目录
1、return基础介绍 📚
1.1 return用途:数据返回
1.2 return执行:函数终止
1.3 return深入:无返回值情况
2、yield核心概念 🍇
2.1 yield与迭代器
2.2 生成器函数构建
2.3 yield的暂停与续行特性
3、return与yield对比 🔍
3.1 执行流程差异
3.2 数据处理方式
3.3 应用场景分析
4、实战:return在函数编程中的应用 🛠️
4.1 简单数据处理函数
4.2 复杂逻辑控制流
4.3 异常处理与返回值
5、实战:yield在高效迭代中的威力 💨
5.1 动态数据生成
5.2 大数据处理优化
5.3 与迭代协议结合实战
6、协程与async/await的yield角色 🔄
6.1 协程基础
6.2 async函数中的yield
6.3 异步IO与yield的高效协作
6.4 yield from的深层理解
7、性能与适用场景分析 📊
7.1 return在性能上的考量
7.2 yield对内存的友好度
7.3 如何选择:return还是yield
7.4 实战项目中的最佳实践
8、总结与展望 🌌

1、return基础介绍 📚
1.1 return用途:数据返回
在Python中,return语句用于从函数中输出数据到调用者。当函数执行到return时,它会立即停止执行当前函数并返回指定的值。如果未指定返回值 ,函数默认返回None。例如,一个简单的函数用于计算两数之和并返回结果:
def add(a, b):
result = a + b
return result
sum_result = add(3, 4)
print(sum_result) # 输出:71.2 return执行:函数终止
return不仅用于传递数据 ,它的执行还意味着函数的终止。一旦遇到return ,不论函数内还有多少未执行的代码,都会直接结束执行并退出函数。例如:
def example():
print("Before return")
return
print("This won't be printed") # 这行不会执行
example() # 输出:Before return1.3 return深入:无返回值情况
如果函数没有显式地包含return语句 ,或者return后面没有跟任何表达式,那么该函数默认返回None。这在不需要函数产生具体输出 ,仅执行某些操作时很有用:
def print_hello():
print("Hello, world!")
result = print_hello()
print(result) # 输出:Hello, world! \n None在此例中 ,尽管print_hello函数打印了消息,但因为没有指定返回值,所以其实际返回None。
2、yield核心概念 🍇
2.1 yield与迭代器
在Python中,yield是一个强大的关键字 ,它允许一个函数在执行过程中保存状态,以便在后续调用中恢复执行。这种行为与传统的函数执行不同,后者在调用结束后清除所有局部变量。当一个函数包含了yield关键字,它就变成了一个生成器函数,每次调用生成器的__next__()方法时 ,函数从上次暂停的地方继续执行,直到遇到下一个yield语句。下面是一个生成斐波那契数列的例子:
def fibonacci(n):
a, b = 0, 1
while a < n:
yield a
a, b = b, a + b
fib = fibonacci(10)
for num in fib:
print(num, end=' ') # 输出:0 1 1 2 3 5 82.2 生成器函数构建
生成器函数与普通函数的主要区别在于它使用yield而非return。这使得生成器能够记住函数的状态,而不是像普通函数那样在执行完毕后清除状态。生成器的这一特性使其非常适合处理大量数据或无限序列 ,因为它们只在需要时生成数据,从而节省内存。创建生成器函数后,通过调用它来获取生成器对象,然后可以使用next()函数或迭代协议来访问生成的数据。
def count_up_to(max):
count = 1
while count <= max:
yield count
count += 1
counter = count_up_to(5)
for number in counter:
print(number) # 输出:1 2 3 4 52.3 yield的暂停与续行特性
yield语句使函数能够在执行过程中暂停,并在下次调用时从暂停点继续执行。这意味着,即使函数中有多个yield语句 ,函数也不会从头开始执行 ,而是从上次暂停的yield之后的代码行开始执行。这一特性使得生成器能够高效地处理数据流,因为它们不需要存储整个数据集在内存中 ,而是按需生成数据。
def number_generator():
for i in range(3):
yield i
print("After yield:", i)
gen = number_generator()
print(next(gen)) # 输出:0
print("Outside generator") # 输出:Outside generator
print(next(gen)) # 输出:After yield: 0 \n 1
print(next(gen)) # 输出:After yield: 1 \n 2在这个例子中,可以看到每当yield语句执行后,函数会暂停并保存当前状态 ,随后可以继续从暂停处执行 ,展示yield的暂停与续行特性。
3、return与yield对比 🔍
3.1 执行流程差异
return关键字用于结束函数执行并返回一个值给调用者。一旦return被执行,函数立刻终止,局部变量也会被清理。例如:
def simple_return(x):
if x > 10:
return "大于10"
else:
return "小于等于10"
print(simple_return(15)) # 输出:"大于10"而yield则用于定义生成器函数 ,它允许函数暂停执行并在下一次迭代时从暂停点恢复,保留了函数的内部状态。例如:
def simple_yield():
yield 1
yield 2
yield 3
gen = simple_yield()
print(next(gen)) # 输出:1
print(next(gen)) # 输出:23.2 数据处理方式
return通常用于一次性返回计算结果 ,适合于处理有限且确定数量的数据。例如 ,一个计算两个数字之和的函数会直接返回总和。
def sum_two_numbers(a, b):
return a + b
print(sum_two_numbers(4, 5)) # 输出:9相比之下,yield支持按需生成数据,特别适用于处理大量数据或无限序列,如遍历文件行或生成斐波那契数列。
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
fib_gen = fibonacci()
for _ in range(10):
print(next(fib_gen), end=' ') # 输出:0 1 1 2 3 5 8 13 21 343.3 应用场景分析
-
• return常用于简单数据处理或计算任务 ,当函数需要一次性返回计算结果时。例如,数据验证、简单的转换逻辑或算法实现等。
-
• yield则在需要逐个访问元素的场景下大放异彩,特别是对于大数据处理、流式处理、或是实现迭代器和协程等高级编程模式。它能够显著提高程序的内存效率,特别适合处理数据量庞大的情境,如日志分析、实时数据流处理等。
通过上述对比 ,我们可以看到return和yield在数据处理和执行流程上的根本差异,以及它们各自适用的典型应用场景。正确选择它们,能够帮助开发者编写出更高效、更灵活的代码。
4、实战:return在函数编程中的应用 🛠️
4.1 简单数据处理函数
在日常开发中,return最常见于简单的数据处理函数,如计算数值、转换数据类型或格式化字符串等。下面的例子展示了如何使用return来实现一个简单的温度转换函数:
def celsius_to_fahrenheit(celsius):
return celsius * 9 / 5 + 32
fahrenheit = celsius_to_fahrenheit(30)
print(fahrenheit) # 输出:86.04.2 复杂逻辑控制流
当函数需要处理复杂的逻辑分支或循环结构时 ,return同样扮演着关键角色。它能够帮助提前终止函数执行 ,避免不必要的计算 ,特别是在条件满足时立即返回结果。下面的例子展示了一个函数,该函数在数组中查找特定元素,找到后即刻返回其位置:
def find_element(arr, target):
for index, value in enumerate(arr):
if value == target:
return index
return -1
index = find_element([1, 2, 3, 4, 5], 3)
print(index) # 输出:24.3 异常处理与返回值
在处理潜在错误或异常情况时,return也非常重要。它允许函数在检测到错误时立即返回一个错误码或异常信息 ,便于调用方处理。下面的示例展示了如何使用try-except块结合return来优雅地处理除零错误:
def safe_division(dividend, divisor):
try:
return dividend / divisor
except ZeroDivisionError:
return "Error: Division by zero"
result = safe_division(10, 0)
print(result) # 输出:Error: Division by zero通过上述实战案例,我们可以看到return在不同场景下的运用方式,无论是基础的数据处理、复杂的逻辑控制还是异常处理,return都提供了强大而灵活的功能 ,使得函数设计更加健壮和高效。
5、实战:yield在高效迭代中的威力 💨
5.1 动态数据生成
yield使得生成器成为动态数据生成的强大工具,它能够按需生成数据项,特别适合处理无穷序列或内存敏感的场景。例如,下面的生成器函数可用来生成连续的自然数:
def infinite_sequence():
num = 1
while True:
yield num
num += 1
# 打印前5个自然数
for count, number in zip(range(1, 6), infinite_sequence()):
print(count, number)
# 输出:1 1, 2 2, 3 3, 4 4, 5 55.2 大数据处理优化
在处理大量数据时,一次性加载所有数据可能会导致内存溢出。通过使用yield,可以逐步处理数据,仅在需要时加载数据片段 ,极大降低了内存消耗。例如,假设我们要处理一个大型文件,每次读取一行:
def read_large_file(file_path):
with open(file_path, 'r') as file:
for line in file:
yield line.strip()
# 假设file.txt为待处理的大文件
for line in read_large_file('file.txt'):
process(line) # 假定process为处理每一行数据的函数5.3 与迭代协议结合实战
yield配合迭代器协议,可以构建复杂的数据处理流程。迭代器协议要求对象实现__iter__和__next__方法,而生成器自动实现了这些方法。下面是一个结合生成器和列表推导的例子,展示如何高效筛选数据:
def filter_even(nums):
for num in nums:
if num % 2 == 0:
yield num
numbers = [1, 2, 3, 4, 5, 6]
even_nums = (num for num in filter_even(numbers)) # 使用生成器表达式进一步封装
print(list(even_nums)) # 输出:[2, 4, 6]通过上述实战应用,我们见识到了yield在实现动态数据生成、优化大数据处理以及构建复杂迭代流程中的独特优势。它不仅提升了代码的效率和灵活性,也为处理大规模数据集提供了内存友好的解决方案。
6、协程与async/await的yield角色 🔄
6.1 协程基础
协程是一种比线程更轻量级的并发机制,它允许在一个进程中同时运行多个函数,通过asyncio库在Python中实现。协程的核心概念是能够在执行过程中挂起和恢复,这种能力由yield语句的后代await关键字实现。在Python中,使用async def定义的函数会生成一个协程对象,这个对象可以挂起并等待异步操作完成。虽然yield本身不直接支持并发 ,但结合asyncio库和协程的概念,可以实现异步生成器 ,从而在非阻塞环境中处理多个任务或数据流。
import asyncio
async def slow_operation(n):
await asyncio.sleep(1)
return n * n
async def produce_squares(numbers):
for number in numbers:
yield await slow_operation(number)
async def main():
squares = [s async for s in produce_squares(range(5))]
print(squares)
asyncio.run(main()) # 输出:[0, 1, 4, 9, 16]6.2 async函数中的yield
在Python 3.5及更高版本中,yield被await取代用于异步操作。await用于等待一个协程对象的完成,而async def定义的函数会返回一个协程对象。下面是一个使用await的简单示例,展示了如何在协程中等待另一个协程的完成:
import asyncio
async def my_coroutine():
await asyncio.sleep(1) # 模拟耗时操作
print("协程执行完毕")
async def main():
task = asyncio.create_task(my_coroutine())
await task
asyncio.run(main())
# 输出:协程执行完毕6.3 异步IO与yield的高效协作
在处理I/O密集型任务时,如网络请求、文件读写等,协程通过await能够极大地提升效率。在等待I/O操作时,协程会挂起,让其他协程运行,从而充分利用CPU资源。例如,下面的代码展示了如何使用aiohttp库异步下载多个网页:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ['https://example.com', 'https://example.org']
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
results = await asyncio.gather(*tasks)
for result in results:
print(len(result))
asyncio.run(main())通过上述示例 ,可以看出await如何在异步I/O操作中发挥关键作用,实现非阻塞的高效数据处理。协程和async/await语法使得编写高并发的网络应用变得既简单又直观。
6.4 yield from的深层理解
yield from语法允许一个生成器将其部分或全部迭代委托给另一个可迭代对象,包括其他生成器。这简化了生成器间的嵌套调用和数据传递,提高了代码的可读性和维护性。
def chain(*iterables):
for it in iterables:
yield from it
print(list(chain([1, 2], ['a', 'b']))) # 输出:[1, 2, 'a', 'b']7、性能与适用场景分析 📊
7.1 return在性能上的考量
return语句在性能上通常对函数调用栈影响较小,因为它直接结束函数执行并返回结果。在不需要保留函数状态或处理大量数据流的场景中 ,return因其简洁明了,成为首选。性能损耗主要体现在函数调用的开销,而非return语句本身。
7.2 yield对内存的友好度
yield在处理大数据集时表现出了极高的内存效率,因为它仅在需要时产生下一个值 ,而非一次性生成整个结果集合。这种“懒惰”计算模式大大减少了内存占用 ,特别适用于处理如文件读取、大规模数据流处理等场景。生成器在迭代过程中保持状态,仅当迭代发生时分配必要的内存。
7.3 如何选择:return还是yield
选择return还是yield取决于具体需求:
-
• 一次性计算:如果函数的任务是完成一个计算并立即返回结果 ,使用
return。 -
• 数据流处理:处理大量数据或需要逐个产生数据项时,
yield和生成器更为合适。 -
• 状态保留:需要在多次调用间保持函数状态时 ,
yield能自然地暂停和恢复执行。 -
• 内存敏感场景:对内存使用敏感的应用,
yield可以有效降低内存消耗。
7.4 实战项目中的最佳实践
-
• 文件读取:利用生成器逐行读取大文件,避免一次性加载整个文件到内存。
def read_large_file(file_path):
with open(file_path, 'r') as file:
for line in file:
yield line
for line in read_large_file('large_file.txt'):
process(line) # 对每一行进行处理-
• 网络爬虫:分页抓取大量数据时,使用生成器控制请求和解析过程,避免内存溢出。
def page_crawler(start_url, max_pages):
current_page = 1
while current_page <= max_pages:
url = f"{start_url}?page={current_page}"
content = fetch(url) # 假设fetch函数获取网页内容
yield parse_content(content) # 解析内容并返回
current_page += 1通过上述分析 ,我们了解到return和yield在不同场景下的性能特点和适用条件。选择合适的控制流机制,不仅能够提升程序效率,还能确保代码的可读性和可维护性。在实际项目中灵活运用这些知识,是优化应用程序的关键。
8、总结与展望 🌌
在Python编程实践中,return与yield作为函数执行路径上的重要机制 ,分别扮演了数据传递与迭代生成的关键角色。return直接输出函数结果 ,终止执行;而yield则构建了状态保留的生成器 ,适合流式处理与内存优化。面对不同的数据处理需求 ,恰当选取二者至关重要。未来,Python的异步编程与协程模型 ,通过async/await深化了yield的应用,预示着在高效I/O处理与并发编程领域持续演进,凸显了语言的灵活性与生态的前瞻性。



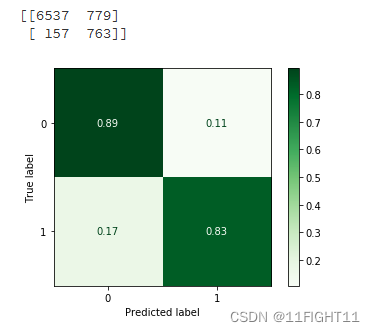
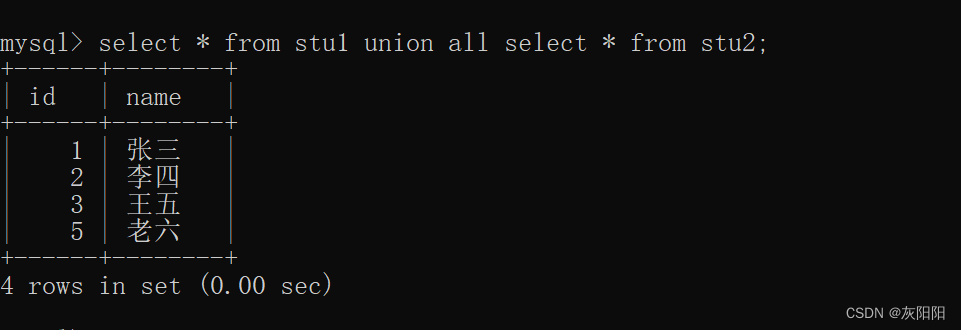
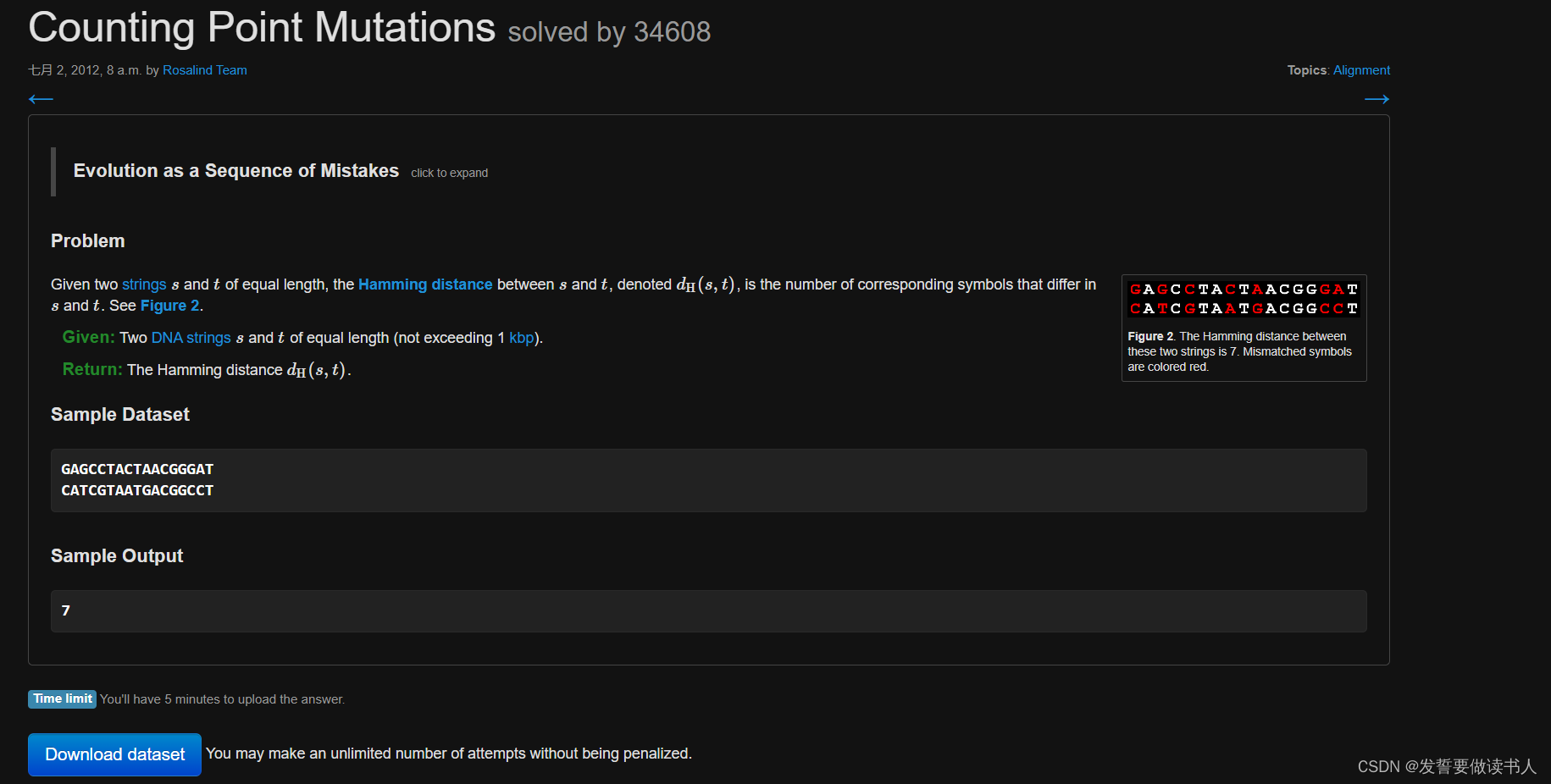



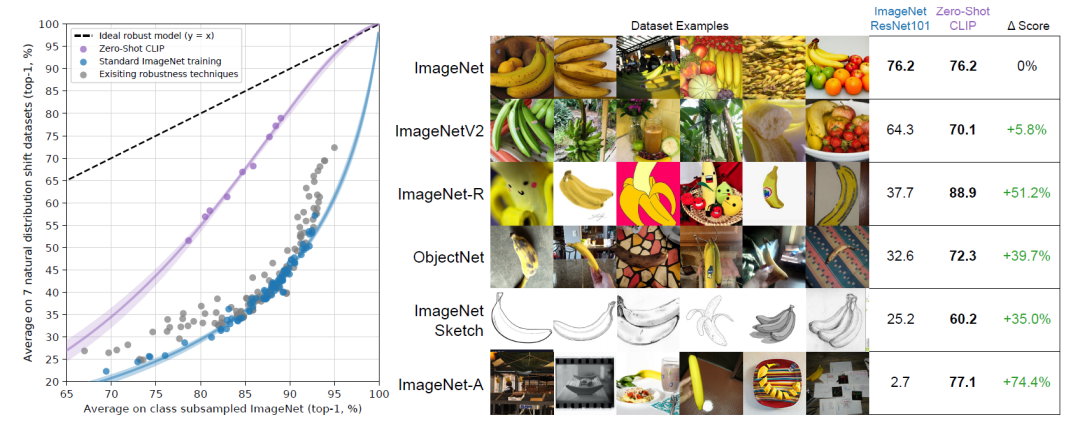






![已解决Error || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]](https://img-blog.csdnimg.cn/direct/aa86eef0d81e4f279688a772e92ea3bc.webp#pic_center)
