查询性能优化
排序优化
无论如何排序都是一个成本很高的操作,所以从性能角度考虑,应尽可能避免排序或者尽可能避免对大量数据进行排序。前面已经提到了,当不能使用索引生成排序结果的时候,MySQL需要自己进行排序,如果数据量小则在内存种进行,如果数据量大则需要使用磁盘,不过MySQL将这个过程统一称为文件排序(filesort),即使完全是内存排序不需要任何磁盘文件时也是如此。如果需要排序的数据量小于"排序缓冲区",MySQL使用内存进行"快速排序"操作。如果内存不够排序,那么MySQL会先将数据分块,对每个独立的块使用"快速排序"进行排序,并将各个块的排序结果存放在磁盘上,然后将各个排好序的快进行合并(merge),最后返回排序结果。MySQL有如下两种排序算法:
- 1.两次传输排序(旧版本使用)(也称双路排序)
读取行指针和需要排序的字段,对其进行排序,然后再根据排序结果读取所需要的数据行。这需要进行两次数据传输,即需要从数据表中读取两次数据,第二次读取数据的时候,因为是读取排序列进行排序后的所有记录,这回产生大量的随机IO,所以两次数据传输的成本非常高。当使用的是MyISAM表的时候,成本可能会更高,因为MyISAM使用系统调用进行数据的读取(MyISAM非常依赖操作系统对数据的缓存)。不过这样做的优点是,在排序的时候存储尽可能少的数据,这就让"排序缓冲区"(内存)中可能容纳尽可能多的行数进行排序 - 2.单次传输排序(新版本使用)
先读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果。这个算法只在MySQL4.1和后续更新的版本中引入。因为不再需要从数据表中读取两次数据,对于IO密集型的应用,这样做的效率高了很多。另外,相比两次传输排序,这个算法只需要一次顺序IO读取所有的数据,而无须任何的随机IO.缺点是,如果需要返回的列非常多、非常大、会额外占用大量的空间,而这些列对排序操作本身来说是没有任何作用的。因为单条排序记录很大,所以可能会有更多的排序块需要合并.
很难说哪个算法效率更高,两种算法都有各自最好和最糟的场景。当查询需要所有列的总长度不超过参数max_length_for_sort_data时,MySQL使用"单次传输排序",,可以通过调整这个参数来影响MySQL排序算法的选择
MySQL在进行文件排序的时候需要使用的临时存储空间可能会比想象的要大得多。原因在于MySQL在排序时,对每一个排序记录都会分配一足够长的定长空间来存放。这个定长空间必须足够长以容纳其中最长的字符串,例如,如果是VARCHAR列则需要分配其完整长度;如果使用UTF-8字符集,那么MySQL将会为每个字符预留两个字节。曾经在一个库表结构设计不合理的案例中看到,排序消耗的临时空间比磁盘上的原表要大很多倍。
在关联查询的时候如果需要排序,MySQL会分两种情况来处理这样的文件排序。如果ORDER BY 子句中的所有列都来自关联的第一个表,那么MysQL在关联处理第一个表的时候就进行文件排序。如果是这样,那么在MySQL的EXPLAIN结果中可以看到Extra字段会有"Using filesort".除此之外的所有情况,MySQL都会先将关联的结果存放到一个临时表中,然后在所有的关联都结束后,再进行文件排序。这种情况下,在MySQL的EXPLAIN结果的Extra字段可以看到"Using temporary;Using filesort",如果查询中有LIMIT的话,LIMIT也会在排序之后应用,所以即使需要返回较少的数据,临时表和需要排序的数据量仍然会非常大。MySQL5.6在这里做了很多重要的改进。当只需要返回部分排序结果的时候,例如使用了LIMIT子句,MySQL不再对所有的结果进行排序,而是根据实际情况,选择抛弃不满足条件的结果,然后再进行排序
查询执行引擎
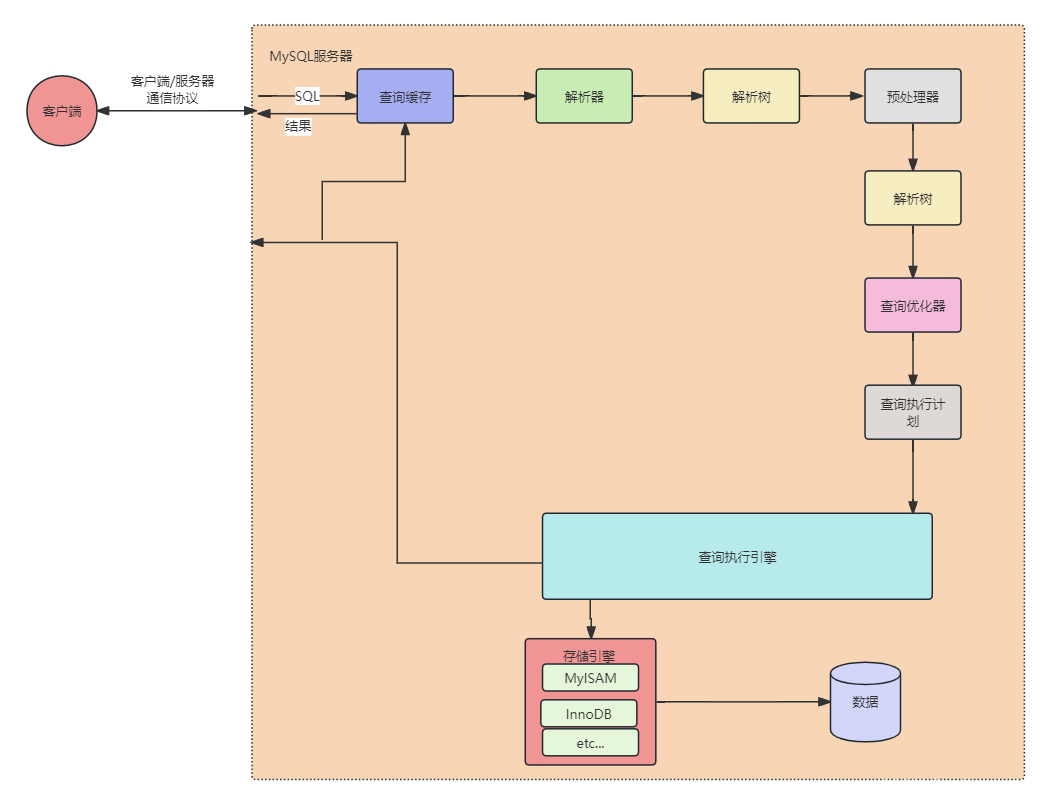
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎根据这个执行计划来完成整个查询。这里执行计划是一个数据结构,而不是和其他的关系型数据库那样生成对应的字节码。相对于查询优化阶段,查询执行阶段不是那么复杂:MySQL只是简单地根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成,这些接口也就是我们成为"handler API"的接口。查询中的每一个表由一个handler的实例表示。实际上,MySQL在优化阶段就为每个表创建了一个handler实例,优化器根据这些实例的接口可以获取表的相关信息,包括表的所有列名、索引统计信息,等等。
存储引擎接口有着非常丰富的功能,但是底层接口却只有几十个,这些接口像"搭积木"一样能够完成查询的大部分操作。例如,有一个查询某个索引的第一行的解耦,再有一个查询某个索引条目的下一个条目的功能,有了这两个功能我们就可以完成全索引扫描的操作了。这种简单的接口模式,让MySQL的存储引擎插件式架构成为可能,但是正如前面的讨论,也给优化器带来了一定的限制。
并不是所有的操作都有handler完成。例如,当MySQL需要进行表锁的时候,handler可能会实现自己的级别的、更细粒度的锁,如InnoDB就实现了自己的行基本锁,但这并不能代替服务器层的表锁。如果是所有存储引擎共有的特性则由服务器层实现,比如时间和日期函数、视图、触发器等等。
为了执行查询,MySQL只需要重复执行计划中的各个操作,知道完成所有的数据查询。
返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。即使查询不需要返回结果集给客户端,MySQL仍然会返回这个查询的一些信息,如该查询影响到的行数。如果查询可以被缓存,那么MySQL在这个阶段也会将结果存放到查询缓存中。MySQL将结果集返回客户端是一个增量、逐步返回的过程。例如,我们回头看看前面的关联操作,一旦服务器处理完成最后一个关联表,开始生成第一条结果时,MySQL就可以开始向客户端逐步返回结果集了。这样处理有两个好处:服务器端无须存储太多的结果,也就不会因为要返回太多结果而消耗太多内存。另外,这样的处理也让MySQL客户端第一时间获得返回的结果。结果集中的每一行会以一个满足MySQL客户端/服务器通信协议的封包发送,再通过TCP协议进行传输,在TCP传输的过程中,可能对MySQL的风暴进行缓存然后批量传输。