绪论
勿问成功的秘诀为何,且尽全力做您应该做的事吧。–美华纳;本章是MySQL的第二章,本章主要写道MySQL中库和表的增删查改以及对库和表的备份处理,本章是基于上一章所写若没安装mysql可以查看Linux下搭建mysql软件及登录和基本使用,同时也强烈建议先上一章在看本章。
话不多说安全带系好,发车啦(建议电脑观看)。

思维导图:

1.库的操作
1.1创建库
创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name #字符集
[DEFAULT] COLLATE collation_name #校验规则
[] 是可选项,也就表示着括号内的内容可填可不填的。
其中 IF NOT EXISTS:表示判断下创建的库是否存在(创建的文件存在了就会报错误信息)
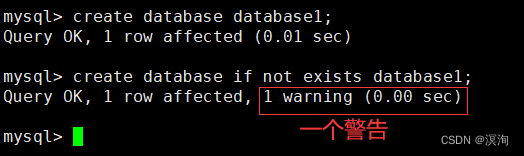
1.1.1指定编码在创建数据库时:
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci(在配置文件中写的)
设置库的字符集和校验规则
语法:
create database dbname charset=字符集 collate 校验规则;
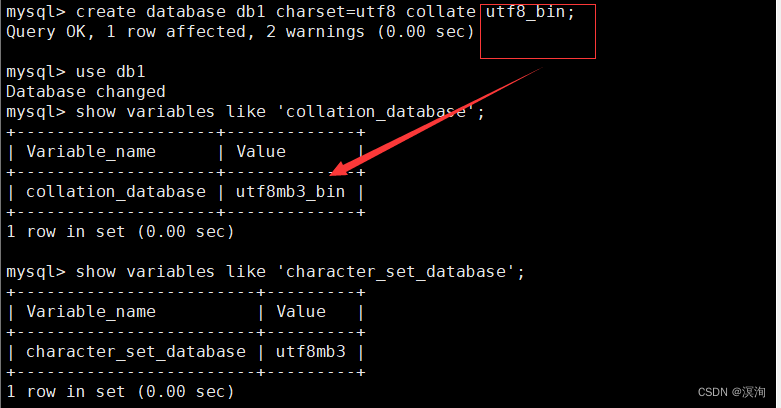
单独的设置字符集:
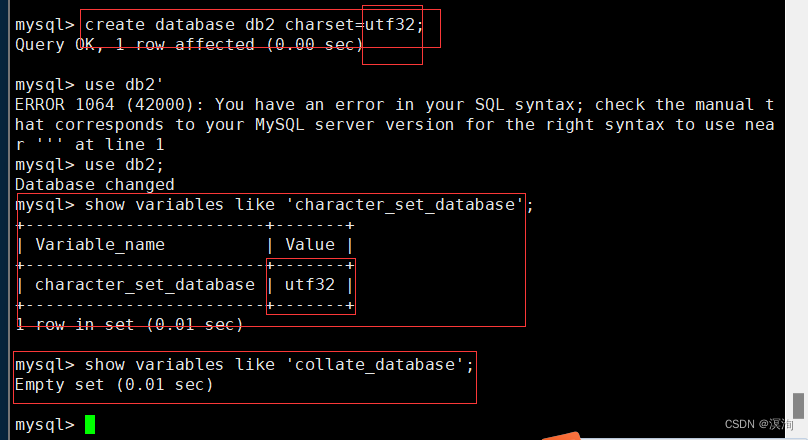
1.1.2字符集和校验规则:
- 数据库字符集 — 数据库未来存储的数据
- 数据库校验集 — 支持数据库,进行字段比较时使用的编码,本质是一种读取数据库中数据的采用的编码格式
写和读的编码集必须是统一的,也就是数据库无论对数据的任何操作,都必须保证操作和编码必须保持一致
查看系统默认字符集以及校验规则:
查看字符集:
show variables like 'character_set_database';
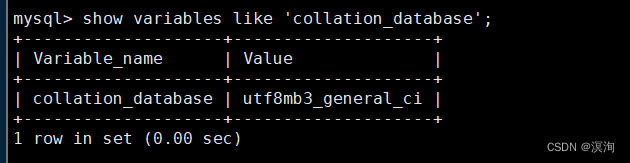
查看校验集;
show variables like 'collation_database';

查看数据库支持的字符集和校验规则:
查看数据库所有支持的字符集:
show charset;
查看数据库支持的校验规则:
show collation;


1.1.3校验规则对数据库的影响
上面所用到的的utf8_general_ci是不区分大小写的、而utf8_bin区分大小写。
验证utf8_general_ci是不区分大小写的如下(附:db数据库的校验规则是utf_general_ci):
在表中查找某个数据验证
语法:
select * from table_name where row_name=check_information;
具体使用:
select * from person where name='a';

上图发现排序后的a、A是一样的,故是不区分大小写的。
排序方法验证(默认升序)
语法:
select * from table_name order by Row_name;
具体使用:
select * from person order by name;

utf8_bin区分大小写的:
在表中查找某个数据
语法:
select * from table_name where row_name=check_information;
具体使用:
select * from person where name='a';
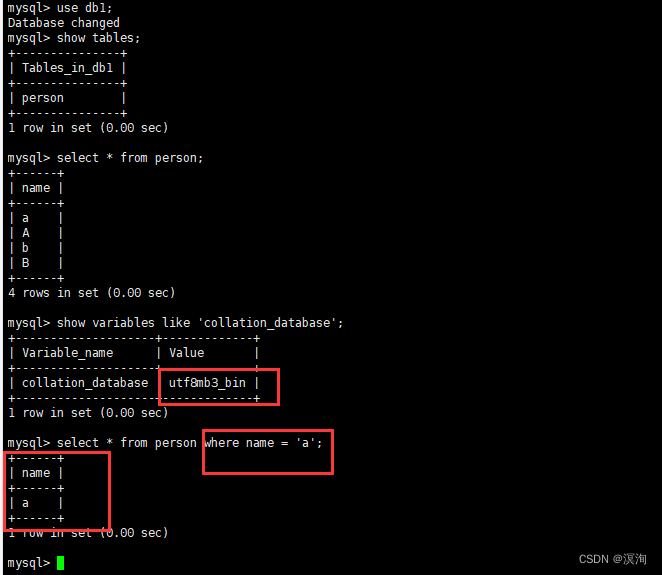
上图只查出了一个就表示是区分大小写的(a!=A)
排序(默认升序):
语法:
select * from table_name order by Row_name;
具体使用:
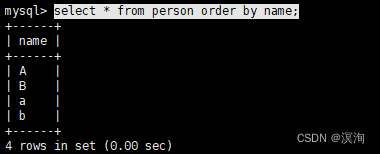
select * from person order by name;
1.2删除库
语法:
DROP DATABASE [IF EXISTS] db_ name;
附:强烈不建议轻易的删除数据库
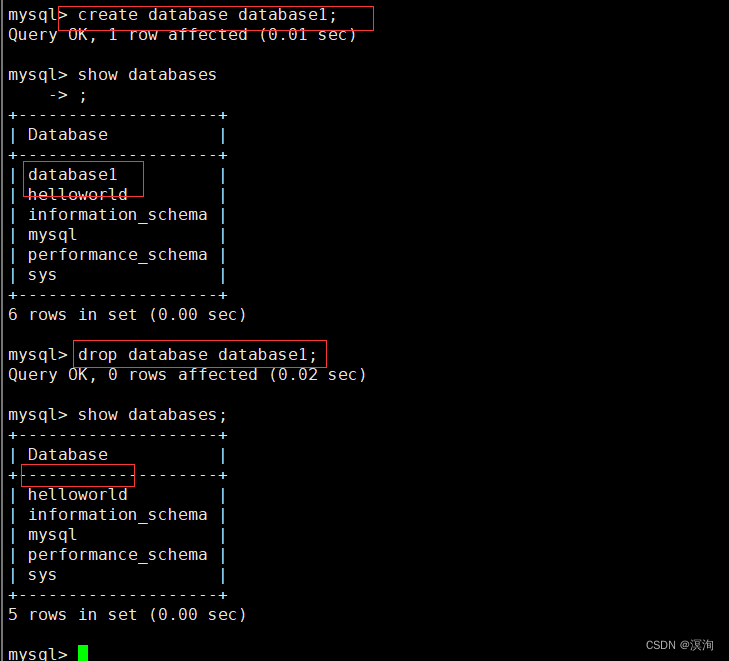
执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
1.3查看库
查看数据库的语法:
show databases;

查看当前所在数据库的语法:
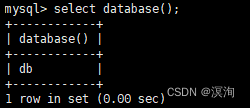
select database();
如当前在db数据库下:
显示创建库的语句
语法:
show create database dbname; #dbname就是数据库名

- 其中在查看到创建库的语句中的 /*!40100 default… */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
1.4修改库
语法:
ALTER DATABASE db_name [alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name #字符集
[DEFAULT] COLLATE collation_name #校验规则
具体使用sql语句方法:
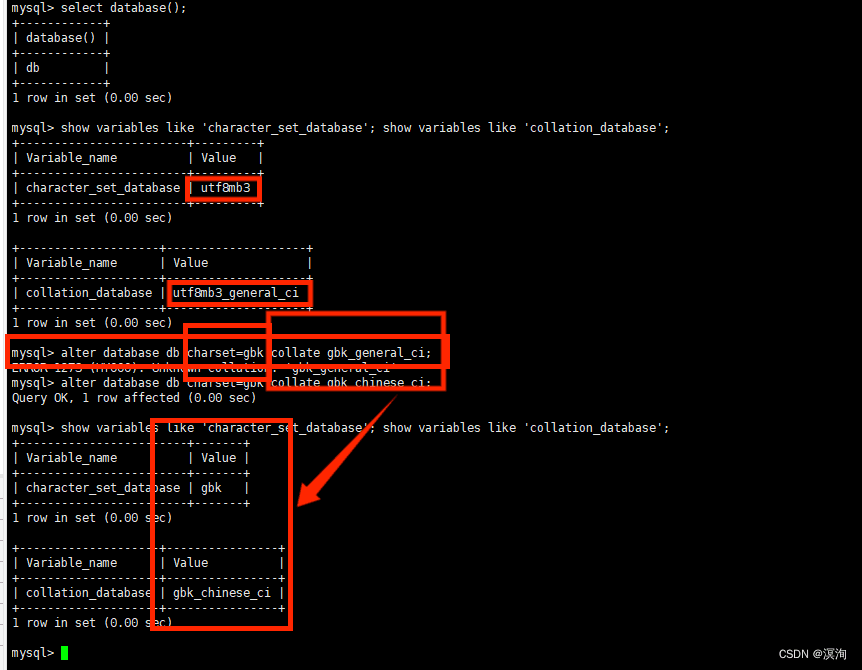
alter database db charset=gbk collate gbk_general_ci;
2.表的操作
2.1创建表
语法:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;
具体使用:
1.
create table if not exists user1(
id int,
name varchar(20) comment '用户名',
password char(32) comment '密码',
birthday date comment '生日'
)character set utf8 collate utf8_general_ci engine MyIsam;
2.
create table user2(
id int,
name varchar(20) comment '用户',
password char(32) comment '密码',
birthday date comment '生日'
)charset=utf8 collate=utf8_general_ci engine=InnoDB;


对比两次创表过程:最后的字符集和校验规则以及存储引擎有两种自定义的方法(自行选择顺手的使用- -)
character set utf8 collate utf8_general_ci engine MyIsam;
charset=utf8 collate=utf8_general_ci engine=InnoDB;
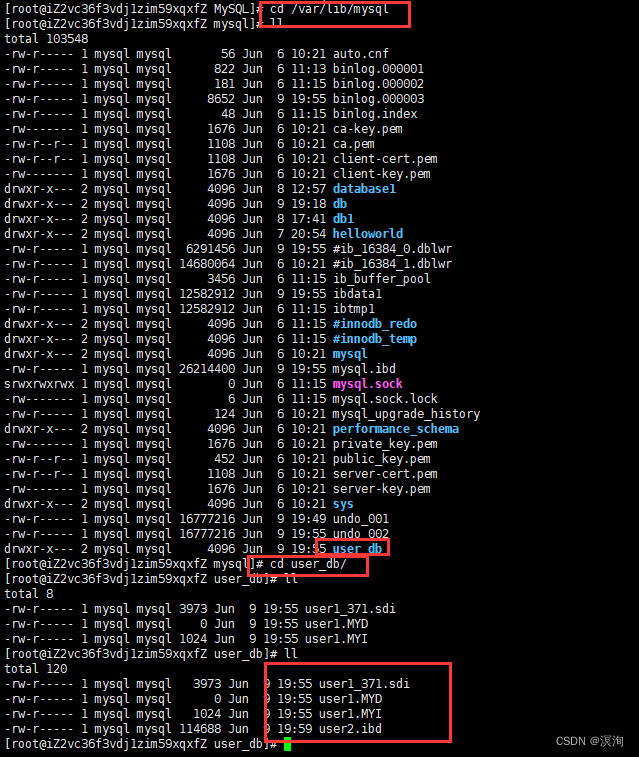
2.1.1当创建的表在库目录使用不同的存储引擎,创建表的文件也是不一样的
-
user1 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
- user1.frm:表结构
- user1.MYD:表数据
- user1.MYI:表索引
-
user2 表存储引擎是 InnoDB ,在数据目中有的文件是:
- user2.frm:表结构
- user2.ibd:表空间文件,用于存储数据和索引
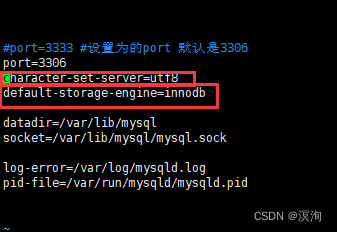
附:当不指定写字符集和校验规则以及存储引擎的话就会默认成配置文件所默认的。
配置文件所在的地址:/etc/my.cnf

1.2查看表
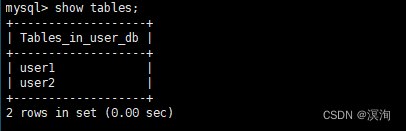
语法:
show tables;
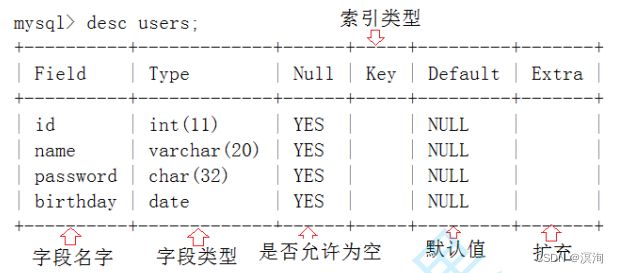
查看表结构(详细信息)
语法:
desc 表名;

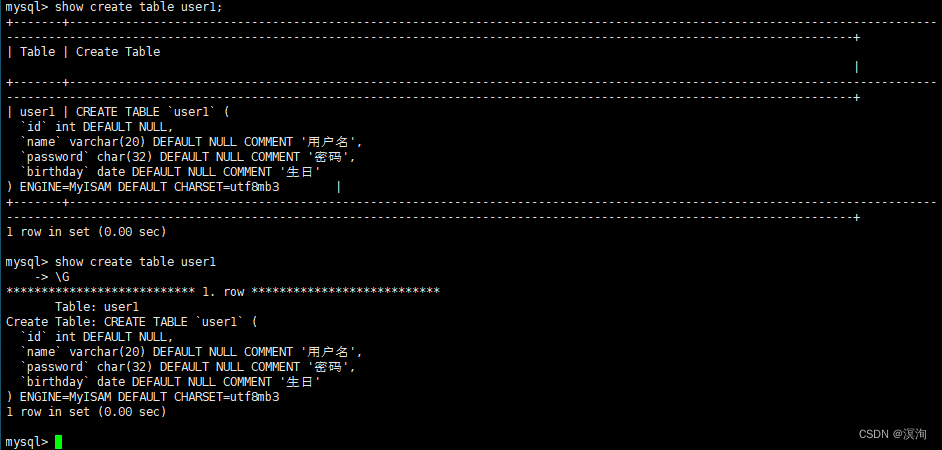
查看创建表的语句
语法:
show create table 表名;
show create table 表名 \G;#加上\G格式化展示
查看创建表的详细数据
语法:
select * form 表名;

1.3修改表
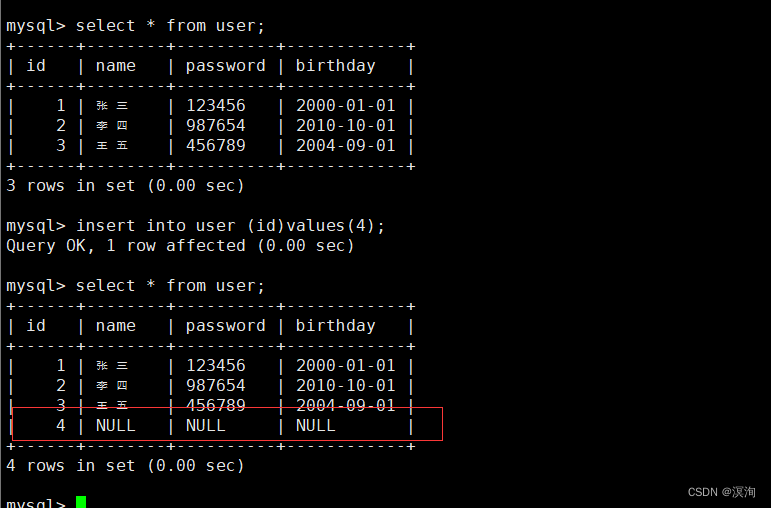
插入信息
语法:
insert into 表名 (列名)values(对应信息);

上图看出若不加列名表示在所有的行都添加信息,反之在values前面加上括号就指定了在某列中添加信息(下图在指定id处添加4)
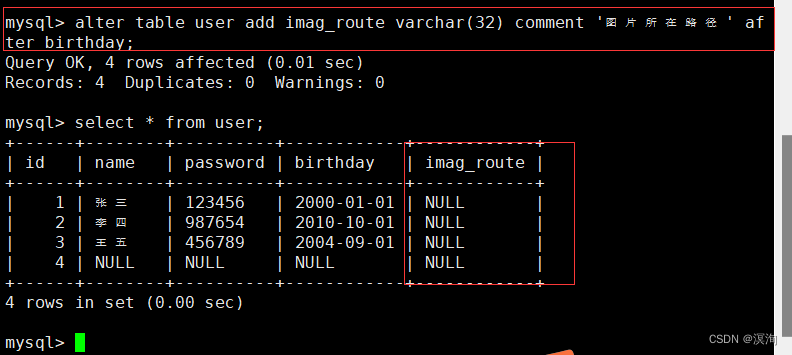
插入新的一列
语法:
alter table 表名 add 新列名 列的类型 comment '描述' after 放在那一行后面
具体使用:
修改某一列的属性
语法:
alter table tablename modify rowname 新属性;
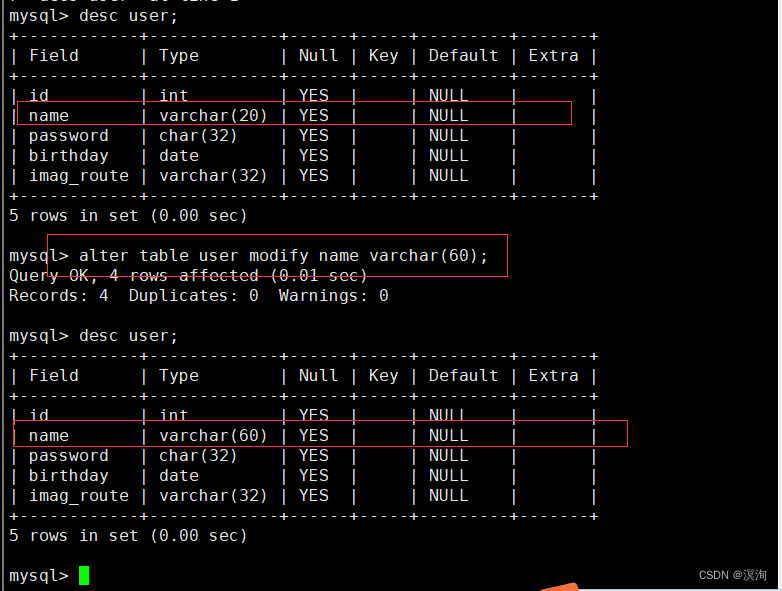
注:
其中我们在修改时,最好写全了(包括描述),因为这是覆盖式的修改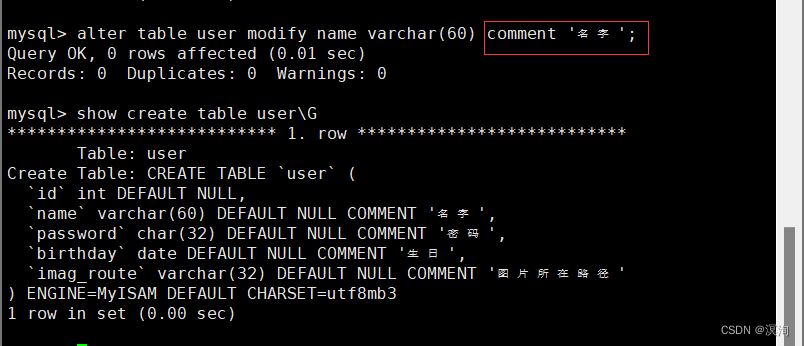
不写全的话:
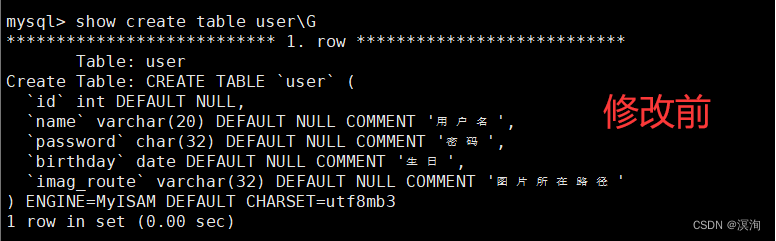
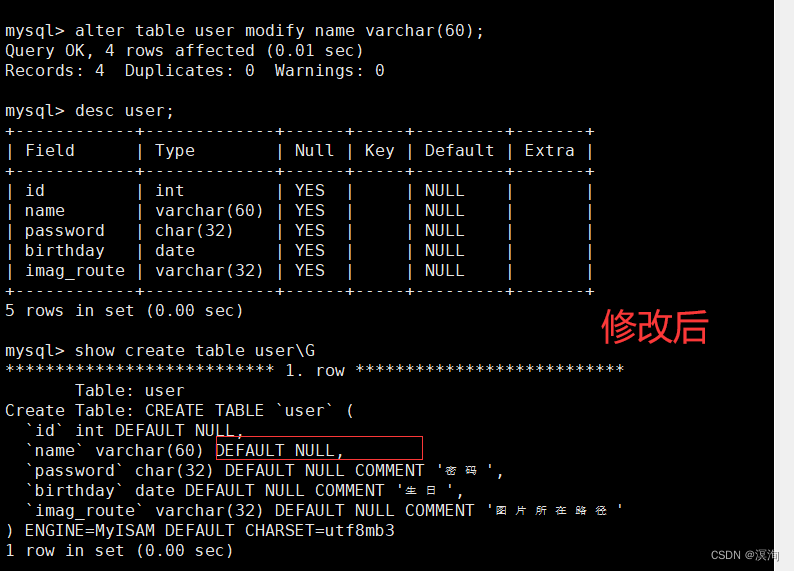
修改表名
语法:
alter table 表名 rename to 新的表名;
其中 to 可以省略

修改列名
语法:
alter table 表名 change 列名 新列名;
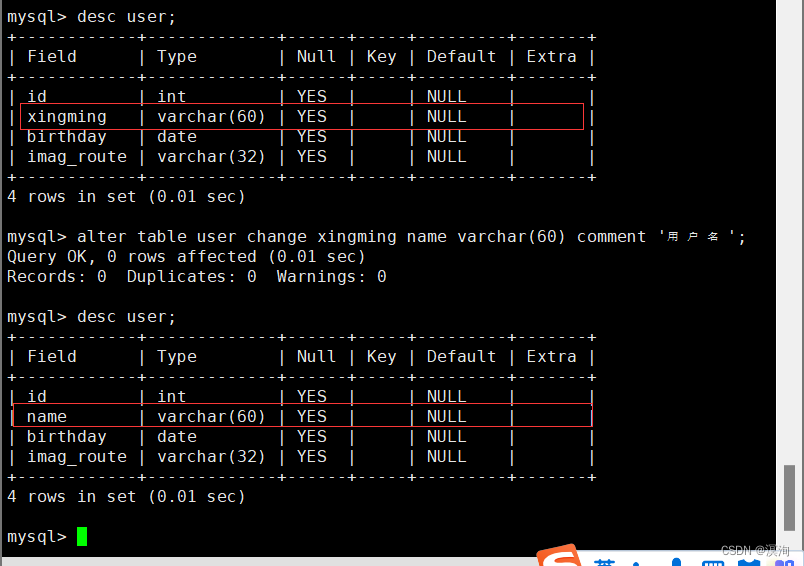
注:在重命名列名时必须要加类型,并且的同样的最好写全了!
1.4删除表
语法:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
具体使用:
drop table user1;
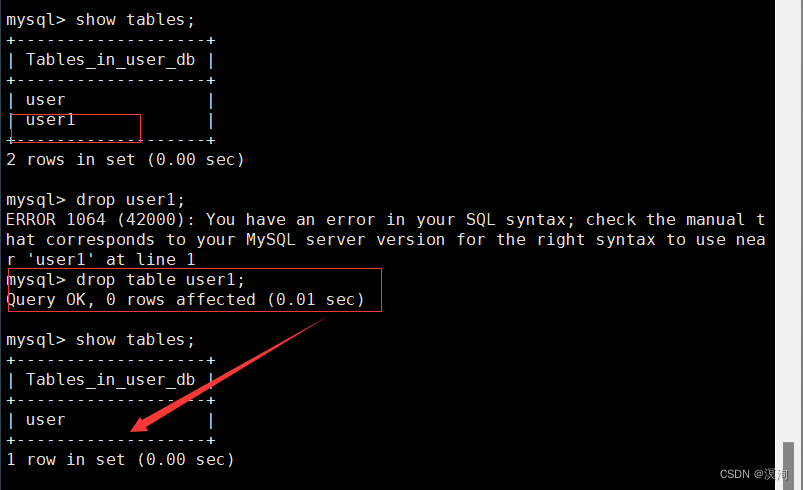
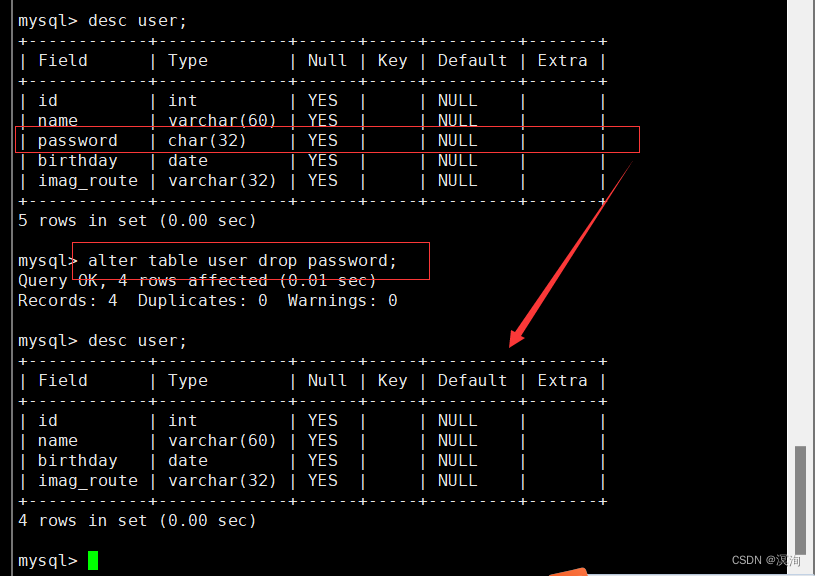
删除列
语法:
alter table 表名 drop 列名;
注:一般不要删,删除后该行的数据就再也找不到了,并且也会影响所有上层用到该数据库的地方
3.数据库中的备份和恢复
3.1备份数据:
通过在服务器上输入bash指令:
备份库:
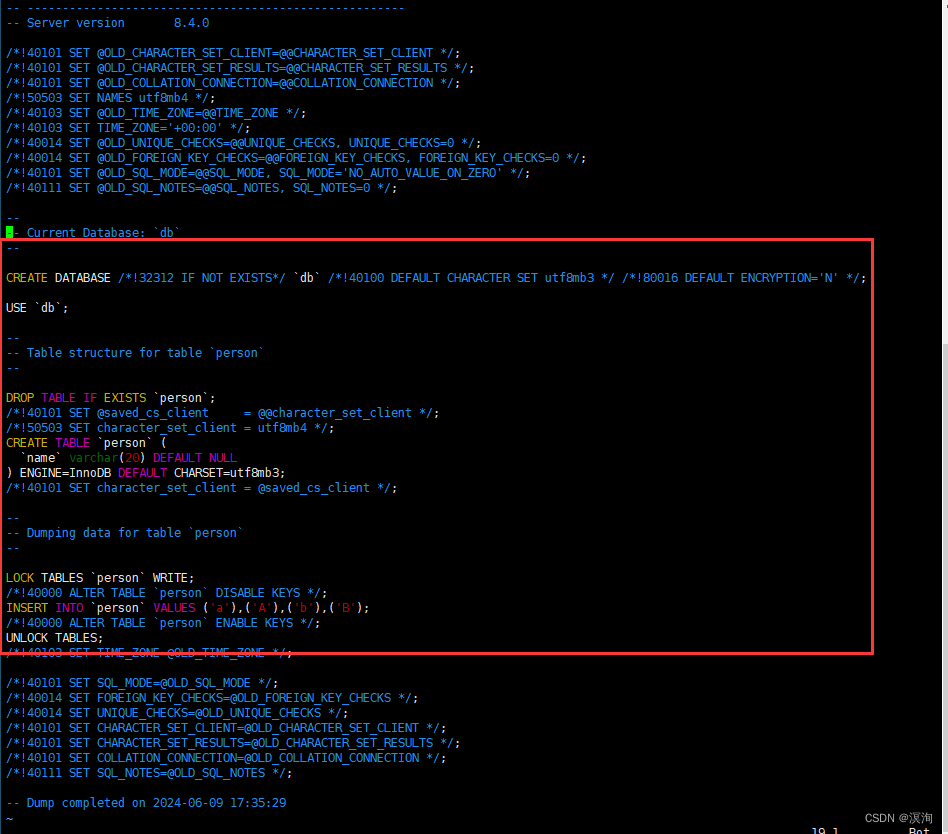
mysqldump -P3306 -uroot -p -B db > db.sql
将会生成一个db.sql备份文件
查看内部内容的语法:
vim db.sql
内部内容就是在数据库主要的sql语句:
3.2恢复数据
source 备份文件的路径;
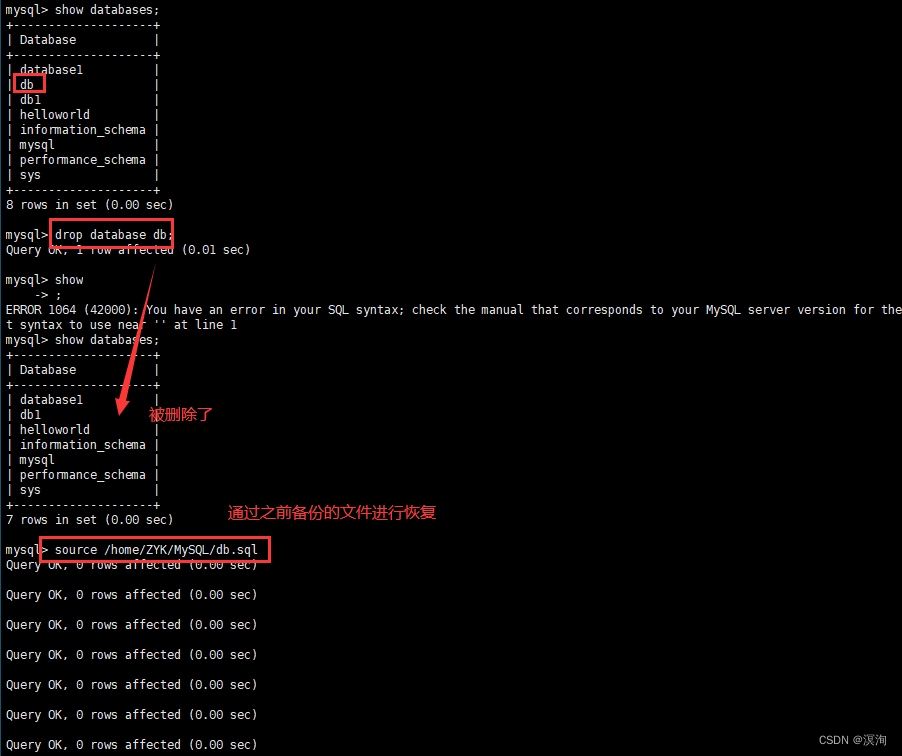
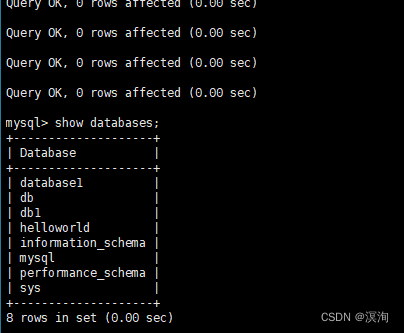
附:
- 备份某张表(恢复一样)
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
其实也就发现和备份库不一样的是少了 -B 选项,所以也就表明了 -B 选项的含义就是在备份文件中加一个创建数据库的SQL语句
同时也侧面说明了,该还原时是需要在一个已经创建好的数据库下使用source来进行还原的!
- 同时备份多份数据库(也很简单类似于备份一个数据库)
mysql -uroot -p -B 数据库名1 数据库名2 ... > 数据库存放的路径
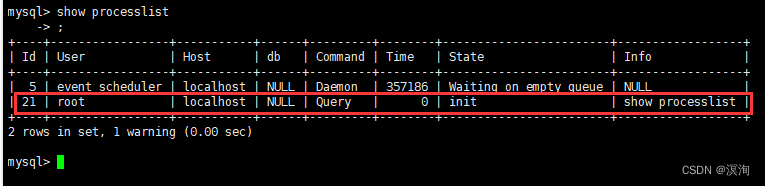
- 查看连接状态
show processlist;
本章完。预知后事如何,暂听下回分解。
如果有任何问题欢迎讨论哈!
如果觉得这篇文章对你有所帮助的话点点赞吧!
持续更新大量MySQL细致内容,早关注不迷路。