目录
一、表的设计
1.第一范式(一对一)
定义:
示例:
2.第二范式(一对多)
定义:
要求:
示例:
3.第三范式(多对多)
定义:
要求:
示例:
二、表的查询
表的拷贝(新增)
聚合查询
1.聚合函数:
2.group by(分组)
3.having(条件句)
联合查询
1.笛卡尔积
2.内连接
3.外连接
左外连接:
右外连接:
全外连接(了解)
4.自连接
子查询
使用子查询——‘=’:
子查询——'in'
子查询——‘all’
子查询——‘any’
子查询——‘exists’(较为重要)
示例一:
示例二:
示例三:
合并查询
union:
union all:
一、表的设计
数据库设计的三大范式是数据库规范化过程中重要的概念,它们通过一系列规则来减少数据冗余、提高数据的一致性。咱们只要按照这个规则,按部就班的设计,就可以,不难。
1.第一范式(一对一)
定义:
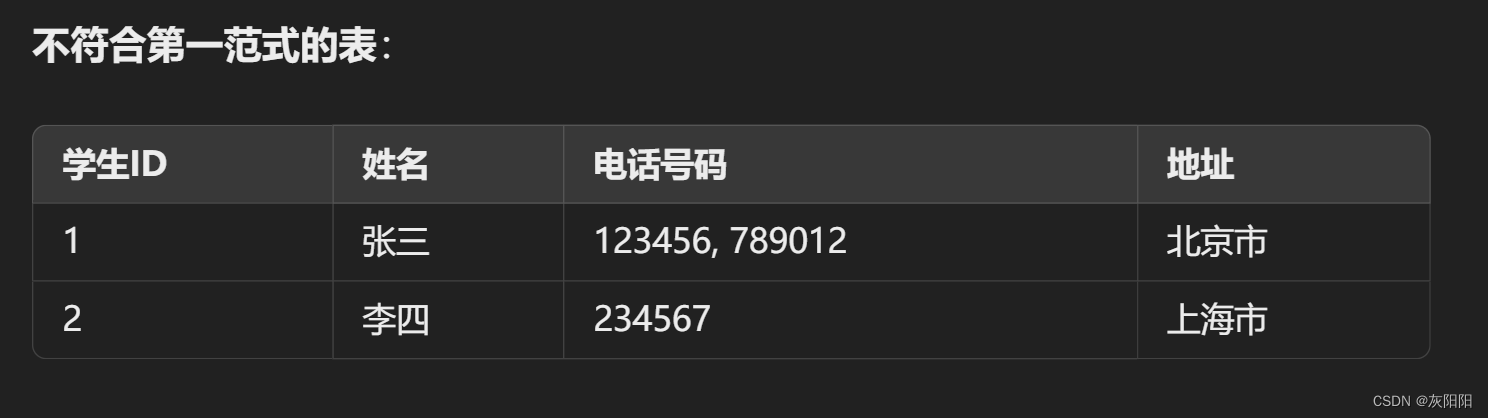
所有列的值都是原子的,即每列不能包含多个值或重复的组。
要求:
- 每个表格的每个字段值都是不可分割的原子值。
- 每一行中的值都唯一。
原子就是一个对象的一个属性,例如:
描述一个人,性别、年龄、电话等都是一个原子。
示例:
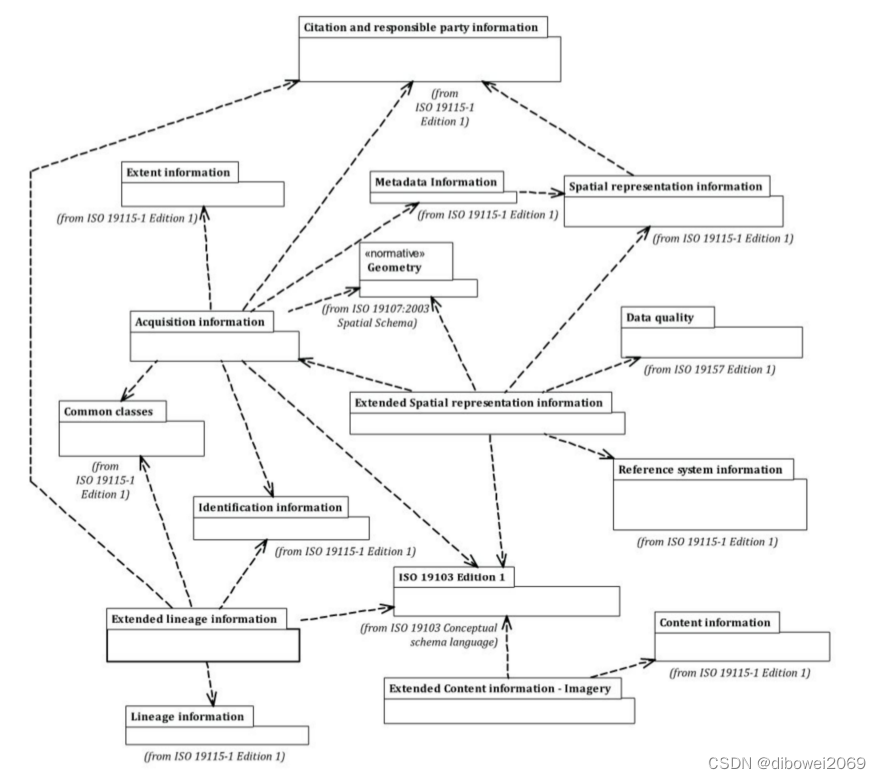
假设我们有一个包含学生信息的表格,其中包括学生的姓名、电话号码和地址。
如果一个学生有多个电话号码,第一范式要求我们将这些电话号码分开,每个电话号码放在单独的一列中,而不是一个列中包含多个电话号码。
2.第二范式(一对多)
定义:
在满足第一范式的基础上,非主属性必须完全依赖于主键,消除部分依赖。
要求:
- 必须先满足第一范式。
- 非主键列必须完全依赖于主键列。
示例:
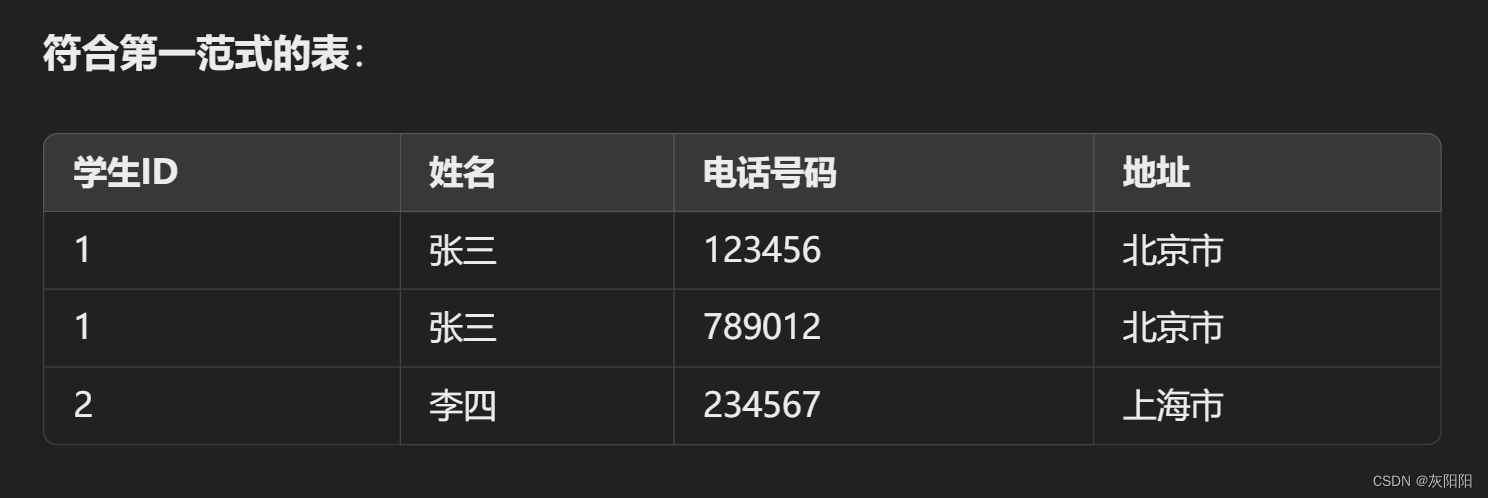
假设我们有一个课程登记的表格,其中包含学生ID、课程ID、课程名称和成绩。这里学生ID和课程ID是联合主键。课程名称仅依赖于课程ID而不是联合主键。
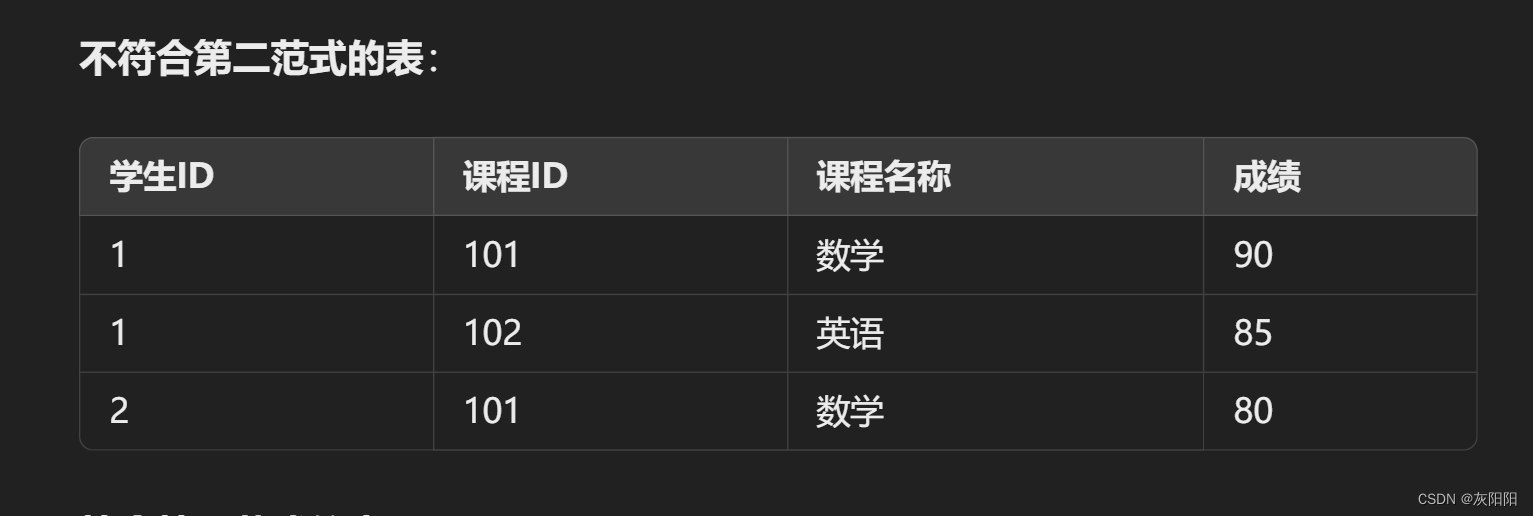
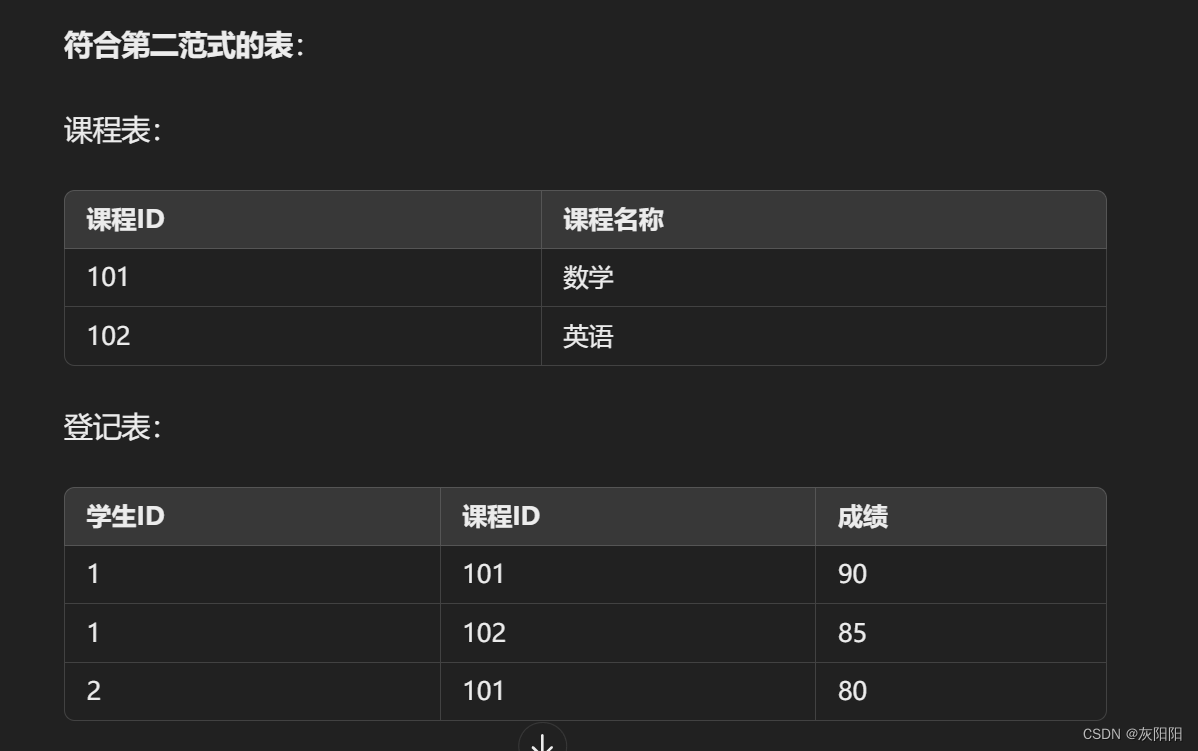
在第二范式中,两个表要有同一个相同主键(字段),示例中就是课程ID,这样才能把两个表建立联系。
3.第三范式(多对多)
定义:
在满足第二范式的基础上,消除传递依赖,即非主属性不依赖于其他非主属性。
要求:
- 必须先满足第二范式。
- 非主键列不能依赖于其他非主键列。
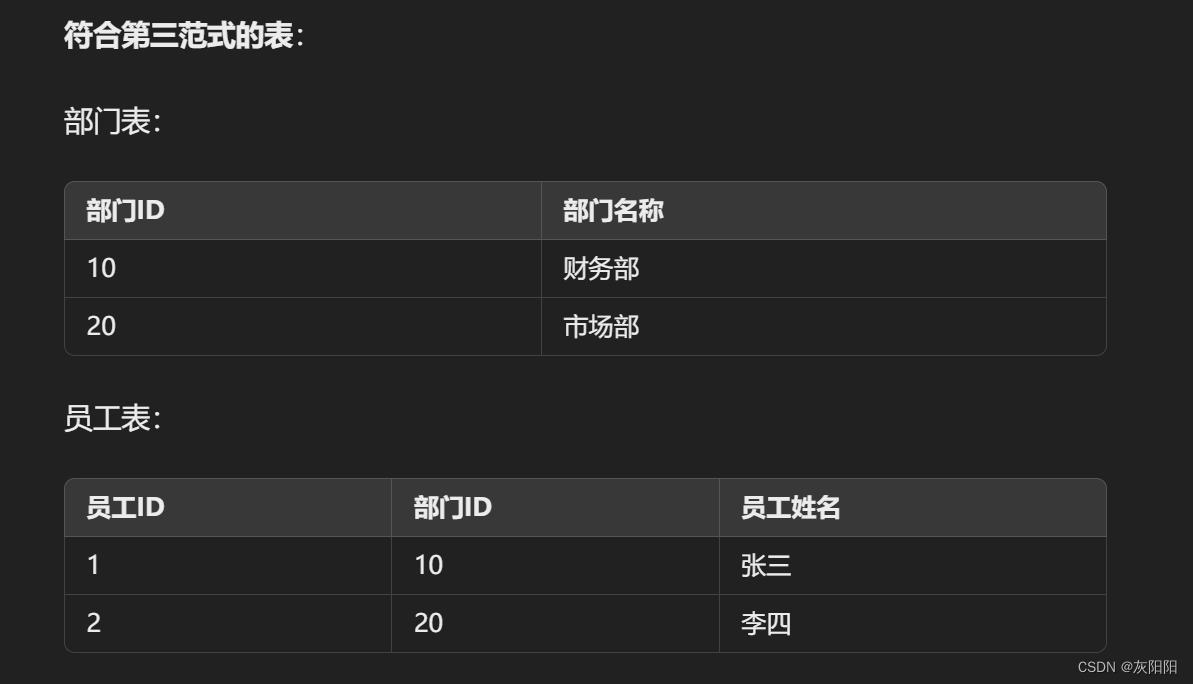
示例:
假设我们有一个员工信息表格,其中包括员工ID、部门ID、部门名称和员工姓名。这里部门名称依赖于部门ID,而部门ID是主键。
二、表的查询
表的拷贝(新增)
在介绍查询之前,新增表的一个语法介绍一下。
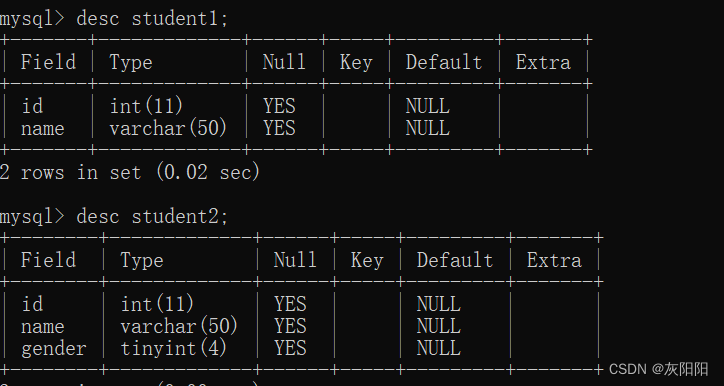
如图这里是两个学生表的结构:
两个表的内容:
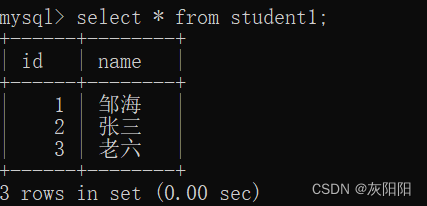
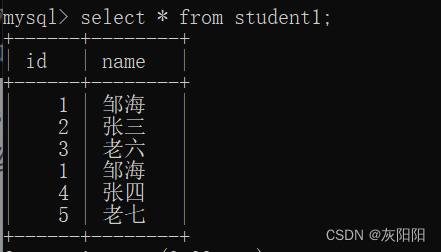
student1:
student2:
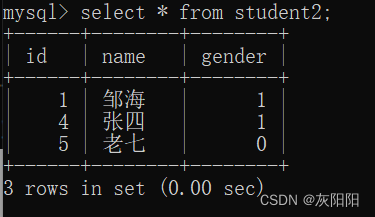
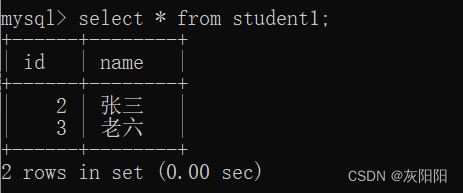
假设有这样一个场景:
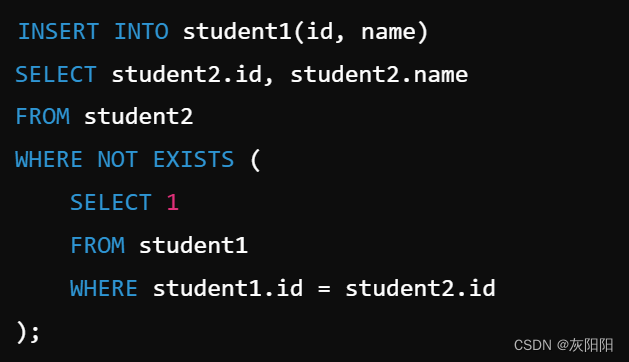
我们要把student2表中的内容,新增添加到student2表中(gender这个字段不添加),那么可以这样做:
insert 后面不加values 而是用select替代。
最终的student1表:
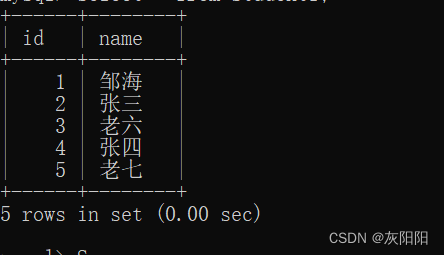
如果想要避免增加重复的数据可以这样:
最终结果:

聚合查询
1.聚合函数:
听起来很高级,实际上就是对数据表中的每一行中特定的一个字段进行数学计算:
COUNT([DISTINCT] expr)
说明: 返回查询到的数据的 数量 SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义
AVG([DISTINCT] expr)
说明: 返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr)
说明: 返回查询到的数据的 最大值,不是数字没有意义
MIN([DISTINCT] expr)
说明: 返回查询到的数据的 最小值,不是数字没有意义
示例:
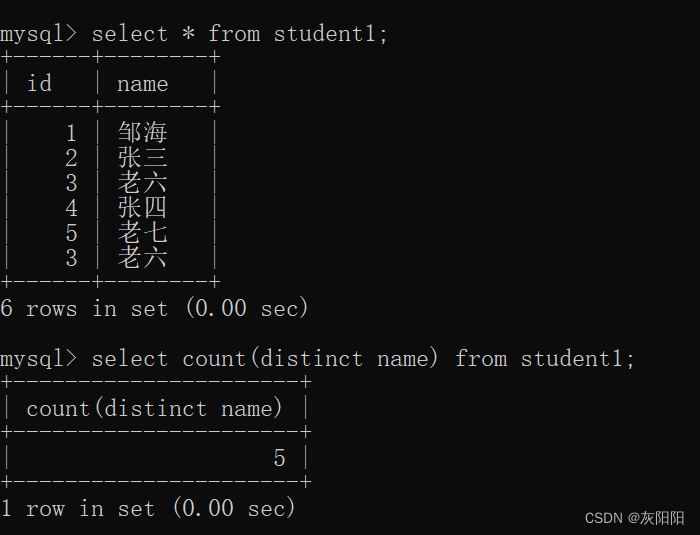
可见,聚合函数的操作对象是某一列的所有相同类型的数据的。
2.group by(分组)
select 语句指定的字段必须是group by中的,如果要显示其他字段,需要把其他的字段搭配聚合函数使用才可以。

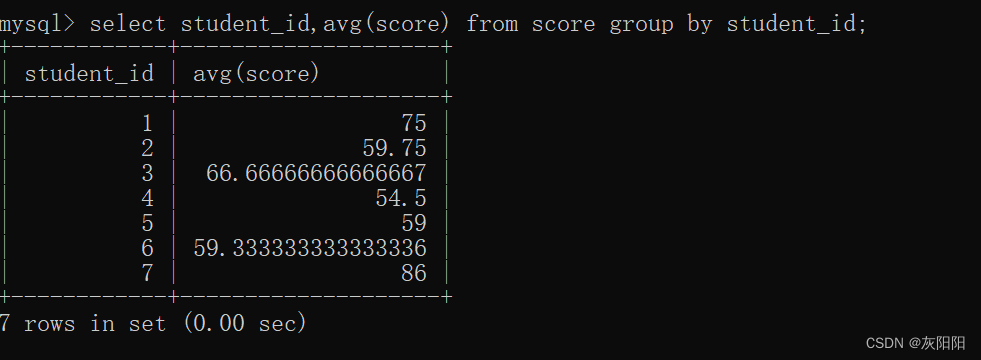
示例:
以学生id进行分组,求每一个学生的平均成绩:
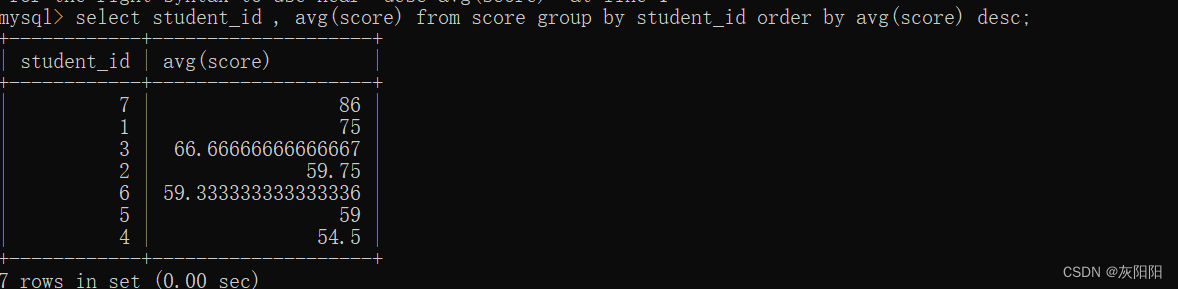
如果要排列平均成绩的降序,那么order by要写到最后,desc写到 order by 的后面:
3.having(条件句)
having和where功能是一样的,用来筛选条件,只是使用group by语句后不能使用where,要使用having才可以。
示例,查找平均成绩大于60的同学(降序):

order by语句仍然是要写到最后的。
联合查询
联合查询类型有好几种,不用特意去记忆,只需要在特定场景使用特定方式查询即可。
1.笛卡尔积
要理解联合查询,要先了解笛卡尔积。
对就是离散数学里面的那个。
听起来很高级,实际上很简单,就是对两个集合的排列组合。
如图,对下面两个表进行笛卡尔积(排列组合):
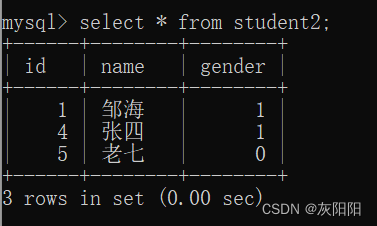
笛卡尔积后: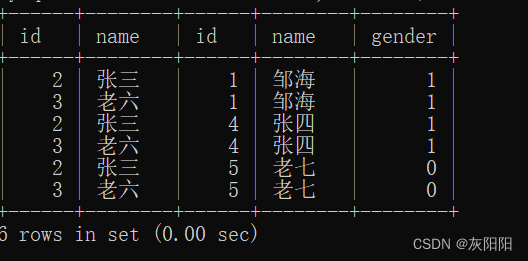
笛卡尔积后的集合数量(6)就是之前两个集合数量之积(2*3)。
下面的联合查询都必须先进行笛卡尔积。
注意:
多表联合查询会产生大量数据,如果原始两个表的数据本身就很多,这对性能影响很大,有时候甚至会把服务器搞挂,因此,要慎重,在操作前,预估一个范围。
2.内连接
解释:显示字段相互匹配的行数据。
语法:
inner 可加可不加。

示例:
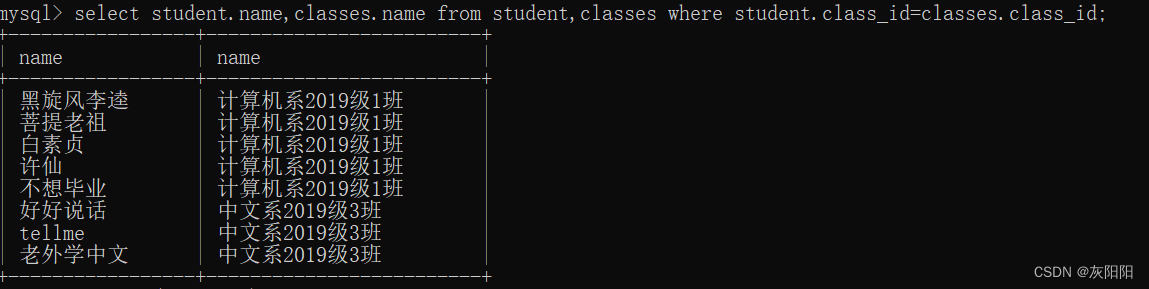
如图student表:
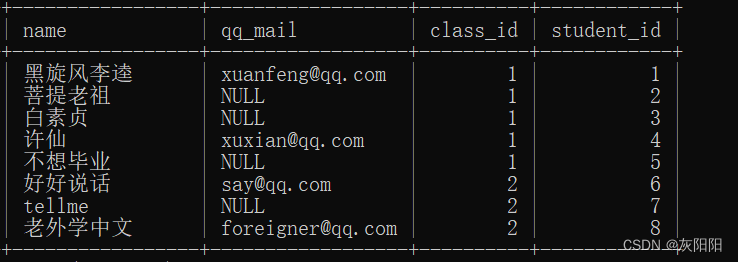
classes表:

若我们想查询每一个学生对应哪一个班级,就可以使用内连接来进行(因为两个表恰好可以靠class_id来进行联系)
使用join来进行:
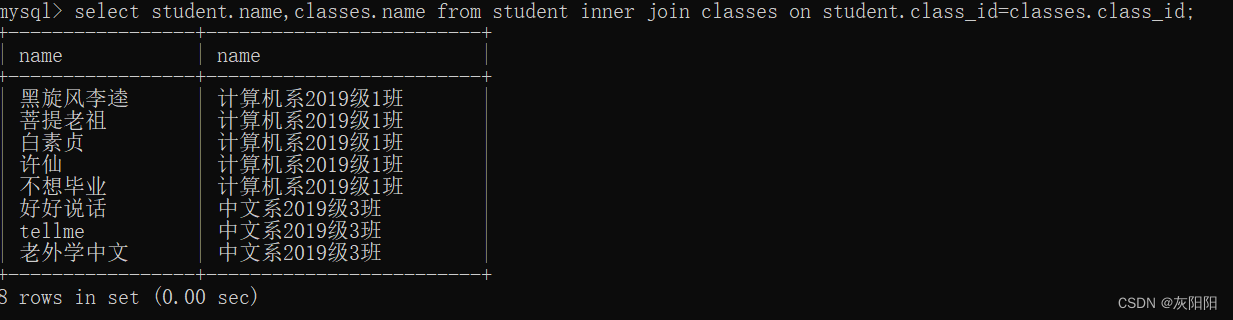
使用where:
3.外连接
外连接和内连接一样,两个表要有同一个含义的字段建立起连接。
外连接分为左外连接和右外连接。
左外连接:
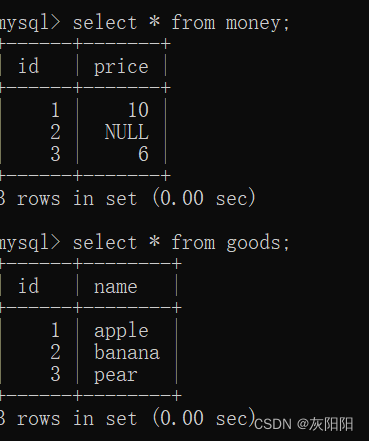
如图商品表(goods)和单价表(price):
如果我们要显示一个表,每一行包含name和对应的价格,那么如图:
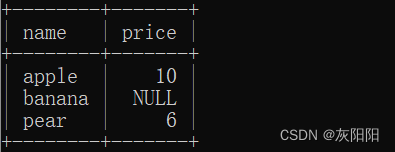 这就是一个左外连接表。
这就是一个左外连接表。
这里的左,意思就是以左边的name为基准,显示表中所有的name,如果另一个表中,没有对应的商品价格,就设置为默认值。
语法:

右外连接:
其实就是左外连接的反向版本,以右边的表作为基准,全部显示,左边的表如果没有与之匹配的显示默认值。
示例:
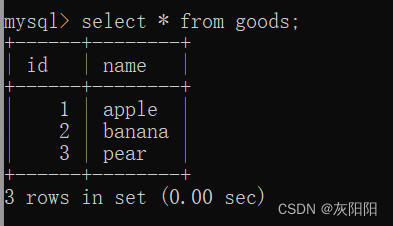
如图goods表和money表:
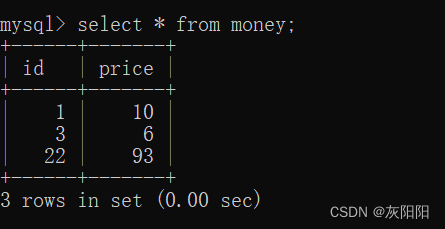
右外连接后的表:

语法格式:

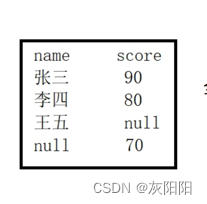
全外连接(了解)
MySQL不支持全外连接,不过oracle支持。
全外连接其实就是左、右外连接的复合:
4.自连接
自连接就是自己和自己笛卡尔积。
自己和自己笛卡尔积有什么用?
来我们看下面这个示例:
如图,对分数表进行自连接:
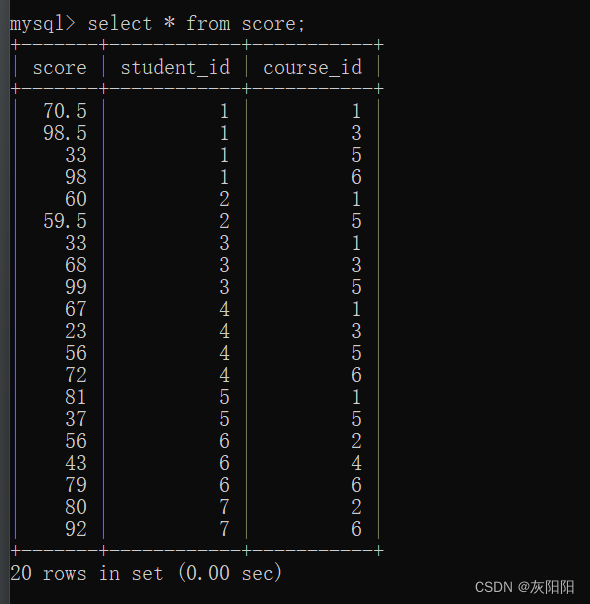
使用语句:

唉,我们发现出问题了,显示说出现重复的别名,那么该如何跟自己笛卡尔积呢?
很简单,分别进行取别名即可:
select * from score as sc1,score as sc2;
这里就不展示笛卡尔积后的结果了,因为数据量太大。
我们先回过头来看一下子表的结构:
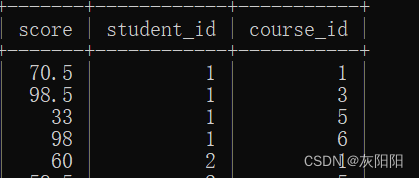
假如说我们有这样一个查询需求,查询课程五分数比课程三 成绩高的同学,你会怎么做?
事先说明:
在sql中条件查询比较的都是同一行的不同列的字段。不能行与行进行比较。
因此不能直接用条件句去判断,这是自连接就派上用场了!
子表中的一列只有一个score。
咱们笛卡尔积一下不就有两个score了吗?
这样不就可以比较了?
问题不就解决了吗?
如图先筛选出既有3课程又有5课程的同学:

然后对表进行简化:

在语句后面多加一个条件既,课程五分数要大于课程三分数:

这就是我们依靠自连接得到的答案了。
自连接的优势实际上就是,把行无法比较的问题,转化成列可以比较的问题。
5.联合查询的基本思路(及其重要)
1、分析查询需要用到那些表
2、使用这些表进行笛卡尔积
3、指定连接条件
4、进一步指定其他条件/聚合操作
5、对最终的表进行简化
子查询
子查询并不推荐,因为代码看起来会比较复杂
子查询实际上就是用学过的语法进行套娃。
示例:
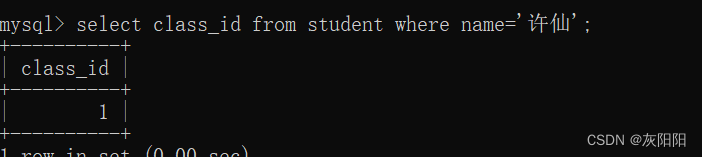
假如说咱们要查询许仙同班同学的名字:
正常的写法:
1、查看整个表
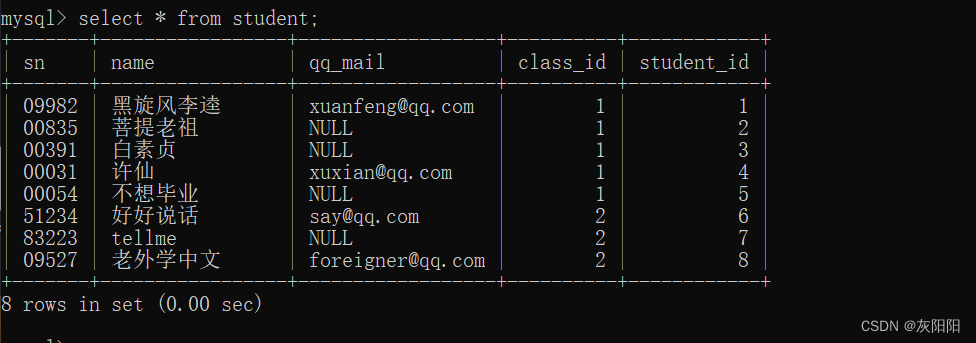
2、查找许仙的班级:
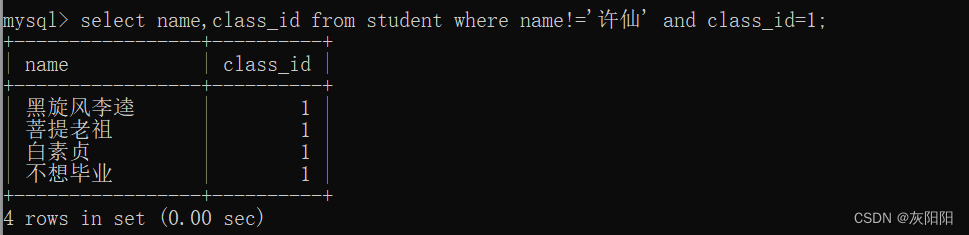
3、 查询同班同学:
使用子查询——‘=’:

一步到位,但是缺点也很明显,代码复杂不易理解,尤其是出现多层嵌套的话。
‘=’子查询中,子句只返回一个值,不能返回多个值
子查询——'in'(条件是一个范围的时候使用)
返回多个结果。
假如说我们要查询分数大于80的同学:
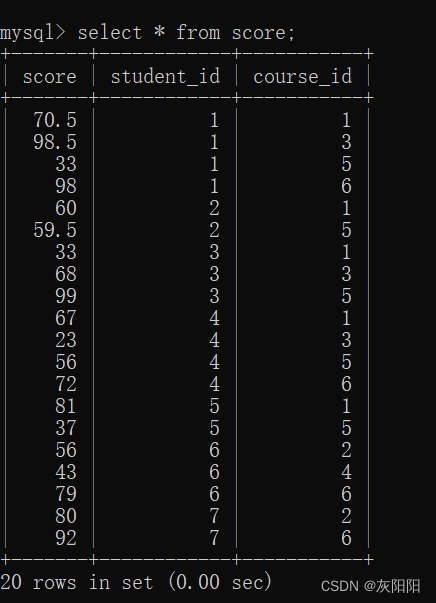
那么可以使用in,不能使用=:
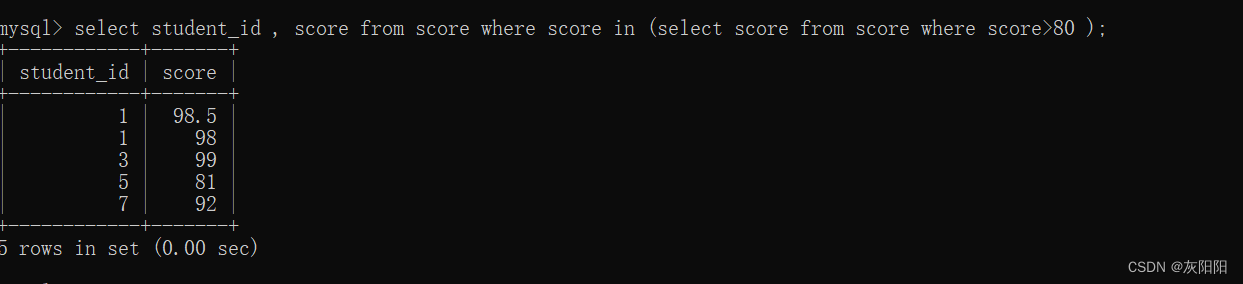
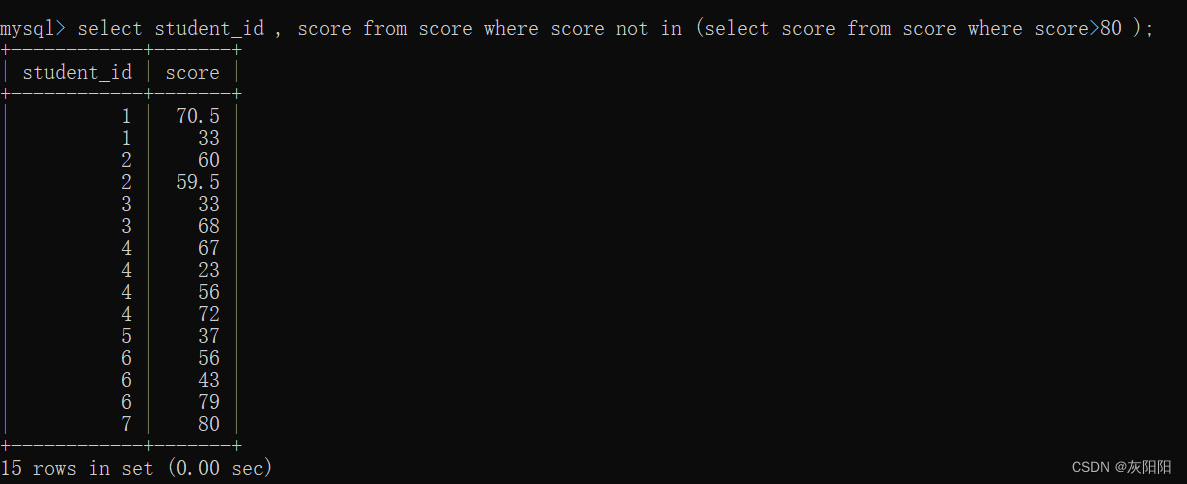
如果是查询小于80分的同学,直接NOT IN 即可:
子查询——‘all’
查询条件必须满足all关键字后面的所有条件。
示例:
查询最高分:

子查询——‘any’
any和some功能是一样的,any或者some内只要有一个条件满足就成立。
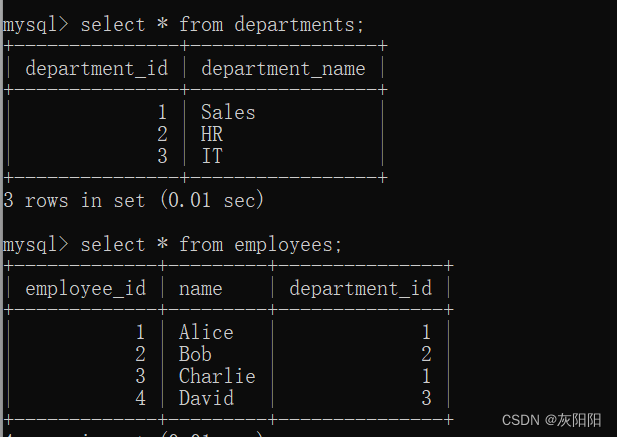
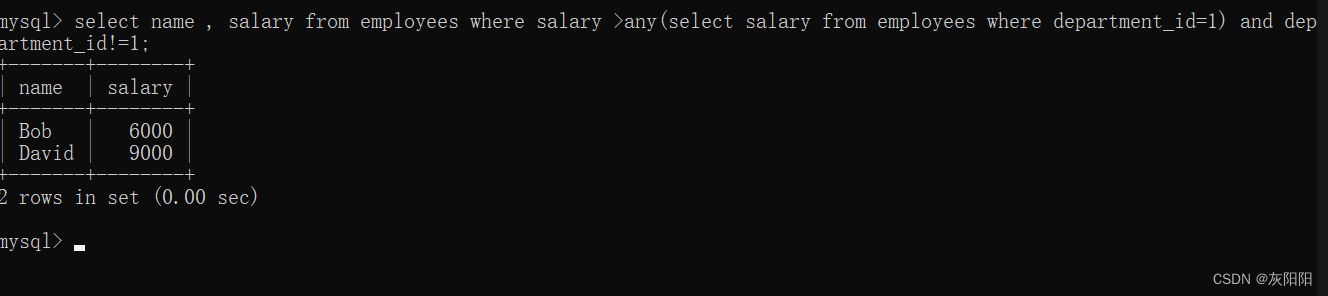
如图,查询一个非Sales部门的员工,他的薪资高于Sales部门所有员工的薪水:
那么可以使用any子查询:
换成some是一样的:

子查询——‘exists’(较为重要)

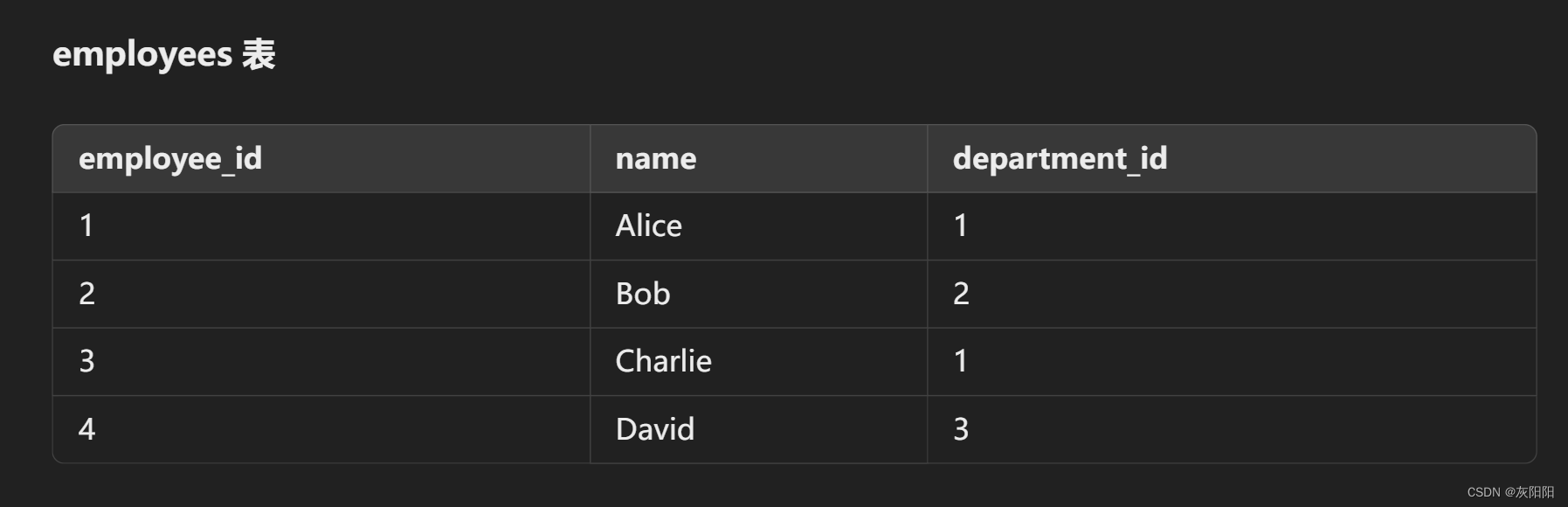
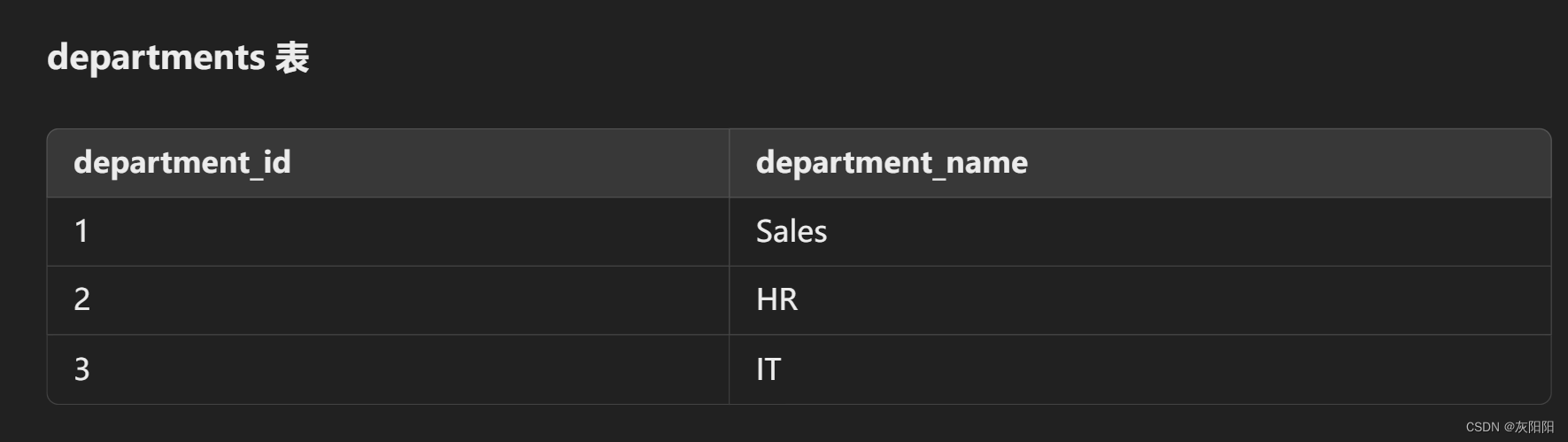
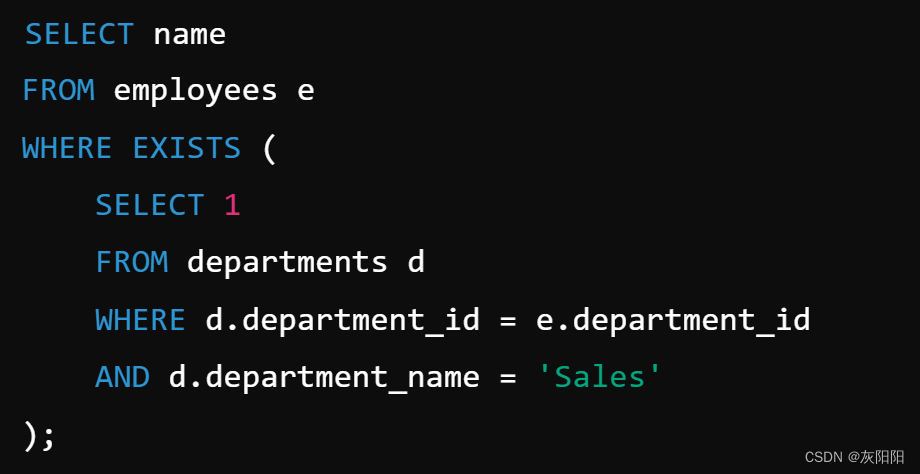
示例一:
查询Sales部门的所有成员:
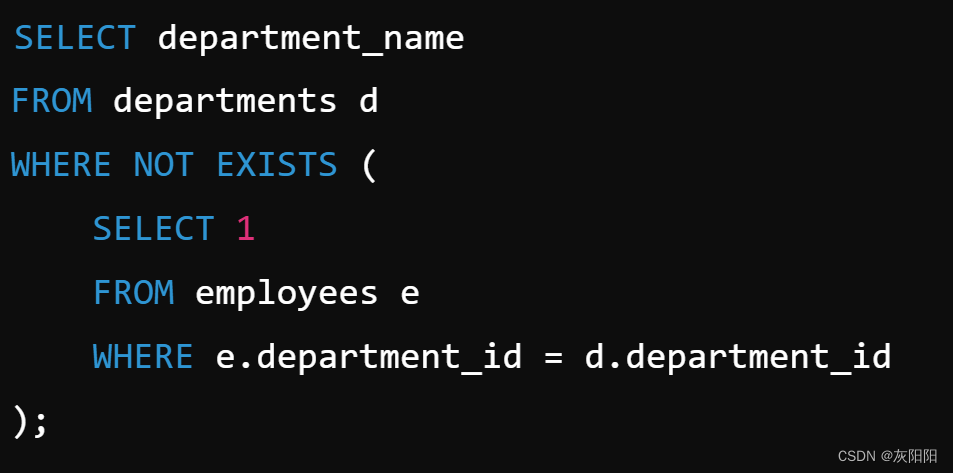
示例二:
查找一个部门,这个部门一个员工都没有:
示例三:
查看某个部门,这个部门的人数必须大于1.
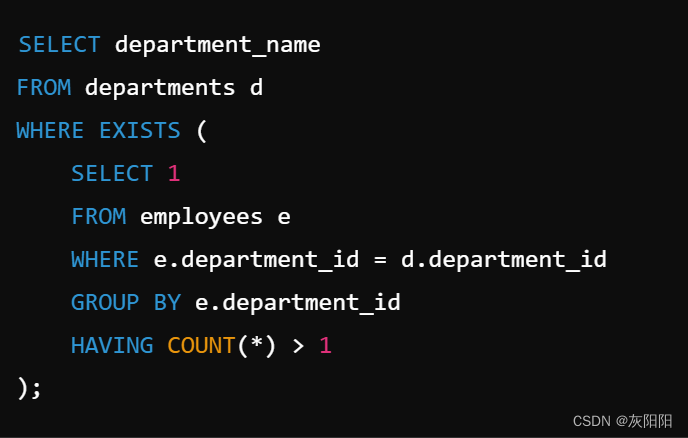
查询结果:
合并查询
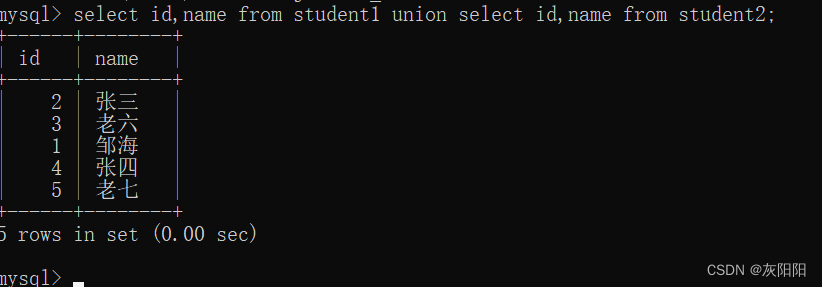
union:
如图两张不同的学生表:
student1:
student2:
如果要查询老六和老七该如何做呢?
因为是两张不同的表,所以不能使用or,这是合并查询就派上用场了:

注意:
1、or和union功能差不多,但是nuion适用范围更加广泛。
2、union 会默认去除相同数据,在原表的基础上,下面的张三只出现了一次:
3、union和union all要求两张表中所查询的字段类型、个数、顺序必须一致(列名不要求)
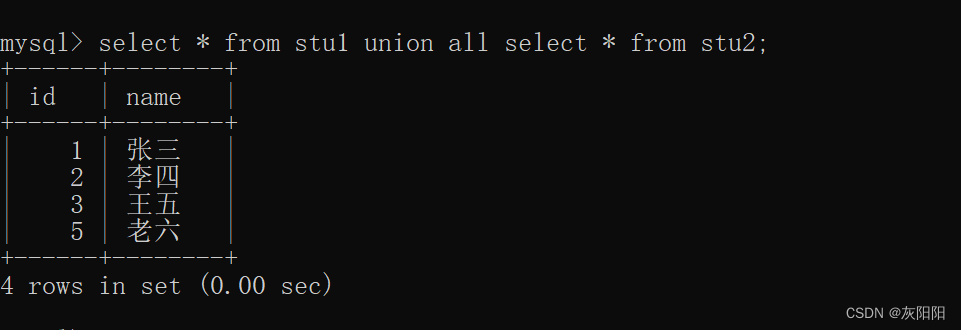
union all:
功能和union一样:









![已解决Error || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]](https://img-blog.csdnimg.cn/direct/aa86eef0d81e4f279688a772e92ea3bc.webp#pic_center)