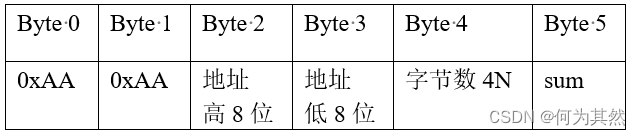
本实验测试数据库在有索引和五索引内容上的查询时间随着数据量级增长的变化
测试的表结构
使用一个菜单的数据库表,包括菜品的ID,菜品名和价格
CREATE TABLE `Menu` (
`dish_id` int(6) unsigned zerofill NOT NULL AUTO_INCREMENT,
`dish_name` varchar(255) NOT NULL,
`price` decimal(10,2) NOT NULL,
PRIMARY KEY (`dish_id`) USING HASH,
UNIQUE KEY `dish_name` (`dish_name`) USING HASH
);
测试程序
使用python程序,插入有两个并发线程(模拟多用户使用),以每秒100条数据插入,然后查询有一个线程,每秒查询一次,同时操作菜单表,查询的是非主键,所有的操作时间都通过日志保存。最终程序会运行到百万级别的数据量,这样才能更清晰的看出有无索引查询的区别
有索引测试程序
import mysql.connector
import threading
import time
import random
import logging
import os
from tqdm import tqdm
def insert_data(
user, password, host, database,
freq, spend, times,
insert_logger
):
cnx = mysql.connector.connect(
user=user,
password=password,
host=host,
database=database
)
cursor = cnx.cursor()
for _ in tqdm(range(times)):
start_time = time.time()
for _ in range(freq):
dish_name = f"dish_{random.randint(1, 1000000)}"
price = random.randint(10, 100)
query = "INSERT INTO Menu_2 (dish_name, price) VALUES (%s, %s)"
data = (dish_name, price)
cursor.execute(query, data)
cnx.commit()
use_time = time.time() - start_time
if spend - use_time > 0:
time.sleep(spend - use_time)
insert_logger.info(f"Insert operation took {use_time} seconds")
cnx.close()
def execute_query(
user, password, host, database,
freq, spend, times,
query_logger
):
cnx = mysql.connector.connect(
user=user,
password=password,
host=host,
database=database
)
cursor = cnx.cursor()
for _ in tqdm(range(times)):
start_time = time.time()
dish_id = random.randint(1, 1000000)
query = "SELECT * FROM Menu_2 WHERE dish_id = %s"
data = (dish_id,)
cursor.execute(query, data)
cursor.fetchall()
use_time = time.time() - start_time
if 1 - use_time > 0:
time.sleep(1 - use_time)
query_logger.info(f"Query operation took {use_time} seconds")
cnx.close()
def build_thread(
name, log_format, date_format, dir,
threads, func, *args,
):
logger = logging.getLogger(name)
logger.setLevel(logging.INFO)
handler = logging.FileHandler(dir + '/' + name + ".log", mode='w')
handler.setFormatter(logging.Formatter(log_format, datefmt=date_format))
logger.addHandler(handler)
args = list(args)
args.append(logger)
t = threading.Thread(
target=func,
args=args
)
threads.append(t)
if __name__ == "__main__":
user='root'
password='123456'
host='127.0.0.1'
database='db_test'
freq = 100
spend = 1
dir = 'indexlogs'
if not os.path.exists(dir):
os.makedirs(dir)
log_format = "%(asctime)s: %(message)s"
date_format = "%Y-%m-%d %H:%M:%S"
args = [
user, password, host, database,
freq, spend, int(1000000/freq)
]
threads = []
build_thread(
'insert_thread1', log_format, date_format, dir,
threads, insert_data, *args
)
build_thread(
'insert_thread2', log_format, date_format, dir,
threads, insert_data, *args
)
build_thread(
'query', log_format, date_format, dir,
threads, execute_query, *args
)
for t in threads:
t.start()
for t in threads:
t.join()无索引测试程序
主要是修改查询部分的线程函数,有索引测试查询的是主键,无索引测试得使用其他字段,同时main部分也要一些修改
def execute_query(
user, password, host, database,
freq, spend, times,
query_logger
):
cnx = mysql.connector.connect(
user=user,
password=password,
host=host,
database=database
)
cursor = cnx.cursor()
for _ in tqdm(range(times)):
start_time = time.time()
dish_name = f"dish_{random.randint(1, 1000000)}"
query = "SELECT * FROM Menu_1 WHERE dish_name = %s"
data = (dish_name,)
cursor.execute(query, data)
cursor.fetchall()
use_time = time.time() - start_time
if 1 - use_time > 0:
time.sleep(1 - use_time)
query_logger.info(f"Query operation took {use_time} seconds")
cnx.close()
if __name__ == "__main__":
user='root'
password='123456'
host='127.0.0.1'
database='db_test'
freq = 100
spend = 1
dir = 'noindexlogs'
if not os.path.exists(dir):
os.makedirs(dir)
log_format = "%(asctime)s: %(message)s"
date_format = "%Y-%m-%d %H:%M:%S"
args = [
user, password, host, database,
freq, spend, int(1000000/freq)
]
threads = []
build_thread(
'insert_thread1', log_format, date_format, dir,
threads, insert_data, *args
)
build_thread(
'insert_thread2', log_format, date_format, dir,
threads, insert_data, *args
)
build_thread(
'query', log_format, date_format, dir,
threads, execute_query, *args
)
for t in threads:
t.start()
for t in threads:
t.join()测试结果可视化
因为前面的测试都有日志保存,我们可以提取相关的数据下来做可视化分析,下面是可视化的程序
import os
import matplotlib.pyplot as plt
import pandas as pd
def draw_figure(name):
dir = name + 'logs'
logs = [
'insert_thread1.log',
'insert_thread2.log',
'query.log'
]
plt.figure(figsize=(10,6))
for log in logs:
with open(dir + '/' + log, 'r') as file:
lines = file.readlines()
time = [float(line.split()[-2]) for line in lines]
df = pd.DataFrame(time, columns=['Time'])
plt.plot(df['Time'], label=log.split('.')[0])
plt.title(name + ' pression exp')
plt.xlabel('Operation Index')
plt.ylabel('Time (seconds)')
plt.legend()
plt.savefig(dir + '/' + name + '_analyze.png')
if __name__ == '__main__':
draw_figure('noindex')
draw_figure('index')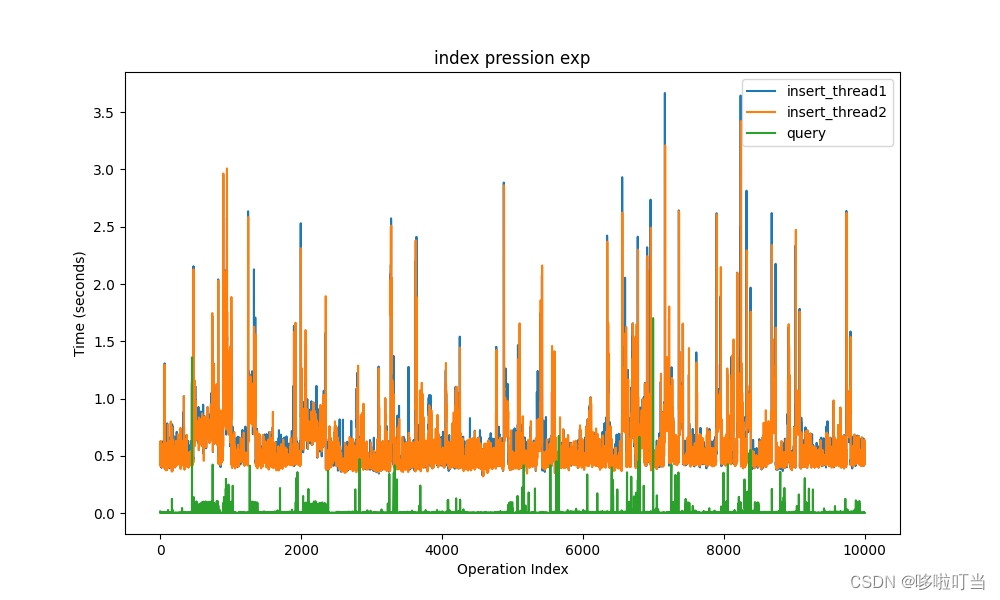
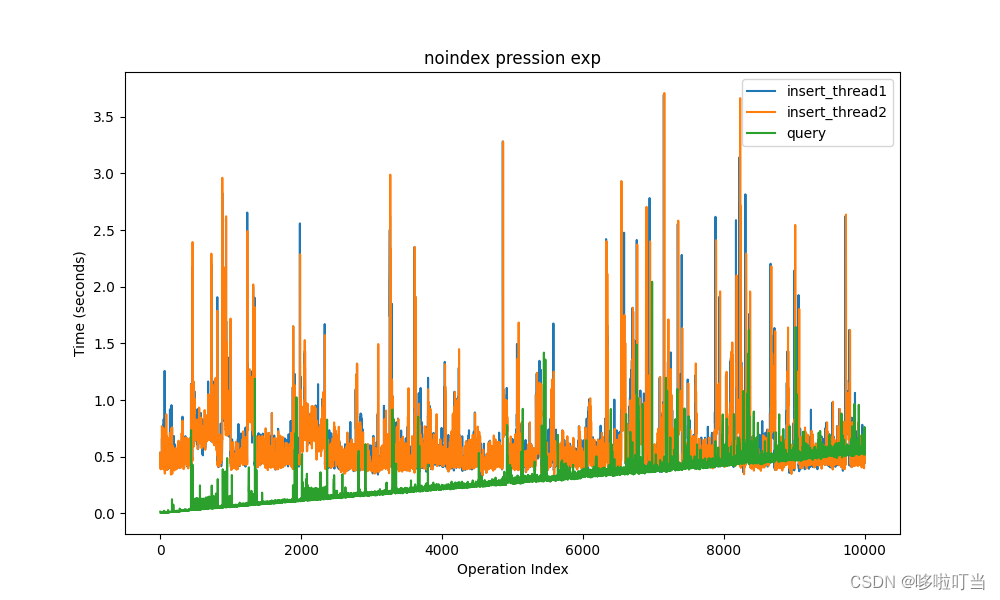
这样子可以很直观的看到,其实随着数据两级的加大,数据的插入操作时间是不怎么变化的,但是无索引的字段查询时间在呈线性升高,有索引的字段查询时间则很稳定。