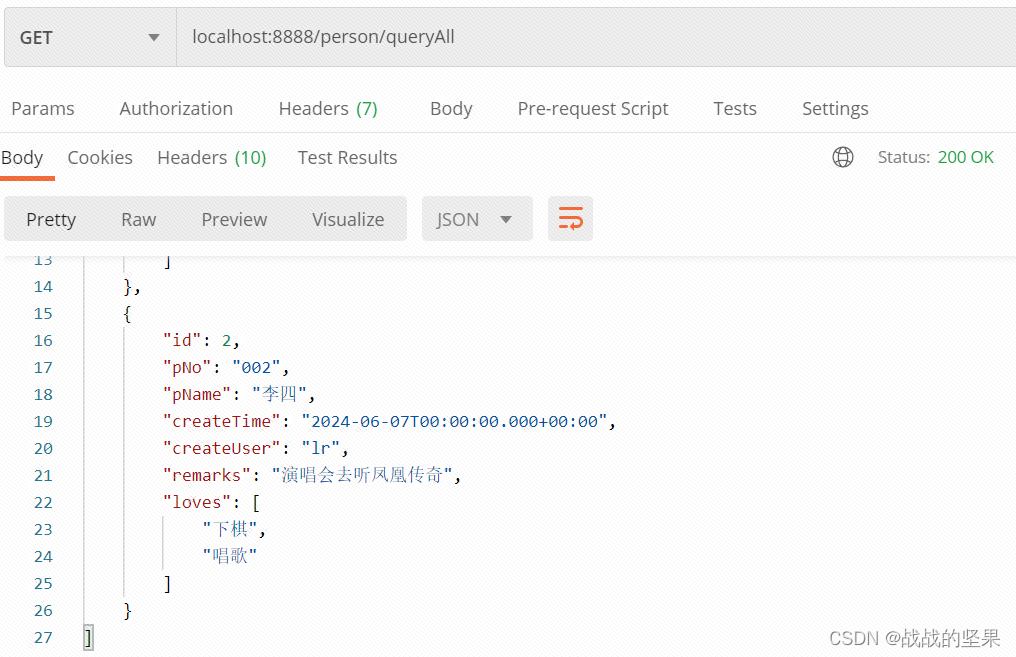
其他查询(聚合分组查询group)根据项目而定!!!