简答题 (3)
顺序表和链表的概念及异同
- 顺序表: 把逻辑上相邻的结点储存在物理位置上的相邻储存单元中,结点的逻辑关系由储存单元的邻接关系来体现.
- 链表: 逻辑上相邻的结点存储再物理位置上非连续非顺序的存储单元中, 结点的逻辑关系由指向下一个结点的指针确保.
- 相同点
- 都是线性表结构.
- 结点逻辑上都是连续的.
- 每个结点都有唯一的前驱和唯一的后续(首结点无前驱, 尾结点无后继).
- 不同点
- 物理存储方式不同: 物理空间上连续 vs 不连续.
- 插入和删除方式不同: 任意位置插入或删除, 需要搬运大量元素, 时间复杂度 O ( n ) O(n) O(n) vs 无需搬运元素, 时间复杂度 O ( 1 ) O(1) O(1).
- 随机访问不同: 支持随机访问, 时间复杂度 O ( 1 ) O(1) O(1) vs 只能顺序访问, 时间复杂度 O ( m ) O(m) O(m).
- 是否需要扩容: 容量不足时, 开辟新空间拷贝元素, 平均时间复杂度为 O ( 1 ) O(1) O(1) vs 无需扩容.
- 空间利用率不同: 利用率高 vs 利用率低, 额外存储指针信息, 空间碎片化.
- 缓存利用率不同: 利用率高, 空间局部性好 vs 利用率低, 空间局部性差.
- 应用场景不同: 适合随机访问频繁, 插入删除少 vs 适合插入删除频繁, 随机访问少.
栈和队列的概念及异同
- 栈: 只允许在一端插入或删除的线性表.
- 队列: 只允许在一段插入, 而在另一端删除的线性表.
- 相同点
- 都是受限的线性表结构.
- 插入操作都限定在表尾进行.
- 都可以通过顺序结构或链式结构实现.
- 插入与删除的时间复杂度均为 O ( 1 ) O(1) O(1), 空间复杂度一致.
- 不同点
- 删除结点位置不同: 在表尾进行, FILO(先入后出) vs 在表头进行, FIFO(先入先出).
- 是否支持空间共享: 单调栈可以实现多栈空间共享 vs 顺序队列不能.
- 应用场景不同: 括号匹配, 表达式转换与求值, 函数调用和递归实现, DFS搜索或遍历 vs 系统资源管理, 消息缓冲管理(TCP), BFS搜索或遍历.
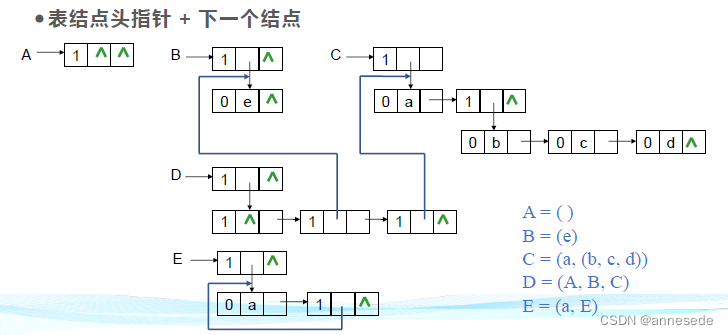
广义表存储方式及深度计算
- 存储方式
- 链式存储; 表头或表尾只考虑当前层.
- 表头-表尾表示法
- 头指针指向表头.
- 结点间需依靠额外的表头结点相连.
- 表结点: 标志(值为 1 1 1), 数据指针, 后继指针(已为表尾时指向 NULL).
- 原子结点: 标志(值为 0 0 0), 值.
- 空表为 NULL.
- 表头-后继表示法
- 头结点(特殊表结点)指向表头.
- 表结点: 标志(值为 1 1 1), 表头指针, 后继指针(已为表尾时为 NULL).
- 原子结点: 标志(值为 0 0 0), 值, 后继指针(已为表尾时为 NULL).
- 空表为空表结点.
- 长度: 最顶层元素个数.
- 深度: 括号最大重数.
- 向下遍历时 + 1 +1 +1, 向上回溯时 − 1 -1 −1, 动态记录最大值.
- 空表深度为 1 1 1.

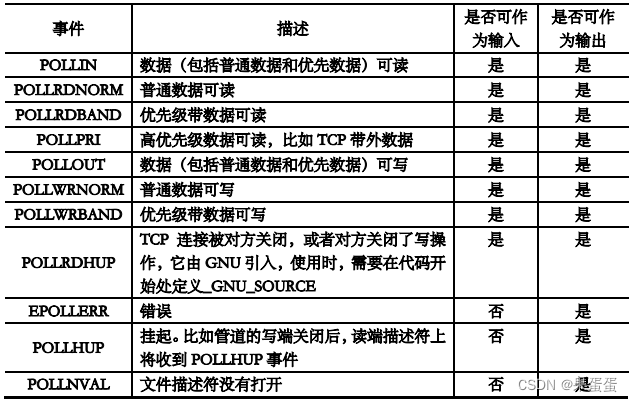
散列表定义/要素/优缺点
- 散列表: 利用连续内存的随机访问时间复杂度为 O ( 1 ) O(1) O(1), 将键值通过散列函数映射到数据索引, 实现快速查找/插入/删除的数组查找结构.
- 要素: 散列函数.
- 确定性: 同一键值, 散列函数总是得到相同的散列值.
- 高效性: 散列值计算速度要快, 以减少查找/插入/删除操作时的耗时.
- 冲突最小化: 不同的键值尽量映射到不同的区域中, 以避免解决冲突导致的性能下降.
- 优点
- 数据处理迅速.
- 能够以 O ( 1 ) O(1) O(1) 时间复杂度实现查找/插入/删除操作.
- 实现相对简单(关键只在于散列函数).
- 缺点
- 散列表中数据无序.
- 不允许出现重复数据.
- 为减少冲突率, 开辟数组大小需超过数据量很多, 容易造成空间浪费.
- 当发生冲突时, 解决冲突较为复杂.
森林转换为二叉树
- 树转换为二叉树
- 孩子结点从左到右顺序编号.
- 所有兄弟结点之间加边.
- 每个结点只保留与第一个孩子的边, 删掉和其余孩子间的边.
- 森林转换为二叉树
- 森林中所有树均转换为二叉树.
- 从第二棵二叉树开始, 依次将根结点作为前一棵二叉树的根结点的右孩子(即成为右子树).
- 所有二叉树都相连后即得.
图的最小生成树
- 最小生成树: 权值最小的生成(保留全部顶点)子树.
- Kruskal: 从边集中逐步选取不会形成回路的最小权边; 时间复杂度为 O ( m log m ) O(m\log m) O(mlogm).
- Prim: 从某结点出发逐步选取不会形成回路的最小权边邻接的顶点; 时间复杂度为 O ( n 2 ) O(n^2) O(n2).
应用题 (5)
给定二元算术表达式, 画出对应的树, 写出前缀表达式和后缀表达式
- 二元算术表达式构造树
- 叶子结点均为数字; 内部结点均为运算符(不包含括号).
- 按照运算优先级从叶子结点反向生长.
- 树的遍历
- 中序遍历 - 中缀表达式: 左根右.
- 前序遍历 - 前缀表达式: 根左右.
- 后序遍历 - 后缀表达式: 左右根.
给定字符及频率, 画出 Huffman 树, 写出 Huffman 编码
- Huffman 树构造
- 每个字符及频率视为一个结点, 即有结点集.
- 依次选择频率最小的两个结点, 构造分别以两结点作为左孩和右孩的新结点替换到集合中, 新结点频率为两结点频率和.
- 直至结点集中只剩一个结点, 即 Huffman 树.
- Huffman 编码: 从根结点出发, 左孩在末尾补 0 0 0, 右孩在末尾补 1 1 1, 直至叶子结点, 即得到该字符编码.
- 前缀码: 不存在某编码为另一编码的前缀的情况.
给定数组, 分别构造二叉排序树和 AVL 树(不平衡时旋转方式), 分别计算平均查找长度
- 构造二叉排序树
- 第一个数作为根结点.
- 小于当前结点成为左孩或进入左子树; 大于当前结点成为右孩或进入右子树.
- 构造 AVL 树
- 平衡: 每个结点平衡因子(左右子树高度差)的绝对值不超过 1 1 1.
- 插入后不平衡时递归旋转调整(旋转中心为子树的根结点).
| 不平衡情况 | 平衡因子 | 旋转类型 | 旋转方式 |
|---|---|---|---|
| LL: 插入较高的左子树的左子树 | 根结点 2 2 2; 左子树根结点 1 1 1 | 右单旋 | 原左子树根结点成为新根结点, 原左子树的右子树成为原根结点左子树, 原根结点成为原左子树根结点的右子树 |
| RR: 插入较高的右子树的右子树 | 根结点 − 2 -2 −2; 右子树根结点 − 1 -1 −1 | 左单旋 | 原右子树根结点成为新根结点, 原右子树的左子树成为原根结点的右子树, 原根结点成为原右子树根结点的左子树 |
| LR: 插入较高的左子树的右子树 | 根结点 2 2 2; 左子树根结点 − 1 -1 −1 | 左右双旋 | 左子树左旋, 整体右旋 |
| RL: 插入较高的右子树的左子树 | 根结点 − 2 -2 −2; 右子树根结点 1 1 1 | 右左双旋 | 右子树右旋, 整体左旋 |
- 平均查找成功长度 = ( ∑ =(\sum =(∑ 本层深度 × \times × 本层结点数 ) / )/ )/ 总结点数.
- 平均查找失败长度 = ( ∑ =(\sum =(∑ 本层深度 × \times × 本层结点补全空叶子结点数 ) / )/ )/ 补全叶子结点总数.
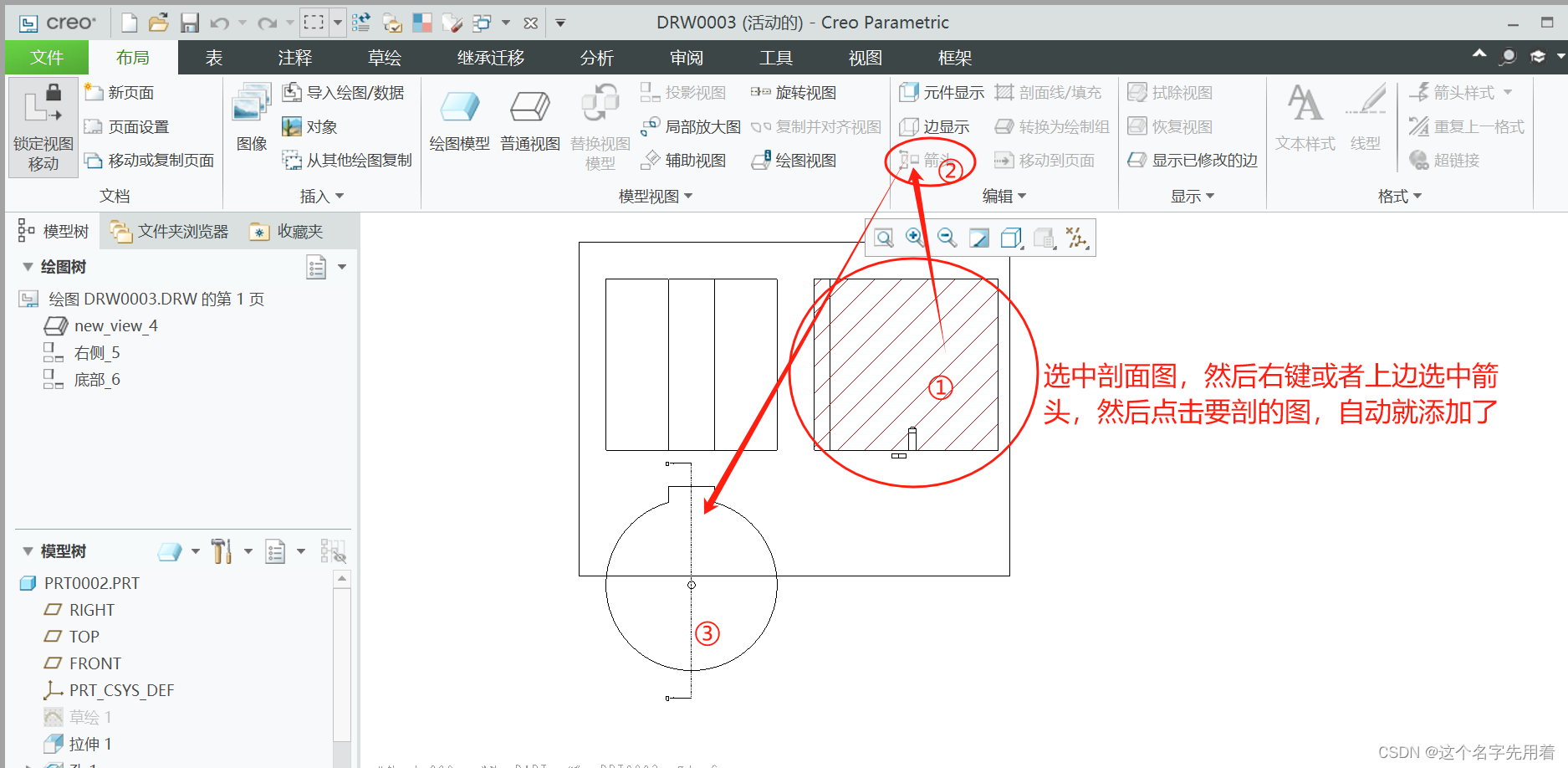
写出图的邻接矩阵和邻接表表示, 对图分别进行 BFS 和 DFS; 对有向图进行拓扑排序
- 邻接矩阵: 对角线为 0 0 0, 无边连接记为 ∞ \infty ∞.
- 邻接表: 遍历时需额外记录顶点邻接点链表中当前的指针.
- BFS: 使用队列辅助.
- 初始化一个队列, 起始顶点入队.
- 出队一个顶点, 标记已遍历, 将未遍历过的邻接点入队.
- 直至队列空.
- DFS: 使用栈辅助或递归.
- 初始化一个栈, 起始顶点入栈.
- 读栈顶, 若栈顶顶点仍有未被遍历的邻接顶点, 邻接顶点入栈; 若没有邻接点或邻接点已全部遍历, 出栈, 并标记为已遍历.
- 直至栈空.
- 拓扑排序: 对有向无环图的顶点线性排序; 每个顶点只出现一次; 若两顶点间存在路径, 则出发点必在终点前.
- 在图中选择一个入度为 0 0 0(即无前驱顶点)的顶点输出, 并在图中删除该顶点及边.
- 直到图中无顶点.
- 若图中仍有顶点但已无入度为 0 0 0 的顶点, 则说明有环, 不存在拓扑排序.
Dijkstra 算法和 Floyd 算法求图的最短路径
- Dijkstra 算法: 一点到其余各点的最短路径; 时间复杂度为
O
(
n
2
)
O(n^2)
O(n2).
- 初始化距离数组 D [ n ] D[n] D[n], 出发点 s s s 赋值为 0 0 0, 其余全部赋值为 ∞ \infty ∞.
- 更新当前顶点所有邻接点的距离 D [ i ] = min ( D [ i ] , D [ j ] + D i s t [ j ] [ i ] ) D[i]=\min(D[i],D[j]+{\rm Dist[j][i]}) D[i]=min(D[i],D[j]+Dist[j][i]) ( j j j 为当前顶点, D i s t [ n ] [ n ] {\rm Dist}[n][n] Dist[n][n] 为邻接矩阵); 当前顶点标记已遍历; 选择未遍历过且 D [ i ] D[i] D[i] 中值最小的顶点作为下一顶点.
- 直至遍历完全部顶点.
- Floyd 算法: 各点间最短路径; 时间复杂度为
O
(
n
3
)
O(n^3)
O(n3).
- 初始化距离矩阵 D [ n ] [ n ] = D i s t [ n ] [ n ] D[n][n]={\rm Dist}[n][n] D[n][n]=Dist[n][n].
- 依次以一顶点作为中介顶点更新距离矩阵 D [ x ] [ y ] = min ( D [ x ] [ y ] , D [ x ] [ j ] + D [ j ] [ y ] ) D[x][y]=\min(D[x][y],D[x][j]+D[j][y]) D[x][y]=min(D[x][y],D[x][j]+D[j][y]) ( j j j 为当前顶点).
- 直至遍历完全部顶点.
选择排序/堆排序/冒泡排序/快速排序/归并排序的步骤/算法复杂度/数据比较次数
- 选择排序
- 依次选出尾序列中的最值放在序列起始位置.
- 从头遍历到尾的前一个.
- 堆排序
- 原地构造大根堆.
- 交换当前末尾与根, 固定末尾将头序列调整为大根堆.
- 从尾遍历到头的后一个.
- 冒泡排序
- 相邻的两两比较并交换.
- 从头遍历到尾的前一个.
- 快速排序
- 分区中随机选择一个基准, 所有小于基准的放在一侧, 大于基准的放在另一侧.
- 对左右小分区递归操作
- 归并排序
- 开辟临时空间, 有序子序列合并后存入临时空间.
- 递归操作.
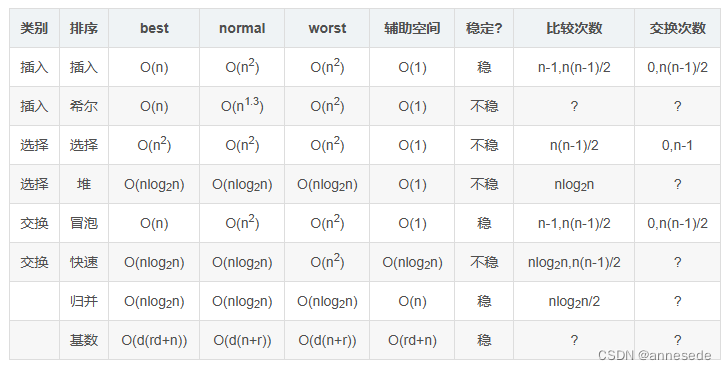
表格来自: 各类排序算法特性+比较次数+交换次数对比表格.
*多项式广义表表示
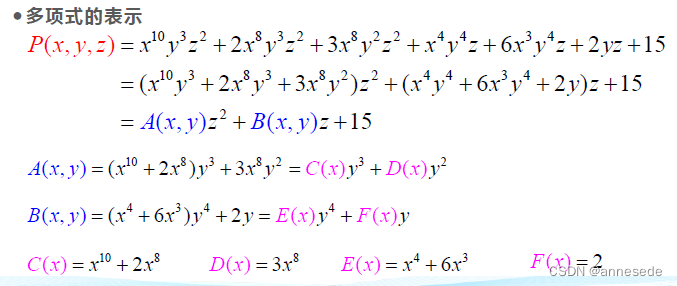

*堆的存储结构和小根堆构建
- 小根堆: 结点值总不小于其父结点值的完全二叉树.
- 存储结构: 链式存储; 顺序存储(数组模拟).
- 小根堆构建: 数组模拟
- 从最底层子树开始, 递归调整父结点和子结点, 使得父结点小于等于子结点.
- 调整后还需递归检查并调整子树, 确保每个子树中父结点均小于等于子结点.
- 直至调整完根节点, 递归检查并调整所有子树.
*先序遍历和中序遍历重构二叉树; 层次遍历和中序遍历重构二叉树
- 先序遍历和中序遍历重构二叉树
- 先序遍历为"根左右", 中序遍历为"左根右", 由此可确定根结点和左右子树.
- 递归地, 可一直确定到左右叶子结点及其父结点.
- 层次遍历和中序遍历重构二叉树
- 层次遍历第一个结点必为根结点, 中序遍历为"左根右", 由此可确定左右子树.
- 层次遍历第二个结点开始为第二层的根结点, 递归地, 可以确定每一层的根结点和左右子树.
*四则运算求值
- 中缀表达式变为后缀表达式
- 数字直接列出.
- 优先级高于或等于栈顶符号的运算符/左括号入栈; 优先级低于栈顶符号/右括号时, 栈顶运算符/左括号出栈, 直至高于或等于栈顶运算符/左括号出栈后, 再入栈.
- 后缀表达式求值
- 数字入栈.
- 遇到运算符时出栈两个数字, 并将运算结果入栈.
- 最后栈中只剩一个数字, 即为运算结果.
算法设计 (2)
两个递增单链表原地合并为递增/递减链表
- 双指针法
- 两个指针分别指向两个单链表头部.
- 比较指针指向结点的数据: 数据较小的结点插入新链表, 指针后移; 相等时插入第一个单链表的结点, 两个指针同时后移.
- 递增合并为递增时采用尾插法; 递增合并为递减时采用头插法.
- 直至一个指针来到单链表末尾.
- 继续将另一指针(若未指向单链表末尾)指向结点插入新链表并后移, 直至也来到单链表末尾.
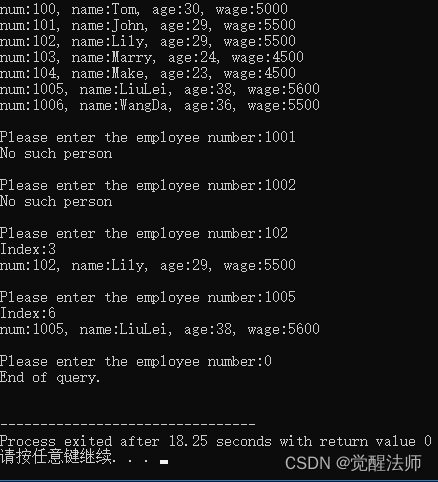
二叉树查找结点并递归返回路径
- 后序遍历
- 找到结点时, 输出当前结点并返回 1 1 1; 抵达叶子结点时返回 0 0 0.
- 左右子递归返回 1 1 1 时, 输出当前结点.
- 递归返回左右子递归返回值.
二叉树中相距最远的距离
- 后序遍历
- 当前根结点最远距离: m a x D i s t = max ( m a x D i s t L e f t , m a x D i s t R i g h t , h e i t g h t L e f t + h e i g h t R i g h t ) {\rm maxDist}=\max({\rm maxDistLeft}, {\rm maxDistRight}, {\rm heitghtLeft}+{\rm heightRight}) maxDist=max(maxDistLeft,maxDistRight,heitghtLeft+heightRight).
- 递归返回最远距离及高度(或结点维护高度只递归返回最远距离).
一步可以迈一个或两个台阶, 走十级台阶有多少种走法
- 动态规划
- 状态转移方程: f ( n ) = f ( n − 1 ) + f ( n − 2 ) f(n)=f(n-1)+f(n-2) f(n)=f(n−1)+f(n−2).
- 初始值: f ( 1 ) = 1 , f ( 2 ) = 2 f(1)=1,f(2)=2 f(1)=1,f(2)=2.


![流批一体计算引擎-9-[Flink]中的数量窗与时间窗](https://img-blog.csdnimg.cn/direct/c817cc224fad4539b1d2fcb638ec0e6e.png)